Privacy in the genomic era
Tam metin
Şekil
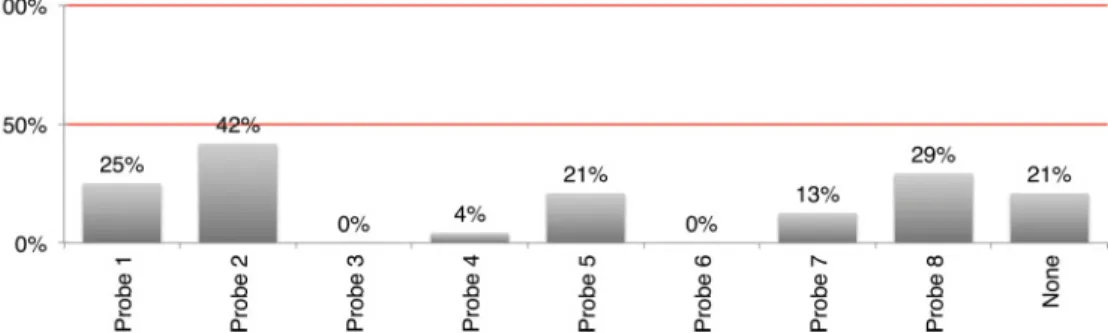
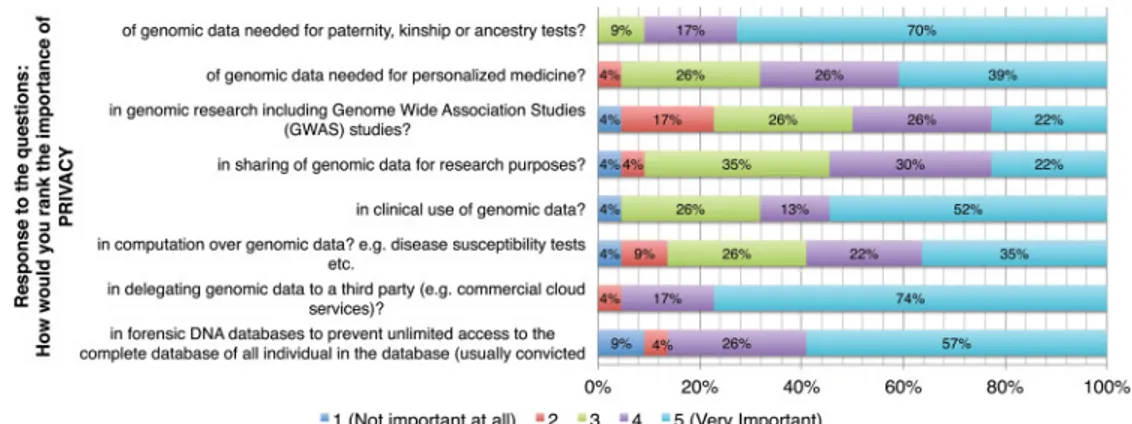
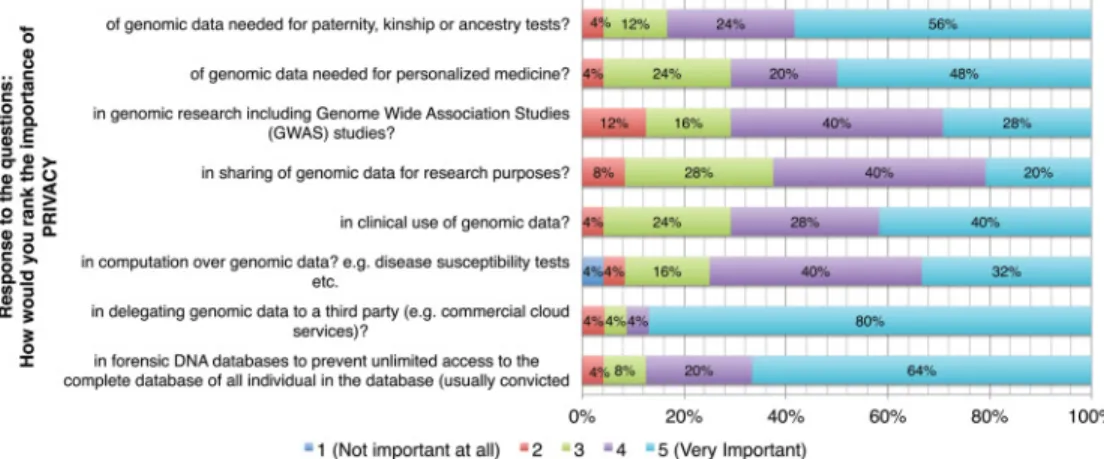



Benzer Belgeler
27 However, our calculations noticeably show that there is no direct correlation between the surface energies of the crystalline slab and the surface area where water reacts or
generations and over time (Finch and Mason, 2007, p. It might occupy a mystical value because of concealing a time which cannot be repeated and perceptions of someone lost.
Siyasal iktidarın bir eyleminin devlete atfedilmesi ve böylece kamu iktidarının otantik kullanımı olarak kabul edile- bileceği düşüncesi, sert hukuksallık ilkesinin
The two main features of the interaction to be simulated within our model are (i) the oscillatory energy difference between the ferromagnetic and the antiferromagnetic ground
Motivated by the studies of the above authors, in this study, we consider semiparallel and 2-semiparallel invariant submanifolds of Lorentzian para-Sasakian (briefiy
Bitirirken Türk tarih tezi, millî, Millî bir tarih inşa etme gayesindedir. Yalnız, millî değerler ve Türklük, modern ve laik bir şekil ve içerikte tanımlanmıştır. Türk
To conclude, despite its ease of application and short operative time, self-gripping mesh repair was not found to be superior to conventional Lichtenstein mesh repair in terms
As future work, we recommend to (1) make further case studies for both OSS and proprietary projects by using simi- lar categorization described in this paper and datasets with
