Analysis of scheduling problems in dynamic and stochastic FMS environment : comparison of rescheduling polices
Tam metin
Şekil


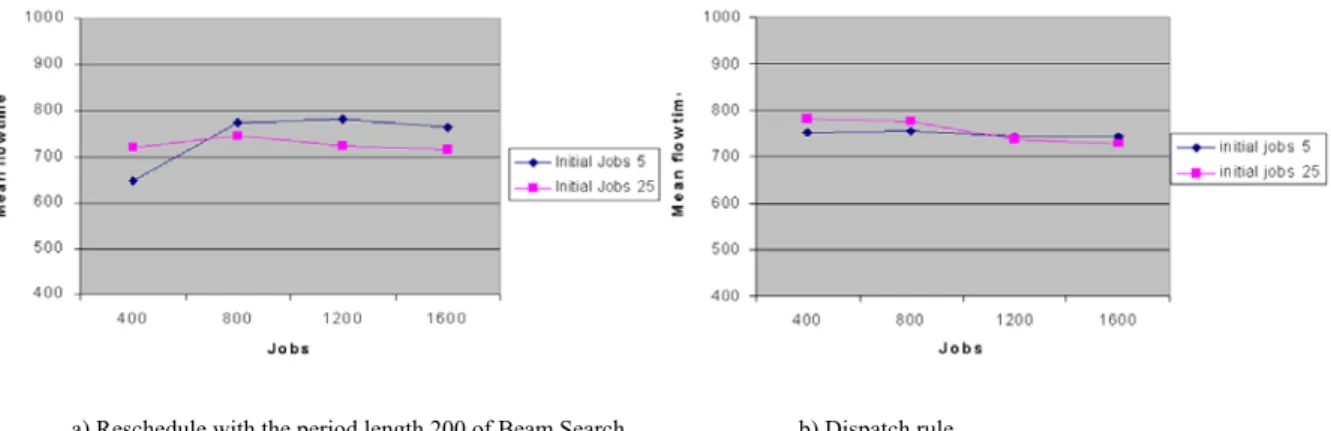
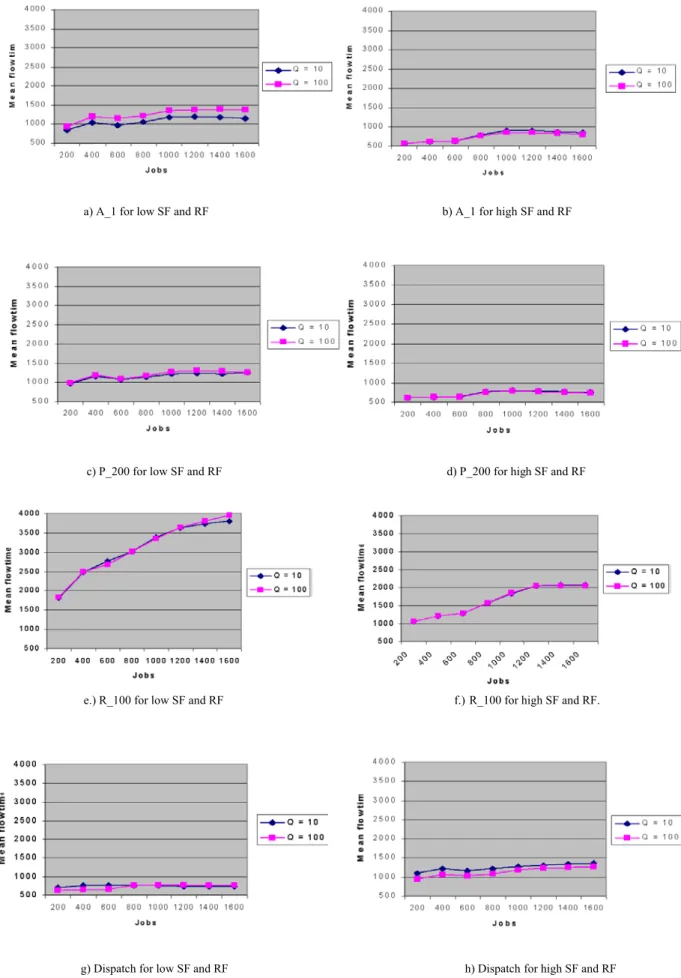
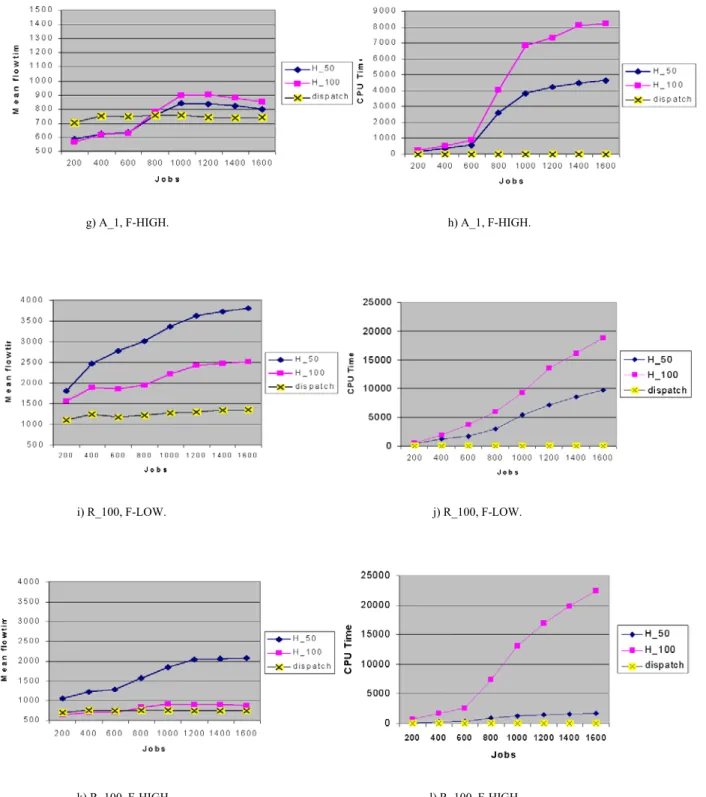
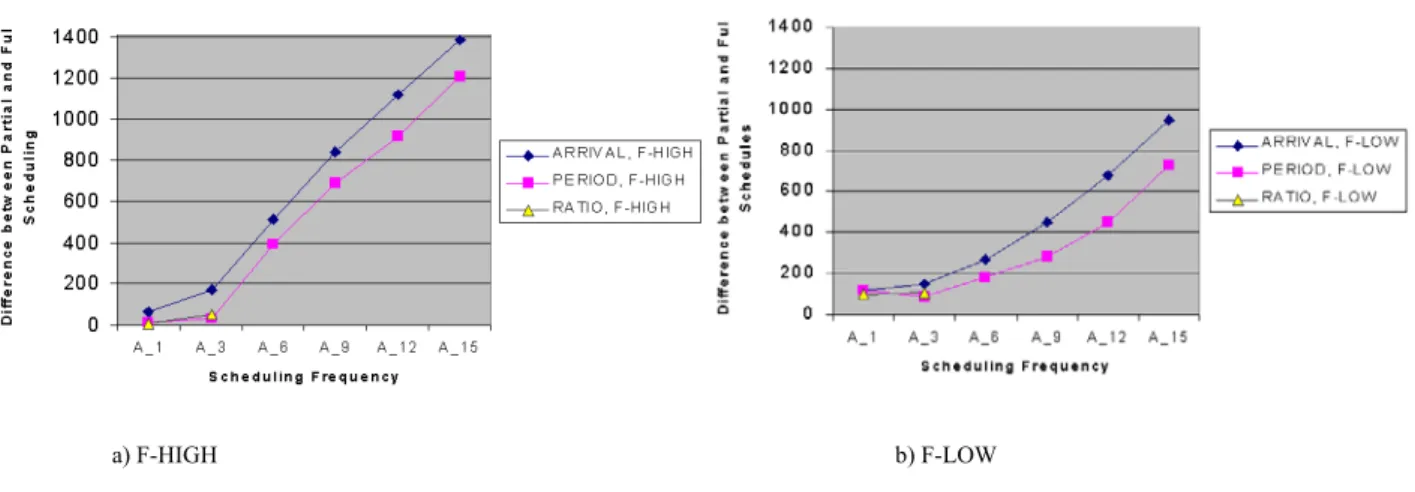


Benzer Belgeler
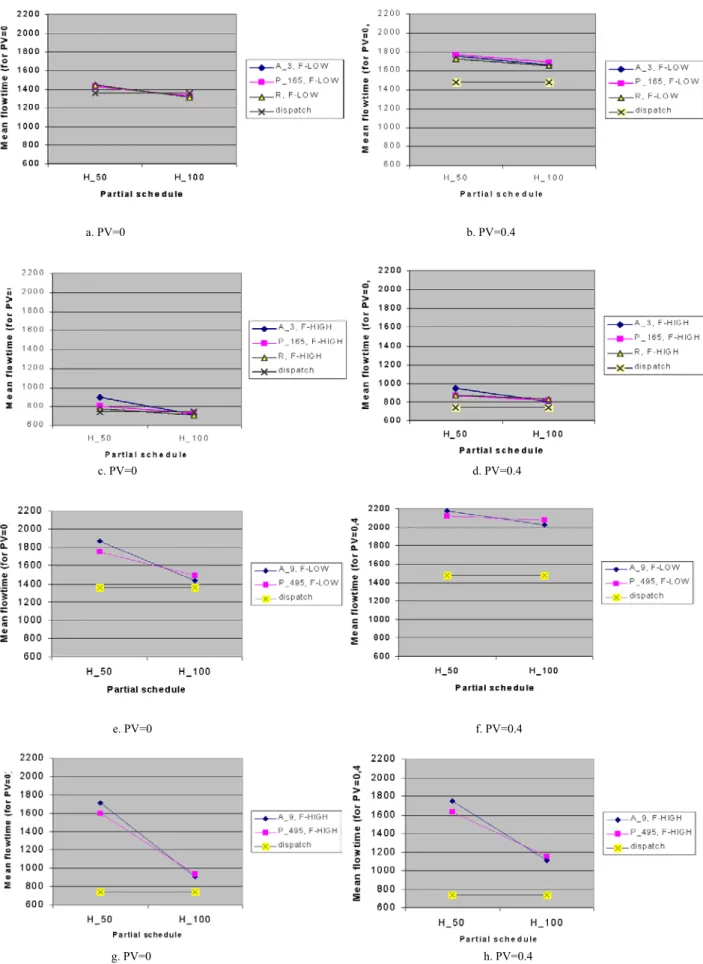
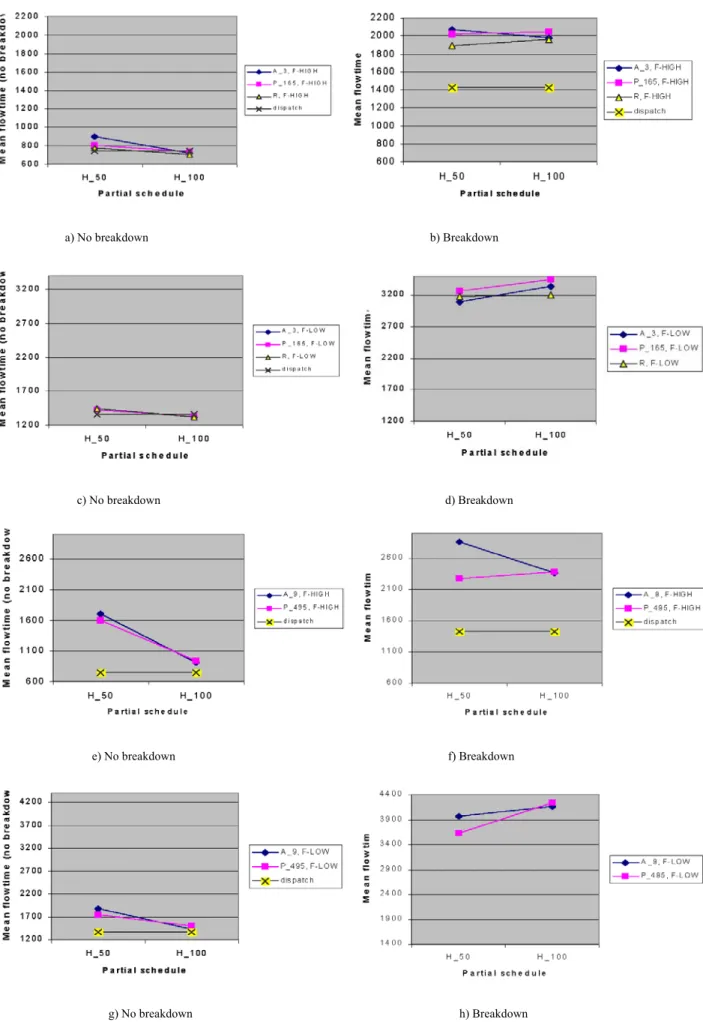
The primary concern of this study is to investigate the combinatorial aspects of the single-stage identical parallel machine scheduling problem and to develop a
çalışmalarında huzurevinde ve kendi evlerinde yaşayan yaşlıların genel sağlık durumlarının ve yeti yitimi puan ortalamaları arasında anlamlı fark bulunmuş, huzurevinde
Başaran 1967 yılında mezun olmuş ve aynı yıl Ankara Üniversitesi Tıp Fakültesi Deri ve Zührevi Hastalıklar Kürsü’sünde uzmanlık eğitimine başlamıştır.. 1971
Laparoskopik cerrahiyi uzman olduktan sonra kursiyer olarak öğrenen ve kliniğinde laparoskopi deneyimi olmayan bir ürolog basit ve orta zorlukta sayılan operasyonları yaptıktan
Elde edilen bu sonuç doğrultusunda, Yaratıcı Drama Yöntemine dayalı Yaratıcı Yazma çalışmalarının öğrencilerin yazmaya yönelik tutumlarını olumlu yönde
Naghizadeh, “Sodyum silikat ve sodyum hidrok- sit ile aktive edilen uçucu kül bazlı jeopolimer beton için karışım tasarımı Normal Portland Çi- mentosu betonundan
Technological Development (RTD) Framework Programme of the European Union stands at the cross-roads of the Community's policies on Research, Innovation and Small and
Öğretim sürecinde ilköğretim beşinci sınıf öğrencilerinin doğal çevreye duyarlılık ve çevre temizliği bilincini artırmak ve daha temiz bir çevre için neler
