Anomaly detection in time series
Tam metin
Şekil


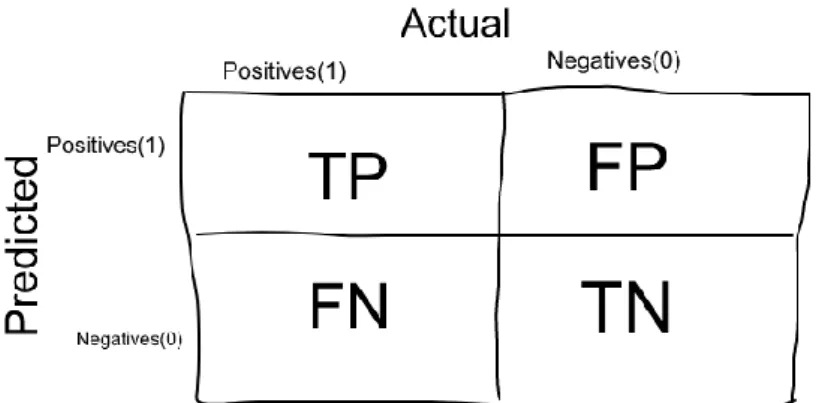
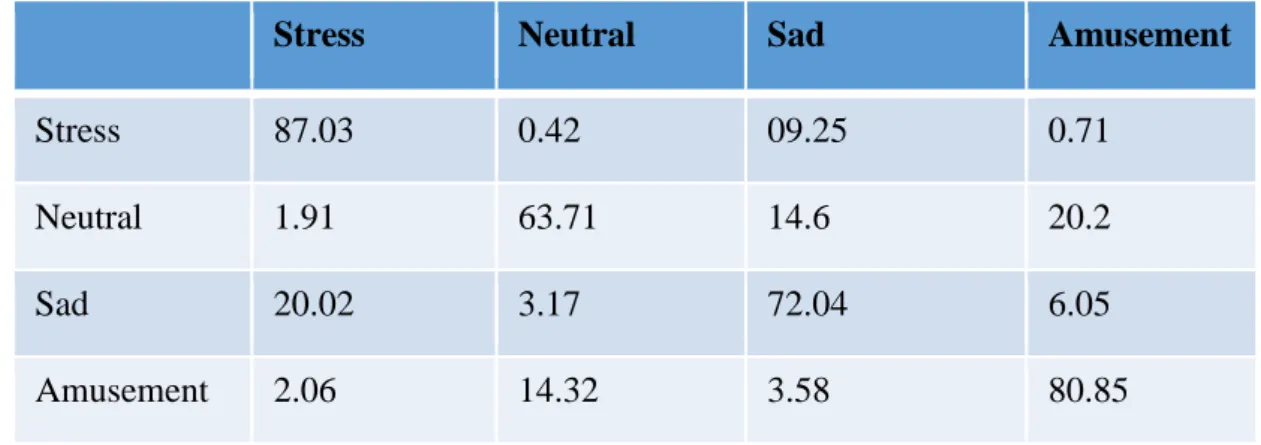
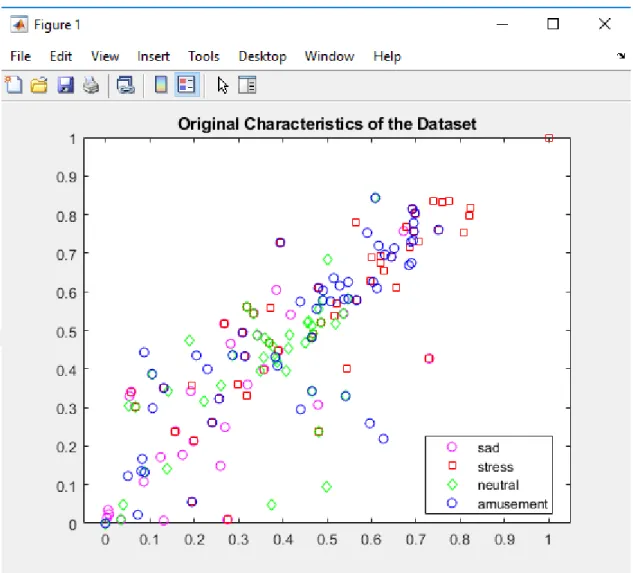
Benzer Belgeler
Gebeliğin sezaryan yolu ile erken dünyaya getirilmesi ve sonrasında nöroşirürjikal müdahalenin gerçekleştirilmesi anne adayının sağlığı ve tedavi ekibinin
Yatırım teşvik belgesi çerçevesinde stratejik yatırımlar, büyük ölçekli yatırımlar ve bölgesel yatırımlar kapsamında yapılan yatırım ile sağlanan ilave istihdam
İttir efsaneye nazaran, Yeni dünyadaki kahve ağaçlarının dedesi, Cavadaki kah~ ve plantasyonlarından celbedilen bir tek kahve ağacıdır.. Bu, hediye olarak
cındaki Ruvayal çikolata fabrikasının yerinde gündüzleri yemek, akşamla rı türlü mezelerle içki verilen (İs- ponik), üst yanında (Bizans) biraha neleri
11 Temmuz 1890 (23 Zilkade 1307) tarihinde Beyrut Vilayetine yazılan yazıda Nusayrîlerle ilgili olarak yapılacaklar şu şekilde ifade edilir: Lazkiye Sancağının Markab
Millî Mücadelede giydiği res mî elbise, kalpağı, çizmesi, foti ni, Sivas Kongresinde üzerinde bulunan caket, Büyük Nutkunu okuduğu zaman giydiği Redin
[r]
Yukarıdaki kenar uzunlukları 12 cm ve 5 cm olan dikdörtgen şeklindeki kartondan kenar uzunluğu 3 cm olan kare biçimindeki bir karton kesilerek çıkarılmıştır.
