Türkçe Kelime Temsilleri için Yorumlanabilirlik
Analizi
Interpretability Analysis for Turkish Word
Embeddings
Lütfi Kerem ¸Senel
1,2,3, Veysel Yücesoy
1, Aykut Koç
1, Tolga Çukur
2,3,4 1ASELSAN Ara¸stırma Merkezi, Ankara, Turkey2Elektrik ve Elektronik Mühendisli˘gi Bölümü, Bilkent Üniversitesi, Ankara, Türkiye 3Sabuncu Beyin Ara¸stırmaları Merkezi, UMRAM, Bilkent Üniversitesi, Ankara, Türkiye
4Sinirbilimi Programı, Bilkent Üniversitesi, Ankara, Türkiye
Email: {lksenel,vyucesoy,aykutkoc}@aselsan.com.tr, [email protected]
Özetçe —Kelime temsilleri, do˘gal dil i¸sleme (DD˙I) uygula-malarında sa˘gladıkları önemli performans artı¸sları dolayısıyla günümüzde yaygın olarak çalı¸sılmakta ve kullanılmaktadır. Ke-lime temsili ö˘grenen algoritmalar, etiketsiz büyük derlemler içerisindeki kelimelerin birbirlerine yakınlık durumlarını göze-timsiz bir ¸sekilde kullanarak kelimeler arasındaki anlamsal ili¸skileri ba¸sarıyla yansıtabilen yo˘gun ve dü¸sük boyutlu vektör uzayları ö˘grenirler. Ancak bu uzaylar genellikle yorumlanabilir boyutlara sahip olmadıkları için uzayların barındırdıkları anlam-sal yapının ara¸stırmacılar tarafından anla¸sılması güçle¸smektedir. Bu uzayların iç yapılarını daha iyi anlayabilmek ve geli¸stire-bilmek için yeni, yorumlanabilir temsiller ö˘grenmek günümüzde önem kazanan ara¸stırma konularındandır. Bu çalı¸smada, kelime vektörü uzaylarının yorumlanabilirliklerini sayısal bir ¸sekilde ölçebilmek için 4000’den fazla farklı Türkçe kelimenin 62 farklı anlamsal kategoride gruplandı˘gı bir veri kümesi (ANKAT) olu¸s-turulmu¸stur. Bu veri kümesini temel alan bir yorumlanabilirlik analiz yöntemi önerilmi¸s ve 5 farklı temsil uzayında test edilmi¸stir.
Anahtar Kelimeler—döküman biçimi, stil, anahtar kelimeler. Abstract—Due to the performance improvements they pro-vided in natural language processing (NLP) applications, word embeddings are commonly studied and used. The algorithms that generate word embeddings, learn low dimensional, dense vector spaces that encode semantic relations among words in an unsupervised manner from large unannotated corpora. However, these vector spaces usually do not have interpretable dimensions making their semantic structure more challenging to be com-prehended by the researchers. To have a better understanding of the inner structures of the word embeddings and further improve their utility, learning new, interpretable word embeddings is an active research area. In this study, a semantic category dataset (ANKAT) that contains more than 4000 unique Turkish words grouped under 62 different categories is composed to quantita-tively evaluate the interpretability of the word embeddings. An interpretability analysis method based on this dataset is proposed and tested on five different embedding spaces.
Keywords—Kelime Temsilleri, Yorumlanabilirlik, Anlamsal Yapı, Do˘gal Dil ˙I¸sleme
I. G˙IR˙I ¸S
Sözdizimsel analiz (parsing), kelime anlamı açıkla¸stırma (disambiguation), makine çevirisi (machine translation), duygu analizi (semantic analysis), doküman sınıflandırma (document classification) gibi çe¸sitli do˘gal dil i¸sleme (DD˙I) uygula-malarında performansı arttırmak amacıyla kelimelerin anlam-larını ve birbirleri arasındaki ili¸skileri ö˘grenebilen modeller geli¸stirmek DD˙I literatüründe oldukça eskilere dayanan önemli bir yere sahiptir. Bu alandaki çalı¸smaların ço˘gu, bir kelimenin beraber geçti˘gi kelimeler tarafından karakterize edildi˘gini savu-nan da˘gılımsal hipoteze [1] dayanır. Latent Semantic Anal-ysis (LSA) [2] ve Latent Dirichlet Allocation (LDA) [3], bu alanda kelimelerin da˘gılım istatistiklerini temel alan yön-temler arasında en bilindik olanlarındandır. Geçmi¸ste sıklıkla kullanılmı¸s olan bu yöntemlerin yanı sıra, kelime temsilleri olarak bilinen, yo˘gun, gerçel ve dü¸sük boyutlu vektörler ö˘grenmeye yarayan yeni algoritmalar da DD˙I alanında gittikçe popülerle¸smektedir. Özellikle word2vec [4] ve GloVe [5] al-goritmalarının ortaya atılmasının ardından birçok ara¸stırmacı bu temsilleri kullanarak DD˙I uygulamalarında performansı arttırmaya çalı¸smı¸s ve ba¸sarılı sonuçlar elde etmi¸slerdir.
Literatürde kelime temsillerinin yorumlanabilirliklerini art-tırmaya ve ölçebilmeye yönelik çe¸sitli çalı¸smalar mevcuttur. Örne˘gin [6], [7] ve [8] gibi çe¸sitli çalı¸smalarda kelime vektörü uzayındaki kümelenmeler yorumlanabilirlik için kullanılmı¸stır. Ancak kelime temsilleri etiketsiz ve büyük derlemler üz-erinde çalı¸san gözetimsiz algoritmalar tarafından ö˘grenildikleri için kelimeler arasında insanlara göre var olmayan ili¸skiler ö˘grenebildikleri gibi insanların olması gerekti˘gini dü¸sündükleri ili¸skileri ö˘grenememeleri de mümkün olmaktadır [9]. Bazı di˘ger çalı¸smalarda [10], [11] ise yorumlanabilir temsiller ö˘grenmek için çe¸sitli matris faktorizasyon yöntemleri öner-ilmi¸s ve bu yöntemler ile ö˘grenilen temsillerin yorumlanabilir-li˘gi [12]’de önerilen kelime ihlal testi (word intrusion test) ile ölçülmü¸stür. Yorumlanabilirli˘gin kayna˘gını insan yargılarına dayandıran ve zahmetsiz bir de˘gerlendirme yapabilmek için kategorize ˙Ingilizce kelime veri kümesi sunmu¸s bir çalı¸sma olan [13], bu kategorilerdeki kelimelerin kelime temsili uza-yının boyutlarının uçlarında yer alıp almamasına dayalı bir yorumlanabilirlik ölçüm yöntemi önermi¸stir.
Tablo I: SEMCAT ve ANKAT’ın istatistiksel özeti
ANKAT SEMCAT
Kategori Sayısı 62 110
Toplam Farklı Kelime Sayısı 4096 6559 Kategorilerdeki Ortalama Kelime Sayısı 79 91 Kategorilerdeki Minimum Kelime Sayısı 22 20 Kategorilerdeki Maximum Kelime Sayısı 201 276
Bu çalı¸smada Türkçe kelime temsillerinin yorumlanabilir-lik derecelerini sayısal olarak, insan çabasına ihtiyaç duymadan ve yorumlanabilirli˘gin temelini insan yargılarına dayandırarak ölçmek için 4000’den fazla Türkçe kelimenin 62 farklı anlam-sal kategori altında toplandı˘gı ANKAT veri kümesi ve bu veri kümesini temel alan bir ölçüm yöntemi önerilmi¸stir. Önerilen yakla¸sım, temelini [13]’ten almasına kar¸sın yorumlanabilirlik ölçümlerini yaparken veri kümesindeki kategorilerin içerisin-deki alt kategorileri de etkin bir ¸sekilde hesaba katmaktadır. Bu sayede nispeten dü¸sük sayıda anlamca geni¸s kategori ile bu kategorilerin barındırdı˘gı çok sayıda olası anlamsal alt grup temsil edilebilmektedir. Bu çalı¸smada Türkçe’ye odak-lanılmı¸stır ancak önerilen yöntem kategorize kelimelerden olu¸san bir veri kümesine sahip herhangi bir dil için de ko-laylıkla uygulanabilir.
Bölüm II bu çalı¸sma kapsamında hazırlanan kategorize edilmi¸s veri kümesini tanıtmaktadır. Kelime temsillerini ö˘gren-mek için kullanılan derlemin ve olu¸sturulan kelime temsil-lerinin açıklandı˘gı bu bölümde, yorumlanabilirli˘gi ölçmek için önerilen yöntem de tanımlanmaktadır. Kelime temsillerinin yorumlanabilirliklerini ölçmek için gerçekle¸stirilen deneyler ve sonuçları Bölüm III’te açıklanmı¸s ve Bölüm IV’te çalı¸sma sonlandırılmı¸stır.
II. YÖNTEMLER
A. Veri Kümesi
Kelime vektörlerinin boyutlarının yorumlanabilirliklerini sayısal olarak ölçebilmek için bu çalı¸smada kategori teorisine [14] ba¸svurulmu¸stur. Bu teori kapsamında kategori, benzer an-lamsal özelliklere sahip kelimeler grubu olarak tanımlanmı¸stır. ˙Insanlar tarafından hazırlanmı¸s olan kategoriler yorumlan-abilirlik ölçümünü do˘grudan insan yargılarına dayandıracak-larından, güvenilir sonuçlar sa˘glama potansiyeline sahiptirler.
Kelime temsillerini yorumlama problemini ele alan [13], benzer bir yakla¸sımla ˙Ingilizce dili için 110 kategoriden olu¸san SEMCAT kategori veri kümesini önermi¸stir. Bildi˘gimiz kadarıyla Türkçe için benzer bir veri kümesi mevcut de˘gildir. Bu nedenle, bu çalı¸sma kapsamında 4000’den fazla birbirinden farklı Türkçe kelimenin 62 farklı kategori altında gruplandı˘gı ANKAT1 (ANlamsal KATegori) kategori veri kümesi
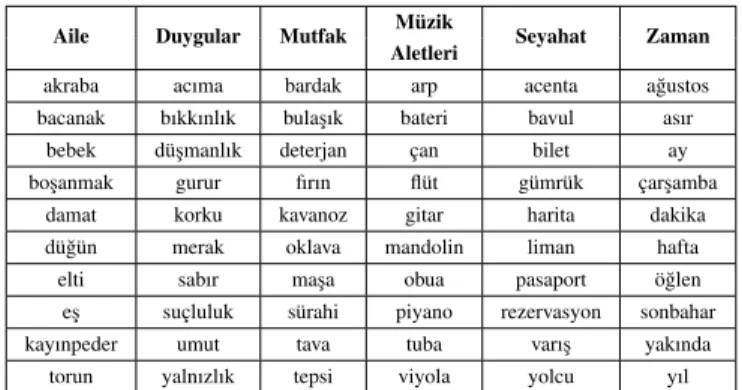
olu¸stu-rulmu¸stur. SEMCAT ile ANCAT’ın istatistiksel özetleri Tablo I’de, ANKAT veri kümesinden seçilen 6 kategoriden 10’ar örnek kelime ise Tablo II’de verilmi¸stir.
B. Kelime Temsilleri
1) Derlem ve Ön ˙I¸sleme: Kelime temsilleri ile ilgili yapılan çalı¸smalarda, Wikipedia’nın makale içerikleri sıklıkla kelime temsillerini ö˘grenmek için derlem olarak kullanılmaktadır. Bu çalı¸smada Türkçe Wikipedia’daki2bütün sayfalar ve makaleler
kelime vektörlerini ö˘grenmek için derlem olarak seçilmi¸stir.
1github.com/avaapm/ANKATdataset2018 216.01.2018 tarihinde eri¸silmi¸stir.
Tablo II: 6 temsili ANKAT kategorisinden 10’ar örnek kelime.
Aile Duygular Mutfak Müzik Seyahat Zaman
Aletleri
akraba acıma bardak arp acenta a˘gustos
bacanak bıkkınlık bula¸sık bateri bavul asır
bebek dü¸smanlık deterjan çan bilet ay
bo¸sanmak gurur fırın flüt gümrük çar¸samba
damat korku kavanoz gitar harita dakika
dü˘gün merak oklava mandolin liman hafta
elti sabır ma¸sa obua pasaport ö˘glen
e¸s suçluluk sürahi piyano rezervasyon sonbahar
kayınpeder umut tava tuba varı¸s yakında
torun yalnızlık tepsi viyola yolcu yıl
Türkçe gibi sondan eklemeli olan dillerde kelimeler metinlerin içinde aldıkları çekim ve yapım ekleri sayesinde çok çe¸sitli ¸sekillerde bulunabilirler. Bu durum çok büyük derlemler için sorun olu¸sturmasa da Türkçe Wikipedia gibi görece küçük boyuttaki derlemlerde olası kelime sayısını arttırırken, her bir kelimenin derlem içerisinde görülme sayısını önemli derecede dü¸sürdü˘günden kaliteli vektör ö˘grenimini zorla¸stırmaktadır [15]. Bu problemi çözmek için cümle seviyesinde belirsiz-lik giderme yöntemleri denenmektedir ancak bu yöntemlerin performansları problemin zorlu˘gu sebebiyle oldukça sınırlıdır. Bu çalı¸smada derlemdeki kelimelerden çekim eklerini kaldır-mak amacıyla zemberek3 kütüphanesi kullanılmı¸stır. Bunun
yanı sıra alfabetik veya sayısal olmayan bütün karakterler kesme i¸sareti ile ayrılmı¸s olan ekler ile birlikte derlemden atılmı¸stır. Ön i¸sleme adımlarından geçtikten sonra elde edilen derlem 820.446 tanesi birbirinden farklı olmak üzere toplam 50.855.950 kelimeden olu¸smaktadır
2) Türkçe Kelime Temsilleri: Bu çalı¸smada yorumlanabilir-lik analizini test edebilmek için 5 farklı kelime vektörü uzayı ö˘grenilmi¸s veya olu¸sturulmu¸stur.
• Rastgele: Yorumlanabilirlik ölçümü yönteminin taban çizgisini temsil etmesi için standart normal da˘gılımdan örneklenerek olu¸sturulan 300 boyutlu vektörlerdir. • Word2vec: Ön i¸slemeden geçen derlem üzerinde
word2vec algoritmasının skip-gram modeli kul-lanılarak ö˘grenilmi¸s 300 boyutlu vektörlerdir. • GloVe: Ön i¸slemeden geçen derlem üzerinde GloVe
algoritması kullanılarak ö˘grenilmi¸s 300 boyutlu vek-törlerdir.
• I: [13]’te açıklandı˘gı ¸sekilde, GloVe ile ö˘grenilmi¸s olan kelime vektörlerinin standart hale getirildikten sonra Bhattacharya uzaklık metri˘gi [16] ile hesaplanan ve normalize edilen kategori vektörleri4 (a˘gırlıkları) üzerine yansıtılması ile elde edilmi¸s 62 boyutlu vek-törlerdir.
• I∗: [13]’te açıklandı˘gı ¸sekilde, GloVe ile ö˘grenilmi¸s
olan kelime vektörlerinin kategorilerin içerisindeki kelimelerin4 ortalama vektörleri üzerine yansıtılması ile elde edilmi¸s 62 boyutlu vektörlerdir.
3https://github.com/ahmetaa/zemberek-nlp
4Bu i¸slemin öncesinde, derlemde en sık geçen 50.000 kelime arasında
C. Yorumlanabilirlik Analizi
Kelime temsillerinin yorumlanabilirlikleri [13]’te kategori veri kümesi kullanılarak (1)’de gösterildi˘gi ¸sekilde hesaplan-mı¸stır. ISi,j+ = |Sj∩ V + i (λ × nj)| nj × 100 ISi,j− = |Sj∩ V − i (λ × nj)| nj × 100 ISi,j= max(IS+i,j, IS
− i,j) ISi= max j ISi,j, IS = 1 D D X i=1 ISi (1)
Bu denklemde ISi,j+ ve ISi,j− kelime temsil uzayının i. boyutunun (i ∈ {1, 2, ..., D}, D temsil uzayındaki boyut sayısı) j. kategori için (j ∈ {1, 2, ..., K}, K veri kümesin-deki kategori sayısı) sırasıyla pozitif ve negatif yönlerde aldı˘gı yorumlanabilirlik skorlarına kar¸sılık gelmektedir. Sjveri
kümesideki j. kategorinin içerisindeki kelimelerin olu¸sturdu˘gu küme, njise j. kategorideki kelime sayısıdır. Vi(λ×nj) temsil
uzayının i. boyutunda en yüksek (Vi+) ve en dü¸sük (Vi−) de˘gerlere sahip λ × nj adet kelimenin olu¸sturdu˘gu kümedir.
Bu denklemde, ISi kelime temsil uzayının i. boyutunun
yorumlanabilirlik skorunu, IS ise temsil uzayının ortalama yorumlanabilirlik skorunu temsil etmektedir.
Bu yöntem ile yorumlanabilirlik ölçümü yapılırken katego-rilerdeki kelimelerin, kelime temsili uzayının boyutlarındaki pozitif ve negatif yönlerde ne kadar ayırt edici bir konuma sahip oldu˘guna (bu kelimelerin ne kadar uçlarda yer aldık-larına) bakılmı¸stır. Denklemlerdeki λ parametresi ise yorum-lanabilirlik algısının ne kadar sert ya da gev¸sek olaca˘gını belirlemek için kullanılmı¸stır. Ancak bu yöntem ile hesaplanan yorumlanabilirlik de˘gerleri veri kümesindeki kategori sayısın-dan ve kategorilerin içeriklerinden oldukça etkilenmektedir. [13]’te de bahsedildi˘gi gibi yorumlanabilirlik ölçümünün insan yargılarını tam olarak yansıtabilmesi için neredeyse sınırsız sayıda kategori gerekmektedir. Böyle bir veri kümesi olu¸s-turabilmek olası görünmese de, az sayıda kategori ile yo-rumlanabilirlik ölçümünde benzer bir performansı elde etmek mümkün olabilir. Bunu ba¸sarabilmek için bu çalı¸smada alt kategori kavramına odaklanılmı¸stır.
SEMCAT ve ANKAT veri kümelerindeki kategoriler nispe-ten çok sayıda kelime içermektedirler. Ancak bu anlamca geni¸s konseptler içlerinde insanlar tarafından yorumlanabilir, sınırları daha dar konseptleri de barındırabilirler. Örne˘gin ANKAT veri kümesindeki Ölçü kategorisi 179, Ülkeler kategorisi 100 farklı kelime içermektedir. Yorumlanabilirlik derecesi (1) kul-lanılarak ölçüldü˘günde kelime temsili uzayındaki bir boyutun bu iki kategoriden birinde yüksek skor alabilmesi için çok sayıda kategori kelimesinin pozitif veya negatif uçlara yer-le¸smi¸s olması gerekmektedir. Ancak bir boyut, ölçü veya ülke kategorisindeki bütün kelimeler yerine bu kategorilerin sadece bir altkümesini (örne˘gin a˘gırlık ölçüleri veya Amerika kıtasın-daki ülkeler) ayırt etmeyi ö˘grenmi¸s olabilir. Bu boyut insanlar tarafından rahatlıkla yorumlanabilecek olmasına kar¸sın ölçüm yöntemi sebebi ile dü¸sük skor alacaktır.
N kelime içeren bir kategoriden elde edilecek alt kate-goriler N farklı uzunlukta olabilirler (n ∈ {1, 2, . . . , N }). Ancak çok az sayıda kelime içeren alt kategorilerin (örne˘gin
¸Sekil 1: 5 farklı kelime temsili uzayının alt kategoriler kul-lanılarak hesaplanan ortalama yorumlanabilirlik de˘gerlerinin nmin = 12 için λ’ya göre de˘gi¸simi gösterilmektedir.
n = 1 gibi) gerçek bir kategori olarak dü¸sünülmek için yeter-siz oldukları savunulabilir. Bu durumu engellemek amacıyla kategori olu¸sturmak için gerekli minimum kelime sayısı be-lirlenebilir (n ∈ {nmin, nmin + 1, . . . , N }). Alt kategori
yakla¸sımına uygulanabilir bir sayısal karma¸sıklık kazandırmak için en az nmin kelime barındıran bütün olası alt kategorileri
denemek yerine, her bir n de˘geri için bir boyutun pozitif ve negatif uçlarındaki n × λ adet kelimenin arasında ilgili kategoriden kaç kelimenin yer aldı˘gına bakılarak boyutun yo-rumlanabilirli˘gi hesaplanabilir. Bu amaçla (1), alt kategorileri de hesaba katacak ¸sekilde de˘gi¸stirilerek (2) elde edilmi¸stir.
ISi,j+ = max nmin≤n≤nj |Sj∩ Vi+(λ × n)| n × 100 ISi,j− = max nmin≤n≤nj |Sj∩ Vi−(λ × n)| n × 100 ISi,j= max(ISi,j+, IS
− i,j) ISi= max j ISi,j, IS = 1 D D X i=1 ISi (2)
Bu yöntem ile 100’den daha büyük ISi,j+ de˘gerleri elde edilebilir ancak bu de˘gerler 100 olarak alınmı¸stır.
III. DENEYLER
5 farklı Türkçe kelime temsil uzayı (Rastgele, word2vec, GloVe, I, I∗) olu¸sturulduktan sonra, ANKAT veri kümesi ve kelime temsilleri sadece derlemde en sık geçen 50.000 kelimeyi içerecek ¸sekilde filtrelenmi¸stir. Sonrasında 5 farklı kelime temsili için ortalama yorumlanabilirlik skorları farklı λ (λ ∈ {1, 2, 3, 4, 5, 6, 7, 8}) ve nmin (nmin ∈ {5, 10, 12, 15})
de˘gerleri için (2) kullanılarak hesaplanmı¸stır. ¸Sekil 1 nmin=12
için hesaplanan yorumlanabilirlik skorlarını göstermektedir. Rastgele olarak olu¸sturulan vektör uzayı bütün λ de˘gerleri için beklendi˘gi gibi neredeyse hiç yorumlanabilirlik skoru alamamı¸stır. Popüler GloVe ve word2vec kelime temsillerinin de yorumlanabilirliklerinin çok dü¸sük seviyede ve taban çizgi-sine yakın oldu˘gu görülmektedir. GloVe ile ö˘grenilen kelime temsillerinin, [13]’te açıklanan ¸sekilde, Bhattacharya uzaklık
Tablo III: Ortalama Yorumlanabilirlik Skorları (%) λ 1 2 3 4 5 6 7 8 nmin = 5 Rastgele 0,0 0,2 0,9 2,2 3,8 5,2 6,5 7,5 Word2vec 1,1 3,7 7,1 10,4 13,3 16,3 18,9 21,4 GloVe 0,8 3,0 6,1 9,1 12,0 15,0 17,5 19,9 I 71,4 96,3 99,3 99,7 100 100 100 100 I∗ 57,4 86,9 93,8 96,9 98,6 98,8 99,2 99,5 nmin = 10 Rastgele 0,0 0,0 0,0 0,0 0,0 0,1 0,4 0,8 Word2vec 0,2 0,8 1,6 3,5 5,5 7,5 9,9 12,1 GloVe 0,0 0,5 1,2 2,5 4,1 5,9 7,9 9,9 I 58,0 90,6 96,0 98,1 99,3 99,7 100 100 I∗ 46,3 76,5 85,9 90,5 93,9 95,7 97,0 98,1 nmin = 15 Rastgele 0,0 0,0 0,0 0,0 0,0 0,0 0,0 0,0 Word2vec 0,1 0,1 0,5 0,9 1,7 2,9 4,2 5,4 GloVe 0,0 0,0 0,4 0,9 1,5 2,5 3,2 4,5 I 42,9 79,5 92,1 96,2 97,8 98,3 98,8 99,3 I∗ 31,9 63,0 78,8 85,6 89,8 93,0 94,7 96,0
metri˘gi kullanılarak hesaplanan kategori vektörlerine ve kat-egori merkezlerine yansıtılması ile elde edilen ve boyutları ANKAT’taki kategorilere kar¸sılık gelen I ve I∗ uzayları beklenildi˘gi gibi oldukça yüksek yorumlanabilirlik skorları elde etmi¸slerdir.
Bir kategori olu¸sturmak için gerekli minimum kelime sayısının belirli bir de˘geri olmadı˘gından farklı nmin
de˘ger-leri kullanılarak kelime temsilde˘ger-leri için farklı yorumlanabilir-lik ölçümleri yapılabilir. Tablo III, nmin=5, 10, 15 için
ke-lime temsillerinin bu çalı¸smada önerilen yöntem ile ölçülen yorumlanabilirlik de˘gerlerini göstermektedir. nmin de˘geri
küçüldükçe rastgele olu¸sturulan kelime vektörlerinin, özellikle yüksek λ de˘gerleri için, giderek yükselen yorumlanabilirlik de˘gerleri aldı˘gı gözlemlenebilir. Rastgele olu¸sturulan tem-sillerde bile bazı boyutlarda bir kategoriye ait az sayıda kelime ¸sans eseri uçlara yakın pozisyonlara denk gelebilir. Dü¸sük nmin de˘gerlerinde çok az sayıda kategori kelimesinin uçlara
yakın olması yorumlanabilirlik açısından yeterli görüldü˘gün-den bu duruma negörüldü˘gün-den olmaktadır. Deneyler sonucunda 10 ile 15 arasındaki nmin de˘gerlerinin yorumlanabilirlik analizi
için uygun de˘gerler oldu˘gu sonucuna varılabilir. Bir kategoriyi tanımlamak için en az 10-15 kelimeye ihtiyaç duyulmasının da mantıksal oldu˘gu savunulabilir.
IV. TARTI ¸SMA VESONUÇ
Bu çalı¸smada Türkçe kelime temsillerinin yorumlanabilir-lik derecelerini sayısal olarak ölçmek için 4000’den fazla farklı Türkçe kelimenin 62 farklı anlamsal kategori altında toplandı˘gı ANKAT veri kümesi ve bu veri kümesini temel alan bir yöntem önerilmi¸stir. Önerilen yöntem yorumlanabilirlik ölçümlerinin temelini insan yargılarına dayandırması yönünden literatürdeki kelime temsili boyutlarındaki kümelenmeleri kullanan yöntem-lerden; ölçümlerde insan eforuna ihtiyaç duymaması açısından insan de˘gerlendirmelerini kullanan kelime ihlal testinden; veri kümesindeki kategorilerin içerisindeki alt kategorileri de kul-lanması açısından di˘ger kategori temelli yöntemlerden avan-tajlıdır. Önerilen yöntemin yenilikçi yönü, yorumlanabilirlik ölçümlerini yaparken veri kümesindeki kategorilerin içerisin-deki alt kategorileri de insan çabasına ihtiyaç duymadan etkin bir ¸sekilde kullanmasıdır. Bu sayede 62 gibi nispeten dü¸sük sayıda kategori ile çok sayıda olası anlamsal grup temsil edilebilmektedir. Bu çalı¸smada Türkçe’ye odaklanılmı¸s olsa da önerilen yöntem kategorize kelimelerden olu¸san bir veri
kümesine sahip herhangi bir dildeki kelime temsillerinin yo-rumlanabilirliklerini ölçmek için kullanılabilir.
Önerilen yöntem 5 farklı Türkçe kelime temsilinin yorum-lanabilirlik derecelerini ölçmek için kullanılmı¸stır. Türkçenin sondan eklemeli yapısının kelime temsili ö˘grenimi için yarat-tı˘gı olumsuz etkilerden kurtulmak için Türkçe Wikipedia içerisindeki çekim eklerinin kelimelerden atılması gibi çe¸sitli ön i¸sleme adımları kullanılmı¸stır. Ön i¸slemeden geçen Türkçe Wikipedia derlemi üzerinde word2vec ve GloVe algoritmaları çalı¸stırılarak Türkçe kelime temsilleri ö˘grenilmi¸stir. GloVe ile ö˘grenilen temsiller ve kategori veri kümesi kullanılarak I ve I∗ temsilleri olu¸sturulmu¸stur. Son olarak önerilen yöntemin
taban çizgisini belirlemek için normal da˘gılımdan örneklenen sayılar ile rastgele bir temsil uzayı olu¸sturulmu¸stur. Önerilen yöntem 5 farklı temsil uzayının yorumlanabilirlik seviyelerini ölçmek için kullanılmı¸stır. Elde edilen sonuçlar önerilen yön-tem ile kelime yön-temsillerinin yorumlanabilirlik seviyelerinin ba¸sarılı bir ¸sekilde ölçülebilece˘gini desteklemektedir.
TE ¸SEKKÜR
Bu çalı¸sma kısmi olarak EMBO IG 3028, TÜBA-GEB˙IP ve Bilim Akademisi’nin BAGEP 2017 ödülü tarafından destek-lenmi¸stir.
KAYNAKÇA
[1] Z. S. Harris, “Distributional structure,” Word, vol. 10, no. 2-3, pp. 146– 162, 1954.
[2] S. Deerwester, S. T. Dumais, G. W. Furnas, T. K. Landauer, and R. Harshman, “Indexing by latent semantic analysis,” Journal of the American society for information science, vol. 41, no. 6, p. 391, 1990. [3] D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichlet allocation,”
Journal of Mach. Learn. Res., vol. 3, no. Jan, pp. 993–1022, 2003. [4] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of
word representations in vector space,” arXiv preprint arXiv:1301.3781, 2013.
[5] J. Pennington, R. Socher, and C. Manning, “Glove: Global vectors for word representation,” in Proceedings of EMNLP, 2014, pp. 1532–1543. [6] A. Zobnin, “Rotations and interpretability of word embeddings: the case
of the russian language,” arXiv preprint arXiv:1707.04662, 2017. [7] S. Arora, Y. Li, Y. Liang, T. Ma, and A. Risteski, “Linear algebraic
structure of word senses, with applications to polysemy,” arXiv preprint arXiv:1601.03764, 2016.
[8] M. Faruqui, Y. Tsvetkov, D. Yogatama, C. Dyer, and N. Smith, “Sparse overcomplete word vector representations,” arXiv preprint arXiv:1506.02004, 2015.
[9] A. Gladkova, A. Drozd, and C. Center, “Intrinsic evaluations of word embeddings: What can we do better?” ACL 2016, p. 36, 2016. [10] B. Murphy, P. Talukdar, and T. Mitchell, “Learning effective and
interpretable semantic models using non-negative sparse embedding,” Proceedings of COLING 2012, pp. 1933–1950, 2012.
[11] H. Luo, Z. Liu, H.-B. Luan, and M. Sun, “Online learning of inter-pretable word embeddings.” in EMNLP, 2015, pp. 1687–1692. [12] J. Chang, S. Gerrish, C. Wang, J. L. Boyd-Graber, and D. M. Blei,
“Reading tea leaves: How humans interpret topic models,” in Advances in NIPS, 2009, pp. 288–296.
[13] L. K. Senel, I. Utlu, V. Yucesoy, A. Koc, and T. Cukur, “Semantic structure and interpretability of word embeddings,” arXiv preprint arXiv:1711.00331, 2017.
[14] G. Murphy, The big book of concepts. MIT press, 2004.
[15] E. Yildiz, C. Tirkaz, H. B. Sahin, M. T. Eren, and O. Sonmez, “A morphology-aware network for morphological disambiguation,” arXiv preprint arXiv:1702.03654, 2017.
[16] A. Bhattacharyya, “On a measure of divergence between two statistical populations defined by their probability distribution,” Bull. Calcutta Math. Soc, 1943.