SELÇUK ÜNĠVERSĠTESĠ FEN BĠLĠMLERĠ ENSTĠTÜSÜ
TRANSFER ÖĞRENMEDE YENĠ YAKLAġIMLAR
BarıĢ KOÇER DOKTORA TEZĠ
Bilgisayar Mühendisliği Anabilim Dalı
Mart 2012 KONYA Her Hakkı Saklıdır
DECLARATION PAGE
I hereby declare that all information in this document has been obtained and presented in accordance with academic rules and ethical conduct. I also declare that, as required by these rules and conduct, I have fully cited and referenced all material and results that are not original to this work.
Barış KOÇER Tarih:
iv
ÖZET DOKTORA TEZĠ
TRANSFER ÖĞRENMEDE YENĠ YAKLAġIMLAR BarıĢ KOÇER
Selçuk Üniversitesi Fen Bilimleri Enstitüsü Bilgisayar Mühendisliği Anabilim Dalı
DanıĢman: Prof. Dr. Ahmet ARSLAN 2012, 86 Sayfa
Jüri
Prof. Dr. Ahmet ARSLAN Prof. Dr. Bekir KARLIK Prof. Dr. Saadetdin HERDEM Prof. Dr. Novruz ALLAHVERDĠ Yrd. Doç. Dr. Mesut GÜNDÜZ
Klasik makine öğrenmesi teknikleri, sadece yeterli miktarda ve uygun eğitim verisi olduğunda verimli çalışabilmektedir. Gerçek hayatta ise makine öğrenmesi yöntemlerini tam anlamıyla verimli bir şekilde çalıştıracak, tüm durumları kapsayan eğitim verisi bulmak bazı durumlarda zor, bazı durumlarda ise maliyetli bir iştir. Ayrıca koşulların değişmesiyle eldeki eğitim verisi güncelliğini kaybederek artık kullanılamaz duruma da gelebilir. Bu gibi durumlarda benzer görevler arası bilgi alışverişine olanak sağlayarak makine öğrenmesi için gerekli eğitim verisine olan ihtiyacı azaltmaya çalışan yaklaşımların bütününe ―Transfer Öğrenme‖ denir. Bu tez çalışmasında transfer öğrenmeye, optimizasyon problemleri penceresinden bakılarak yeni yaklaşımlar geliştirilmiştir. Ayrıca optimizasyon problemleri için geliştirilen yaklaşımları sınıflandırma problemlerinde de kullanabilmek amacıyla genetik algoritmalar - yapay sinir ağları hibrit yaklaşımı kullanılmıştır. Bu çalışmalara ek olarak ―örnek transferi‖ yaklaşımı için genetik algoritmalardan faydalanılarak yeni bir ağırlıklandırma metodu geliştirilmiştir. Son olarak, transfer öğrenme yaklaşımlarından ―parametre transferi‖ ve ―örnek transferi‖ yaklaşımları birleştirilerek yüksek performanslı bir transfer yaklaşımı geliştirilmiş ve mevcut yöntemle karşılaştırılmıştır. Sonuç olarak bu tez çalışmasında transfer öğrenmenin temel sorunlarına çözüm olabilecek ve transfer öğrenmenin performansını arttırabilecek yeni yaklaşımlar ortaya konulmuş, transfer öğrenmenin avantajlarının optimizasyon problemlerinde de kullanılabilmesine olanak sağlayacak yöntemler geliştirilmiştir.
Anahtar Kelimeler: Genetik algoritmalar, Hibrit algoritmalar, Transfer öğrenme, Yapay sinir ağları.
v
BarıĢ KOÇER
THE GRADUATE SCHOOL OF NATURAL AND APPLIED SCIENCE OF SELÇUK UNIVERSITY
THE DEGREE OF DOCTOR OF PHILOSOPHY IN COMPUTER ENGINEERING
Advisor: Prof. Dr. Ahmet ARSLAN 2012, 86 Pages
Jury
Prof. Dr. Ahmet ARSLAN Prof. Dr. Bekir KARLIK Prof. Dr. Saadetdin HERDEM Prof. Dr. Novruz ALLAHVERDĠ Asst. Prof. Dr. Mesut GÜNDÜZ
Traditional machine learning techniques can work efficiently if it has enough training data. But in some cases, it is may be difficult or costly to find suitable training data which provides machine learning techniques work efficiently. Also, training data may become outdated because of changed conditions and so it can't be used in new case. Approaches which try to transfer knowledge between related domains to reduce the need for training data in machine learning are named as ―Transfer Learning‖. In this thesis, transfer learning is evaluated for optimization problems by developing new approaches. Proposed approaches are also applied to classification problems by genetic algorithms - artificial neural network hybrid approaches. Additionaly a new weighting method for instance transfer is also proposed by using genetic algorithms. Finally in this thesis a high performance transfer learning approach is developed by combining two transfer learning approaches, "instance transfer" and "parameter transfer" and the test results are compared to existing approach. As the result, new approaches which can solve the main problems of transfer learning and improve the performance of the transfer learning are proposed and it is also provided to take advantage of transfer learning methods for optimization tasks.
vi
ÖNSÖZ
Öncelikle bu tez çalışmamda bana rehber olması ve katkılarından dolayı saygıdeğer danışman hocam Prof. Dr. Ahmet ARSLAN’a teşekkürü borç bilirim.
Tezimi hazırlarken fikirleriyle beni yönlendiren, eksiklerimi görüp tez çalışmamı iyileştirmemi sağlayan, tez izleme komitesi üyeleri hocalarım Prof. Dr. Saadetdin HERDEM ve Yrd. Doç. Dr. Mesut GÜNDÜZ’e teşekkür ederim.
Üzerinde çalıştığım ―Transfer Öğrenme‖ konusu, dünya literatüründe çok sıkça işlenen bir konu değildir. Böyle bir konuda çok kapsamlı bir çalışma yaparak neredeyse tüm literatürü kapsayacak şekilde bir sınıflandırma yapan ve Transfer Öğrenme konusundaki bilgi birikimimin temelini oluşturan Hong Kong Bilim ve Teknoloji Üniversitesi Bilgisayar Bilimleri Bölümü’nden Sinno Jialin Pan ve Qiang Yang’a çok teşekkür ederim. Yaptıkları çalışmalarla bana ışık tuttukları gibi ben de bu tez çalışmamla benden sonra bu konuda çalışmak isteyenlere yardımcı olmayı umuyorum.
Bu tezi hazırlamamda bana çok destekte bulunan eşim ve aileme ayrıca bana yeni fikirler vererek yeni çalışmalar hazırlamamda yardımları dokunan çalışma arkadaşlarıma çok teşekkür ederim.
Barış KOÇER KONYA-2012
vii
ĠÇĠNDEKĠLER ... vii
1. GĠRĠġ ... 1
2. LĠTERATÜR ÇALIġMASI ... 3
3. GENETĠK TRANSFER ÖĞRENME ... 6
3.1. Genetik Algoritmalar ... 6
3.1.1. Kodlama ... 6
3.1.2. Uygunluk fonksiyonu ... 7
3.1.3. Yeniden oluşturma ... 7
3.2. Transfer Öğrenme ... 9
3.2.1. Tranfer öğrenme planlamaları ... 12
3.2.1.1. Tümevarımsal transfer öğrenme ... 12
3.2.1.2. Tümdengelimsel transfer öğrenme ... 13
3.2.1.3. Öğreticisiz transfer öğrenme ... 13
3.2.2. Tranfer öğrenme yaklaşımları ... 13
3.3. Genetik Transfer Öğrenmenin Temelleri ... 17
4. GERÇEK UYGULAMALAR ... 31
4.1. Gezgin Satıcı Problemi ... 31
4.2. Araç Yönlendirme Problemi ... 36
4.2.1. Değişen seyahat zamanları ... 40
4.2.2. Değişen müşteri ihtiyaçları ... 44
4.3. Düzensiz Nesne Yerleştirme Problemi ... 45
4.4. Yapay Arı Kolonisi Algoritmasında Genetik Transfer Öğrenme ... 56
4.5. Sınıflandırma Problemi ... 64
4.6. Örnek Transferinde Genetik Algoritmalar Yaklaşımı ... 70
4.7. Hibrit Transfer Yaklaşımı ... 74
5. SONUÇ VE ÖNERĠLER... 79
5.1. Sonuç ... 79
5.2. Öneriler ... 80
KAYNAKLAR ... 81
1. GĠRĠġ
Makine öğrenmesi, belli bir eğitim verisini kullanarak eğitilmiş bir sistemin, önceden karşılaşmadığı durumlar için karar vermeyi öğrenmesini amaçlayan bir araştırma alanıdır. Burada eğitim verisi, belli sayıda değişik durum için nasıl karar verileceğine dair fikir veren veriler topluluğudur. Makine öğrenmesi teknikleri uygun ve yeterli miktarda eğitim verisi ile çok başarılı tahminler yapabilir. Fakat zamanla mevcut eğitme durumunun değişmesi sonucu, artık eğitim verisinin yeni durumları karşılayamaması durumunda, yeni eğitim verileri ile sistemin yeniden eğitilmesi gerekmektedir. Ne yazık ki çoğu durumda, eğitim verisini yeniden elde etmek zor ve maliyetli bir iş olabilir. Ayrıca sık sık değişen bir sistemde, her değişim için yeniden eğitim verisi toplamak da oldukça güçtür.
Makine öğrenmesi insan öğrenmesini temel almaktadır. Örneğin, bir çocuğa masa tenisi oynamayı öğretmek için, çocuğun masa tenisi oynayanları bir süre izlemesi veya bir öğreticinin ona masa tenisi oynamayı öğretmesi gerekir. Makine öğrenmesi penceresinden bakıldığında çocuğun tenis oynayanları izlemesi veya birinin ona nasıl tenis oynanacağını öğretmesi eğitim verisi olarak tanımlanabilir. İşte tam bu noktada insan öğrenmesini makine öğrenmesinden ayıran en önemli unsur, insanların yeni bir şey öğrenirken sıfırdan başlamak yerine eski deneyimlerinden de faydalanabilmeleridir. Örneğin, bir çocuk masa tenisi oynamayı yeterince öğrendikten sonra tenis oynamayı, hiç masa tenisi oynamamış birine göre daha kolay öğrenebilir.
Makine öğrenmesinin performansını, eğitim verisinin kalitesine ve çokluğuna bağlı olmaktan kurtarmak için insan öğrenmesindeki ―geçmiş deneyimlerden faydalanma‖ yeteneğini kullanmak gerekir. Transfer öğrenme adını verdiğimiz yaklaşımlar bütünü, makine öğrenmesini insan öğrenmesine bir adım daha yaklaştırmak amacıyla, makine öğrenmesinde benzer görevlerden elde ettiği deneyimleri yeni görevlerde kullanabilmeyi sağlayacak yeni yöntemler ve yaklaşımlar geliştirmeyi amaçlar.
Şimdiye kadar transfer öğrenme yöntemleri sadece sınıflandırma problemlerine uygulanmıştır. Oysa optimizasyon problemlerinde de transfer öğrenme yöntemlerinin uygulanmasının büyük avantaj sağlayacağı durumlar vardır. Ayrıca transfer öğrenmenin temel sorunlarından olan neyin, nasıl ve ne kadar transfer edileceği sorularına da optimizasyon problemlerinde transfer öğrenme tekniklerinin kullanılabilmesi için cevaplar bulunmalıdır. Bu tez çalışmasında optimizasyon problemlerinde transfer
örnek transferi yaklaşımının birleştirilerek yüksek performanslı yeni bir yaklaşımın ortaya konmasıdır.
Bu tez, beş bölümden oluşmaktadır. 1. bölümde, makine öğrenmesi ve insan öğrenmesi arasındaki ilişkiden bahsedilerek transfer öğrenmenin bu ilişki arasındaki köprü görevi anlatılmış ve böyle bir tez çalışmasının yapılmasındaki temel amaçlara kısaca değinilmiştir. 2. bölümde, transfer öğrenme ile ilgili literatürde yapılan çalışmalar hakkında bilgi verilmiştir. 3. bölümde, transfer öğrenme konusunda ayrıntılı olarak bilgi verildikten sonra transfer öğrenme için geliştirilen yaklaşımların temelini oluşturan genetik transfer öğrenme yaklaşımı derinlemesine ele alınmıştır. 4. bölümde, geliştirilen yaklaşımların mevcut optimizasyon problemlerine nasıl uygulandığı hakkında bilgiler verilerek deneysel sonuçlar gösterilmiştir. 5. bölümde ise, araştırmadan elde edilen sonuçlar kısaca özetlenerek ileriye yönelik çalışmanın geliştirilmesi için çeşitli önerilerde bulunulmuştur.
2. LĠTERATÜR ÇALIġMASI
Sınıflandırma, kümeleme, eğri uydurma ve optimizasyon gibi alanlarda veri madenciliği ve makine öğrenmesi teknikleri büyük başarı yakalamıştır. Fakat bununla birlikte bu yöntemlerin başarılı olabilmesinin temel şartı, eğitim kümesindeki veriler ile test kümesindeki verilerin aynı özelliklerde ve aynı dağılımda olmasıdır. Aksi takdirde yöntemler başarılı olamaz. Diğer bir deyişle eğitim verisiyle oluşturulan modelin gerçek hayatta kullanılabilmesi için, gerçek hayatta karşılaşılan ve üzerinde karar verme işlemi gerçekleştirilecek probleme ait verinin, eğitim verisiyle aynı uzayı paylaşması ve dağılımının aynı olması gerekir. Teoride böyle çalışan makine öğrenmesi ve veri madenciliği yöntemleri uygulamada bazı zorluklarla karşılaşabilir. En sık karşılaşılan zorlukların başında yeterli etiketli eğitim verisinin bulunamamasıdır. Bu gibi durumlarda benzer görevlerden bilgi veya veri transfer etmek bir çıkış yoludur. Fakat bilgi transfer edilecek görevle (kaynak görev) bilginin transfer edileceği görevin (hedef görev) eğitim verisin aynı özelliklere ve aynı sınıf etiketlere sahip olması gerekir, aksi taktirde transfer öğrenme tekniklerinin uygulanması mümkün olmamaktadır. İşte bu gibi durumlarda kaynak görev veya görevlerden bilgiyi transfer edebilmek için veriyi uygun hale getiren yaklaşımlar ve bu yaklaşımları değişik şekillerde kullanan yöntemler geliştirilmiştir. Bu yaklaşımların hepsinin ortak noktası iki tür görev üzerinde çalışmalarıdır. Bunlardan biri kaynak görev, diğeri ise hedef görevdir. Transfer öğrenme yaklaşımında kaynak görevin performansının arttırılması gibi bir amaç bulunmamaktadır. Transfer öğrenme kaynak görevi, sadece yararlanabileceği bir bilgi kaynağı olarak görmektedir. Transfer öğrenmede asıl amaç, kaynak görevden transfer edilebilir bilgi, ağırlıklandırılmış eğitim verisi veya hedef görevle kaynak görev arasındaki farkı en aza indirecek ortak bir özellik tanımlaması elde etmektir. Bu tür bir bilgi elde edildikten sonra bir sonraki adım kaynak görevden mümkün olan en iyi biçimde faydalanmak ve hedef görevin performansını, klasik makine öğrenmesi yöntemlerine göre arttırmak veya çözülemeyecek durumda olan problemleri bile çözülebilir hale getirmektir.
Transfer öğrenme konusunda ilk çalışmalardan biri olan Prat’ın (1993) çalışması, eğitilmiş olan bir yapay sinir ağının, ağırlık değerlerini başka bir sinir ağının başlangıç ağırlık değeri olarak kullanmayı amaçlamaktadır. Bunun için eğitilmiş ağırlık değerleri üzerinde bir dizi ön işlem yaparak hedef görev için uygun hale getirmektedir. Makine öğrenmesi alanında transfer öğrenme konusunun asıl tartışılmaya başlanması
tür bir duruma örnek olarak ―iç ortam wi-fi konumlama problemi‖ gösterilebilir. Bu problemde kapalı bir mekan(örneğin bir ofis) belirli genişlik ve uzunlukta odacıklara ayrılır. Amaç, mekandaki kablosuz vericilerin önceden belirlenen hücrelerdeki yayın gücüne bakılarak alıcının hangi hücrede olduğu tahmin etmeye çalışmaktır. Bu problem farklı yönleriyle ele alınmıştır. Bunlardan biri Zheng ve ark. (2008)’nın yaptığı ve eğitim verisinin zamanla ofis içinde yeni engeller çıkması nedeniyle yansımaların değişmesi ve eğitim verisinin işe yaramamasıdır. Eğitim verisinin güncelliği yitirmesine neden olabilecek bir diğer durum ise, eğitim verisi oluşturulurken kullanılan donanımın test aşamasında kullanılamıyor olmasıdır. Bu durumda yine Zheng ve ark. (2008b) tarafından ele alınmıştır. Bu iki farklı çalışmada da sorun, eğitim verisinin değişen durumlara uyum sağlayamaması sonucu tahmin doğruluğunun azalmasıdır. İki durum için de problemin çözümü, yeni durum için yeni eğitim verisi elde etmektir. Fakat bu ve benzeri problemler için yeni eğitim verisi elde etmek oldukça güç olabilir. Çünkü ölçüm yapılacak kapalı mekan çok büyük olabilir, bu da büyük bir insan gücü gerektirebilir veya eğitim verisi çok sık güncelliğini yitiriyor olabilir. Bu duruma çözüm olarak transfer öğrenme önerilebilir. Her yeni durum için az miktarda yeni eğitim verisi, eski eğitim verisinden bilgi transfer etmek üzere kullanılabilir. Transfer öğrenme özellikle eğitim verisinin çok az olduğu durumlarda benzer eğitim verilerinden bilgi elde etme probleminde kritik bir rol oynamaktadır. Buna örnek olarak Ling ve ark. (2008)’nın yaptığı çalışma gösterilebilir. Bu çalışmada, Çince web sayfalarının önceden belirlenmiş kategorilerden hangisine girdiğini belirlemek üzere tasarlanan bir sistemin, yeterli etiketli veri bulamaması problemine transfer öğrenme ile çözüm aranmıştır. Bunun için yeterli miktarda etiketli verisi olan ―ingilizce web sayfalarını etiketleme‖ problemindeki eğitim verisinden, az miktardaki Çince etiketli veri sayesinde bilgi transfer edilmesi yoluyla performans artışları sağlanmıştır.
Bilgi transferini sağlamak üzere bazı makine öğrenme teknikleri değiştirilmiştir. Buna örnek olarak, sıkça transfer öğrenmede kullanılmak üzere değiştirilen takviyeli öğrenme (reinforcement learning) gösterilebilir. Örnek olarak Koridas ve Barto (2007)’nun benzer görevler arasında beceri transfer eden çalışması, Cohen ve ark.
(2007)’nın aksiyon şemaları transferi ve Fernández ve ark. (2007)’nın öğrenilmiş olan kontrol bilgilerini benzer planlayıcılar arasında transfer eden çalışmaları gösterilebilir. Bu alanda bir diğer ilgi çekici çalışma da Mihalkova ve ark. (2007)’nın markov mantıksal ağları üzerine yaptıkları çalışmadır. Markov mantıksal ağları birinci derece mantığı yumuşatmak adına, ağırlık değerleri verilmiş formüllerden oluşur. Bu formüller karşılaşılan durumlara açıklık getirmek üzere kullanılır. Örneğin, bir film setindeki ilişkileri ifade eden formüller (bir film, bir yönetmene sahiptir, bir filmde birden fazla oyuncu olabilir vb.) bir üniversite bölümündeki ilişkileri ifade etmek üzere (bir bölümün bir başkanı olabilir, bir bölümde birçok çalışan olabilir vb.) değiştirilerek, bazı bölümleri silinerek veya bazı formüller birleştirilerek kullanılmıştır. Geliştirmiş olduğumuz genetik transfer öğrenme metodu da (Koçer ve Arslan, 2010), transfer öğrenmede kullanılmak üzere değiştirilmiş yöntemler kategorisinden değerlendirilebilir. Bu çalışmada geliştirilen yöntemle, benzer optimizasyon problerini çözerken, en uygun çözümü sıfırdan aramaya başlamak yerine önceki aramalardan elde edilen deneyimleri kullanarak aramaya avantajlı başlamak amacıyla geliştirilmiştir. Yöntem, mevcut problem çözülürken, her yeni jenerasyonda, en iyi ve ortanca çözümün bir havuza atılarak, ileride karşılaşılacak problemlerin çözümünde kullanılması esasına dayanmaktadır.
Transfer öğrenme yöntemleri birçok sınıflandırma problemine de uygulanmıştır. En çok karşılaşılan sınıflandırma problemlerinden biri metin sınıflandırmasıdır. Metin sınıflandırma, bir belgenin içeriğine göre, önceden belirlenmiş sınıflardan birine ait olup olmadığının belirlenmesidir. Metin sınıflandırma ile ilgili olarak Dai ve ark. (2007)’nın Expectation Maximization tabanlı naive bayes sınıflandırıcı kullandıkları, Eaton ve ark. (2008)’nın grafik tabanlı bir transfer metodu kullandıkları ve yine Dai ve ark. (2007b)’nın AdaBoost algoritmasını transfer öğrenme için değiştirdikleri ve eski veriyi, az miktarda yeni veri ile güncel probleme taşıyıp sınıflandırma başarısını artırdıkları çalışmalar gösterilebilir. Transfer öğrenme konusunda kapsamlı ve derinlemesine bir çalışma olarak da Pan ve Yang (2010)’ın hazırladıkları çalışma örnek gösterilebilir.
kendine temel alan bir ―adaptif arama sezgisi‖ olarak tanımlanabilir. İlk olarak Holland (1975) tarafından ortaya atılmıştır. Daha sonra Goldberg (1989) tarafından yazılan kitap, genetik algoritmalara tarihi perspektiften bakan bir referans eser olarak gösterilebilir. Genetik algoritmalarla ilgili referans olabilecek diğer çalışmalara örnek olarak Davis (1987, 1991), Grefenstette (1986, 1990) ve Michalewicz (1992) gösterilebilir.
Genetik algoritmalar bilgisayar bilimleri, ekonomi, kimya, matematik, üretim gibi birçok alanlarda kullanılmaktadır. Genetik algoritmalar, soruna bir çözüm üretmek yerine birden fazla çözüm üreterek geniş arama uzaylarında etkin arama yapmak üzere geliştirilmiştir. Genetik algoritmalarda bireyler, gen denilen ve problemi tanımlamak üzere birleşmiş temel yapı taşlarından oluşur. Bir birey problem için üretilen çözümdür. Bireyler birleşerek popülasyonları oluşturur. Popülasyon denilen çözüm topluluğu kendi arasında yeni çözümler üreterek yeni nesiller oluşturur. Bunu yaparken de doğal seleksiyonda olduğu gibi güçlü bireyler yani çözüme en yakın bireylerin yeni nesilde daha çok temsil edilmesi sağlanır. Genetik algoritmaların çalışması için aşağıdaki dört temel prensibin yerine getirilmesi gerekir.
3.1.1. Kodlama
Genetik algoritmaların doğru bir şekilde çalışabilmesi için problemin doğru bir şekilde kodlanması gerekir. Örneğin eşitlik 3.1’ deki gibi, bir problemin minimizasyonunda sayılar 8 bit şeklinde yan yana kodlanmalıdır.
3 2 2 2xy y x A x, y,0x256,0 y256 (3.1)
Eşitlik 3.1’deki bir problem için, Şekil 3.1’deki örnek kodlama kullanılabilir.
ġekil 3.1. Örnek kodlama
Kodlama için ikili veri kullanılabileceği gibi daha karmaşık problemler için ondalık değerler de kullanılabilir. Örneğin yapay sinir ağına ait katsayıları belirlemek için yapılacak kodlamada pozitif ve negatif ondalık sayılar kullanılmalıdır.
3.1.2. Uygunluk fonksiyonu
Uygunluk fonksiyonu, bir nesildeki bireylerin çözüme ne kadar yaklaştığını belirlemek üzere bireylerin uygunluğunu ölçen fonksiyondur. Bu fonksiyona bireyin içindeki genler yerleştirildikten sonra elde edilen değer, o bireye ait uygunluk değerini verir. Problemin türüne ve seçilen uygunluk fonksiyonuna göre en uygun bireyin en yüksek uygunluk değerine, en küçük uygunluk değerine, sıfıra en yakın değere veya önceden belirlenen sabit bir değere sahip olması beklenebilir. Örneğin eşitlik 3.2’deki safir (sapphire) problemi uygunluk fonksiyonu olarak kullanıldığında, sıfıra en yakın uygunluk değerine sahip birey en uygun birey olarak değerlendirilir.
D i i x F 1 2 (3.2)Bu fonksiyonda D problemin boyut sayısını, xi ise bireyin optimum çözüm için
söz konusu boyuta önerdiği değeri temsil etmektedir.
3.1.3. Yeniden oluĢturma
Yeniden oluşturma adımı, bir nesilde bulunan iyi çözümlerden daha iyi çözümler üretmek veya arama uzayında daha önce gezilmemiş yerleri muhtemel çözümleri aramak üzere gezmek için, çaprazlama ve mutasyon gibi genetik operatörler kullanarak,
Çaprazlama için iki birey seçilir. Bu bireyler seçilirken çok farklı yollar olmakla birlikte çoğu yöntem, en uygun bireyin en fazla seçilmesi esasına dayanır. Bunun için rulet tekerleği adı verilen seçim metodu örnek olarak gösterilebilir. Bu yöntemde, nesil içindeki bireyin çaprazlama için seçilme olasılığı 3.3’deki eşitlikle hesaplanır.
N i i i i F F P 1 (3.3)Eşitlik 3.3’deki N değeri, popülasyondaki birey sayısını ifade eder. Eşitlik her bireyin toplam uygunluktaki payını temsil etmektedir. Bu olasılık değeri, her birey için ayrı ayrı hesaplandıktan sonra, bu değerler rulet tekerleğine yerleştirilmektedir. Çaprazlama için bir birey seçileceği zaman, rulet tekerleği çevrilir ve rulet hangi bireyin üstünde durduysa o birey çaprazlama işlemi için seçilmiş sayılır. Çaprazlama işlemi, seçilen iki bireyin belirli nokta veya noktalardan çıkarılan parçalarının değiş tokuşu esasına dayanır. Şekil 3.2’de ikili bir kodlama üzerinde çaprazlama işlemi gösterilmiştir.
3.1.3.2. Mutasyon
Genetik algoritmalarda arama işleminin bir noktaya (yerel optimum) takılıp kalmasını engellemek için, bazı bireylerde çok küçük olasılıklarla rastgele değişiklikler yapılmaktadır. Bu işleme mutasyon denilmektedir. Örnek olarak ikili bir kodlamada mutasyon işlemi, rastgele seçilen bir bireyin rastgele bir bitinin değilinin alınması ve bit değerinin değiştirilmesi ile gerçekleştirilir. Şekil 3.3’de ikili bir kodlama üzerinde çaprazlama işlemi gösterilmiştir.
ġekil 3.3. Mutasyon operatörü
3.1.4. Sonlandırma
Genetik algoritmalar her yeni nesilde problem için daha iyi çözümler aramaktadır. Fakat sonsuza kadar arama yapılamayacağı için aramanın bir noktada sonlandırılması gerekir. Bu sonlandırma koşulu, belli bir uygunluk değerine ulaşılması, belli bir nesil sayısına ulaşılması veya artık yeni neslin çoğunun aynı çözümü öneriyor olması gibi şartlardan biri olabilir.
3.2. Transfer Öğrenme
Klasik makine öğrenmesi yöntemleri, her problemi ayrı ayrı değerlendirip sıfırdan çözmeye başlamaktadır yani geçmiş deneyim, yardımcı veri kavramları yoktur. Buna karşılık insan öğrenmesi önceden karşılaşmadığı problemlere çözüm ararken gerek farkında olarak gerekse farkında olmadan geçmiş deneyimlerinden faydalanmakta
gerçek dünya probleminde eğitim verisi bulmak veya üretmek çok pahalı, insan gücü gerektiren veya zaman alıcı olabilir. İşte bu gibi durumlarda benzer problemlerde kullanılan eğitim verilerinin bir şekilde düzenlenip, mevcut eğitim verisinin zenginleştirilmesi veya elde olan fakat etiketlenememiş verinin etiketlenmesi, bu tür problemlerin çözümü için büyük avantaj sağlamaktadır. Bu işlem bir bakıma insan zekâsının sahip olduğu geçmiş deneyimlerden faydalanma becerisinin makine öğrenmesinde kullanılması anlamına da gelmektedir. İşte bu ve benzer durumlar için, görevler arası bilgi veya veri transfer etmek üzere geliştirilmiş yaklaşımlara ―transfer öğrenme‖ adı verilmektedir. Şekil 3.4’de klasik makine öğrenmesi yöntemlerinin çalışma prensibi, Şekil 3.5’de ise transfer öğrenme yaklaşımlarının çalışma prensibi gösterilmiştir.
ġekil 3.5. Transfer öğrenme yaklaşımı temel çalışma prensibi
Transfer öğrenme konusunda daha bilimsel bilgiler verebilmek için makine öğrenmesi ve veri madenciliğinde sıkça karşılaşılan alan ve görev terimlerine değinmek gerekir. Bunun için alan kavramı 3.4’deki eşitlik ile gösterilebilir.
)} ( , {X P X
D , X {x1,x2,...,xn}X (3.4)
Bu eşitlikte D alanı (domain), X giriş uzayını ve P(X) de marjinal olasılık dağılımını ifade etmektedir. Bu alan kavramından yola çıkarak görev kavramı ise 3.5 eşitlik ile gösterilebilir.
y y yn yi Y X Y P( | ), { 1, 2,..., }, Y (3.5)
Bu ifadede ise Y verilen alan için etiket uzayını temsil eder. Görevin amacı
verilen xi için Y kümesine ait bir yi etiketini bu veriye atamaktır.
Transfer öğrenmede iki tür görev vardır. Bunlardan ilki olan kaynak görev, kaynak alanda (source domain) tanımlı ve yeterli miktarda etiketli eğitim verisi olan, klasik makine öğrenmesi görevidir. Bu görev için ek veriye veya bilgi transferine ihtiyaç yoktur. İkinci tür görev ise yeterli veya hiç etiketli verisi olmayan veya etiketsiz verisi olduğu halde bunu eğitim verisi olarak kullanmak üzere etiketlenmesi gereken, kaynak görevle aynı alanda olan veya benzerlikler içeren, kısaca veri veya bilgi transferine ihtiyacı olan hedef görevdir (target task). Kaynak görev ve hedef görev aynı alandan olmak zorunda değildir. Yani iki görevin etiket uzayı veya olasılık dağılımları
2 1 n i n H H H H H H H X Y y y y y Y P( | ), { , ,..., }, 2 1 YH (3.9)
Transfer öğrenmede, bilgi transfer edebilmek için öncelikle aşılması gereken sorunlar vardır. Pan ve Yang (2010) yaptıkları çalışmada bu sorunları üç ana başlıkta toplamıştır. Bunlar neyin transfer edileceği, nasıl transfer edileceği ve ne zaman transfer edileceği konularıdır. Neyin transfer edileceği konusu, nasıl bir bilginin transfer edileceğini ele alır. Transfer edilecek bilgi türü tespit edildikten sonra nasıl transfer edileceği sorusunun çözümü aranır. Son olarak da kaynak ve hedef görevin ilişkili olup olmadığı ve bilgi transferinin hedef görev için faydalı mı yoksa zararlı mı olacağını belirlemek gerekmektedir. Bilgi transferinin zararlı olduğu duruma negatif transfer adı verilir ve transfer öğrenmede aşılması gereken en büyük sorunlardan biridir. Tüm bu sorulara cevap aramak üzere, transfer öğrenme için planlamalar yapılmış ve yaklaşımlar geliştirilmiştir. Pan ve Yang (2010) yaptıkları çalışmada transfer öğrenme planlamalarını aşağıdaki şekilde üçe ayırmıştır.
3.2.1. Tranfer öğrenme planlamaları
Etkili bir bilgi transferi için kaynak ve hedef görevlerin sahip olduğu verinin niteliğine göre özel transfer planı yapmak gerekir. Aşağıda temel transfer öğrenme planlamaları tanımlanmıştır.
3.2.1.1. Tümevarımsal transfer öğrenme
Bu transfer öğrenme planında hedef görevde az da olsa etiketli veri bulunmaktadır. Kaynak görevde ise etiketli veri olup olmamasının bir önemi yoktur. Hedef görevdeki etiketli veri ile, kaynak görevdeki veri, hedef görev için uygun hale getirilerek hedef görevin performansı arttırılmaya çalışılır.
3.2.1.2. Tümdengelimsel transfer öğrenme
Hedef görevin hiç etiketli veriye sahip olmadığı fakat etiketsiz veriye sahip olduğu, kaynak görevde ise birçok etiketli verinin bulunduğu durumdur. Hedef görevdeki etiketsiz veri, kaynak görevdeki etiketli verinin de yardımıyla hedef görev için kullanılabilir bilgiye dönüştürülür. Hedef görevin başarısını artırmayı amaçlayan bu yaklaşıma benzer yaklaşımlara Daumé ve Marcu (2006)’nun ―alan adaptasyonu‖ (domain adaptation), Zadrozny’nin (2004) ―örnek seçme eğilimi‖ (sample selection bias)ve Shimodaira’nın (2000) ―ortak değişken kaydırma‖ (covariate shift) çalışmaları örnek olarak gösterilebilir.
3.2.1.3. Öğreticisiz transfer öğrenme
Bu transfer öğrenme planında, hedef görevde de, kaynak görevde de etiketli veri bulunmamaktadır. Bu tür bir yöntem için kaynak görevde, hedef göreve göre çok fazla etiketsiz veri olmalıdır. Bu tür transfer öğrenme planlaması hedef görevin kümeleme, boyut azaltma gibi öğreticisiz öğrenme yöntemlerinin kullandığı durumlarda yapılabilir. Bu planlama türünde çok fazla çalışma yapılmamıştır. ―öğreticisiz kümeleme‖ (self-taugh clustering) (Dai ve ark., 2008) ve ―transfer edilmiş ayrıklaştırma analizi‖ (transferred discriminative analysis) (Wang ve ark., 2008) bu konuda son zamanlarda yapılan çalışmalara verilebilecek örneklerdir (Pan ve Yang, 2010).
3.2.2. Tranfer öğrenme yaklaĢımları
Transfer öğrenmede transfer edilecek verinin türüne, transfer öğrenmenin hangi planlama türüne ait olduğuna göre değişik transfer öğrenme yaklaşımları geliştirilmiştir. Pan ve Yang (2010) yaptıkları çalışmada bu planlamalar çerçevesinde kullanılabilecek yaklaşımları da aşağıdaki şekilde dörde ayırmışlardır.
3.2.2.1. Örnek transferi
Akla ilk gelebilecek olan örnek transfer yaklaşımı, kaynak görevdeki verilerin tamamının olmasa bile, en azından bir kısmının hedef görevde kullanılabileceği durumlarda kullanılan yaklaşım ve yöntemleri kapsamaktadır. Bu yaklaşım kaynak ve
gerileme‖ (logistic regression) için kaynak görevdeki veri örneklerini yardımcı veri olarak kullandığı çalışma ve Dai ve ark. (2007) metin sınıflandırma için aynı ana kategoriye ait farklı alt kategorilerin sınıflandırılmasında, örnek transferi yaptığı çalışmalar örnek olarak gösterilebilir.
3.2.2.2. Özellik temsil transferi
Hedef görev ve kaynak görev birbirinden ne kadar farklı ise, bu iki görev arası bilgi transfer etmek o kadar zorlaşacaktır. Bu farklılığı azaltmak üzere ortak ve daha küçük bir özellik uzayı tanımlanabilirse bilgi transferi kolaylaşabilir. Bu tür yöntemler, eğer kaynak veride çok miktarda etiketli veri varsa eğiticili, eğer etiketli veri yoksa eğiticisiz öğrenme teknikleriyle yeni özellik uzayı oluşturmaya çalışır. Doğal dil işleme konusunda Ando ve Zhang (2005)’ın çalışması ve metin sınıflandırma konusunda Dai ve ark. (2007)’nın çalışması özellik temsil transferi için örnek olarak gösterilebilir.
3.2.2.3. Parametre transferi
Kaynak ve hedef görevin gizli de olsa ortak parametreleri veya benzer dağılımları olduğu varsayımından yola çıkarak bu parametreleri tespit etmeye çalışan yöntemler bu yaklaşımın içinde ele alınabilir. Her ne kadar transfer öğrenmeden ayrı bir yaklaşım olsa da, benzer sınıflandırma görevlerini aynı yapay sinir ağında eğiterek aralarındaki gizli parametreleri, görevlerin preformansını arttırmak üzere kullanan ―çoklu görev öğrenme‖ (multitask learning) (Caruana, 1997) , parametre transferi için örnek teşkil edebilecek bir çalışmadır. Bu çalışmadan farklı olarak Gauss işlemlerinde aynı ―önceliği‖ (prior) kullanarak, paylaştıkları parametreleri tespit etmeye çalışan uygulamalarıyla Lawrence ve Platt (2004) ve aynı metodu ―destek vektör makinesinin‖ (support vector machine) parametrelerini kontrollü bir şekilde transfer etmek üzere kullanan çalışma (Evgeniou ve Pontil, 2004) parametre transferi için örnek olarak gösterilebilir.
3.2.2.4. ĠliĢkisel bilgi transferi
İlişkisel bilgi, diğer alanlardan farklı olarak sosyal ağ verisi, hiyerarşik ilişkiler gibi ağ şeklinde ifade edilebilecek eşit dağıtılmış olması şart olmayan veri türünü ifade eder. Bu konuda en önemli çalışmaları Mihalkova ve ark. (2008) gerçekleştirmiştir.
Pan ve Yang (2010) yaptıkları çalışmada Şekil 3.6’daki, hangi yaklaşımın hangi durumda kullanılabileceğini özetleyen bir ağaç yapısı oluşturmuşlardır.
3.3. Genetik Transfer Öğrenmenin Temelleri
Genetik algoritmalarda transfer öğrenmenin kullanımına ilişkin yaklaşım bu noktadan itibaren ―genetik transfer öğrenme‖ olarak nitelendirilecektir. Genetik algoritmalar, bir probleme bir yerine birden çok çözüm öneren ve önerdiği çözümlerin kalitesini test ederek daha iyi çözümler üretmeye çalışan iteratif bir arama metodudur. Genetik algoritmalar kör arama dediğimiz, ne aradığını bilmeden sadece elindeki uygunluk fonksiyonuna bakarak çözüme ne kadar yaklaştığını bilen bir şekilde arama yapar.
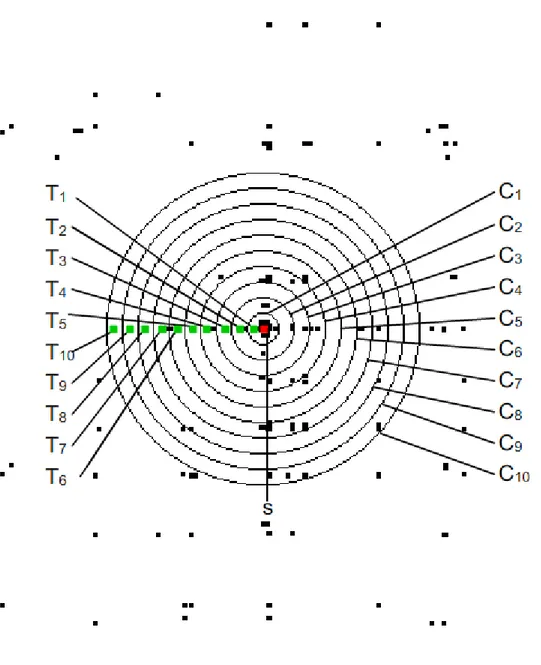
Genetik algoritmalar her nesilden, daha kaliteli çözümler üretmek üzere yeni nesiller türetir. Belirli bir nesil sayısına ulaştığında, önceden belirlediği uygunlukta bir çözüme ulaştığında veya nesil içindeki bireylerin artık farklı bir birey oluşturamayacak kadar birbirine benzediğinde arama işlemine son verilerek, o zamana kadar elde edilmiş en iyi çözüm, sonuç çözüm olarak kabul edilir. Bir nesilden başka bir nesil üretildikten sonra, eski nesil bir daha kullanılmamak üzere yok edilmiş olur. İşte bu nokta genetik algoritmalarda transfer öğrenmenin kullanılması için bir başlangıç olmuştur. Yok edilen nesiller, benzer optimizasyon problemlerinde birbirlerine uygun çözümler içerebilir. Şekil 3.7’de iki tane 64 bit tamsayıyı bulmaya çalışan bir genetik algoritma probleminin 50 popülasyon ile 100 nesil için elde edilen ―gezilmiş çözüm uzayı‖ resmedilmiştir.
Şekil 3.7, 64 bit sayıların biri x koordinatını, diğeri ise y koordinatını temsil edecek şekilde çözümlerin 1000 x 1000 piksellik bir düzleme normalleştirilmesiyle denk gelen noktanın siyah olarak işaretlenmesiyle elde edilmiştir. Şekilde görülen S noktası optimum çözümü göstermektedir. Görüldüğü üzere çözüme uzak noktalar daha az aranırken, çözüm etrafında yapılan aramalar daha yoğundur. Bu durumu sayısal olarak ifade etmek üzere bir dizi denemeler yapılmış ve arama yoğunluğu (AY) denilen ve 3.10’de verilen eşitlikle bir alanda ne kadar sık arama yapıldığını gösteren bir ölçü belirlenmiştir.
ġekil 3.7. Örnek bir aranmış çözüm uzayı
A
AY N (3.10)
Eşitlik 3.10’deki N, belirtilen alana denk düşen arama sayısını, A ise belirtilen alanın (piksel)2
cinsinden büyüklüğünü belirtmektedir. Optimum çözüm noktasının (S) etrafındaki alan incelenmiş ve Şekil 3.8’de görüldüğü gibi, optimum çözüm etrafına çizilen çemberlere denk gelen arama yoğunlukları eşitlik 3.10 ile hesaplanmıştır.
ġekil 3.8. Optimum çözüm etrafındaki arama yoğunluğu hesaplamak için çizilen çemberler
Şekilde C1’den C10’a kadar olan çemberler merkezleri S olacak şekilde,
yarıçapları 10’ar piksel artarak çizilmiştir. Bu şartlar altında ölçüden arama yoğunlukları Çizelge 3.1’de gösterilmiştir. Yoğunluklar hesaplanırken kullanılan arama miktarları 10 bağımsız çalışma sonucu elde edilen ortalama değerdir.
Çizelge 3.1’de görüldüğü gibi en sık arama, optimum sonuç olan S noktasına en yakın alanda gerçekleşmektedir. Eğer S noktasını bulmak için çalıştırılan genetik algoritmanın her nesli saklanabilirse gelecek benzer görevlerin çözümünü bulmak için de kullanılabilir. Öte yandan böyle bir işlem için çok fazla hafıza alanı gerekebilir. Ayrıca çözüm sayısı arttıkça, rastgele yapılacak bir transferde, uygun çözümün bulunma olasılığı da azalacaktır. Bu nedenle yok edilen her nesil birkaç bireyle ifade edilebilmeli
Çizelge 3.1. Şekil 3.3.2’deki çemberler için arama yoğunlukları Çemberin Adı Arama Miktarı (N) Çemberin Alanı (piksel2
) Arama yoğunluğu arama/piksel2 C1 20466 314 65,17866 C2 23706,4 1256 18,87452 C3 24528,7 2826 8,679653 C4 24623,2 5024 4,901115 C5 24647,9 7850 3,13986 C6 24673,4 11304 2,182714 C7 24706,1 15386 1,605752 C8 24733,3 20096 1,230757 C9 24746 25434 0,97295 C10 24756,4 31400 0,78842
Çözüm havuzu iki şekilde kullanılabilir. Bunlardan biri havuzdan seçilen kaynak görev için en kötü çözümleri içermeyen rastgele çözümlerin, hedef görevin rastgele oluşturulan ilk neslindeki bireylerin belli bir oranıyla değiştirilmesidir. Bu duruma kör transfer adı verilmiştir. Bir diğer transfer seçeneği ise, havuzdaki tüm elemanların, hedef görev için uygun bir şekilde değerlendirilerek en iyi bir veya birkaç bireyin hedef görevin rastgele oluşturulan ilk neslindeki bireylerle değiştirilmesidir. Bu duruma ―adaptif transfer‖ adı verilmiştir. Transfer öğrenmenin, genetik algoritma içinde kullanımına ilişkin akış diyagramı Şekil 3.9’de ve 3.10’da verilmiştir. Kaynak fonksiyonda çözüm havuzunun nasıl oluşturulacağını Şekil 3.9, hedef fonksiyonda çözüm havuzunun kör ve adaptif transfer için nasıl kullanılacağı ise Şekil 3.10’da gösterilmiştir.
Max y y x x U s T s T 2 2 ) ( ) ( (3.11)
Eşitlik 3.11’de xs ve ys noktaları kaynak görevin koordinatını, xt ve yt noktaları
hedef görevin optimum sonucunun koordinatı belirtir ve “Max”; her bir genin aynı uzunlukta olduğu varsayılarak, bir genin alabileceği en büyük uzunluktur. Bu değer örnek problem için 264’tür. Bu durumda “U” kaynak ve hedef görevlerin optimum
çözümleri arasındaki normalleştirilmiş uzaklıktır. Daha açık bir ifade ile U kaynak ve hedef görevlerin birbiri ile ne kadar ilişkili olduğunu belirleyen bir göstergedir.
Adaptif ve kör transferin, kaynak ve hedef görevin ilişki durumuna göre ne kadar etkili olduğu ve hiç bilgi transferi yapılmadığında nasıl bir performansla karşılaşacağımız Şekil 3.11’den Şekil 3.20’ye kadar olan grafiklerle her bir hedef görev için ayrı ayrı incelenmiştir. Grafikler popülasyon sayısı 100 olan genetik algoritmaların, %75 çaprazlama ve %1 mutasyon ihtimali ile 100 nesil çalıştırılması sonucu oluşturulmuştur.
ġekil 3.11. T1 hedef görevi için karşılaştırmalı performans analizi
ġekil 3.13. T3 hedef görevi için karşılaştırmalı performans analizi
ġekil 3.15. T5 hedef görevi için karşılaştırmalı performans analizi
ġekil 3.17. T7 hedef görevi için karşılaştırmalı performans analizi
ġekil 3.19. T9 hedef görevi için karşılaştırmalı performans analizi
durumda adaptif transferin, kör transferden daha iyi sonuçlar bulduğu söylenebilir. Yukarıdaki grafikleri bir tabloda özetleyecek olursak aşağıdaki Çizelge 3.2 ve Çizelge 3.3. ortaya çıkar.
Çizelgeleri açıklamak gerekirse, K ile başlayan kolonlar, kör transfer A ile başlayan kolonlar ise adaptif transfer metodu ile elde edilen test sonuçlarını temsil etmektedir. Kolon isimlerinden sonra gelen sayılar, kolondaki değerin kaçıncı nesilden alındığını göstermektedir. Kolonların değerleri ise, klasik genetik algoritmadan elde edilen sonucun, belirtilen yöntemle elde edilen sonuca bölünmesi ile bulunmuştur. Örneğin çizelge 3.2’deki T1 görevi için bulunan K1 = 6.21 ve A1= 6.18 değerleri,
genetik algoritmalar 1. nesilde 10 bağımsız arama sonucunda ortalama olarak çözüme 9.87 x 1017 yaklaşmıştır. Aynı şekilde 10 bağımsız çalıştırma sonucu kör arama ile sonuca 1.58 x 1017 yaklaşmıştır. Bu durumda kolon değeri
21 . 6 ) 10 58 . 1 /( ) 10 87 . 9
( 17 17 olarak hesaplanmıştır. Çizelge 3.2, hedef göreve yakın olarak seçilen ve Şekil 3.8’de gösterilen hedef görevlerin, 10’ar aralıklarla seçilen nesil sayısına göre gösterdikleri performansların ortalama değeri çizelgenin en altında gösterilmiştir.
Çizelge 3.2. Yakın hedef görevler için adaptif ve kör öğrenme performansları
Çizelge 3.3. Uzak hedef görevler için adaptif ve kör transfer performansları
Uzaklık K1 A1 K10 A10 K20 A20 K30 A30 K40 A 0 K50 A50 K60 A60 K7 A70 K80 A80 K90 A90 K100 A100 0.1 1.40 1.04 1.30 0.87 1.06 0.70 1.02 0.68 1.02 0.68 1.02 0.67 1.02 0.67 1. 2 0.67 1.02 0.67 1.02 0.67 1.02 0.67 0.2 0.89 1.37 1.05 1.11 1.19 1.55 1.19 1.56 1.19 1.57 1.19 1.57 1.19 1.57 1.16 1.54 1.15 1.52 1.14 1.51 1.14 1.51 0.3 1.06 1.27 0.83 1.31 0.92 1.26 0.92 1.27 0.92 1.27 0.93 1.27 0.93 1.27 0.85 1.16 0.79 1.13 0.78 1.13 0.78 1.13 0.4 1.37 1.30 1.72 1.07 1.58 1.44 2.38 1.67 1.14 0.77 0.75 0.79 0.60 0.62 0.60 0.62 0.60 0.62 0.60 0.62 0.60 0.62 0.5 2.73 0.68 2.12 0.82 1.89 1.00 1.91 1.00 1.92 1.00 1.92 1.00 1.92 1.00 1.92 1.00 1.92 1.00 1.92 1.00 1.92 1.00 0.6 0.97 1.11 1.52 1.41 1.44 1.32 1.44 1.32 1.44 1.32 1.44 1.32 1.35 1.24 1.20 1.10 1.20 1.10 1.20 1.10 1.20 1.09 0.7 1.09 1.27 1.94 1.07 2.10 1.22 2.10 1.23 2.10 1.23 2.10 1.23 2.10 1.23 2.12 1.22 2.35 1.22 2.40 1.22 2.40 1.22 0.8 1.37 0.82 1.75 0.69 1.85 0.64 2.10 0.65 2.10 0.65 2.12 0.65 2.13 0.65 2.13 0.65 2.45 0.65 2.51 0.65 2.52 0.65 Ortalama 1.36 1.11 1.53 1.04 1.50 1.14 1.63 1.17 1.48 1.06 1.43 1.06 1.40 1.03 1.37 1.00 1.43 0.99 1.44 0.99 1.45 0.99 Görev K1 A1 K10 A10 K20 A20 K30 A30 K40 A40 K50 A50 K60 A60 K70 A70 K80 A80 K90 A90 K100 A100 T1 6.21 6.18 0.94 2.12 0.64 1.48 0.62 1.45 0.62 1.45 0.62 1.45 0.6 1.45 0.62 1.45 0.62 .45 0.62 .45 0.6 1.45 T2 4.02 3.98 1.49 3.18 1.33 2.93 1.33 2.93 1.33 2.93 1.33 2.93 1.33 2.97 1.33 2.97 1.12 2.49 1.12 2.49 1.27 2.49 T3 1.85 1.88 0.69 2.82 0.80 3.29 0.95 3.31 0.95 3.31 0.95 3.31 0.95 3.31 1.15 3.31 1.15 3.31 1.15 3.31 1.14 3.26 T4 1.56 1.42 2.82 2.21 3.57 2.12 3.57 2.12 3.57 2.12 3.57 3.45 3.57 3.93 2.93 3.24 2.75 3.04 2.74 3.03 2.74 3.03 T5 1.76 1.40 2.00 1.05 1.78 0.89 1.78 0.88 1.78 0.88 1.78 0.88 1.78 0.88 1.78 0.88 1.78 0.88 1.78 0.88 1.78 0.88 T6 1.20 1.38 0.68 1.68 0.66 1.68 0.68 1.68 0.68 1.68 0.68 1.68 0.68 1.68 0.68 1.72 0.68 1.72 0.68 1.73 0.68 1.73 T7 1.09 1.62 1.00 4.15 0.99 4.13 0.99 4.14 1.06 4.15 1.06 4.15 1.06 4.15 1.06 4.15 1.03 4.03 1.03 4.02 1.03 4.02 T8 1.14 1.01 1.24 1.12 1.36 1.17 1.35 1.17 1.35 1.17 1.35 1.17 1.35 1.17 1.35 1.26 1.35 1.26 1.35 1.26 1.35 1.26 T9 0.99 1.46 1.27 2.34 1.32 3.61 1.32 3.87 1.32 3.87 1.15 3.36 1.10 3.22 1.10 3.22 1.10 3.22 1.10 3.22 1.10 3.22 Ortalama 2.20 2.26 1.35 2.30 1.38 2.37 1.40 2.40 1.41 2.40 1.39 2.49 1.38 2.53 1.34 2.47 1.29 2.38 1.29 2.38 1.30 2.37
İlerleyen nesillerde farkın kapanması, genetik algoritmaların bir süre sonra sonuca yaklaşması ile açıklanabilir. Diğer taraftan aynı testler daha ilişkisiz (uzak) hedef görevler için yapıldığında Çizelge 3.3’deki sonuçlar elde edilmiştir. Bu sonuçlar incelendiğinde kör transfer, adaptif transferden ortalama 1.4 kat daha iyi sonuçlar bulmuştur. Buna karşılık adaptif transfer 0.99 değerinin altına inmeyerek, negatif transfer yapmamıştır. Tüm bu değerler ışığında, genetik algoritmalarda, transfer öğrenme tekniklerinin etkin bir biçimde uygulanabileceği söylenebilir. Transfer öğrenme özellikle sonuçları birbirine yakın görevler için uygulandığında, ilk nesillerden itibaren yüksek bir performans göstermektedir. Bu özelliği ile zamanın kritik olduğu uygulamalarda transfer öğrenmenin daha büyük bir önem arz ettiği söylenebilir.
4. GERÇEK UYGULAMALAR
Bu bölümde genetik transfer öğrenmenin gerçek dünya problemlerine uygulanırken karşılaşılabilecek problemleri ve çözüm yolları ele alınmıştır. Bu bölümde önerilen ve literatürde zaten var olan yöntemler C# programlama dilinde yazılmıştır.
4.1. Gezgin Satıcı Problemi
Helsgaun (2000)’e göre gezgin satıcı problemi, kombinasyonel optimizasyon problemleri içinde en çok kullanılanıdır. Gezgin satıcı problemi, bir satıcının n adet şehrin her birini, her şehre bir kere uğramak üzere, dolaşması ve tekrar başladığı şehre dönmesi şartına dayalı bir optimizasyon problemidir. Problemde amaç en kısa yolu satıcıya sunabilmektir. Hesaplama karmaşıklığı teorisine göre NP (Non-Polinomal) tam zorlukta bir optimizasyon problemidir. Bunun anlamı bu problemin her durumu için etkin bir şekilde çalışacak bir algoritmanın olmadığı ve eklenecek her şehir için en kötü durumda hesaplama süresinin üstel olarak artacağıdır. Daha açık bir ifadeyle 100 şehirlik bir gezgin satıcı probleminin çözümü, her olasılık tek tek denenecek olursa, yıllar alabilir. Problemin çözümü planlama, taşımacılık, DNA sıralama ve hatta mikroçip tasarımı gibi başka alanlarda da kullanılmaktadır. Problemin çözümü için sezgisel ve meta sezgisel yöntemler kullanılmıştır. Problem için bir çözüm bulunduğunda, satıcının tüm şehirleri bu plan üzerinden gezeceği, planın hiçbir değişime uğramayacağı varsayılır. Fakat gerçek hayatta durum bu kadar basit olmayabilir. Satıcı ilk noktadan yolculuğa başladıktan sonra bazı satıcılara giden yollar kapanabilir, bazı noktalara firmanın başka bir satıcısının gitmesi gerekebilir veya başka bir nedenle gideceği şehir sayısı azalabilir. Bu durumda tüm yol planının yeniden yapılması gerekir. Fakat bu değişiklikler sıkça karşılaşılan bir durumsa her durum için yeniden bir plan yapılması çok zaman alacağı için toplam seyahat süresini arttıracaktır. İşte bu noktada ―genetik transfer öğrenme‖, ―sıkça değişen seyahat noktaları‖ problemi için kullanılabilir.
Gezgin satıcı problemleri, seyahat süresinin sabit olup olmamasına göre simetrik ve asimetrik gezgin satıcı problemi olmak üzere ikiye ayrılabilir. Simetrik gezgin satıcı problemlerinde, iki şehir arasındaki mesafe sabittir. Örneğin A şehrinden B şehrine bir araç 1 saatte gidiyorsa, aynı şekilde B şehrinden kalkan bir araç A şehrinde 1 saatte
matematiksel temellere dayanan sınırlandırılmış "lagrangean relaxation‖ yaklaşımı ile asimetrik gezgin satıcı problemi için getirdikleri çözüm yöntemi ve Grötschel ve Holland (1991)’ın düzlem kesme prosedürü ile 1000 şehre kadar olan simetrik gezgin satıcı problemleri için geliştirdikleri yöntemleri örnek olarak gösterilebilir. Gezgin satıcı problemlerini çözmek için geliştirilen bir diğer yaklaşım ise sezgisel veya olasılıksal yaklaşımlardır. Tam metotlar, gezgin satıcı probleminin sadece küçük bir kısmını çözebildiği için bu yaklaşıma ihtiyaç duyulmuştur. Tabu arama (Glover, 1990), yapay sinir ağları (Hopfield, 1985) ve elbette genetik algoritmalar (Jog ve ark., 1989; Grefenstette ve ark.,1985; Nguyen ve ark., 2007) bu yaklaşım içinde gezgin satıcı problemi için çözüm olarak kullanılan yöntemler arasında sayılabilir.
Transfer öğrenme klasik gezgin satıcı problemi için yeni bir yöntem önermez, sadece değişen durumlar için mevcut yöntemlerle yeniden bir gezinti planı yapmak yerine, eski planın kullanılabilen kısımlarını genetik transfer öğrenme ile transfer ederek yeni planı geleneksel yöntemlere göre çok daha hızlı ve efektif bir şekilde oluşturmayı amaçlar. Bu durumu açıklamak üzere 100 şehirlik bir gezgin satıcı problemi üzerinden, genetik algoritmaların ve genetik transfer öğrenmenin performansları değerlendirilmiştir. Bunun için 100 şehirlik problem kaynak görev olmak üzere 3 farklı hedef gezgin satıcı problemi oluşturulmuştur. Hedef görevler, kaynak görevden rastgele şehirler silinerek oluşturulmuş, farklı şehir sayısı içeren görevlerdir. Gezgin satıcı probleminde uygunluk fonksiyonu olarak değişik ölçüler kullanılmıştır. Bunlardan biri olan Manhattan uzaklığı şehirlerin x ve y koordinatları arasındaki farkı toplamaktadır. Maksimum metrik ise x ve y koordinatlarından büyük olanı toplayarak gitmektedir. Bu çalışmada ise 4.1’deki öklit uzaklığa dayanan eşitlik, uygunluk fonksiyonu olarak kullanılmıştır. 2 0 2 0 1 1 2 1 2 1) ( ) ( ) ( ) (x x y y x x y y D n n n i i i i i
(4.1)Eşitlik 4.1’de başlangıç şehrinden başlayarak, son şehre kadar kat edilen uzaklığın üzerine son şehirden başlangıç şehrine kat edilen uzaklık eklenerek uygunluk fonksiyonu hesaplanır. Test’i gerçekleştirmek üzere kaynak görev olarak, 100 şehirden oluşan problem, 100 bireyli popülasyon ile 100 nesilde oluşturacak şekilde seçilmiştir. Kaynak görevin her bir neslinden alınan en iyi, ortanca ve en kötü bireylerin saklanmasıyla çözüm havuzu oluşturulmuştur. Bu durumda çözüm havuzu 100 x 3 = 300 çözümden oluşmaktadır. Hedef görev olarak üç farklı görev seçilmiştir. Bu görevler 100 şehirli kaynak görevden rastgele, şehirler silinerek elde edilmiştir. Hedef görevler sırasıyla 80, 60 ve 40 şehirden oluşmaktadır. Bu noktada çözüm havuzundaki çözümler, nokta sayısı az olan hedef görevler için direk çözüm olarak kullanılamaz. Bu çözümlerin hedef görevde kullanılabilmesi için bir ön işleme tabi tutularak, hedef görevde bulunmayan şehirlerin ayıklanması gerekir. Bu işlem için Algoritma 4.1 kullanılmıştır.
For i=0 to çözüm_havuzu_boyutu do begin
Çözüm havuzundan i. Çözümü al S’e ata j=0;
For k=0 to S’in_uzunluğu do Begin
S’in içindeki k. Şehri oku ve R’ye ata If hedef görev R şehrini içermiyorsa then S’den R şehrini sil
End
S’in uygunluğunu hedef görevin uygunluk fonksiyonunu kullanarak hesapla End
Çözüm havuzunu uygunluğuna göre sırala
ġekil 4.1. 80 şehir için genetik algoritma, genetik transfer performans karşılaştırması
ġekil 4.3. 40 şehir için genetik algoritma, genetik transfer performans karşılaştırması
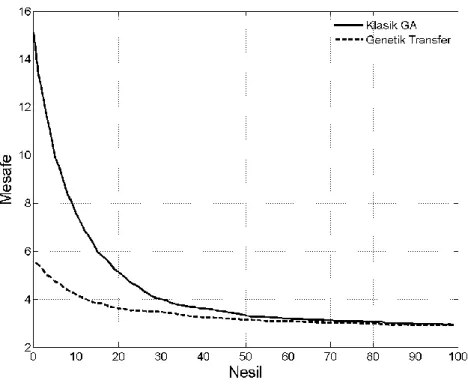
Yukarıdaki grafikler Çizelge 4.1’de özetlenmiştir. Grafiklere bakıldığında genetik transfer öğrenmenin özellikle ilk iterasyonlarda yüksek performans gösterdiği fakat ilerleyen iterasyonlarda klasik genetik algoritmanın aradaki farkı kapattığı görülmüştür.
Çizelge 4.1. Klasik genetik algoritmaların bulduğu sonuçların genetik transfer öğrenme ile karşılaştırılması Hedef Görev Nesil 1 Nesil 10 Nesil 20 Nesil 30 Nesil 40 Nesil 50 Nesil 60 Nesil 70 Nesil 80 Nesil 90 Nesil 100 80 şehir 4.29 2.97 2.34 1.96 1.79 1.67 1 57 1.46 1.39 1.33 1.30 60 şehir 3.78 2.60 1.97 1.65 1.42 1.28 1.22 1.16 1.13 1.10 1.11 40 şehir 2.74 1.87 1.44 1.16 1.11 1.07 1.04 1.03 1.02 1.02 1.01
Çizelge 4.1, seçilen nesildeki genetik algoritmaların hesapladığı toplam mesafenin genetik transfer öğrenme ile hesaplanan toplam mesafeye bölünmesi sonucu elde edilmiştir yani bu değerler genetik algoritmanın, genetik transfere göre ne kadar kötü sonuç bulduğunu göstermektedir. Tablonun üst satırındaki numaralar ölçümlerin
4.2. Araç Yönlendirme Problemi
Araç yönlendirme problemi(AYP) NP tam zorlukta bir optimizasyon problemidir. AYP, gezgin satıcı probleminin çok daha zor ve bilimsel versiyonu olarak ifade edilebilir. AYP hakkında ilk çalışma Dantzig ve ark. (1954)’nın yaptığı çalışma olarak gösterilebilir. ―Araç yönlendirme‖ terimi ilk olarak Golden ve ark. (1978) tarafından ortaya atılmıştır. Benzer terimler olarak ―filo yönlendirme‖ terimi Levin (1971) tarafından, ―taşıma ağı dizaynı‖ ise O’Connor ve ark. (1970) tarafından ilerleyen yıllarda kullanılmıştır. AYP, ürün ya da hizmetleri depo veya depolardan ihtiyaç sahiplerine, kısıtlı kapasiteli araçlarla ulaştırma problemidir. Daha bilimsel bir ifadeyle AYP, graf-teorik bir problemdir. G = (V, A)’ nın tam graf ve V={1,2,3,…,n} kümesinin önceden belirlenen oj miktarınca ihtiyacı olan müşterileri temsil eden
düğümler kümesi olduğu varsayılırsa, A kenarı, i ve j müşterileri arasındaki seyahat maliyeti olan cij olarak ifade edilebilir. Klasik bir AYP probleminde, seyahat maliyetleri
simetriktir yani cij = cji’dir ve sadece bir depo vardır ve bu depo V0 ile ifade edilir. İlk
AYP problemleri belirli parametreler üzerine kurulu idi yani seyahat süreleri, araç kapasiteleri, müşteri siparişleri önceden belirlenmiş ve değişime açık değildi. Fakat gerçek hayatta AYP problemleri çok daha fazla karmaşıktır. Örneğin birden fazla depo olabilir, seyahat zamanları günün saatlerine göre değişiklik gösterebilir veya müşteri ihtiyaçları önceden tanımlı olmayabilir. Bu ve benzeri durumlar Eksioglu ve ark. (2008) tarafından hazırlanan çalışmada hiyerarşik bir şekilde anlatılmış ve Çizelge 4.2’de özetlenmiştir. İhtimale dayalı parametreler AYP de ilk defa Golden ve Steward (1978) tarafından kullanılmıştır. Ayrıca Laporte ve Osman (1995) ve Solomon’un (1983) çalışmaları da AYP’de dinamik problem parametreleri kullanan ilk çalışmalardan sayılabilir. Bu konuda Koçer ve Arslan (2012)’ın yaptığı çalışma AYP’de transfer öğrenme yöntemlerinin kullanıldığı tek çalışmadır. Çalışmanın ayrıntıları aşağıda açıklanmıştır.
Çizelge 4.2. AYP çalışmalarının temel sınıflandırma hiyerarşisi (Eksioglu ve ark., 2008) 1. Çalışmanın Türü
1.1. Teorik
1.2. Uygulamalı yöntemler 1.3. Dokümante edilmiş uygulama 1.4. Geniş inceleme çalışmaları 2. Senaryo Karakteristiği 2.1. Yoldaki durak noktaları 2.2. Yükün ayrılabilirliği 2.3. Müşteri ihtiyacının miktarı 2.4. Müşteri isteklerinin zamanı 2.5. Çalışma anındaki bekleme süreleri 2.6. Zaman penceresinin yapısı 2.7. Müşterinin teslim zamanı tercihi 2.8. Müşterilerin istek farklılıkları 2.9. Düğüm/Kenar içeriği
3. Problemin fiziksel karakteristiği 3.1. Taşıma ağının dizaynı 3.2. Müşteri adresleri
3.3. Müşterilerin coğrafi konumları 3.4. Başlangıç noktası sayısı 3.5. Depo sayısı
3.6. Zaman penceresinin tipi 3.7. Araç sayısı 3.8. Araç kapasiteleri 3.9. Araç farklılıkları 3.10. Seyahat süreleri 3.11. Seyahat maliyetleri 4. Bilginin karakteristiği 4.1. Bilginin değerlendirilmesi 4.2. Bilginin kalitesi 4.3. Bilginin kullanılabilirliği 4.4. Bilginin işlenmesi 5. Verinin karakteristiği 5.1. Veri kullanılmış 5.2. Veri kullanılmamış
Çizelge 4.2’de görüldüğü gibi teoride basit bir taşıma problemi gibi gözükmesine rağmen AYP problemi gerçek hayatta içerisinde çok farklı parametreler barındıran karmaşık bir problemdir. Bu problem türlerinin her birini çözmek üzere özelleşmiş sezgisel ve meta sezgisel yöntemler bulunmaktadır. Fakat bu yöntemlerden hiç biri birden fazla durumu en iyi biçimde karşılayacak şekilde geliştirilmemiştir. Geliştirilen yöntem, yukarıdaki problem türlerinin birden fazlası için etkin çözüm olabilir.
ġekil 4.4. Sıralı çaprazlama (order crossover) operatörü
Metodun etkinliğini test etmek üzere iki farklı problem türü için karşılaştırma yapılmıştır. Bu karşılaştırmalar, gerçek hayatta sıklıkla karşılaşılan ―değişen seyahat zamanları‖ ve ―değişen müşteri ihtiyaçları‖ alt problemleri için genetik transfer öğrenme ile klasik genetik algoritmalar ve klasik yerleştirme yöntemleri ile yapılmıştır. AYP kombinasyonel bir optimizasyon problemi olduğu için genetik algoritmalarda kullanılan çaprazlama ve mutasyon işlemleri istenmeyen sonuçlara neden olabilir. Bu yüzden Şekil 4.4’de gösterilen ve Davis (1985) tarafından geliştirilen ―sıralı çaprazlama‖(order crossover) operatörü, çaprazlama için ve Şekil 4.5’de gösterilen ―ters çevirme mutasyon‖ operatörü de, mutasyon işlemi için kullanılmıştır.
Ele alınan AYP senaryosunda, araç her yeni şehre vardığında yeni bilgiler alınmakta ve yeni yönlendirme planı oluşturulmaktadır. Her yeni plan oluşturulurken de çözüm havuzuna yeni çözümler eklenerek çözüm havuzu genişletilmektedir. Çözüm havuzundaki çözümler, önceden ziyaret edilmiş şehirleri de içerebileceğinden veya çözüm havuzunda değişik uzunluklarda çözümler olabileceğinden Algoritma 4.2 ile uygun olmayan çözümler o anki probleme uygun hale getirilmiştir.
Değişkenler:
V: Ziyaret edilmiş müşterilerin dizisi
C: Geriye kalan, ziyaret edilecek müşteri sayısı L: Havuzdan seçilen çözümün uzunluğu
B: Aracın en son teslimat yaptığı ve henüz yanından ayrılmadığı müşteri. CG: Yeni bireyler oluşturmak için oluşturulan bir sayaç.
H: Çözüm havuzundaki çözümün su anki duruma adapte edilmiş hali Çözüm havuzundan ―S‖ çözümü alınır.
H’ın tüm genlerine ―-1‖ değeri atanır İlk 1 gene B değeri verilir
CG=2
For i=0 to L do Begin
S’in i. Geni okunur ve R’ye atanır If R içinde değil V then
begin
H’ın CG. genini R’ye ata
CG=CG+1 If CG>=C then break End End For i=0 to C do Begin
If H’ın i. geni ―-1‖ ise then begin
V dizisinde olmayan uygun bir sayısı H’ın i. Genine ata End
end
H’ın uygunluk değerini hesapla
sayesinde taşıma işleminde kullanılan araçlarla iletişime geçilerek anlık trafik bilgisi ve güncel seyahat süreleri bilgisi verilebilir. Seyahat sürelerinin değişmesi eğer sık karşılaşılan bir durum değilse, seyahat planı yeniden oluşturularak bu durumun üstesinden gelinebilir, fakat büyük bir taşıma filosu ve geniş bir coğrafi alandan bahsediliyorsa durum karmaşıklaşır ve seyahat sürelerindeki değişimle birlikte yeni seyahat planlarına olan ihtiyaç da artar. Her değişen seyahat zamanı için yeni bir plan oluşturmak verimli bir çözüm değildir. Bunun yerine bir noktadan, diğer bir noktaya harekete başladıktan sonra, hedefe varıldığında yeni seyahat bilgilerini alarak yeni bir seyahat planı oluşturmak hem pahalı olabilecek mobil iletişimi hem de işlem karmaşıklığını azaltmış olacaktır.
Bir taşıma probleminde seyahat süreleri, seyahat süresi tablosu denilen sanal bir tabloda tutulmaktadır. Bu tablo iki nokta arası ne kadar sürede seyahat edileceğini göstermektedir. Simetrik bir AYP’de bu tablonun boyutu Eşitlik 4.2 ile hesaplanabilir.
2 N B (4.2)
Eşitlik 4.2’de N, şehir sayısını göstermektedir. Bu bölümde işlenen problem için 100 şehir olduğu ve araç bir şehirden başka bir şehre varana kadar, seyahat tablosundaki seyahat sürelerinin belli bir yüzde oranında (değişim oranı) değiştiği varsayılmıştır. Bu değişime genetik algoritmalarla ve genetik transfer öğrenme ile çözüm aranmıştır ve sonuçlar grafik olarak gösterilmiştir. Şekil 4.6’dan 4.10’a kadar farklı maksimum nesil sayısı ve farklı ―değişim oranları‖ ile genetik algoritmalarla karşılaştırılmıştır.
ġekil 4.6. Değişme oranı %10 ve maksimum nesil sayısı 10 için genetik algoritmalar ile genetik transfer öğrenmenin performans karşılaştırması
ġekil 4.7. Değişme oranı %20 ve maksimum nesil sayısı 20 için genetik algoritmalar ile genetik transfer öğrenmenin performans karşılaştırması
ġekil 4.8. Değişme oranı %30 ve maksimum nesil sayısı 30 için genetik algoritmalar ile genetik transfer öğrenmenin performans karşılaştırması
ġekil 4.9. Değişme oranı %40 ve maksimum nesil sayısı 40 için genetik algoritmalar ile genetik transfer öğrenmenin performans karşılaştırması
ġekil 4.10. Değişme oranı %50 ve maksimum nesil sayısı 50 için genetik algoritmalar ile genetik transfer öğrenmenin performans karşılaştırması
Grafikler, her yeni şehirde yapılan hesaplama sonucu bulunan seyahat sürelerinin 10 bağımsız çalıştırma ortalaması ile çizilmiştir. Sonuçlar değerlendirildiğinde yüksek şehir sayısı için genetik transfer öğrenmenin çok daha iyi sonuçlar bulduğu, şehir sayısı azaldıkça klasik genetik algoritmanın aradaki farkı kapattığı görülebilir. Geliştirilen yöntemin performansı, genetik algoritmalarla süre olarak karşılaştırıldığında aşağıdaki Çizelge 4.3 ortaya çıkar. Bu süreler her iki metodun da 50 bireyle, 100 iterasyon çalıştırılması sonucu bulunmuştur. Testlerde Intel® Core ™ i7 Q840 işlemcili 6 GB ram’e sahip, Windows 7 SP1 işletim sistemi ile çalışan bir bilgisayar kullanılmıştır.
Çizelge 4.3. Klasik genetik algoritmalarla genetik transferin maliyet - süre kazanç karşılaştırması DeğiĢim Oranı Klasik GA Maliyet Genetik Transfer Maliyet Klasik GA Süre (ms) Genetik Transfer Süre (ms) Maliyet Kazanç Süre Kazanç 10% 29.36 26.61 2708 2884 10.33% -6.10% 20% 30.84 28.36 2168 2298 8.74% -5.66% 30% 30.5 27.37 2105 2199 11.44% -4.27% 40% 30.71 27.76 2110 2242 10.63% -5.89% 50% 29.76 26.77 2036 2171 11.17% -6.22%
Gerçek hayatta sıkça karşılaşılan bir diğer AYP problemi de, müşteri sipariş veya ihtiyaçlarının değişiklik göstermesidir. Bu durumda araç, gerekli siparişleri müşterilere dağıtmak üzere yola çıktıktan sonra bazı müşterilerin siparişlerini iptal etmesi veya listede olmayan bazı müşterilerin sipariş bildirmeleri üzerine hızlı bir şekilde yeni yönlendirme planına ihtiyaç duyulur. Değişen seyahat süreleri problemine paralel olarak, belirli oranlarda değişen müşteri ihtiyaçları, değişik maksimum nesil sayısı ile test edilmiş ve performans sonuçları, ilk kez Roy ve ark. (1984) tarafından ortaya atılan ve daha sonra birçok metoda ilham kaynağı olan klasik yerleştirme metodu ve klasik genetik algoritmalarla karşılaştırması Çizelge 4.4’te gösterilmiştir.
Klasik yerleştirme metodu, yeni eklenen ziyaret noktalarını sırayla eldeki çözümün uygun bir noktasına (maliyeti en az arttıran noktaya) yerleştirilmesi ile yeni çözüm oluşturulması esasına dayanır. Bu noktada klasik yerleştirme için seçilen ilk çözüm, genetik algoritma ile Çizelge 4.4’den alınan maksimum nesil sayısı parametresine uygun bir şekilde belirlenir. Bu çizelge incelendiğinde genetik transfer öğrenmenin, her durumda genetik algoritmalardan ortalama %21 oranında daha iyi sonuçlar verdiği görülebilir. Klasik yerleştirmenin ise özellikle değişim oranının arttığı durumlarda genetik transfer öğrenmeye yaklaştığı, fakat nesil sayısı arttıkça genetik transferin farkı arttırdığı görülmektedir.
Genetik transfer öğrenme, özellikle değişen seyahat zamanı probleminde görüldüğü gibi AYP’de klasik genetik algoritmaların yerine kullanılabilecek performansa sahiptir. Değişen müşteri ihtiyaçları probleminde ise özellikle düşük değişim oranları için yüksek performans göstermiştir. Bunun nedeni müşteri ihtiyaçlarının az değişmesi sonucu transfer edilecek bilginin kalitesinin artmasıdır. Sonuç itibari ile genetik transfer öğrenmenin, AYP’de birden fazla alt problem çeşidine tek çözüm önerebilecek bir yapıda olduğu ve klasik yöntemlere göre yüksek performans sağladığı için kullanılabilir olduğu söylenebilir.