T.C. DOĞUŞ UNIVERSITY
INSTITUTE OF SCIENCE AND TECHNOLOGY
COMPUTER AND INFORMATION SCIENCES MASTER PROGRAM
A RULE BASED EXPERT SYSTEM
GENERATION FRAMEWORK
USING
AN OPEN SOURCE BUSINESS RULE ENGINE
M.S. Thesis
Gökhan POLAT
2003097002
ADVISOR :
Doç. Dr. Selim AKYOKUŞ
Associate Professor Dr. Selim Akyokuş
DECEMBER 2006
İ
stanbul
ACKNOWLEDGEMENTS
I would like to express special thanks to my supervisor Ass.Prof. Selim Akyokuş for his great support and encouragement. Without his help this thesis can not be completed. In addition, during master program and thesis study, my wife’s patient and help was incredible. These type of supports was luck for my entire study.
ABSTRACT
Knowledge is key instrument for the deciding processes. On the other hand, for a deciding process, gathering knowledge and learning are very difficult phases. For this reason, in the last decades, studies are focused on the machine-learning systems and the expert systems for the most of the knowledge oriented areas, like academic, commercial, military and industrial areas.
In this thesis, a framework is developed for the rule base learning expert systems. Briefly, this framework will take a data set, induct the rules from this data set, construct an expert system according to inducted rules, and give a web based interface for testing new cases.
There are a lot of concepts in this study. Classification, decision tree, knowledge acquisition, ID3 algorithm, rule base systems, expert systems, rule engines, open source perspective are some of them. These concepts will be discussed briefly, after the discussion; framework will be explained with some examples.
Examples will show the reusability of the framework. Different data set can be applied the framework. But data set must be convenient to the ID3 decision tree algorithm. Other restrictions will be defined next sections. After constructing expert system new cases can be tested.
This framework has some principles: • Java technologies are used
• Open source tools are used where needed • Standardizations are applied where available
ÖZET
Bilgi, karar verme süreçlerinde anahtar araçtır. Öte yandan, bir karar verme sürecinin en zor evreleri bilgiyi edinme ve öğrenmedir. Bu nedenle, akademik, ticari, askeri ve endüstriyel alanlar gibi bilgi merkezli pek çok alanda çalışmalar makina öğrenmesi sistemleri ve uzman sistemlere odaklanmıştır.
Bu tezle bir kural tabanlı öğrenen uzman sistem çatısı sunulmaktadır. Kısaca bu çatı uygun data kümesini alır, bu kümeden kurallar çıkarır, bu kurallara göre bir uzman sistem kurar ve yeni durumları test etmek için web tabanlı bir arayüz verir.
Bu çalışma birçok konuyu kapsamaktadır. Sınıflandırmalar, karar ağaçları, ID3 algoritması, kural tabanlı sistemler, uzman sistemler, kural motorları ve açık kaynak kodlu yaklaşım bunlardan bazılarıdır. Bu konular kısaca açıklanacak, değerlendirmeler sonrasında çatı örnekler ile açıklanacaktır.
Örnekler çatının yeniden kullanabilirliğini gösterecektir. Çatı uygulama, farklı data kümeleri ile çalışabilmelidir. Ancak seçilen data kümeleri ID3 algoritmasına uygun olmalıdır. Diğer kısıtlamalar ileriki bölümlerde açıklanacaktır.
Çatı aşağıdaki temel prensiplere dayanmaktadır.
• Java teknolojileri kullanılmıştır
• Gerekli durumlarda açık kaynak kodlu araçlar kullanılmıştır • Mümkün olduğunca standartlaştırma uygulanmıştır
TABLE OF CONTENTS
ACKNOWLEDGEMENTS... i
ABSTRACT... ii
ÖZET ... iii
LIST OF FIGURES... vi
LIST OF TABLES ... vii
ABBREVIATIONS... viii
1. INTRODUCTION ...1
1.1. Labor Intensive Knowledge-Based Approach...4
1.2. Automated Learning Approach ...4
2. GOAL AND ARCHITECTURE...5
3. MACHINE LEARNING - INDUCTIVE LEARNING...7
4. CLASSIFICATION RELATED BASIC CONCEPTS...10
4.1. Brief Explanation ...10
4.2. Types of Classification...10
4.3. Decision Table ...11
4.4. Decision Tree...11
4.4.1. When to Consider Decision Tree ...12
4.5. Comparison...13
5. BUILDING DECISION TREE - ID3...14
5.1. Data Set ...15
5.2. ID3 Algorithm ...15
5.2.1. Entropy ...16
5.2.2. Information Gain...17
5.2.3. Example Calculations with Weather Data Set ...18
5.3. ID3 Java Implementation ...20
5.3.1. Original Methods...21
5.3.2. New Methods ...22
6. RULE-BASED SYSTEMS...23
6.1. Requirements of a Rule-Based System ...23
6.2. Architecture of a Rule-Based System ...24
6.2.1. Inference Mechanism ...25
6.2.1.1. Forward Chaining Systems ...25
6.2.1.2. Backward Chaining Systems...26
6.2.2. Rule Base ...27
6.2.3. Working Memory...28
6.3. Rules...28
6.4. Rule Engine ...29
6.4.1. Advantages of the Rule Engine...29
6.4.2. Why and When to Use a Rule Engine? ...30
6.4.3. Which Rule Engine to Use?...31
6.4.4. RETE Algorithm ...31
7. JBOSS RULE AS AN OPEN SOURCE RULE ENGINE ...33
7.1. Open Source Perspective...33
7.2. Why Open Source? ...34
7.3. When Open Source?...35
7.4. JBoss Rule Engine ...36
7.5.2. Runtime...38
7.5.3. Drools Rule Base...39
7.5.4. Drools Working Memory ...39
7.5.5. Knowledge Representation ...41
7.5.5.1. Rules ...41
7.5.5.2. Facts...41
7.5.6. The Rule Language ...42
7.6. Using Drools (Simple Example)...42
8. STANDARDIZATION OF RULE ENGINE ...46
8.1. Architecture Of JSR-94...47
8.1.1. Runtime API ...47
8.1.2. Rules Administrator API ...48
8.2. Using JSR-94 With Drools (Simple Example)...49
9. A FRAMEWORK FOR A LEARNING EXPERT SYSTEM ...51
9.1. Requirements For The Framework ...51
9.2. Architecture of the Framework...52
9.2.1. Constructing Rule Base ...52
9.2.2. Web Based Interface...55
9.2.2.1. RuleExecuter ...55
9.3. Framework Example 1 ...58
9.4. Framework Example 2 ...60
10. RULE DECLARATION FILE (DRL FILES) EDITOR ...63
11. DISCUSSIONS ...65
12. CONCLUSION ...68
REFERENCES...69
APPENDIX I. JAVADOCS OF THE JAVA CLASSES ...72
APPENDIX II. JSP FILES ...99
LIST OF FIGURES
Figure 1.1 Classic transfer of expertise ...2
Figure 1.2 Bottleneck on the classic expert system...3
Figure 2.1 Brief representation of the framework...5
Figure 2.2 The architecture of the framework ...6
Figure 4.1 An example of decision table ...11
Figure 5.1 ID3 Algorithm ...16
Figure 5.2 Entropy Graph ...17
Figure 5.3 Which attribute to select?...19
Figure 5.4 Final decision tree for weather data set ...20
Figure 5.5 Permission from Dr.Benny Raphael...21
Figure 6.1 Interaction between OO and rule-based system ...24
Figure 6.2 Architecture of a rule-based system ...24
Figure 6.3 Forward chaining system ...26
Figure 6.4 Backward chaining system...27
Figure 7.1 JBoss authoring ...37
Figure 7.2 JBoss runtime ...38
Figure 7.3 Drools rule base...39
Figure 7.4 Drools Working Memory...40
Figure 7.5 Procedural IF and drools rule ...41
Figure 7.6 HelloWorld.drl file ...43
Figure 7.7 Required library for Drools...43
Figure 7.8 Importing Packages ...44
Figure 7.9 Returning a rule base ...44
Figure 7.10 Main part of the HelloWold example ...45
Figure 7.11 Message object ...45
Figure 8.1 Main part of JSR-94 compliant example ...49
Figure 8.2 Hello world JSR-94 example ...50
Figure 9.1 Java based projects for the framework ...52
Figure 9.2 Content of the Weather_DataSet.txt ...53
Figure 9.3 If-then-else form of ID3 output ...53
Figure 9.4 Rule list form of ID3 output...54
Figure 9.5 drl output of ID3 output ...54
Figure 9.6 Distinct values files...55
Figure 9.7 RuleExecuter method I ...56
Figure 9.8 RuleExecuter method II ...57
Figure 9.9 Example 1 choosing data set ...58
Figure 9.10 Example 1 testing new case ...59
Figure 9.11 Example 1 result page...60
Figure 9.12 Example 2 choosing data set ...61
Figure 9.13 Example 2 testing new case ...61
Figure 9.14 Example 2 result page...62
Figure 10.1 Rule file editor...63
LIST OF TABLES
Table 3.1 Deduction versus Induction...9 Table 4.1 Comparison of the models...13 Table 5.1 Weather Data set...18
ABBREVIATIONS
API Application Program Interface
ID3 Iterative Dichotomiser 3
J2EE Java 2 Enterprise Edition
J2SE Java 2 Standard Edition
JDK Java Development Kit
JSR Java Specification Request
LHS Left Hand Side
OO Object Oriented
OSS Open Source Software
RETE NET (latin)
RHS Right Hand Side
XML Extensible Markup Language
1. INTRODUCTION
Learning is very attractive concept for computer-based researches. There are a lot of methods for learning process. At the same time, a lot of result-based system uses these methods.
Learning capabilities are needed for intelligent systems that can remain useful in the face of changing environments or changing standards of expertise (Buchanan B.G., 1989)
Expert systems mostly need mentioned learning methods as a supporting system. In other words, this supporting system feeds the resulting expert system. Feeding methods are using some techniques to support expert systems , which are defined as;
• rule-based techniques • inductive techniques • hybrid techniques • symbol-manipulation techniques • case-based techniques • qualitative techniques • model-based techniques • temporal reasoning techniques • neural networks
In this thesis, rule-based techniques and inductive techniques are used to feed expert system. These two techniques are integrated as a new hybrid model. Before giving details of the new hybrid model, background of the expert system will be discussed.
An expert system’s central goal is to help professional in the process of shifting from old implementation to modern approaches, based on latest technologies. An expert system assists the human designer by efficient encoding of expert knowledge and by reusing the available systems.
The use of expert systems in the speed-up of human professional work has been in two orders of magnitude with resulting increases in human productivity and financial returns. Last decade shows that a growing number of organizations shift their informational systems towards a knowledge-based approach. This fact generates the need for new tools and environments that intelligently port the legacy systems in modern, extensible and scalable knowledge-integrated systems (Pop D. and Negru V., 2003).
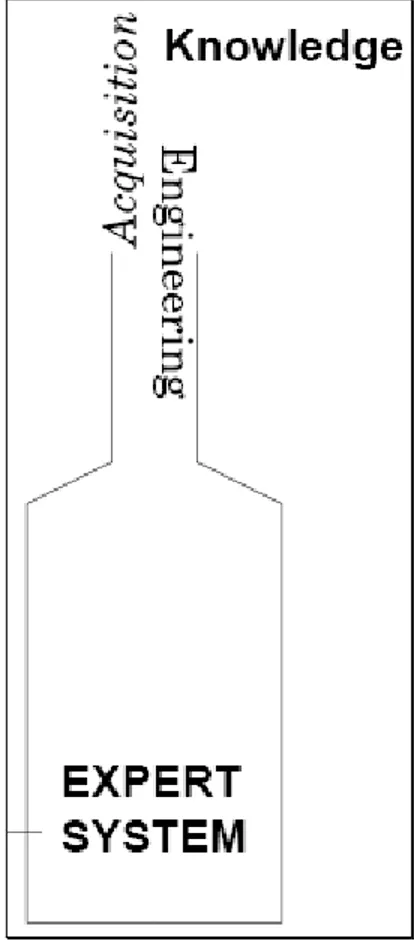
The most popular technique of knowledge acquisition is still done with an interaction with a human expert. A knowledge engineer, a person acquiring knowledge, interacts with an expert either by observation of the expert in action or by interview. As a result, rules are produced, first in plain English, later on in the coded form accepted by a computer. It is the responsibility of the knowledge engineer to acquire knowledge in such a way that the knowledge base is as complete as possible (Dobroslawa et al., 1995).
Classical expert system can also be explained in figured manner (Figure 1.1). As seen clearly on the explanations and the figure, human acts as a key role on the this picture.
Figure 1.1 Classic transfer of expertise (Buchanan B.G and Shortliffe E.H., 1984)
The process of working with an expert to map what he or she knows into a form suitable for an expert system to use has come to be known as knowledge engineering. We refer to the process of mapping an expert’s knowledge into a program’s knowledge base as knowledge engineering.
For the representation of knowledge in expert systems, a number of forms are used, such as: rules set (production rules, association rules, rules with exceptions), decision tables, classification and regression trees, instance-based representations, and clusters. Each
Main idea of this study is; an expert system may be built by human by means of a rule set, which is the natural way for humans to understand the knowledge. But limited capability of the human causes a bottleneck on the expert system (Figure 1.2). On the other hand, a decision tool , which uses some data mining methods, can make the process much more easier.
Figure 1.2 Bottleneck on the classic expert system (Buchanan B.G and Shortliffe E.H., 1984)
The knowledge needed to drive the pioneering expert systems was codified through protracted interaction between a domain specialist and a knowledge engineer. While the typical rate of knowledge elucidation by this method is a few rules per man day, an expert system for a complex task may require hundreds or even thousands of such rules (Quinlan, J.R., 1985).
To avoid drawbacks of the knowledge-based systems, in this thesis, learning-based methodology is used. At this point, to be clear on the framework structure, summarized comparison of the knowledge-based and learning-based approaches is needed.
1.1. Labor Intensive Knowledge-Based Approach
Human experts construct a set of rules with which concepts can be identified in a text Advantages :
• Human experience can be used to quickly distinguish good rules from bad ones Disadvantages :
• Laborious, time-intensive development process • Requires the availability of human expertise
1.2. Automated Learning Approach
Automated learning algorithms induce a model with which concepts can be identified in a an example data set . Learning requires :
• a goal-directed process of a system that improves the knowledge or the knowledge representation of the system by exploring experience and prior knowledge
• acquisition of new declarative knowledge
• development of motor and cognitive skills through instruction and practice • organization of new knowledge into general effective representation
• discovery of new facts and theories through observation and experimentation • a process of knowledge construction, not of knowledge recording or absorption Advantages :
• There is no need for human experts
• Techniques are largely domain independent • Exceptions are not likely to be overlooked Disadvantages :
• (Large amounts of) example data are required to train most common machine learning algorithms
2. GOAL AND ARCHITECTURE
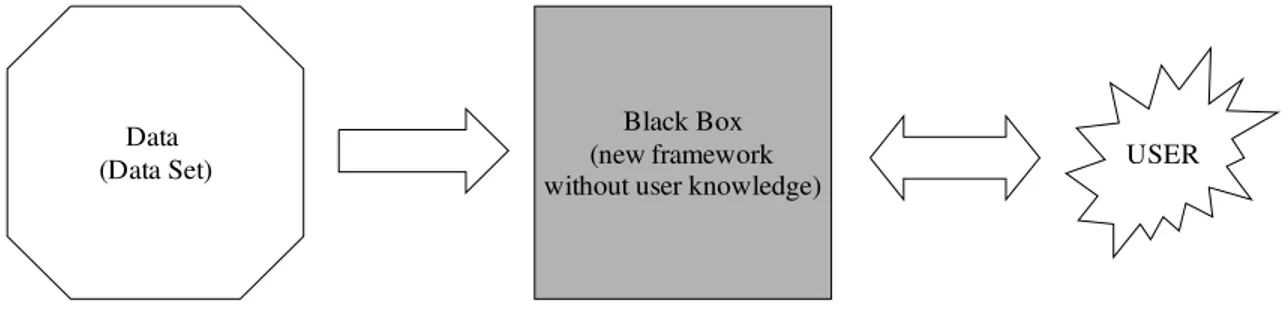
Data (Data Set)
Black Box (new framework
without user knowledge) USER
Figure 2.1 Brief representation of the framework
As explained in the introduction, an automated learning methodology for rule generation is more reasonable approach for expert systems. This approach has a superiority against to the knowledge-based systems besides some drawbacks. On the other hand, better observations and researches can produce large and good enough example data. One of the assumptions of this study is that; data should be reasonable.
This thesis presents a complete framework for constructing an expert system. This framework based on learning approach, can also be expressed as rule-based.
This expert system framework includes:
• Uses convenient data set
• Uses decision tree data mining method as a learning method • Uses ID3 decision tree algorithm
• Automatic rule generation • Uses JBossRule engine • Generates rule file
• Generates web based interface for test new cases • Uses open source products
Data
(Data Set) Data Formatting
Reasonable Data Set Rule Formation ID3 Decision Tree Algorithm List of Rules
Inference Engine Web Interface USER
3. MACHINE LEARNING - INDUCTIVE LEARNING
After the words about base of expert system and learning approach, machine learning and inductive learning should be explained briefly. Because the field of machine learning in concerned with the question of how to construct computer programs that automatically improve with experience, this concept should be clear.
Knowledge-based systems are relatively old structures. A newer paradigm, generally considered to be the machine learning approach, has attracted attention of researchers in artificial intelligence, computer science, and other functional disciplines such as engineering, medicine, and business. In contrast to Knowledge-based systems which acquire knowledge from human experts, machine learning systems acquire knowledge automatically from examples, i.e., from source data. Machine learning refers to a system capable of the autonomous acquisition and integration of knowledge. This capacity to learn from experience, analytical observation, and other means, results in a system that can continuously self-improve and thereby offer increased efficiency and effectiveness.
Knowledge acquisition is the transfer and transformation of problem-solving expertise from some knowledge source to a program. Learning from examples may automate much of the knowledge acquisition process by exploiting large data bases of recorded experience (Buchanan B.G and Shortliffe E.H., 1984).
To gain a knowledge, machine learning techniques, as rote learning, learning by being told, learning by analogy, learning from examples, and learning from discovery, have been studied extensively by AI researchers over the past two decades. Among these techniques, learning from examples, a special case of inductive learning appears to be the most promising machine learning technique for knowledge discovery or data analysis. It induces a general concept description that best describes the positive and negative examples.
Machine-learning approaches commonly used for classification include inductive-learning algorithms such as decision-tree induction and rule induction, instance-based learning , neural networks, genetic algorithms, and Bayesian-learning algorithms. Among the various machine-learning approaches developed for classification, inductive learning from instances
is the most commonly used method in real-world application domains. Inductive learning techniques are fast compared to other techniques. Another advantage is that inductive learning techniques are simple and their generated models are easy to understand. Finally, inductivelearning classifiers obtain similar and sometimes better accuracies compared with other classification techniques (Pham D. T. and Afify A. A., 2004).
Inductive learning has received considerable attention since the 1950s. Nowadays some approaches (eg. some growing toolkit of programs) can assist in knowledge acquisition (Buchanan B.G., 1989).
Induction refers to inference of a generalized conclusion from particular instances. Inductive learning techniques are used to automatically construct classifiers using labeled training data. Different inductive learning algorithms was developed, some of them are listed below;
• Decision Trees
• Find Similar (a variant of Rocchio’s method for relevance feedback) • Naïve Bayes
• Bayes Nets
• Support Vector Machines (SVM)
All methods require only on a small amount of labeled training data (i.e., examples of items in each category) as input. This training data is used to “learn” parameters of the classification model. (Dumais et al., 1998)
Conventional knowledge based system’s inference mechanism is deductive. On the other hand learning systems use inductive structure. To understand difference between deduction and induction a table is constructed (Table 3.1). As seen from this table induction helps us for generalization. Whereas deduction goes from general to specific, induction, generates hypotheses, goes from specific to general .
Table 3.1 Deduction versus Induction
Deduction Induction
All humans are mortal. (Axiom) Socrates is human. (Background K.) Socrates is human. (Fact) Socrates is mortal. (Observation(s))
Conclusion: Generalization:
Socrates is mortal. All humans are mortal.
Inductive-learning techniques can be divided into two main categories, namely, decision-tree induction and rule induction (Pham D. T. and Afify A. A., 2004).In this study, decision tree induction and rule induction are used as a composite inductive learning method. Decision tree method will be explained in detail in the next sections.
4. CLASSIFICATION RELATED BASIC CONCEPTS
As described previous sections in this thesis, decision tree algorithm is chosen as an inductive learning method which is the one of the best machine learning techniques. The inductive learning can be done with classification methods. Classification is one of the most important data mining tasks. In this chapter, classification will be explained briefly.
4.1. Brief Explanation
Classification is a key data mining technique whereby database tuples, acting as training samples, are analyzed in order to produce a model of the given data . Each tuple is assumed to belong to a predefined class, as determined by one of the attributes, called the classifying attribute. Once derived, the classification model can be used to categorize future data samples, as well as provide a better understanding of the database contents. Classification has numerous applications including credit approval, product marketing, and medical diagnosis (Kamber et al.,1997).
4.2. Types of Classification
A number of classification techniques from the statistics and machine learning communities have been proposed. These techniques are also called as classification algorithms.
Algorithms that classify a given instance into a set of discrete categories are called as classification algorithms. These algorithms work on a training set to come up with a model or a set of rules that classify a given input into one of a set of discrete output values. Most classification algorithms can take inputs in any form, discrete or continuous although some of the classification algorithms require all of the inputs also to be discrete. The output is always in the form of a discrete value. Decision trees and Bayes nets are examples of some of classification algorithms (Polumetla A., 2006).
This thesis focuses decision tree algorithm, because it fits the main goal of the study. On the other hand an other method, decision table will be explained and the differences between two decision methods will be described.
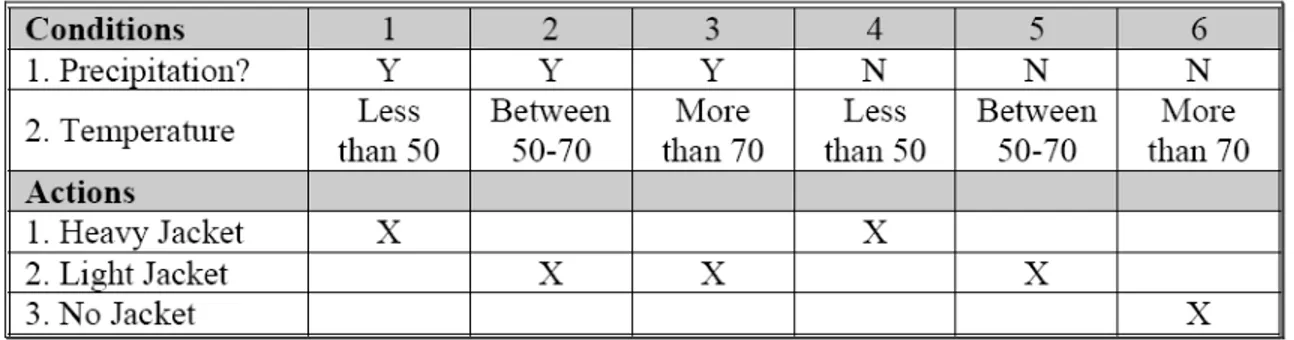
4.3. Decision Table
A decision table consists of a two-dimensional array of cells, where the columns contain the system’s constraints and each row makes a classification according to each cell’s value (Pop D. and Negru V., 2003). A decision table consists of a two-dimensional array of cells. Associated with each row in the array is a classification. A decision table can be viewed as a conjunction of row rules. An example of the decision table can be seen in Figure 4.1.
Figure 4.1 An example of decision table (Kolahi S., 2006)
4.4. Decision Tree
Decision tree are commonly used for gaining information for the purpose of decision-making. Decision tree starts with a root node on which it is for users to take actions. From this node, users split each node recursively according to the decision tree learning algorithm. The final result is a decision tree in which each branch represents a possible scenario of decision and its outcome.
In summary, the systems described here develop decision trees for classification tasks. These trees are constructed beginning with the root of the tree and proceeding down to its leaves. (Quinlan, J.R., 1985).
4.4.1. When to Consider Decision Tree
Decision trees are considered as an efficient technique to express classification knowledge and to use it. Their success is explained by their ability to handle complex problems by providing an understandable representation easier to interpret and also their adaptability to the inference task by producing logical rules of classification (Elouedi et al.,2000).
Decision trees are useful for automating decision processes that are part of an application program. Decision trees are used in a large number of applications, and the number continues to grow as practitioners gain experience in using trees to model decision making processes. Present applications include various pixel classification tasks, language understanding tasks such as pronoun resolution, fault diagnosis, control decisions in search, and numerical function approximation (Utgoff P.E., 1995).
Decision tree learning algorithm is suited when
• Instance is represented as attribute-value pairs. For example, attribute 'Temperature' and its value 'hot', 'mild', 'cool'. We are also concerning to extend attribute-value to continuous-valued data (numeric attribute value) in our project.
• The target function has discrete output values. It can easily deal with instance which is assigned to a boolean decision, such as 'true' and 'false', 'p(positive)' and 'n(negative)'. Although it is possible to extend target to realvalued outputs, we will cover the issue in the later part of this report.
• The training data may contain errors. This can be dealt with pruning techniques that
4.5. Comparison
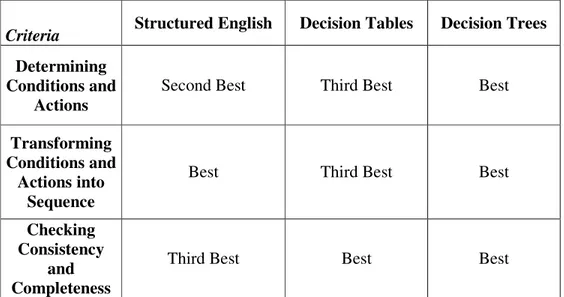
Table 4.1 Comparison of the models
Criteria Structured English Decision Tables Decision Trees Determining
Conditions and Actions
Second Best Third Best Best
Transforming Conditions and
Actions into Sequence
Best Third Best Best
Checking Consistency
and Completeness
Third Best Best Best
The decision table and decision tree are essential tools for systems analysts. These decision aids are used by systems analysts in depicting conditional logic for programmers and in validating this logic with the user. In addition, many authors recommend the decision table and tree as useful aids in decision making (Subramanian G.H et al., 1989).
A rule can be defined by structured English words, a decision table and a decision tree. All three methods have some advantages and drawbacks. Table 4.1 shows that decision tree is the most effective method for defining rule according to specified criteria.
5. BUILDING DECISION TREE - ID3
Several methods have been proposed to construct decision trees. These algorithms input the training set composed by instances where each one is described by the set of attribute values and its assigned class. The output is a decision tree ensuring the classification of new instances
Decision tree learning algorithm has been successfully used in expert systems in capturing knowledge. The main task performed in these systems is using inductive methods to the given values of attributes of an unknown object to determine appropriate classification according to decision tree rules.
ID3 is a simple decision tree learning algorithm developed by Ross Quinlan (1983). The basic idea of ID3 algorithm is to construct the decision tree by employing a top-down, greedy search through the given sets to test each attribute at every tree node. In order to select the attribute that is most useful for classifying a given data set, a metric called information gain, which will be defined later, is used.
ID3 is used as a machine learning methods which induces a rule set that is a subset of all potential rules hidden in the original data set. Successful applications of ID3, C4 and other decision tree algorithms have provided knowledge bases for working expert systems whose task is to classify. They are widely used in a variety of fields notably in artificial intelligence applications. Their success is explained by their ability to handle complex problems by providing an understandable representation easier to interpret and also their adaptability to the inference task by producing logical rules of classification (Elouedi et al. 2000).
One approach to the induction task above would be to generate all possible decision trees that correctly classify the training set and to select the simplest of them. The number of such trees is finite but very large, so this approach would only be feasible for small induction tasks. ID3 was designed for the other end of the spectrum, where there are many attributes and the training set contains many objects, but where a reasonably good decision tree is required without much computation. It has generally been found to construct simple decision trees, but
The basic structure of ID3 is iterative. A subset of the training set called the window is chosen at random and a decision tree formed from it; this tree correctly classifies all objects in the window. All other objects in the training set are then classified using the tree. If the tree gives the correct answer for all these objects then it is correct for the entire training set and the process terminates. If not, a selection of the incorrectly classified objects is added to the window and the process continues(Quinlan, J.R., 1985).
5.1. Data Set
This study assumes that data is correct and classifiable. A measurement by a specific variable is the assignment of a specific value to that variable, notionally by the real-world process. The value set belonging to a variable is a discrete set of names, usually describing qualitative properties. A value set must have at least two members. The prototypical case is a boolean variable with values {true, false}, but other value sets are possible: for example the variable sex has the value set {male, female}. If a variable refers to a continuous measurement, its value set frequently names the results of a series of relational tests on the measurement The basis is a universe of objects that are described in terms of a collection of attributes. Each attribute measures some important feature of an object and will be limited here to taking a (usually small) set of discrete, mutually exclusive values(Quinlan, J.R., 1985).
5.2. ID3 Algorithm
Several algorithms have been developed for learning decision trees. In the artificial intelligence community, the most used is based on the TDIDT (Top-Down Induction of Decision Tree) approach. In that approach, the tree is constructed by employing a recursive divide and conquer strategy. Its steps can be defined as follows:
• By using an attribute selection measure, an attribute will be chosen in order to partition the training set in an ”optimal” manner.
• Based on a partitioning strategy, the current training set will be divided into training subsets by taking into account the values of the selected attribute.
In the literature many attribute selection measures are proposed in. Among the most used, we mention the information gain used within the ID3 algorithm. The information gain of an attribute A relative to a set of objects S measures the effectiveness of A in classifying the training data.
Algorithm is defined in Figure 5.1.
Figure 5.1 ID3 Algorithm (Yüret D., 2003)
5.2.1. Entropy
Entropy, characterizes the (im)purity of an arbitrary collection of examples. That is, it measures the homogeneity of examples. Entropy equation for two classes positive and negative is below;
Where
S is a sample of training examples
p
p is the proportion of positive examples in S
n
p is the proportion of negative examples in S
In summary; entropy is expected number of bits needed to encode class (p or n) of randomly drawn member of S.
If all instances in S belong to the same class, then E(S) equals 0.
If S contains the same number of instances for each class, then E(S) equals 1.
Figure 5.2 Entropy Graph
5.2.2. Information Gain
Information gain is the answer of the “How do we choose the best attribute?” question in decision tree algorithm.
In order to measure the worth of an attribute a statistical property is defined, information gain, which measures how well a given attribute separates the training examples according to their target classification.
Information Gain equation is given;
) ( ) ( ) , ( ) (
∑
∈ − ≡ A Values v v v S Entropy S S S Entropy A S Gain (Equation 5.2)The information gain Gain(S,A) is the expected reduction in entropy caused by knowing the value of the attribute A.
5.2.3. Example Calculations with Weather Data Set
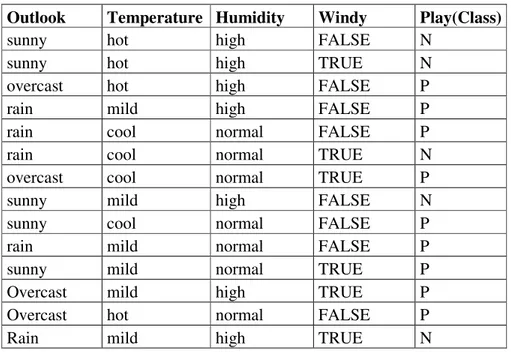
The weather problem is a example data set which we will use to understand how a decision tree is built. It comes from Quinlan’s paper which discusses the ID3 algorithm. It is reproduced with slight modifications by Witten I.H., Frank E. (1999), and concerns the conditions under which some hypothetical outdoor game may be played. The data is shown in Table 5.1.
Table 5.1 Weather Data set
Outlook Temperature Humidity Windy Play(Class)
sunny hot high FALSE N
sunny hot high TRUE N
overcast hot high FALSE P
rain mild high FALSE P
rain cool normal FALSE P
rain cool normal TRUE N
overcast cool normal TRUE P
sunny mild high FALSE N
sunny cool normal FALSE P rain mild normal FALSE P sunny mild normal TRUE P Overcast mild high TRUE P Overcast hot normal FALSE P
In this dataset, there are five categorical attributes outlook, temperature, humidity, windy, and play. We are interested in building a system which will enable us to decide whether or not to play the game on the basis of the weather conditions, i.e. we wish to predict the value of play using outlook, temperature, humidity, and windy. We can think of the attribute we wish to predict, i.e. play, as the output attribute, and the other attributes as input attributes.
Figure 5.3 Which attribute to select?
Calculation for the entropy of the humidity attribute is as follows
H(D) = -(9/14) log (9/14) - (5/14) log (5/14) = 0.94
H(D, Humidity = High) = -(3/7) log (3/7) - (4/7) log (4/7) = 0.985 H(D, Humidity = Normal) = -(6/7) log (6/7) - (1/7) log (1/7) = 0.592
Calculation for the information gain of the humidity attribute;
Gain(D, Humidity) = 0.94 - (7/14) * 0.985 + (7/14) * 0.592 = 0.151
Similarly, for wind attrbute;
Gain (D, Wind) = 0.94 - (8/14) * 0.811 + (6/14) * 1.0 = 0.048
Gain(D, Humidity) = 0.151 bits Gain(D, Wind) = 0.048 bits
Gain(D, Temperature) = 0.029 bits Gain(D, Outlook) = 0.246 bits
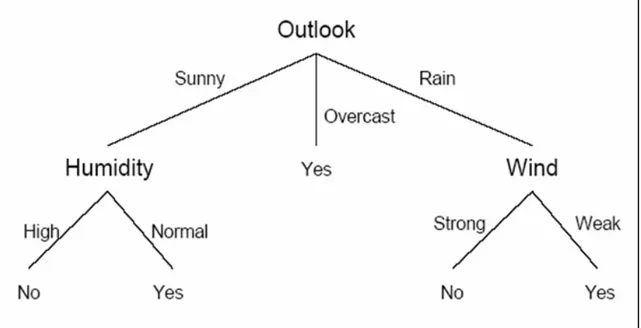
Clearly, outlook is the highest gain, so this should be the root node. According to the algorithm, the procedure should continue recursively until the end. After that, the result tree can be obtained as seen in Figure 5.4.
Figure 5.4 Final decision tree for weather data set
5.3. ID3 Java Implementation
In this thesis, java technologies are used for all implementations. On the other hand, ID3 java implementation is not developed by the author. It is originally developed by Dr.Benny Raphael. With his permission, some modifications are done for the framework adaptation.
Figure 5.5 Permission from Dr.Benny Raphael
Important methods of the Dr. Benny Raphael’s implementation and our modifications are below. Furthermore, its javadoc parts in the Appendix section.
5.3.1. Original Methods
readData : Function to read the data file. The first line of the data file should contain the
names of all attributes. The number of attributes is inferred from the number of words in this line. The last word is taken as the name of the output attribute. Each subsequent line contains the values of attributes for a data point. If any line starts with // it is taken as a comment and ignored. Blank lines are also ignored.
calculateEntropy : Calculates the entropy of the set of data points. The entropy is calculated
using the values of the output attribute which is the last element in the array attributes.
decomposeNode : This function decomposes the specified node according to the ID3
algorithm. Recursively divides all children nodes until it is not possible to divide any further.
printTree : This function prints the decision tree in the form of if/then/else structure. The
action part of the rule is of the form outputAttribute = "symbolicValue" or outputAttribute = { "Value1", "Value2", .. } The second form is printed if the node cannot be decomposed any further into an homogenous set.
5.3.2. New Methods
listRules : This function prints the rules as a sentence.
createRules4File : This function exports the rules to a .drl file which is used for JBossRule
6. RULE-BASED SYSTEMS
Rule-based systems are a very simple model that can be used to solve many decision problems. Instead of representing knowledge in a relatively declarative, static way, rule-based system represent knowledge in terms of a bunch of rules. A rule-based system consists of a bunch of IF-THEN rules, a bunch of facts, and some interpreter controlling the application of the rules, given the facts.
Rule-Based systems maintain a small database of facts about the world, so that they can perform reasoning; if a fact about the world matches a condition of a rule, that condition is judged to be fulfilled (Kingston J., 1987).
In Summary, a rule-based system can be defined as a system that uses rules to derive conclusions from premises.
6.1. Requirements of a Rule-Based System
• A set of facts to represent the initial working memory. This should be anything relevant to the beginning state of the system.
• A set of rules. This should encompass any and all actions that should be taken within the scope of a problem, but nothing irrelevant. The number of rules in the system can affect its performance.
• A condition that determines that a solution has been found or that none exists. This is
necessary to terminate some rule-based systems that find themselves in infinite loops otherwise.
A rule-based system works by applying the rules that are applicable to the current state of the system. At the beginning, the “working memory” consists of the description of the initial state of the system. It then finds all the rules that are applicable to this state.
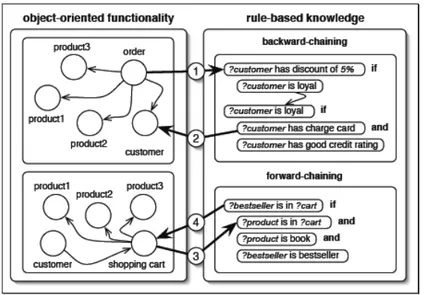
In this study, facts are objects (java beans) which are asserted into the working memory. Facts are any java objects which the rules can access. Detailed explanation about framework is given on the section 10 and interaction between object-oriented functionality and rule-based knowledge is described in Figure 6.1.
Figure 6.1 Interaction between OO and rule-based system (Maja D., 2004)
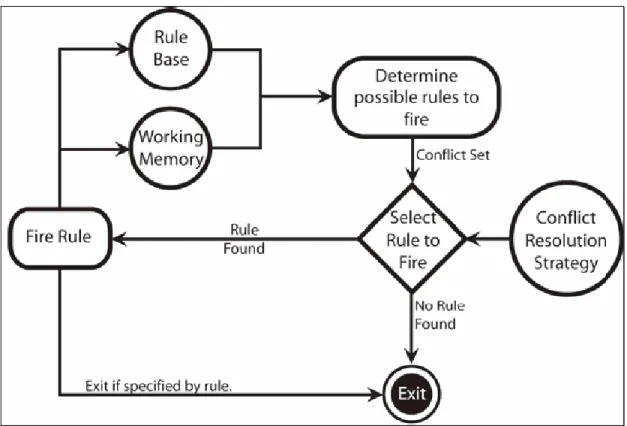
6.2. Architecture of a Rule-Based System
A typical rule-based system contains below items. It can be also seen in the Figure 6.2. • An inference engine • A rule base • A working memory User Interface Rule Base Inference Engine Working Memory
6.2.1. Inference Mechanism
The way knowledge systems model human reasoning is called inference. The inference engine is a component of a rule engine that fires the rules.
Many rule-based expert systems are developed using expert system shells. A shell provides facilities for writing rules easily, often in a format which resembles English syntax, and also provides a strategy for solving problems in general - that is, it has built-in algoithms for deciding which rule is to be used when. This strategy is known as the shell's inference mechanism. A shell can be thought of as a rule-based expert system without any knowledge, or a framework around which an expert system can be developed.
An inference mechanism consists of algorithms and the rules in a rule base. There are two methods for executing rules in rule-based systems, forward chaining and backward chaining.
6.2.1.1. Forward Chaining Systems
Forward chaining searches the inference rules until it finds one where the “If” clause is known to be true. When found it can conclude, or infer, the “Then” clause, resulting in the addition of new information to its dataset.
Forward-chaining systems are data-driven. The facts in such systems are represented in a working memory that is continually updated. Furthermore, in these systems rules represent possible actions to take when specified conditions hold on items in the working memory, they are sometimes called condition-action rules. The conditions are usually patterns that must match items in the working memory, while the actions usually involve adding or deleting items from the working memory.
Figure 6.3 Forward chaining system (Chan S. T. and Gröndahl F., 2005)
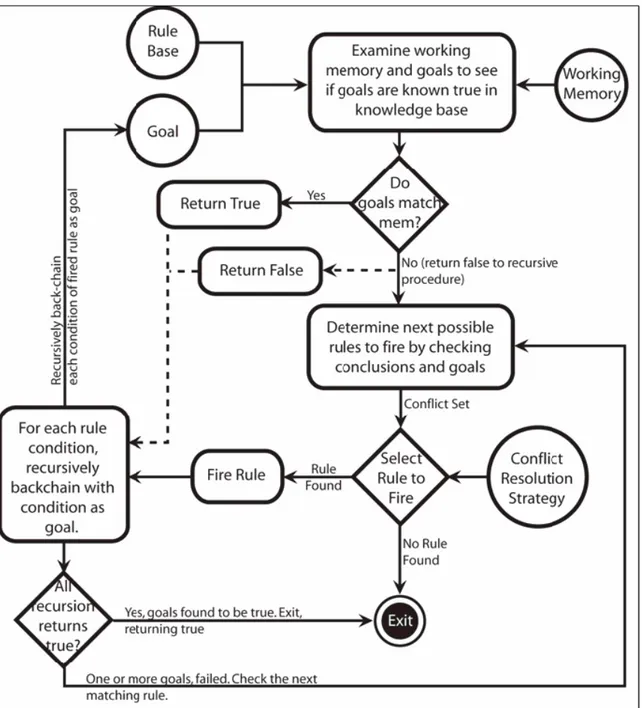
6.2.1.2. Backward Chaining Systems
Backward chaining would search the inference rules until it finds one which has a “Then” clause that matches a desired goal. If the “If” clause of that inference rule is not known to be true, then it is added to the list of goals (in order for your goal to be confirmed you must also provide data that confirms this new rule).
Backward-chaining systems are goal-driven. These systems look for the action in the THEN clause of the rules that matches the specified goal. In other words, they look for the rules that can produce this goal. If a rule is found and fired, they take each of that rule’s conditions as goals and continue until either the available data satisfies all of the goals or there are no more rules that match.
Figure 6.4 Backward chaining system (Chan S. T. and Gröndahl F., 2005)
6.2.2. Rule Base
The rules need to be stored somewhere. The rule base contains all the rules the system knows. They may simply be stored as strings of text, but most often a rule compiler processes them
into some form that the inference engine can work with more efficiently (Chanda M. S.,2004).
The rule base contains specific knowledge about the problem area presented in rules. Rules, in the form “if - then” are elementary units of knowledge (Dobroslawa et al., 1995).
6.2.3. Working Memory
In a typical rule engine, the working memory, sometimes called the fact base, contains all the pieces of information the rule-base system is working with. The working memory can hold both the premises and conclusions (result objects) of the rules. Some implementations can hold only objects of a specific type, and others can include objects of any type, for example Java objects (Chanda M. S.,2004).
The working memory holds concrete data in the form of the object-attribute-value triplets. The data is used by the rule engine to match to the rules’ conditions. Two possibilities arise:
1. If one of the rule conditions has no variables, then it is satisfied only if an identical expression is present in the working memory
2. If one of the rule conditions has at least one variable, i.e. if it is a pattern, then it is satisfied only if there exists data in working memory which matches it, taking into account the rule’s other conditions that have been matched (D’Hondt M., 2004).
6.3. Rules
Rules are similer to the if-then statements of traditional programming languages. An order rule can look like this, in an English-like pseudocode:
IF
A student is in the laboratory AND
He/She is hungry THEN
In the simplest design, a rule is an ordered pair of symbol strings, with a left-hand side and a right-hand side (LHS and RHS). A rule can also be viewed as a simple conditional statement, and the invocation of rules as a sequence of actions chained by modus ponens.
A rule consists of two parts: an antecedent and a consequent. The rule antecedent consists of one or more conditions that specify when and where to apply the rule. If the conditions of the rule are met, then the second part of a rule – the consequent – specifies the actions to take when the conditions of the rule are met.
Rules are generally used to represent knowledge about strategies for solving problems in a particular area (Kingston J., 1987).
Basically two different formalisms of expressing rules exist, production rules, used in production systems, and first-order predicate logic used in logic-based systems. Production systems consist of three parts, the production rules, the working memory and the rule engine (Rosenberg F. and Dustdar S., 2005).
Obviously, production system means rule-based system and production rules are one of the major part of the constructed rule-based system in this study.
6.4. Rule Engine
The term “Rule Engine” can be defined for any system that uses rules, in any form, that can be applied to data to produce outcomes; which includes simple systems like form validation and dynamic expression engines.
6.4.1. Advantages of the Rule Engine
• Declarative Programming : Rule engines allow you to say "What to do" not "How to do it". They key advantage of this point is that it can make it easy to express solutions to hard problems, and consequently have those solutions verified (rules are much easier to read then code). Rule systems are capable of solving very hard problems, yet providing a solution that is able to explain why a "decision" was made.
• Logic and Data Separation : Your data is in your domain objects, the logic is in the rules.
• Speed and Scalability : The Rete algorithm, Leaps algorithm, and its descendents, provide very efficient ways of matching rule patterns to your domain object data. • Centralization of Knowledge : By using rules, you are creating a repository of
knowledge which is executable.
• Tool Integration : Tools such as eclipse provide ways to edit and manage rules and get immediate feedback, validation and content assistance. Auditing and debugging tools are also available.
• Explanation facility : Rule systems effectively provide an "explanation facility" by being able to log the "decisions" made by the rule engine (and why the decisions were made). Understandable rules (readable by domain experts). By creating object models that model your problem domain, rules can look very close to natural language. They lend themselves to logic that is understandable to domain experts who may be non technical.
6.4.2. Why and When to Use a Rule Engine?
While rule engines can solve a lot of problems for us , it is worth considering if a rule engine is appropriate for the application. Some important points are:
• Application Complexity : For applications that shuffle data to and from a database , but not much more , it is probably best not to use a rules engine. However , where there is even a moderate amount of processing, it is worthwhile considering the use of rule engine. This is becuase most applications develop complexity over time and rule engine will let you cope easily with this.
• Application Lifetime : Using a rule engine pays off especially in the medium to long term. Prototypes can benefit from the combination of rule engine and agile methods to take the 'prototype' into production.
• Application updates : The only sure thing about your requirements is that they will change, either during or just after development. A rule engine helps to cope with this by specifying the business rule in one or more easy to configuration files.
6.4.3. Which Rule Engine to Use?
There are many business rule engines on the market, both open source and commercial. Here is a list of the most popular commercial business rule engines (Chanda M. S.,2004):
• JRules from ILOG • Advisor from Brokat • OPSJ from Charles Forgey
• QuickRules from Yasu Technologies • CommonRules from IBM alphaworks • exteNd Director from Novell
• ACQUIRE from acquired Intelligence
The list of the most popular open source rule engines is as follows:
• JBoss Rule Engine
• JESS (Java Expert System Shell) from Sandia National Labs • Mandarax
• CLIPS from Gary Riley
• InfoSapient
In this study, JBoss Rule Engine is used as a rule engine. One of the major reason is that this rule engine is an open source rule engine. Why open source question will be explained next section.
6.4.4. RETE Algorithm
The RETE algorithm was invented by Dr. Charles Forgy and documented in his PHd thesis in 1978-79 (Forgy C., 1979),. A simplified version of the paper was published in 1982.
There are many methods for optimizing rule engines to execute rules more efficiently. Most rule engines use the Rete (Latin for `net') Algorithm for optimization. This algorithm is intended to improve the speed of forward-chained rule-based engines by limiting the effort
required to re-compute a conflict set after a rule is fired. In the Rete algorithm, executable rules are compiled into a network. Input data to the network consists of changes to the working memory. Objects are inserted, removed, and modified. The network processes these changes and produces a new set of rules to be fired. The network minimizes the number of evaluations by sharing tests between rules and propagating changes incrementally. Briefly, the rete algorithm eliminates the inefficiency in the simple pattern matcher by remembering past test results across iterations of the rule loop. Only new or deleted working memory elements are tested against the rules at each step. Furthermore, Rete orgonizes the pattern matcher so that these few facts are only tested against the subset of rules that may actually match. The main drawback of this algorithm is its high memory space requirement.
7. JBOSS RULE AS AN OPEN SOURCE RULE ENGINE
7.1. Open Source Perspective
Although there is considerable confusion about the strengths and weaknesses of open source software (OSS), it has become clear that OSS has an important role to play in the IT industry and business in general. OSS, for the most part, represents a software development process. It can be leveraged to provide considerable value and complement commercial software products. At the same time, commercial software products will continue to play a critical role for the foreseeable future (Heintzman D., 2003)..
The IT industry is going through major changes. New concepts in technology, such as Web services and grid computing, are opening the door to tremendous opportunities for taking e-business to the next level of profitability. The potential of these technologies to transform business is truly remarkable, and open standards and open source software will play increasingly critical roles in this new world.
To clear the open source concept some definition should be placed.
Open source software : Is the software whose source code is published and made available
to the public, enabling anyone to copy, modify and redistribute the source code without paying royalties or fees. Open source code evolves through community cooperation. These communities are composed of individual programmers as well as very large companies. Some examples of open source initiatives are Linux, Eclipse, Apache, Mozilla, and various projects hosted on SourceForge.
Free software : Is the terms that are roughly equivalent to Open Source. The term "free" is
meant to describe the fact that the process is open and accessible and anyone can contribute to it. "Free" is not meant to imply that there is no charge. "Free software" may be packaged with various features and services and distributed for a fee by a private company. The term "public domain" software is often erroneously used interchangeably with the term "free software" and "open source" software. In fact, "public domain" is a legal term that refers to software whose
copyright is not owned by anyone, either because it has expired, or because it was donated without restriction to the public. Unlike open source software, public domain software has no copyright restrictions at all. Any party may use or modify public domain software.
Commercial software : Is the software that is distributed under commercial license
agreements, usually for a fee. The main difference between the commercial software license and the open source license is that the recipient does not normally receive the right to copy, modify, or redistribute the software without fees or royalty obligations. Many people use the term "proprietary software" synonymously with "commercial software." Because of the potential confusion with the term "proprietary" in the context of standards and interfaces, and because commercial software may very well implement open, non-proprietary interfaces, this article will use the term "commercial software" to refer to non-open source software (Heintzman D., 2003).
7.2. Why Open Source?
The most obvious boon of open source to software developers is the opportunity to base a design on existing software elements. The open source community gives us a rich base of reusable software, typically available at the cost of downloading the code from the Internet. So, in many cases we can select best code to reuse in our system without having to reinvent the wheel. The resulting products benefit in two ways. First, the reused open source code will typically be of higher quality than the custom-developed code’s first incarnation. Second, the functionality the reused element offers will often be far more complete than what the bespoke development would afford (Spinellis D. and Szyperski C. , 2004),.
Moreover, reuse granularity is not restricted by the artificial product boundaries of components distributed in binary form (which marketing considerations often impose). When reusing open source, code adoption can happen at the level of a few lines of code, a method, a class, a library, a component, a tool, or a complete system. Furthermore, when software is available in source code form, we can more easily port to our target platform and adjust its interfaces to suit our needs.
Consequently, software reuse possibilities open up on three axes: what to reuse (promoted by the available software’s breadth and price), how to reuse it (diverse granularity and interfacing options), and where to reuse it (inherent portability of source code over most binary packaged component technologies). Movement along all three axes increases the breadth of software reuse opportunities in any development effort.
In addition, source code’s availability lets us perpetually improve, fix, and support the reused elements. This factor often mitigates the risk of orphaned components or incompatible evolution paths that are associated with the reuse of proprietary components. Also, by incorporating the source code of a reused element into the system being built, developers can achieve tight integration and a system that can be maintained as a whole.
7.3. When Open Source?
Before deciding to use open source, some the conditions must be considered. An open source software
• should meet the requirements • should support by large community • should be sure continuity
• should be examine for performance issue
• should be documented, published, and reviewed in source code form • should be discussed, internalized, generalized, and paraphrased
7.4. JBoss Rule Engine
At the start of the study, an investigation was made for rule engines. Our concept is , it should be open source java software and meet the conditions on section “When Open Source?”. At the same time rule engine should obey open standards JSR-94 (Java Specification Requests, which are formal documents that describe proposed specifications and technologies to be added to the Java platform). After this investigation two alternatives were found; JESS and Drools.
On the other hand JESS was not fully open source software, but for academic usage required permission was possible. However, JESS structure is very complicated and not so suitable for java implementation. So, Drools was best alternative for our work.
Initial implementation was made by Drools 2.1. After this time, Drools Rule Engine is acquired by JBoss. This trade was proof the power of the Drools, because JBoss one of the most important open source software constitution. JBoss products are using many production environments, and now its rule engine is Drools(after here ,both JBoss Rule Engine and Drools Rule Engine are used in the same meaning).
One drawback of this trade is; knowledge representation and implementation was slightly changed, and its version was Drools 3.x. So our initial works were reimplemented.
Drools is an "augmented implementation of Charles Forgy's Rete algorithm. Rete algorithm is a popular approach to Forward Chaining, tailored for the Java language". Drools has implementations for both Rete and Leaps. The Drools Rete implementation is called ReteOO signifying that Drools has an enhanced and optimized implementation of the Rete algorithm for Object Oriented systems.
In summary, open source business rule management systems might make more sense then their expensive commercial counterparts. JBoss Rules and Jess represent two of the better open source offerings out on the market. In this thesis, JBoss rule engine is chosen for the below reasons:
It has
• A very active community • Easy to use
• Fast execution speed
• Gaining popularity among Java developers
• JSR 94-compliant (JSR 94 is the Java Rule Engine API) • Free
After this summary about history of our rule engine works, JBoss rule engine architecture and its components should be explained.
7.5. Architecture Of JBoss Rule Engine
Drools is split into two main parts Authoring and Runtime.
7.5.1. Authoring
The authoring process involves the creation of drl or xml files for rules which are fed into a parser. The parser checks for correctly formed grammar and produces an intermediate structure, then passed to the Package Builder which produces Packages. Package Builder also undertakes any code generation and compilation that is necessary for the creation of the Package. A Package object is a self contained and deployable, in that it's serializable, object consisting of one or more rules (Proctor et al., 2006).
Figure 7.1 JBoss authoring (Proctor et al., 2006)
7.5.2. Runtime
A RuleBase is a runtime component which consists of one or more Package's. Packages can be added and removed from the RuleBase at any time. A Rule Base can instantiate one or more Working Memories at any time; a weak reference is maintained, unless it's told otherwise. The Working Memory consists of a number of sub components including Working Memory Event Support, Truth Maintenance System, Agenda and Agenda Event Support. Object assertion may result in the creation of one or more Activations, the agenda is responsible for scheduling the execution of these Activations (Proctor et al., 2006).
Figure 7.2 JBoss runtime (Proctor et al., 2006)
7.5.3. Drools Rule Base
A Rule Base contains one more packages of rules, ready to be used (i.e. they have been validated/compiled etc). A Rule Base is serializable so it can be deployed to JNDI, or other such services. Typically, a rule base would be generated and cached on first use; to save on the continually re-generation of the Rule Base; which is expensive (Proctor et al., 2006).
Figure 7.3 Drools rule base (Proctor et al., 2006)
7.5.4. Drools Working Memory
The Working Memory is the main Class for using the Rule Engine at runtime. It holds references to all data that has been "asserted" into it (until retracted) and it is the place where the interaction with your application occurs. Working memories are stateful objects. They may be shortlived, or longlived (Proctor et al., 2006).
7.5.5. Knowledge Representation 7.5.5.1. Rules
A Production Rule, or Rule, in Drools is a two part structure with a Left Hand Side (LHS) and a Right Hand Side (RHS). Additionally a rule may have the following attributes:
• salience • agenda-group • auto-focus • activation-group • no-loop • duration
Figure 7.5 Procedural IF and drools rule
The LHS of a Rule consists of Conditional Elements (CE) and Columns; to run the encoding of propositional and first order logic. The term Column is used to indicate Field Constraints on a Fact (Proctor et al., 2006).
7.5.5.2. Facts
Facts are objects (beans) from your application that you assert into the working memory. Facts are any java objects which the rules can access. The rule engine does not "clone" facts at all, it is all references/pointers at the end of the day. Facts are applications data. Strings and other classes without getters and setters are not valid Facts and can't be used with Field Constraints which rely on the JavaBean standard of getters and setters to interact with the object (Proctor et al., 2006).
7.5.6. The Rule Language
Drools 3 has a "native" rule language that is non XML textual format. This format is very light in terms of punctuation, and supports natural and domain specific languages via "expanders" that allow the language to morph to your problem domain.
A rule file is typically a file with a .drl extension. In a drl file you can have multiple rules, functions etc. However, rules can be spread across multiple rule files. Spreading rules across files can help with managing large numbers of rules. A DRL file is simply a text file.
Domain specific languages are implemented as an enhancement over the native rule language. They use the "expander" mechanism. The expander mechanism is an extensible API, but by default it can work with .dsl files, which contain mappings from the domain or natural language to the rule language and your domain objects.
As an option, Drools also supports a "native" rule language as an alternative to DRL. This allows to capture and manage the rules as XML data. Just like the non-XML DRL format, the XML format is parsed into the internal "AST" representation - as fast as possible (using a SAX parser). There is no external transformation step required. All the features are available with XML that are available to DRL (Proctor et al., 2006).
7.6. Using Drools (Simple Example)
In this chapter, a simple example will explained for giving answer the question “how drools rule engine works”. This is classical hello world example which is a simple java class. It’s full name is gp.tez.jbossrule.HelloWorldExample.
This example simple get messages, print to system out, modify the message and reprint modified message to the system out. For this operation two rules are written to the HelloWorld.drl file (Figure 7.6).
Figure 7.6 HelloWorld.drl file
To run a drools application, some java libraries must be classpath. This list of jar files can be seen in Figure 7.7.
After adding libraries, required classes should be imported (Figure 7.8).
Figure 7.8 Importing Packages
A new working memory is created for the rule base, “Message” object (Figure 7.11) is asserted to this working memory and rules fired.
Figure 7.10 Main part of the HelloWold example
8. STANDARDIZATION OF RULE ENGINE
The specification defines a Java API for rule engines. The API prescribes a set of fundamental rule engine operations. The set of operations is based on the assumption that most clients need to be able to execute a basic multiple-step rule engine cycle that consists of parsing rules, adding objects to an engine, firing rules, and getting resultant objects from the engine.
This new API gives developers a standard way to access and execute rules at runtime. As implementations of this new spec ripen and are brought to the market, programming teams will be able to pull executive logic out of their applications.
JSR 94 defines a simple API to access a rule engine from a Java SE or Java EE client. It provides APIs to
• Register and unregister rules • Parse rules
• Inspect rule metadata • Execute rules
• Retrieve results • Filter results
Note that JSR 94 does not standardize the following:
• The rule engine itself • The execution flow for rules
• The language used to describe the rules
• The deployment mechanism for Java EE technology
The goals of the specification are to:
• Facilitate adding rule engine technology to Java applications.
• Increase communication and standardization between rule engine vendors.
• Encourage the creation of a market for third-party application and tool vendors through a standard rule engine API.
• Facilitate embedding rule engine technology in other JSRs to support declarative programming models.
• Promote independence of client code from J2SE environment.
• Make Java applications more portable from one rule engine vendor to another. • Provide implementation patterns for rules-based applications for the J2SE platform. • Support rule engine vendors by offering a harmonized API that meets the needs of
their existing customers and is easily implemented.
8.1. Architecture Of JSR-94
The interfaces and classes defined by the specification are in the javax.rules and javax.rules.admin packages. The javax.rules package contains classes and interfaces that are aimed at “runtime clients” of the rule engine. The runtime client API exposes methods to acquire a rule session for a registered rule execution set and interact with the rule session. The administrator API exposes methods to load an execution set from these external resources: URI, InputStream, XML Element, binary abstract syntax tree, or Reader. The administrator API also provides methods to register and unregister rule execution sets. Only registered rule execution sets are accessible through the runtime client API (Toussaint A., 2003).
8.1.1. Runtime API
The runtime API for the specification is defined in the javax.rules package. The
high-level capabilities of the runtime API are (Toussaint A., 2003):
• Acquire an instance of a rule engine vendors RuleServiceProvider interface through the RuleServiceProviderManager class.