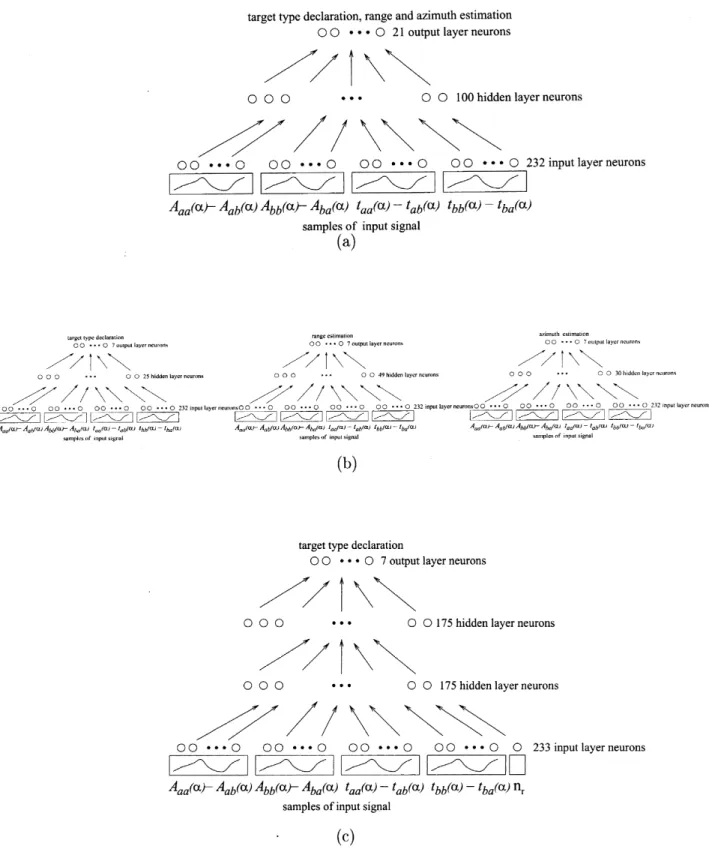
Neural networks for improved target differentiation and localization with sonar
Tam metin
Şekil

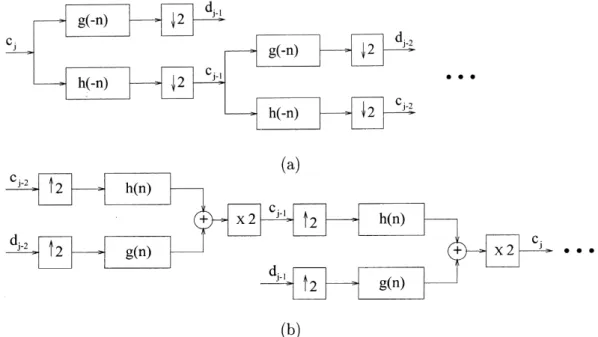
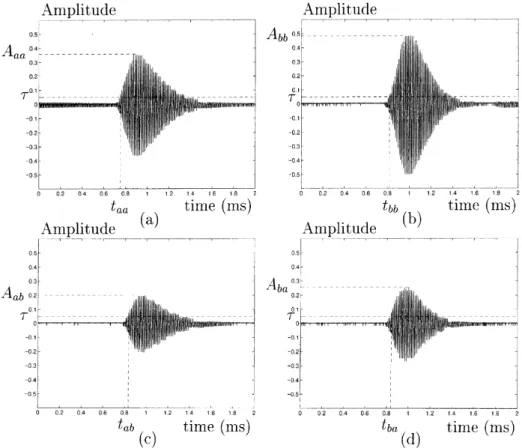

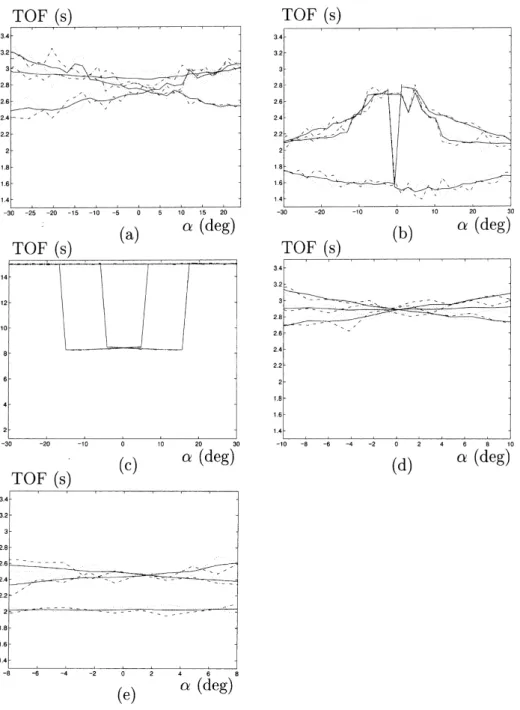

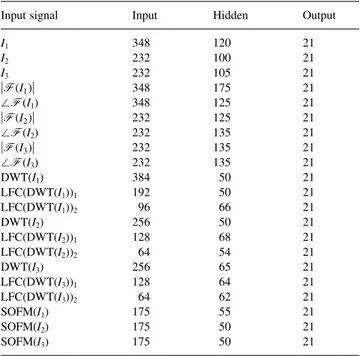
Benzer Belgeler
pylori pozitif olan ve B 12 vitamin eksikliği olan bireyler çalışmaya alınmıştır.Sonuç- ta dental plakta H.. Pylori bulunanlarla OHI ile iliş- kili bulunmuştur.Bu ilişki,
It is interesting to note that all these data were obtained with a relatively small number of measurements, which implies a reduced amount of time (1 hour), with particular care
Thus, we solved the generated test problems using the minisum version of ASP and reported the results of the model (P2) for five instances of the problem with 40 rectangles, 0.25
By adjusting the power and com- pression settings, or the power alone, of a fixed-wavelength pump pulse provided by a standard mode-locked fiber laser, the output FOCR wavelength from
Kernel approximation with random Fourier features [33] is used for binary classification problem in [34] where the proposed algorithm learns (in online manner) the linear
In other words, SEEK is used for searching a server with load and storage space inclusively bounded by certain values, respectively, and storage space is as less as possible.. By
The optimal solution of the path-based model determines not only the road links that should be closed to hazmat shipments by the regulator, but also the routes that would be used
Her basın yayın organının riayet etmesi gerekli evrensel kurallar, prensipler vardır. Bu kurallar ve prensipler ile birlikte her basın yayın organının
