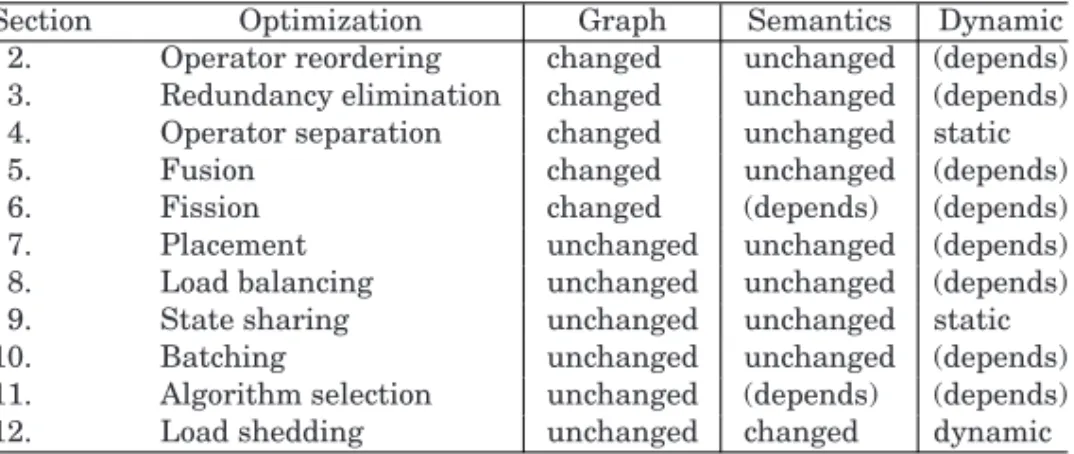
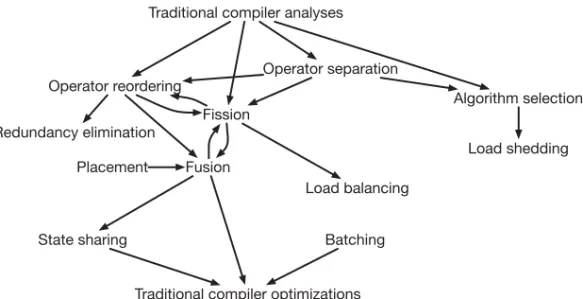
A catalog of stream processing optimizations
Tam metin
Şekil

Benzer Belgeler
The results of the examination of the relationship between teacher candidates’ attitudes toward teaching profession and teaching-learning process competencies
We have further given a pseudo-polynomial time dynamic program (DP_OPT) and an FPTAS (DP_APX) for the exact and the approximate solution, respectively, of WMAD_WMC. We have
Molecular analysis of human HCC has shown many epigenetic alterations that result in the deregulation of several oncogenes and tumor suppressor genes including TP53, β – catenin,
The arguments in the book are based on the public surveys and data that Taylor received from Pew Research Center, an indepen- dent think that provides knowledge and data in
The implemented forces, which have an impact on the motion of the hair strands, are spring forces, grav- ity, repulsions from collisions (head and ground), ab- sorption (ground
This study begins by examining the transformation of the middle-class Turkish living room through this closed-salon practice, considered a powerful and dominant custom in
For the city, I say that during that time when Sultan Mehmed came to fight this very city, the emperor Constantine Palaiologos, his archontes and the people prostrated
Figure 2(a) shows the measured transmission spectra of periodic SRRs (solid line) and CSRRs (dashed line) between 3-14 GHz.. The second bandgap (8.1-11.9 GHz) is present for both
