Lock-based concurrency control in distributed real-time database systems
Tam metin
Şekil
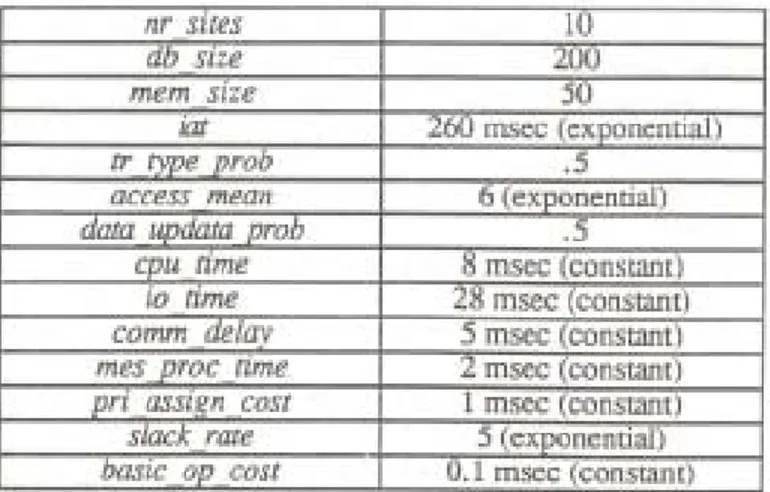
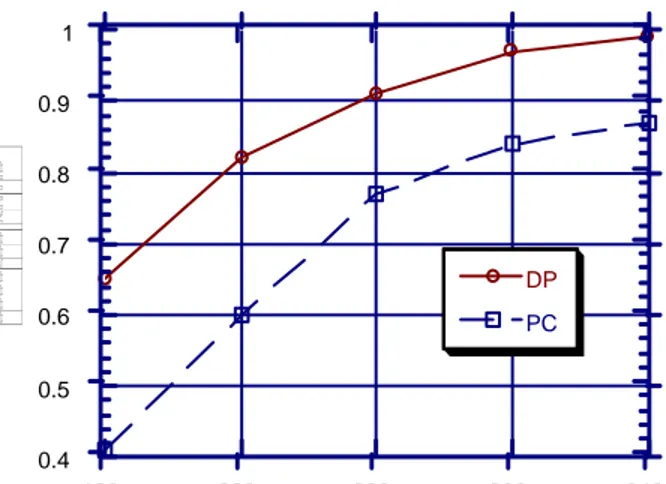
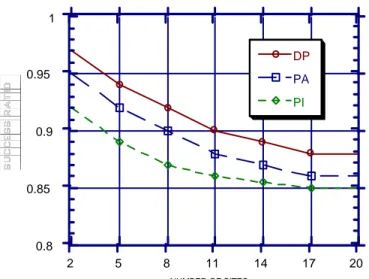
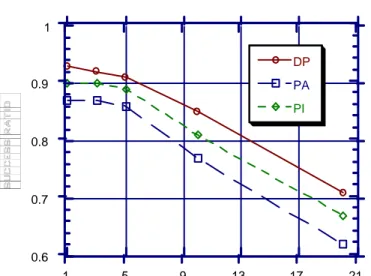
Benzer Belgeler
Our approach to the problem is motivated by its connection with triangulations of Riemann surfaces and ramified coverings.. It turns out that the last problem is
To assess the validity of the plasmon-pole approximation in Q1D systems, we display in figure 2 the static dielectric function ε(q) calculated in the RPA and the
Compared to the jagged partitioning (JP) model, the proposed hypergraph par- titioning (HP) model results in both better load balancing in the rendering phase and less total volume
For our devices, using ALD has an additional benefit that it minimizes the contamination during fabrication since the tunnel oxide, charge trap layer, and the blocking oxide all
The amplitude from the folding reaction was 65% that of the prefolded control, indicating that approximately two-thirds of the ribozyme folded to the native state with a rate
of the evolutionary approach, the mistakes jirevent any of the varic'ties, \.c. the strategies in the model, from getting extinct. The firms ¡K'rcc'ive theur own
On the other hand, before the discovery of this inscription from Ancyra and the clear proof it provides that members of the legio XXX Ulpia Victrix Pia Fidelis were in the east in
In addition to the QDs whose spectral X, trion, and BX behaviors are provided in Figure 4, we measured and obtained integrated TRF decay terms under high- intensity excitation for
