Sınıflandırma kurallarının çıkarımı için etkin ve hassas yeni bir yaklaşım
Tam metin
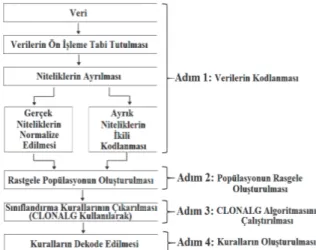
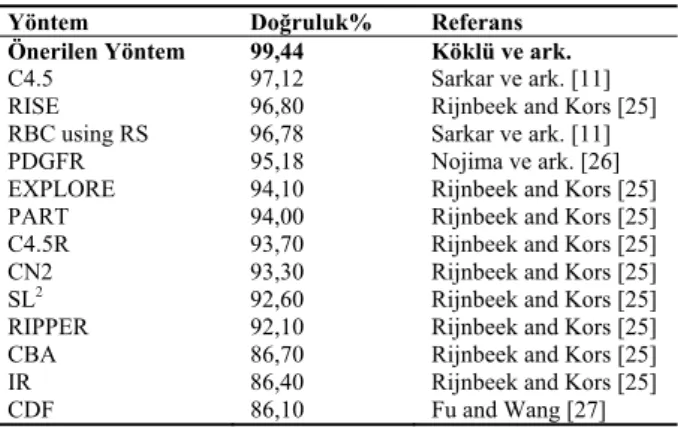
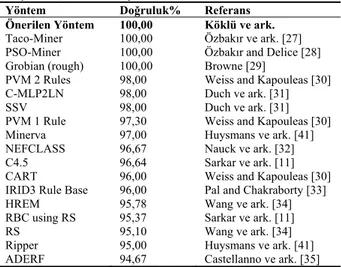
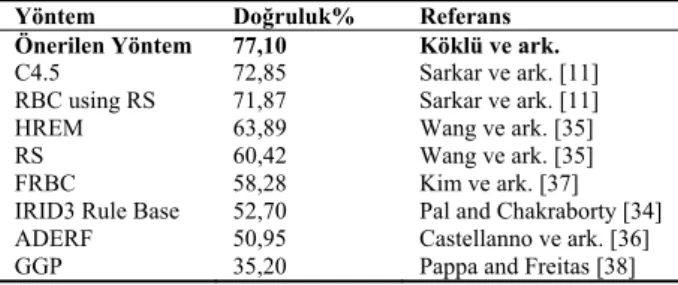
Şekil

Benzer Belgeler
這些患者若不接受治療,未來出現心肌梗 塞、中風等心血管疾病的機率,將是正常 人的 3~5
Söz konusu olgu sadece potansiyel bir depremin maksimum şiddetini artırmakla kalmayıp aynı zamanda olasılıkları da değiştiriyor: Birlikte hareket eden daha çok fay olması
Kontrol algoritması olarak geliştirdiğimiz kural tabanlı bir algoritma yardımı ile hastanın yürüme safhalarına dayalı mekanik sistemin bilek açısı kontrolü
Oto yedek parçacısı ol maktan son anda kurtulan Markiz Pastanesi’nin tarihi geçmişi oldukça ilginç geliş melere sahne olmuş.. yüzyıl sonlarında
Pek çok sergi açmış olması, çok sayıda resme imza atışı, yaşadığı dönemde İbrahim Safi'nin tanınmasına fırsat vermişse de, önemsenmesini bir ölçüde
Onuncu Yıl Marşı nın adının Cum huriyet Marşı olarak değiştirilmesi ka ran, ancak onun OLUR'uyla gerçekleşti.. Ben kamunun sesine aracı oldum, o da sesi
Additionally, when leukotriene C4 (LTC4) is injected into the unlesioned brain, the stem cells get activated and mimic a regeneration situation, suggesting that acute
India is a popular nation, which shows that there are so many people with many religious convictions in the Indian society as 'unity is diversity.' For women a special
