Hypergraph models for sparse matrix partitioning and reordering
Tam metin
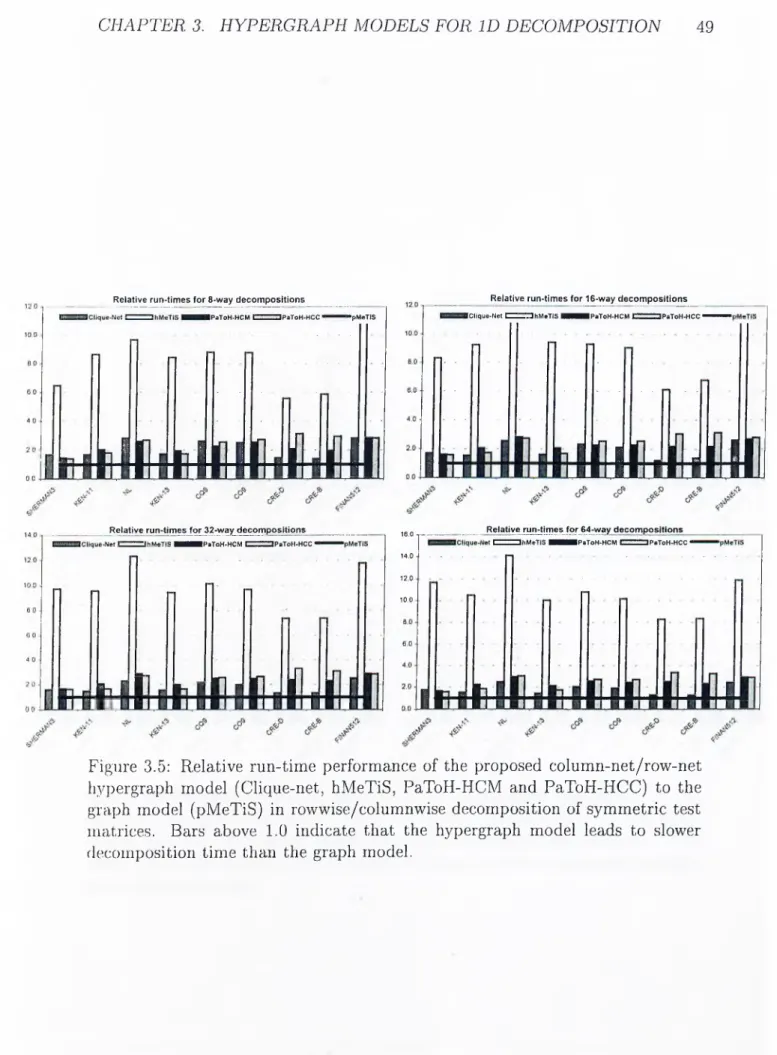
Şekil
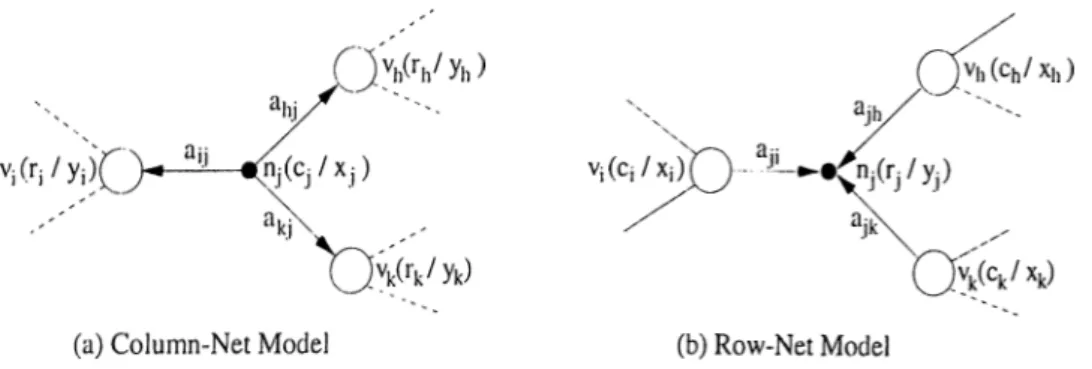
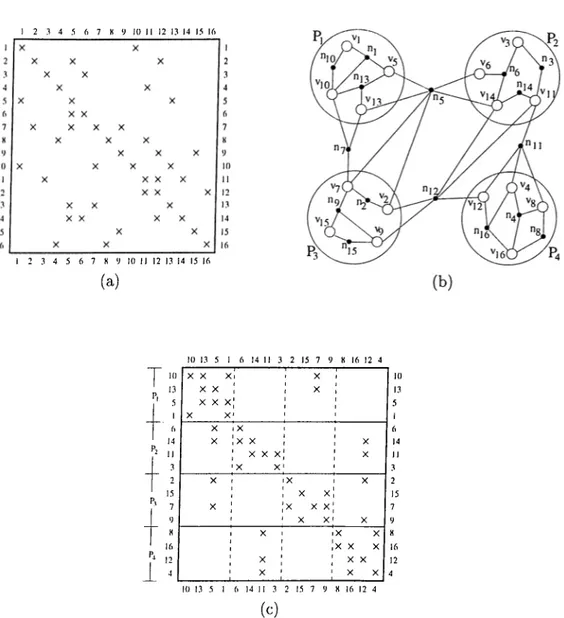

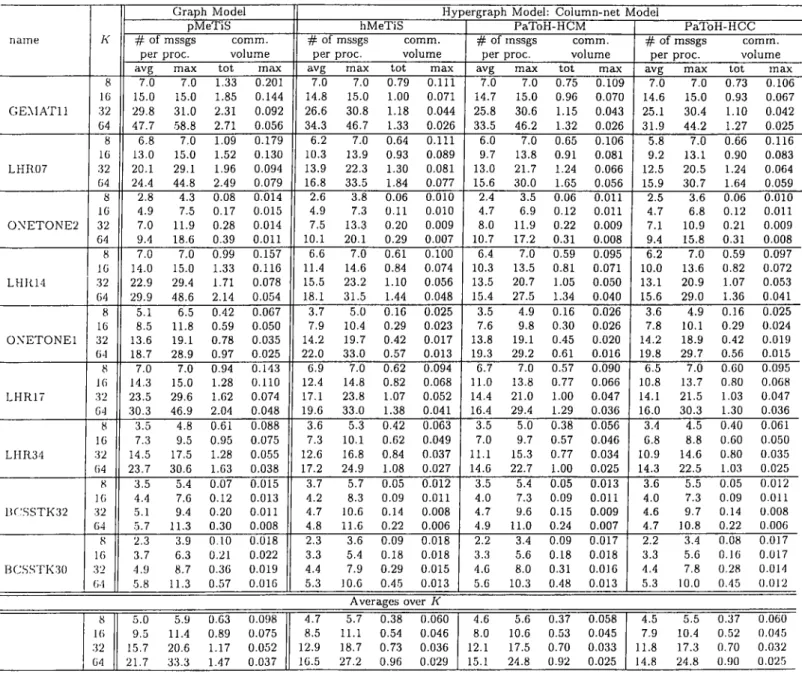
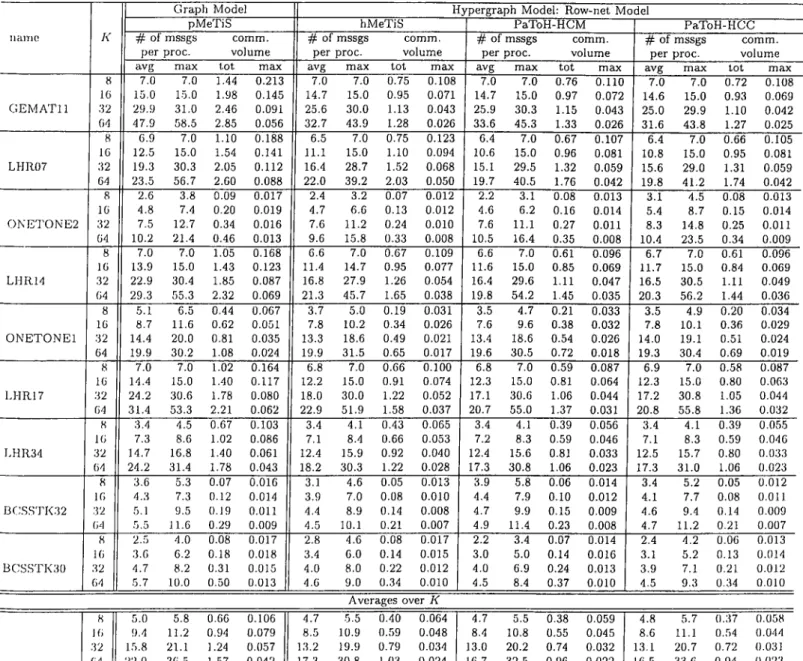
Benzer Belgeler
Bu çalışmada yeşil davranışların yayınlaşması için önemli olduğu düşünülen yeşil dönüştürücü liderlik ele alınmış ve yeşil dönüştürücü liderliğin
The turning range of the indicator to be selected must include the vertical region of the titration curve, not the horizontal region.. Thus, the color change
Extensive property is the one that is dependent on the mass of the system such as volume, kinetic energy and potential energy.. Specific properties are
This study examined the in fluence of immersive and non-immersive VDEs on design process creativ- ity in basic design studios, through observing factors related to creativity as
Analysis of Volvo IT’s Closed Problem Management Processes By Using Process Mining Software ProM and Disco.. Eyüp Akçetin | Department of Maritime Business Administration,
Örneğin, Aziz Çalışlar’ın çevirdiği Sanat ve Edebiyat (1996) başlıklı derleme ile “Sol Yayınları”nın derlediği Yazın ve Sanat Üzerine (1995) başlıklı
(2.3) and elementary theta function identities make it possible to write each modular equation as a theta function identity.. Ramanujan derived an extensive “catalogue” of formulas
Yüksek düzeydeki soyutlamalarda resim, yalnız başına renk lekelerinden ve materyallerin baskı izlerinden oluşmakta, renk kullanma işlemi, boyama tarzı ve aynı
