Near optimality guarantees for data-driven newsvendor with temporally dependent demand: A Monte Carlo approach
Tam metin
Şekil
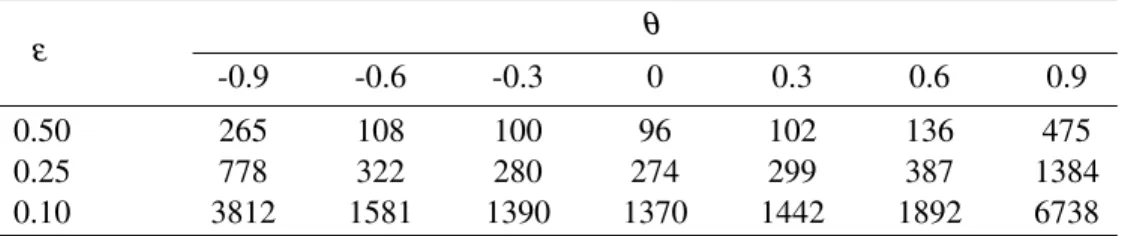
Benzer Belgeler
yıldönümü nedeniyle Paris’teki Le Petite Galerie tarafmdan düzenlenen ve 40 ressamm eserlerinden oluşan sergi, Paris Champs - Elysees Belediyesi Gösteri
Cervical intradural disc hernia tion. Kataoka O, Nishibayashi Y, Sho T. Intradur<i! lumbar disc herniation. Report of three cases with a review of the literature. lntradural
Bu görüşm elerin ilk gü nünde, T ürkiye Büyük M illet Meclisi hüküm etinin tem silcileri, İstanbul hüküm etini tem silen gelen.. Sadrıâzam Tevfik Paşa
Furthermore, using Strong Coupling Theory, we obtained the (ground state) energies of the nD polaron in strong-coupling regime in terms of α 0 and we found that there is a
Somatic chromosome number (2n), ploidy level, karyotype formula, ranges of chromosome length, total karyotype length (TKL) for the studied Astragalus taxa.. Taxa
supportive to cultural and/or religious rights and freedoms of immigrant minorities.. Regarding the discursive opportunities, this dissertation hypothesizes
These early lists pale to some extent when compared with the so-called ‘West Saxon Genealogical Regnal List’, composed in its present form during the reign of *Alfred, which
Anavar~a'daki bir mezar kaz~s~nda ele geçmi~~ olan uzun, damla bi- çimli ve hemen hemen renksiz camdan yap~lm~~~ unguentariumlar yayg~n örneklerdendirler (Resim 1o.5-8).Adana
