Characterizing Gnutella network properties for peer-to-peer network simulation
Tam metin
Şekil
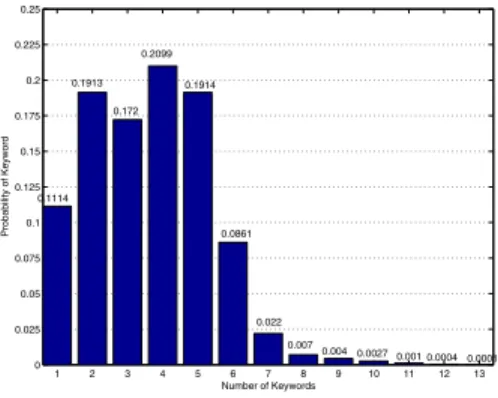

Benzer Belgeler
An cak böyle bir inanç, maddî müşküllerin üstündeki cemiyet dışı görülüşe taham mül kuvveti verebilirdi, işte Vasfi Rıza Zobu, bizim daha önce
Patolojik meme başı akıntısı olan hastanın değer- lendirilmesinde, anamnez ve fizik muayeneyi takiben duktal orientasyonlu ultrasonografi (US), mamografi (MG), galaktografi,
Sevkiyat verimliliği optimi- zasyonu aslında beton üreticileri için yatırımın geri dönüşü (ROI) anlamına gelmez, çünkü ROI daha çok beton üre- ticisi ile nakliye
Tüm uygulama gruplarının kontrol grubuna kıyasla cGMP miktarında artış sağladığı belirlenirken 100 µM GA ve 100 µM IAA uygulamaları uygulama süresinin artmasıyla
Günümüze ka- dar yap›lan ve yak›n gelecekte yap›lmas› planlanan uzay çal›flmalar›, bu gezegenleraras› yolculuklara haz›r- l›k niteli¤inde.. Üstelik, bu
Alman bu Örnekte X- iğin bulunan standart sapma değerleri çok küçüktür ve bu nedenle de göz önüne alınmayabilirler. Bununla beraber ef er standart sapma miktarları ortalama
18 Belirli bir tarihsel dönemi veya o dönemdeki toplumsal haritayı incelemek isteyen sosyal tarihçilerin malzeme deposu, toplumda siyasal bilinç oluşturmak için edebî eseri bir
Tedavi bitiminde FREMS ve TENS tedavisi grubundaki hastaların bel ve bacak ağrısı VAS, Oswestry Dizabilite Skoru, Roland-Morris Dizabilite Skoru, lateral fleksiyon ve el parmak-
