An investigation of effects on hierarchical clustering of distance measurements
Tam metin
Şekil
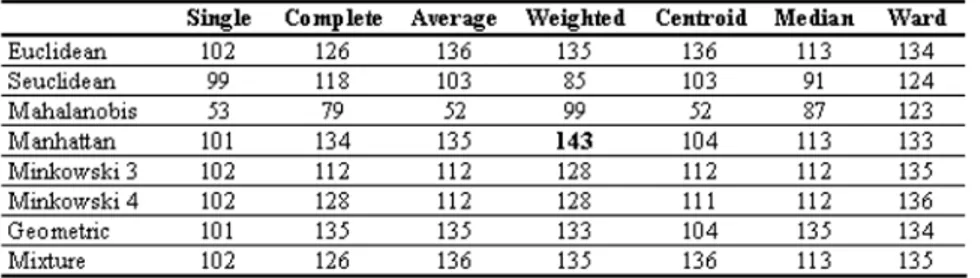

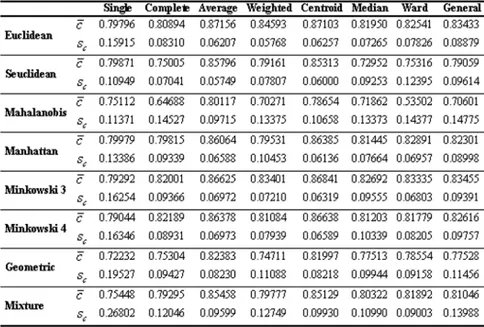
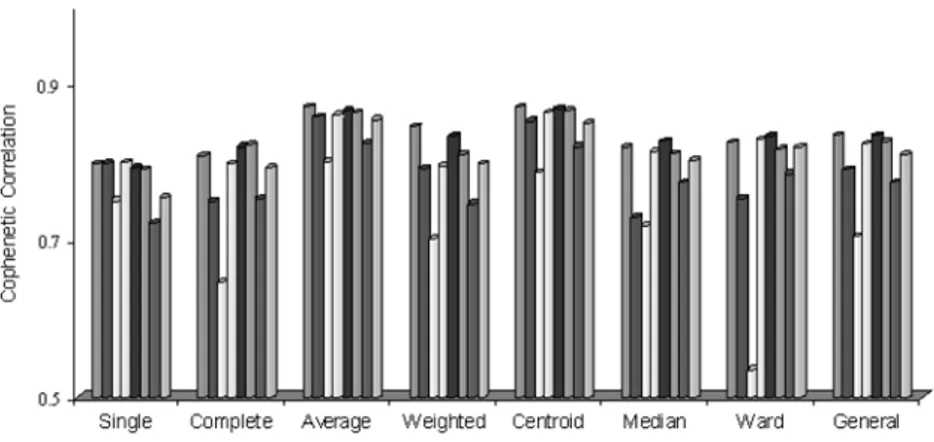
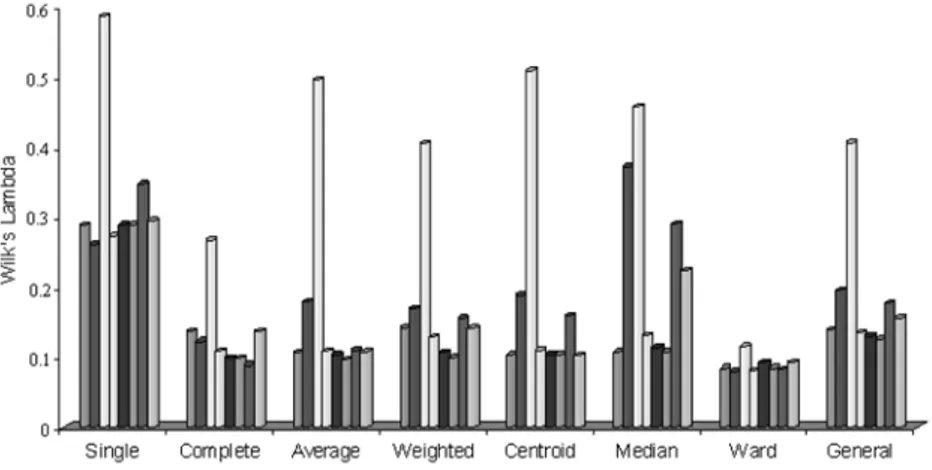
Benzer Belgeler
During the early stages of Ottoman history, the greatest threat to central authority of the sultan came from the frontiers. Ottoman beys of the marches might have
ABSTRACT: We report on the full-wave analyses of a frequency reconfigurable antenna integrated with metallic nanoelectromechanical system (NEMS) switches (length ¼ 3 lm, width ¼ 60
of this hologram will yield a 3-D frame. To obtain a sample of the resultant frame by simulation, two more simulation steps must be added to the steps described in the
These include pancreaticoduodenectomy (Whipple procedure), distal pancrea- tectomy, and central pancreatectomy. This is because such surgical procedure allows for organ tissue
Furthermore, it can also be seen that the coefficient of the interaction term that accounts for the effect of lagged inflation on expected inflation controlling for the level
Through merging Glitch Art and 360-degree video, ‘Reciprocal Reality’ project aims to create a VR-like experience while leaving the meaning of it to the spectator, at
Orta Doğu Teknik Üniversitesi Fizik Bölümü Kurucu Öğretim Üyelerinden, seçkin insan, büyük bilim adamı, değerli
Nestor İskender’in yazdığı kabul edilen “Çar Şehrinin Öyküsü (Şehrin Kuruluşu ve 1453 Yılında Türk- ler Tarafından Alınışı)” adlı tarih-savaş
