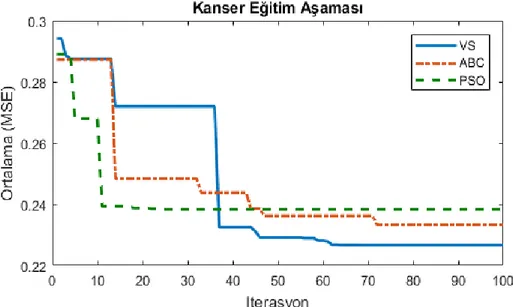
Yapay sinir ağlarının girdap arama algoritmasıyla eğitilmesi
Tam metin
Şekil
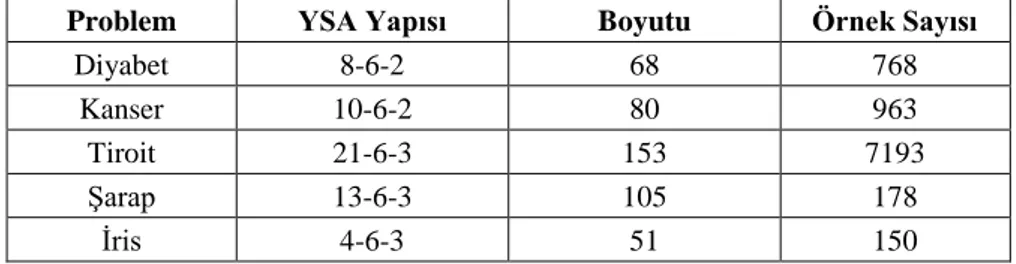
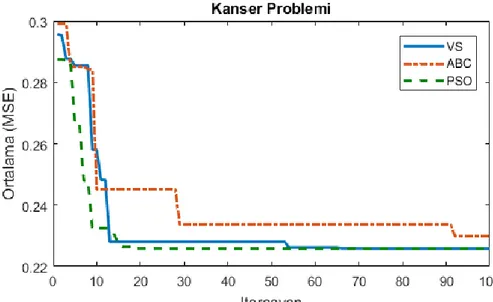
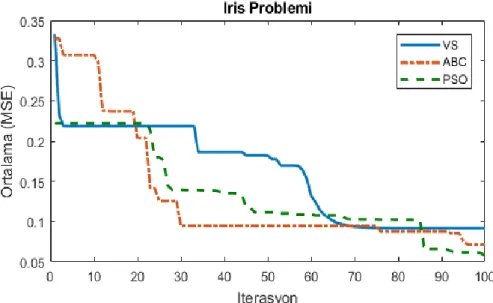



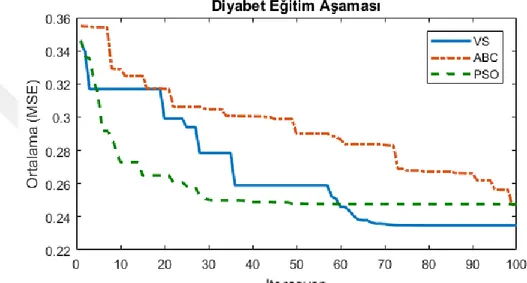


Benzer Belgeler
Şeyh Şamil’in asîl kanını taşıyan ve daha onaltı yaşında, Nevres Receb gibi Teşkilât-ı Mahsusa saflarına katılan Hamza Osman, arkadaşının yardımına
Onun, olduğundan başka türlü görünmek istemesini de, devrimiz de pazarlıksız muvahhidlere düşen j hicabı bira/ örtmek ve aşmak gibi, i maalesef yenemediği
Uzun bir dönem halk kütüphanesi hizmeti de veren halkevi 1951 yılında çıka- nlan 5830 sayılı Kanunla kapatılınca buradaki kütüphanede devre dışı
The Clinical and Radiological Evaluation of Canine Cranial Cruciate Ligament Rupture Treatment with Tibial Plateau Leveling Osteotomy. Radiographic evaluation and comparison of
Gesture pro- duction after focal brain injury has been mainly investigated with respect to intrasentential rather than dis- course-level linguistic processing. In this study,
Bu tezde uygulamalı matematik ve mekanik problemlerinin çözümünde çok kullanılan ve Lyapunov eğrileri olarak adlandırılan eğriler sınıfının bir genelleşmesi
There was a significant relationship be- tween increased AEG-1 staining scores and clear and non-clear carcinoma subtypes (p = 0.032) as well as between increased AEG-1 staining
1 Department of Horticulture, Agricultural Faculty, Harran University, Sanliurfa, Turkey 2 Faculty of Agriculture and Natural Science, Duzce University, Duzce, Turkey 3
