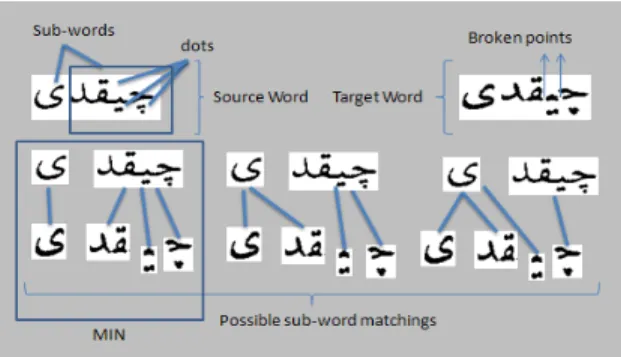
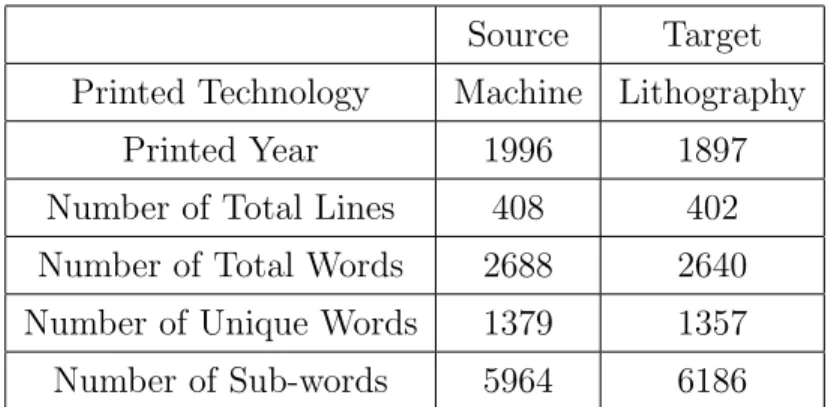
Historical document analysis based on word matching
Tam metin
Şekil
![Figure 2.1: First one is an example page in Ottoman and second one (image courtesy of [9]) is in Arabic](https://thumb-eu.123doks.com/thumbv2/9libnet/5783204.117434/21.918.219.745.167.454/figure-example-page-ottoman-second-image-courtesy-arabic.webp)



Benzer Belgeler
The objective of our study was to determine the prevalence, awareness, treatment, and control rates in a population (aged 25 or older) from Derince dis- trict of Kocaeli county,
In particular, this factsheet is relevant to people who design and develop informal sports offers, people who directly deliver informal sport (coaches, leaders, coordinators etc
This thesis aims for modeling and evaluating the movement of a Turkish armored battalion emplaced next to border from assembly area to the mobilization task areas, determining
Another alternative is to use an exact model that gives the exact number of occurrences of all run length values. Huffman coding is prefered to arithmetic.. Experiments
On the other hand, we expect to see higher sensitivity to exchange rate volatility for firms with low coverage ratio and with high level of international activity.. Nevertheless,
Our results suggest that although volatility response to most news indicators is larger in expansion, currency market reaction to new home sales and Fed funds rate news is larger in
In short, encapsulation of carvacrol in electrospun CD-IC fibrous webs has shown potentials for food and oral care applications due to free-standing and fast-dissolving character
Sometimes, the Gerays acted as loyal members of the Ottoman imperial establishment, or, as unruly nobles with their own vision of political geography, power, and nobility, and
