T Fault-TolerantTrainingofNeuralNetworksinthePresenceofMOSTransistorMismatches
Tam metin
Şekil
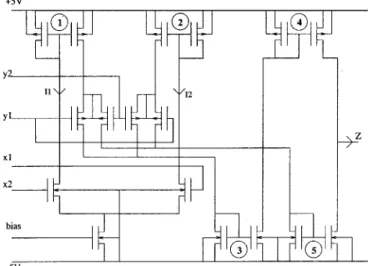
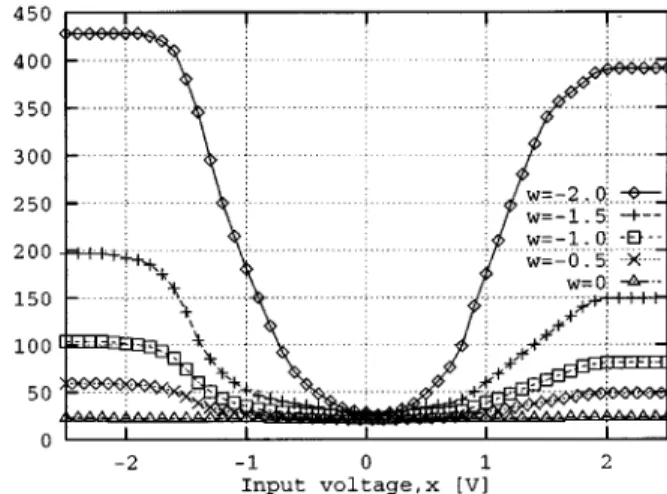
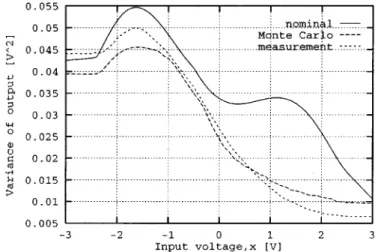

Benzer Belgeler
In this paper, we consider approximate computation of the conditional marginal likelihood in a multiplicative exponential noise model, which is the generative model for latent
• When the factor graph is a tree, one can define a local message propagation – If factor graph is not a tree, one can always do this by clustering
Motivated by the structure of hub networks that we encounter in practice and the fact that multiple allocation solutions are often significantly cheaper than single allocation
Due to the large power gain coefficient measured in si–GaP, the low threshold of pump laser power as a prereq- uisite for operation of a cw Raman oscillator on GaP has.
sınıflarında 2012–2013 öğretim yılında okutulan Fen ve Teknoloji ders kitabındaki “Maddenin Değişimi ve Tanınması” ünitesini eleştirel düşünme standartları
Multiresolution coding techniques have been used for lossy image and speech coding, in this thesis we developed multiresolution techniques for the lossless image
Halkla ilişkiler uygulamacıları, sosyal sorumluluk düşüncesi ile paralellik gösteren bir biçimde etik açıdan kime sadakat gösterecekleri konusunda iki seçeneğe
Çoklu regresyon analizlerin ikinci aşamasında yönetim faaliyetlerinin yürütülmesi bağımlı değişken ile verimlilik, yenilik, etkinlik ve kontrol bağımsız
