Dynamic load balancing in distributed systems: “hands of god” in parallel programming with MPi
Tam metin
Şekil

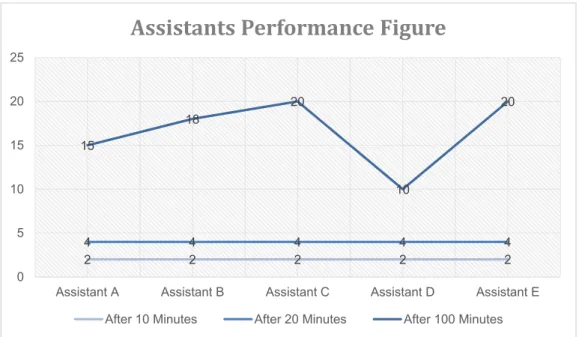
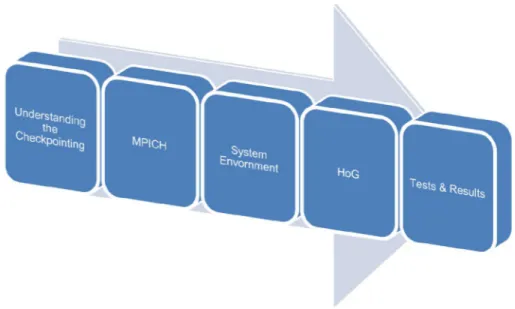



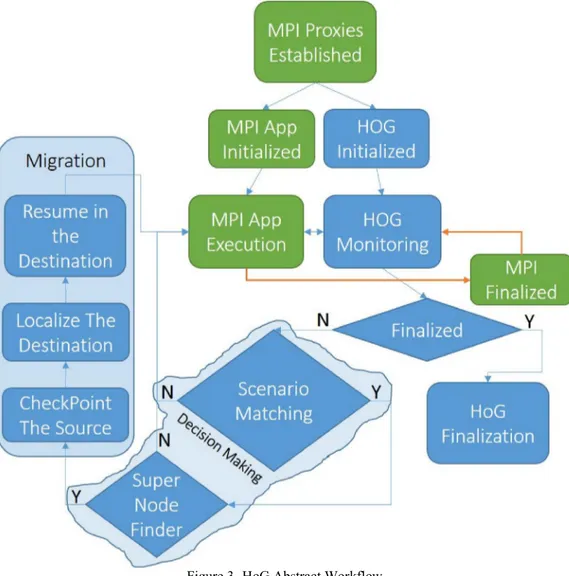
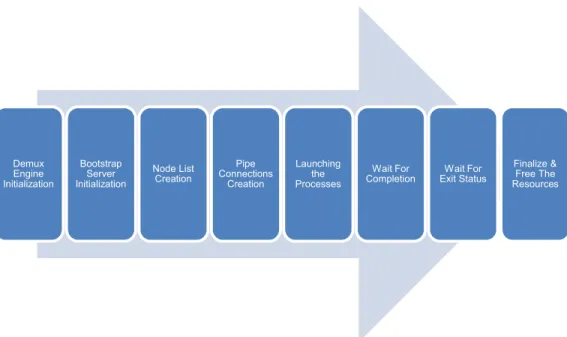
Benzer Belgeler
“İlmi ledün, mürşit, zikir, dört kapı, ilahi aşk, tevhit” gibi tasavvuf geleneğinin temlerini dile getiren Fedâî Baba, Alevi-Bektaşi geleneğine mensup olduğu
Arap dilinde, kapalı ve gizli olan anlamındaki bâtın kelimesiyle orijine geri dönmek, maksada yönelmek, bir şeyin akıbet ve sonucunu bildirmek gibi anlamlar içeren
Bugünkü bina, ahşap saray yık tırılmak suretile 1853 de Abdül- mecit tarafından Balyan usu ya yaptırtılmıştır.. Ampir üslubunda ki binanın dahilî
Çalışanlar tarafından haber uçurma (whistleblowing) iki şekilde yapılmaktadır; içsel whistleblowing (internal whistleblowing), haber uçuranın örgüt içindeki ahlaki
Sürdürülebilir kalkınmanın bir aracı olarak kabul gören sürdürülebilir turizmin gelecekteki fırsatları koruyup geliştirmeyi gözetmesi, turistlerin ve ev
Birinci basamak sağlık kuruluşlarında çalışan hekim dışı sağlık profesyonellerinin hizmet içi eğitim gereksinimlerinin belirlenmesi.. Amaç: Bu çalışmanın amacı,
Tablo 1’de yer alan analiz sonuçlarına göre araştırmaya katılan çalışanların duygusal tükenmişlik ile duyarsızlaşma düzeylerinin düşük düzeyde olduğu, kişisel
