Online anomaly detection with bandwidth optimized hierarchical kernel density estimators
Tam metin
Şekil
![Fig. 1. In this example, a depth-2 binary tree partitions the observation space S = [−A, A] × [−A, A]](https://thumb-eu.123doks.com/thumbv2/9libnet/5925746.123107/4.918.196.730.85.342/fig-example-depth-binary-tree-partitions-observation-space.webp)
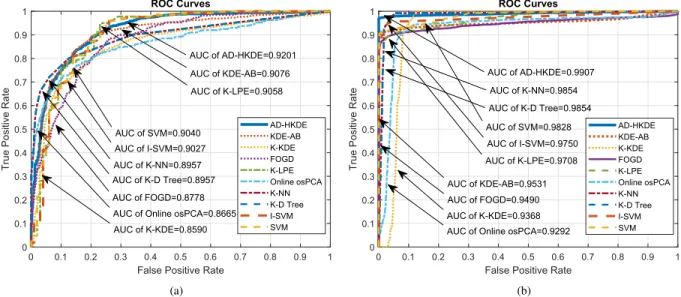
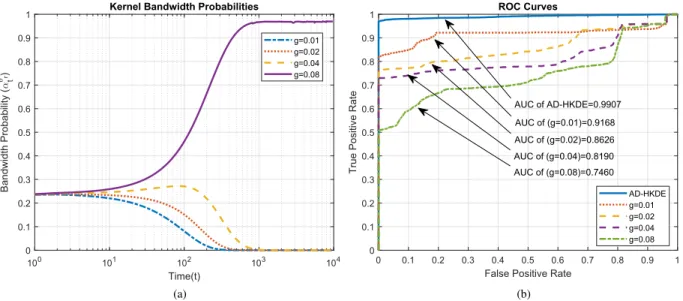
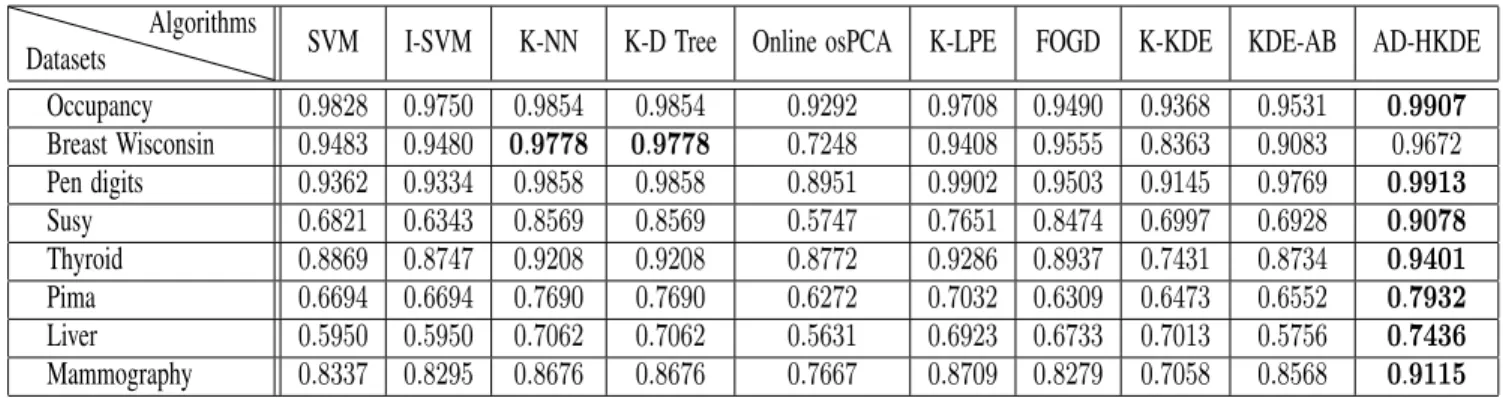
Benzer Belgeler
Bunun yanında Carlson (2009) çevre estetiği için uygun bulmadığı peyzaj modeli için hakim manzarayı dayattığı görüşünü öne sürmüştür. Ancak bu çalışmada
The main purpose of this paper is to prove the existence of the fuzzy core of an exchange economy with a heterogeneous divisible commodity in which preferences of individuals are
After CP removal and FFT processing, the resulting sig- nals are applied to a whitening filter (to remove the effects of correlated ambient noise) and finally to a maximum
In the following, two figures of merit in terms of gain- bandwidth product defined in [5] are used to compare the performance of cMUTs with the uniform and nonuniform membranes..
Systematically varying the angle of deposition (θ) with respect to the surface normal, we found that the device current efficiency and external quantum efficiency (EQE)
ABSTRACT: Range-separated hybrid functionals along with global hybrids and pure density functionals have been employed to calculate geometries, ionization energies (IP)s,
Abstract The purpose of this note is to give a probability bound on symmetric matrices to improve an error bound in the Approximate S-Lemma used in establishing levels of
The basic idea of our method is that the detector reading is maximum at some positions and the corresponding positional values of the sensors can be used for range estimation
