Robotic task planning using a backchaining theorem prover for multiplicative exponential first-order linear logic
Tam metin
Şekil
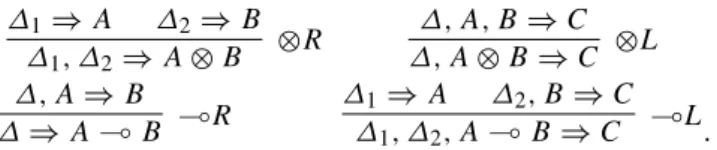






Benzer Belgeler
Bu çalışmada, 2002-2007 yılları arasında Selçuk Üniversitesi Meram Tıp Fakültesi çocuk psikiyatrisi polikliniğine başvuran çocuk ve ergen hastaların
Exceptions where both mean vectors and full covariance matrices were used include [4 , 5 ] where EM was used for the actual local optimization by fitting Gaussians to data in
Single-layer, bilayer, multilayer, and layered periodic structures derived from freestanding SL structures may be stable and display properties gradually 473 25.1 Motivation
Although the fellow eye retina of study group seemed inflamed and edematous in H&E stained sections, TUNEL staining revealed no apop totic changes. Therefore, we
We prove that there exists a critical value of initial stock, in the vicinity of which, small differences lead to permanent differences in the optimal path.. Indeed, we show that
The most important commonality between the reformist Western tradition that both includes the social democrats and the communists and the revolutionary movements
Nevrûz gicesi, 22 Mars 1947 mürşidi Ahmed Sırrı Baba, rehberi Ergirili Dervîş Lütfî.. 85- Fâtıma Şâkir: Kemâl
13-14 Nisan 2017 tarihinde yapacağımız Beton 2017 Kongresi’nde; beton bileşenleri, üretimde ve yerinde nitelik denetimi, özel beton- lar, özel projelerde beton tasarım
