LOJİSTİK REGRESYON ANALİZİ VE TIP ALANINDA
KULLANIMINA İLİŞKİN BİR UYGULAMA
Yıldır Atakurt*
ÖZET
Bu çalışmada, çok değişkenli istatistiksel analiz yön-temlerinden Lojistik Regresyon Analizi'nin esasları ve ana basamakları açıklanmış ve kardiyolojik verilere uy-gulanarak yorumlanması yapılmıştır.
Çalışmada 500 bireyden elde edilen 34 değişken kul-lanılmış analiz sonucunda bağımlı değişken olarak alı-nan KOR (Koroner arter hastalığı) ile diğer bağımsız de-ğişkenlerin ilişki dereceleri ve önemlilikleri test edile-rek modele katkıları belirlenmiştir. Bulunan istatistikler doğrultusunda yorumlar yapılmıştır.
Anahtar Kelimeler: Lojistik regresyon analizi, Lojit transformasyon, Odds oranı, Olabilirlik oran istatistiği.
SUMMARY
Logistic Regression Analysis and Related Applicati-on to Usage in Medicine
İn this study, the principles and basic steps of Logis-tic Regression Analysis, which is one of the means for multivariate analysis, are explained. Coronary Artery Disease data have been applied and the results of this application were evaluated.
Thirty-four independent variables were obtained from 500 patients as a candidate for multivariate mo-del. The use of multivariate logistic regression analysis was permitted recognition of independent variables as-sociated with dependent variable CAD (Coronary Ar-tery Disease) and their signit'icance tests. Interpretations were evaluated by using statistical results.
Key VVords: Logistic Regression Analysis, Logit trans-t'ormation, Odds ratio, Likelihood ratio test.
Tıp alanındaki araştırıcılar üzerinde çalıştıkları ko-nuda çok etken olması durumunda etkenlerin tek tek bağımlı değişken üzerine etkisi yanında, bunların bir-likte etkisini de öğrenmek ya da incelemek istemekte-dirler. Birlikte etkinin incelenmesinde kullanılan deği-şik istatistik yöntemler bulunmaktadır. Örneğin, ba-ğımlı değişkenin sürekli, bağımsız değişkenlerin kesik-li olması durumunda varyans analizi, hepsinin kesikli olması durumunda log-lineer modeller, hepsinin sü-rekli olması durumunda regresyon analizi gibi. Tıp alanındaki araştırmalarda çok zaman bağımlı ve ba-ğımsız değişkenlerin tür ve yapıları yukarıda belirtilen-lere benzemez, sürekli ve kesikli karışımı bağımsız de-ğişkenlerle karşılaşılır. Üzerinde en çok durulan ve araştırıcı için önemli olan diğer bir konuda etken veya etkenlerle hastalık arasındaki ilişkinin risk yönünden incelenmesidir. Bu tip incelemelerde ağırlıklı olarak
Lojistik Regresyon Analizi kullanılmaktadır. Lojistik regresyon analizi, temelde regresyon analizi olmakla birlikte bir ayırıcı analiz tekniği olma özelliğini de ta-şımaktadır. Ancak lojistik regresyon analizi, bağımsız değişken yapısı ve kombinasyonu yönünden diskrimi-nant analizinden farklılık göstermektedir. Regresyon analizinden ise üç önemli farklılığı vardır.
1- Regresyon analizinde bağımlı değişken sayısal iken lojistik regresyon analizinde kesikli bir değer olma-lıdır.
2- Regresyon analizinde bağımlı değişkenin değeri, lojistik regresyonda ise bağımlı değişkenin alabile-ceği değerlerden birinin gerçekleşme olasılığı kes-tirilir.
3- Regresyon analizinde bağımsız değişkenlerin çoklu normal dağılım göstermesi koşulu aranırken, lojis-tik regresyonun uygulanabilmesi için bağımsız de-* Ankara Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı Öğretim Üyesi
ğişkenlerin dağılımına ilişkin hiçbir koşul gerek-mez.(1 )
Çalışmamızda, lojistik regresyon analizinin esasla-rı ve ana basamaklaesasla-rı kısaca açıklandıktan sora, kardi-yolojik veriler üzerinde uygulanması ve sonuçlarının değerlendirilmesi amaçlanmıştır.
Y Ö N T E M
Lojistik regresyon modelinde, bağımlı (sonuç) de-ğişken ikili (binary) 0, 1 gibi kesikli bir dede-ğişken olup; risk belirten durum 1, diğer durum 0 ile gösterilir. Reg-resyon problemlerinde anahtar değer, verilen bir ba-ğımsız değişken değerine bağlı olarak, bağımlı (sonuç) değişkenin ortalama değerini bulmaktır. Bu değer ko-şullu ortalama olarak adlandırılır ve E(Y\x) ile gösteri-lir. Burada, Y bağımlı değişkeni, x ise bağımsız değiş-keni göstermektedir. Lineer regresyon analizinde, ko-şullu ortalamanın x'in lineer bir denklemi olduğu var-sayılır;
E(Y\x) = pn + p,x 1
bu eşitlik , x'in aralığının ve arasında değişme-sinden dolayı E(Y\x)'in mümkün olan her değeri ala-bileceğini göstermektedir. Lojistik regresyon analizin-de ise koşullu ortalama; O'dan büyük, 1'analizin-den küçük ya da 1'e eşit olmak zorundadır.
0 < E(Y\x) <1 2 Lojistik regresyon analizinde, E{Y\x) = P0 + P ^
eşitli-ğinin sol tarafı 0-1 arasında sınırlı olasılık değerleri al-dığından ve bu değerler sonsuz değerler alabilen açık-layıcı değişkenlerle ilişkilendirildiğinden, söz konusu eşitlik her zaman sağlanamamaktadır. Böylesi bir du-rumla karşılaşılmaması için en iyi çözüm, sonuç değe-ri olarak ifade edilen olasılık değedeğe-rinin çeşitli dönü-şümlerle -°o ile +°o arasında tanımlı hale getirilmesidir ( 1 , 2 ) .
İki düzey içeren bir sonuç değişkenin analizinde kullanılmak üzere önerilen birçok dağılım fonksiyonu vardır. En yaygın kullanılan iki tanesi lojit ve probit dönüşümleridir. Bunlardan lojistik dağılımı seçmek için de iki tane önemli neden vardır, ilk neden, lojis-tik regresyon analizinde varsayım kısıtlaması olmama-sından dolayı kullanım rahatlığının yanı sıra, analiz sonucu elde edilen modelin matematiksel olarak çok esnek olması, ikinci neden ise biyolojik olarak kolay yorumlanabilir olmasıdır.
Gösterimi kolaylaştırmak için, lojistik dağılım kul-lanıldığında, x bilindiğinde Y'nin koşullu ortalamasını göstermek için n{x) - E(Y\x) değerini kullanabiliriz. Lojistik regresyon modelinin spesifik formu aşağıdaki gibidir;
ePo + Pıx rc(x) =
1 + ePo + M
Lojistik regresyon çalışmamıza merkez olacak fl(x)'in bir transformasyonu yukarıda bahsedildiği gibi lojit transformasyondur. Bu transformasyonu n{x) cin-sinden aşağıdaki gibi tanımlarız;
g(x) = 7t(x)
1 - 7ü(x) 4
Bu transformasyonun önemi, g(x)'in lineer regres-yon modelinin istenen tüm özelliklerini taşımasıdır. Lojit g(x), parametreleri bakımından lineer, sürekli ve x'in aldığı değerlere bağlı olarak ve arasında değişebilmektedir (1).
Modelin Oluşturulması
Lojistik regresyon modelinde katsayıların kestirimi (tahmini) için lineer regresyonda olduğu gibi maksi-mum olabilirlik kestirimi yöntemi kullanılır. (x;, y;) gi-bi n tane bağımsız gözlem eşinin olduğu varsayıldığın-da, yı iki düzeyli sonuç değişkenini, x('de / denek için bağımsız değişkenin değerini gösteriyorsa ve sonuç değişkeni için 0 ve 1 kodlarının belirli bir karakteristi-ğin yokluğunu ya da varlığını belirlediği kabul edildi-ğinde lojistik regresyon modelini uydurabilmek için bilinmeyen Pn ve p, parametrelerini kestirmemiz gere-kir. Eğer Y, 0 ve 1 olarak kodlandıysa, 7r(x) ifadesi x ve-rildiğinde Y'nin 1'e eşit olma koşullu olasılığını ver-mektedir n(x)= P(Y= 1\x). [1-/r(x)] değeri verilen her-hangi bir x için Y'nin 0'a eşit olma koşullu olasılığını göstermektedir ~\-n{x)- P(Y= 0\x). (x(V y) çiftinin y= 1 olduğu zaman olabilirlik fonksiyonuna katkısı tt(x,) iken, y= 0 olduğu zaman olabilirlik fonksiyonuna kat-kısı 1-p(X|) kadardır. (x(V y) çiftinin olabilirlik fonksiyo-nuna katkısını ifade etmenin güvenilir bir yolu da aşa-ğıdaki gibidir;
Ç(x,.) = 7t(x,.)>'/[1-7c(xI.)]1-)'/ 5 Gözlemlerin birbirlerinden bağımsız olduklarını
varsaydığımız için, olabilirlik fonksiyonu 5 numaralı denklemdeki terimlerin çarpılmasıyla elde edilir.
/(P) = i l Ç(x,) 6 (=1
Matematiksel olarak 6
numaralı eşitliğin logaritmasıyla çalışmak daha kolay olacağından log olabilirlik fonksiyonu şöyle tanımlan-mıştır;
ı=1
L((3) maksimum yapan p değerini bulabilmek için
/-(p)'yı P0 ve P/e göre türevini alıp O'a eşitleriz. Sonuçta elde edilen eşitlikler aşağıdaki gibidir;
İ [y, - 7t(x,.)] = 0 8 İ(P) = ln[/(P)] = X | y, In[n(x,.)] + (1-y,.) In[l-7t(x,.)][ 7 (=1 ve İ x[y,.-7i(x(.)] = /'=1
Bu eşitliklere olabilirlik eşitlikleri denir. Lineer reg-resyonda olabilirlik eşitlikleri kolay çözülebilen lineer denklemlerdir, fakat lojistik regresyonda bu ifadeler Po ve P/e göre nonlineer denklemlerdir, bu denklemle-rin çözümü için özel iterasyonla yapılan metotlar ge-rekir. 8 ve 9 nolu denklemlerden elde edilen P'nın de-ğeri, maksimum olabilirlik kestirimi (tahmini) olarak adlandırılır ve p olarak gösterilir. Örnek olarak, 7i(x(.)'nin maksimum olabilirlik kestirimini 7t(x() ile
gös-terebiliriz. Bu değer x'in xj gibi bir değere eşit olduğu
bilindiği zaman, Y'nin 1'e eşit olma koşullu olasılığı-nın kestirimini verir.
8 nolu denklemin sonucunda; E y , =Xrt(x,)
(=1 ı=1 10
y'nin gözlenen değerlerinin toplamının, kestirilen (tahmin edilen) değerlerin toplamına eşit olduğu gö-rülmektedir.
Değişkenlerin Önemliliği
Regresyon analizi tekniğinin temel kavramlarından biri modele katılan değişkenlerin önemli olmasıdır. Modele katkısı olamayan değişkenler kullanarak
kesti-rimde bulunmak hatalıdır. Aynı şekilde lojistik regres-yon analizinde de modele katılacak olan değişkenle-rin önemliliğin test edilmesi gerekir (3).
Katsayıları kestirdikten sonra, kestirilen modeldeki değişkenlerin önemlilikleri araştırılır. Bu test genelde, modelde bulunan bağımsız değişkenlerin "önemli" bir şekilde sonuç değişkeniyle ilişki içinde olup olmadığı-nın testi şeklinde olmaktadır. Testin yapılış metotları bir modelden diğerine spesifik özelliklerine bağlı ola-rak farklılık göstermektedir.
Lojistik regresyonda katsayıların önem testi için ana prensip sorgulama altındaki değişkeni kapsayan ve kapsamayan modellerden elde edilen kestirim de-ğerlerinin, sonuç değişkeninin gözlenen değerleriyle karşılaştırılmasıdır. Gözlenen ve kestirilen değerlerin karşılaştırma işlemi log-olabilirlik fonksiyonu ile yapı-lır. Olabilirlik fonksiyonlarını kullanarak gözlenen ve kestirilen değerleri karşılaştırmak aşağıdaki ifade ile olmaktadır;
D = - 2ln Şu andaki modelin olabilirliği Doymuş modelin olabilirliği 11 Bu teste olabilirlik oranı testi adı verilir. (11) nolu denklemi kullanarak aşağıdaki denklemi elde ederiz.
D = - 2 E
ı=1
y, İn
+(1 -y,) İn v y j 1-y, 12D istatistiği sapma (deviance) olarak adlandırılır. Uyum iyiliğine karar verirken D istatistiği önemli bir rol oynamaktadır. Bağımsız bir değişkenin önemine karar vermek amacıyla, denklemde bağımsız değişke-nin olduğu ve olmadığı durumlardaki D değerleri kar-şılaştırılır.
Bağımsız değişkeni kapsamasından dolayı ortaya çıkan D'deki değişim aşağıdaki gibidir;
C= DfDeğişkensiz model için)
-D(Değişkenli model için) 13 Bu istatistik lineer regresyonda kullanılan F testin-deki pay kısmı ile aynı rolü üstlenir.
G = - 2ln Değişkensiz modelin olabilirliği Değişkenli modelin olabilirliği 14 Tek bağımsız değişkenli özel durumlarda, değişke-nin modelde olmadığı zamanki P„'ın maksimum ola-bilirlik kestirimi ln(n1/n0)'dır n, = £y(. ve n0 = X(1-y,).
Kestirim değeri sabittir (n,/n). G istatistiği de aşağıdaki gibidir; G - -2ln ( V v f \ V / n nm-ûp-y? h=\ 15 ya da G-2 I
(=1 y,.|n nf + 1 -y. İn 1-7i(.
n1 İn n, l+n0ln[n0 |-nln(n) 16 Tüm değişkenleri içeren model ile kestirilen mode-le ilişkin olabilirlik oran değermode-lerinin farkına dayanan ölçütlerin ki-kare dağılımı göstereceği düşüncesinden hareketle kurulan modelin geçerliliği sınanmaktadır. Bu yolla modele girecek açıklayıcı değişkenlere karar verilmektedir. P,= 0 hipotezi altında, C istatistiği 1 serbestlik derecesinde ki-kare dağılım gösterir. Katsa-yıları kestirdikten sonra, kestirilen modeldeki değiş-kenlerin önemlilikleri araştırılır (1).
Çok Değişkenli Lojistik Regresyon
Birden çok bağımsız değişkenin yer aldığı lojistik modellere çok değişkenli lojistik regresyon adı verilir. Yapısal olarak bu modelin diğer çok değişkenli regres-yon modellerinden farkı olmayıp regresregres-yon katsayıla-rının yorumlanması farklıdır. Yorumlama bağımsız de-ğişken türüne göre değişir. Çok dede-ğişkenli lojistik reg-resyonda sürekli olmayan değişkenler; nominal (sınıf-landırılabilir) ve ordinal (sıralanabilir) değişkenler ola-bilir (2).
Lineer regresyonda olduğu gibi lojistik regresyonda da modellemenin gücü çok değişkenli modelleme ye-teneğine bağlıdır. Değişkenlerden bazıları değişik öl-çüm biçimlerinde olabilir. Çoklu lojistik regresyon modelinde genel eğilimimiz katsayıların tahmini ve onların önem testi şeklinde olacaktır. Kesikli ve nomi-nal ölçekli bağımsız değişkenleri denkleme sokabilmek için dizayn değişkenleri kullanılacaktır (2,4).
-x' = (x1,x2,...,xp) vektörü ile gösterilen, p tane ba-ğımsız değişken toplandığını varsayalım. Sonuç
değiş-keninin mevcut olduğu (Y=1) zamanki koşullu olasılık P(Y=1 \x)=7i(x)'e eşittir. Çoklu lojistik regresyon mode-linin lojiti aşağıdaki denklem ile verilmiştir;
g(x)= p0 + p,x, + p2x2 + ... + ppxp bu durumda eg(x) 17 7i(x) = 1 + e&x)
Eğer bazı bağımsız değişkenler kesikli, nominal öl-çekli (ırk, cinsiyet, tedavi grupları v.b.) ise o zaman bu değişkenleri aralık değişkenleriymiş gibi denkleme sokmak yanlış olacaktır. Çünkü bu değişkenlere veri-len kodların herhangi bir sayısal değerleri yoktur. Bu durumlarda dizayn değişkenleri ya da "dummy" de-ğişkenleri (kukla dede-ğişkenleri) kullanılmalıdır.
Genel olarak, eğer nominal bir değişken k katego-riye sahipse o zaman k-1 dizayn-değişkenine ihtiyaç vardır, k-1 dizayn değişkeni Dj u olarak ve katsayıları-da Pju olarak belirtilmiştir. Sonuç olarak, j. değişkeni kesikli olan p değişkenli model için lojit aşağıdaki gi-bidir;
V1
g(x)= p0 + P,x, + ... + I p.,Dyu + ppxp 19 u= 1
Birbirinden bağımsız n tane (xjlyi) değişkeni
oldu-ğunu varsayalım. Tek değişkenli modelde olduğu gibi modeli uydurmak için kestirim vektörünü p'= (p0, P1;...,P ) elde etmemiz gerekir. Çok değişkenli durum-da kestirim metodunun, tek değişkenlide olduğu gibi maksimum olabilirlik olduğunu söyleyebiliriz. Log olabilirlik fonksiyonunu p+1 katsayıya göre türevini alarak p+1 olabilirlik denklemi elde ederiz (5).
i
[ y . - n(x)] = o
20ı=1 ve
X x j yi - 7t(x,.) ] = 0, j=1, 2,...,p 2 1
;= i
p bu denklemlerin çözümünü göstersin. Çoklu lo-jistik regresyon modeli için p ve x/yi kullanarak uydu-rulan değerler ile Tc(xf) bulunur. Maksimum olabilirlik kestiriminin teorisi, log olabilirlik fonksiyonunun ikin-ci dereceden türevlerinden oluşan matristen kestirim değerlerinin elde edileceğini vurgular. Bu türevlerin genel şekli aşağıdaki gibidir;
d2L(?>) = - X X?.7t,.(1-7t;) ı=1 ıj r 32/-(p) _ ap^p, = -/= 1 1 XijXklKiO-K) 22 23 j, u=0, 1, 2,...,p.
"Information" matrisi adı verilen [(p+1) x (p+1)] matrisi yukarıdaki denklemlerde verilen terimlerin ne-gatiflerini kapsar. Kestirilen katsayıların varyans kovar-yansları bu matrisin tersinden elde edilir XP = |-'(P). Çok özel durumların dışında bu matrisin açık şeklini yazmak mümkün değildir. g2(Pj) ile bu matrisin j.
di-yagonal elementini gösterebiliriz, ki o da p/ninvar-yansıdır. Matrisin diyagonal olmayan elemanlarından o(pj, Pu)'de ve Pj ve Pu'nun kovaryanslarını
vermekte-dir. Varyans ve kovaryansların kestirimleriS(p) ile gös-terilmiştir.
Matristeki elemanları 62(Pj) ve 6(P(,Pu) ile
göstere-ceğiz. Kestirilen katsayıların standart hataları aşağıda-ki gibidir;
s m = a2(pj) 1/2
j= 0, 1,2, ... ,p. 24 Yukarıdaki bu formülü, katsayıları test ederken ve kestirimlere ilişkin güven sınırlarını bulurken kullana-cağız.
"Information" matrisinin aşağıdaki formu model uydururken ve uyumun iyiliği tartışılırken kullanılabi-lir.
I(P) = X'VX 25
X matrisi [n x (p+1)] boyutunda bir matrisdir ve her bir denek için verileri kapsar.
X = 11 2 1 n1 *2P np
V matrisi (n x n) boyutunda genel elemanı jt(.(1-7t;)
olan rc(. diyagonal bir matrisdir.
V =
71,(1-71,) 0 ... 0 0 ft2(1-ft2) ... o
0 ft„(1-ftj Modelin Önemlilik Testi
Bu işlemdeki ilk adım modeldeki değişkenlerin önem kontrolünü yapmaktır. Modeldeki bağımsız de-ğişkenler için p katsayının tümel olabilirlik oran testi tek değişkenli durumdakiyle aynıdır. Test 12 ve 14 no-lu denklemlerde verildiği gibi G istatistiği temeline bağlıdır. "Modeldeki p tane "eğim" katsayısının sıfıra eşit olması" hipotezi altında, C istatistiği p serbestlik derecesinde ki kare dağılımı gösterir.
Değişkenleri tek tek Wald test istatistiği ile test ede-biliriz Wj = Py/Sf(Py) . "Bir katsayının (py) sıfıra eşit
ol-ması" hipotezi altında VVald istatistiği standart normal dağılım gösterir. Bu istatistiğin önemi, modeldeki her-hangi bir değişkenin önemli mi yoksa önemsiz mi ol-duğunu belirlemektir (1).
Göz önünde bulundurmamız gereken asıl nokta, en iyi uyum modelini en az parametre ile belirlemek-tir. Bundan sonraki ilk mantıklı adımımız, önemli ol-duğunu düşündüğümüz değişkenleri modele alarak yeni bir analiz yapmak ve bunu full modelle karşılaş-tırmaktır.
Kategorisel olarak ölçeklendirilmiş bağımsız değiş-kenler modelden çıkarıldığı (ya da girdiği) zaman, onun bütün dizayn değişkenleride modelden çıkarıl-malıdır (ya da girmelidir). Eğer kategorik bir değişke-nin k seviyesi varsa, serbestlik derecesine bu değişke-' nin katkısı k-1 kadar olacaktır. Çoklu serbestlik dere-cesinden dolayı VVald istatistiğini kullanırken dikkatli olmamız gerekmektedir. Örnek olarak, eğer her iki katsayı için W istatistiği 2'yi geçerse, o zaman dizayn değişkeninin önemli olduğuna karar verebiliriz. Alter-natif olarak, eğer katsayılardan birinin W istatistiği 3, diğerinin değeri 0.1 ise değişkenin modele katkısı hak-kında kesin bir şey söyleyemeyiz (1,2).
Lojistik Regresyon Modelinde Katsayıların Yorumlanması
Karar vermemiz gereken ilk adım, "bağımlı değiş-kenin hangi fonksiyonu bağımsız değişkenler ile line-er bir fonksiyon oluşturmaktadır?" sorusudur. Bu fonk-siyona link fonksiyonları adı verilir.(5)
Lineer regresyon modelinde link fonksiyonu / (identity) matrisidir, çünkü bağımlı değişken paramet-releri ile lineerdir. Lojistik regresyon modelinde ise link fonksiyonu lojit transformasyondur.
g(x) = ln{n(x)/[1-7i(x)]} = pn + p,x 26
Lojistik regresyon katsayılarının yorumuna bağım-sız değişkenin ikili olduğu zamanki durum ile başlaya-cağız. x'in 0 ve 1 ile kodlandığını varsayalım.
x=1 olan bireyler içinde, sonuç değişkeni görülme (y=1) odds değeri xc( 1 >/[ 1 —xc( 1)] olarak tanımlanmıştır. Benzer şekilde x = 0 olan bireyler içinde, sonuç değiş-keni görülme (y=1) odds değeri rc(0)/[1-rc(0)] olarak verilmiştir. Odds değerlerinin logaritması lojit olarak adlandırılır.
g( 1) = ln{7i(1)/[1-7i(1)]| g( 0) = ln{7i(0)/[ 1-rc(0)]}
Odds oranı, bu odds değerlerinin oranı olarak tanımlanır.
0P0+P1 1
7 i ( m ı - n ( i ) ] 27 7t(0)/[1-7t(0)]
Odds oranının logaritması, log-odds, lojit farka eşittir.
I n m = İn 7t(1)/[1-TC(1))
rc(0)/[ 1-7i(0)J 28 = g(1)-g(0)
Tablo 1 'deki değerleri yukarıdaki denklemde yeri-ne koyarsak odds oranı aşağıdaki gibi bulunur;
Tablo 1. İkili Bağımsız Değişkende Lojistik Regresyon Katsayı-ları
Bağımsız değişken (X) x = 1 x = 0
ePo+Pı ePo
Sonuç değişkeni 71(1 )= 1 +ePo+Pı 7t(0)=" 1+ePo y = 1
1 efe
Sonuç değişkeni 1-7t(1) l+ePo+Pı 1-7C(0)= 1+ePo y = 0 Toplam 1.0 1 .0 1+ePo+Pı 1+ePo ePo 1 2 9 1 +ePo 1 +ePo+Pı ePo+Pı
oPn
ePıLojistik regresyonda bağımsız değişken ikili ise odds oranı = e13' ve lojit fark da İn OF) = p/e eşit olacaktır. Odds oranı çok yaygın kullanılan bir ilişki ölçüsüdür.
Sürekli değişkenlerde odds oranını yorumlarken, lojitin sürekli değişkenle lineer bir ilişkide olması ge-rekmektedir. Eğer lojitin, sürekli değişkenle lineer bir ilişki içinde olmadığı düşünülüyorsa, sürekli değişken-leri gruplandırmak ya da dizayn değişkendeğişken-lerini kullan-mak gerekecektir. Alternatif olarak, bu tür değişkenle-re transformasyon yapılmalıdır.
Uyum İyiliği Testi
Doğrusal regresyon çalışmalarında modelin önem-liliği için yapılan varyans analizi gibi lojistik regres-yonda da modelin uyum iyiliği testi gereklidir. Uyum iyiliğinde kullanılan istatistik ve analizler çeşitlidir. Bunlardan bazıları regresyondan ayrılışın test edilme-si gibi klaedilme-sik anlayışı taşırlar. Diğerleri ise lojistik man-tıktan hareket ederek ki-kare uyum iyiliği istatistiğini kullanırlar. Regresyondan ayrılışı test etme amacı taşı-yan uyum iyiliği test istatistiklerinde bağımsız ken kavramı kullanılmaktadır. Genel olarak çok değiş-kenli regresyon analizlerinde birbiri ile aynı olan ba-ğımsız değişken kombinasyonlarına baba-ğımsız değiş-ken deseni adı verilir. Bağımsız değişdeğiş-ken deseni sayı-sı DS<toplam gözlem sayısayı-sıdır. Bağımsayı-sız değişken de-senleri regresyonda aynı davranışı göstermediklerin-den özellikle regresyondan ayrılışların hesaplanma-sında önemli rol oynarlar. Regresyondan ayrılışlar;
(Artık)Aİ = y - P (y= 1 , x ) (i = 1,2,...DS) i' inci değişken deseni için;
ZAİ = Standartlaştırılmış artık olmak üzere Pearson istatistiği;
DS
Pearson y} = S 30
eşitliği ile bulunur. Pearson istatistiği, k bağımsız değişken sayısını göstermek üzere (DS-k-1) serbestlik derecesi ile khi-kare dağılımı gösterir.
Regresyondan ayrılışın incelenmesinde kullanılan diğer bir istatistik de Deviance İstatistiğidir. (yj( çif-tinin gözlem sayısı 1 olmak üzere Deviance artıkları;
Yi = 1 İÇİn d, = V2|ln(P(y = 1 ,x))| 31 Yi = 0 için d; = -V2|ln(1-P(y = 1,x))| olmak üzere, bu özel durum dışında i' inci değiş-ken desenindeki gözlem sayısı ^ olmak üzere
-
(
\ Vi +(n-yi)ln ( \ ( nry , ) -- tnip( y i 'xi )) +(n-yi)ln ^ [ l - P t y ^ ) ] J -olmak üzere DS D = I d2 33 i=1 1dir. D istatistiği de (DS-k-1) serbestlik derecesi ile khi-kare dağılımı gösterir.
Pearson ve Deviance istatistiklerinin DS = n olma-sı durumunda dağılımları bozulduğundan kullanılma-sı önerilmez.
MATERYAL
Uygulamamızda kullanılan veriler A.Ü. Tıp Fakül-tesi Kardiyoloji Anabilim Dalı kayıtlarından alınmış-tır.^) Çalışmaya dahil edilen 500 hastanın 356'sı ko-roner arter hastalığına sahip, 144 'ü ise koko-roner arter hastalığına sahip değildi. Çalışma grubundaki birey-lerden elde edilen; YAŞ, CİNSİYET, D1Q, D1N, D2Q, D2N, D3Q, D3N, AVRQ, AVRN, AVLQ, AVLN, AVFQ, AVFN, V1Q, V1 N, V2Q, V2N, V3Q, V3N, V4Q, V4N, V5Q, V5N, V6Q, V6N, KOR, KAH,
AHI-PO, AAKI, ADIS, IHIAHI-PO, IAKI, IDIS 34 adet değişken analizde kullanıldı. Bu değişkenlerden KOR (koroner arter hastalığı) bağımlı değişken olarak alındı. Değiş-kenler içerisinde tek sürekli değişken olan yaş, lojit ile lineer bir ilişki içinde olmadığından dolayı kategorik olarak bireyler 5 yaş grubunda toplandı (Tablo 2). Cin-siyet değişkeni, erkek=1 kadın=0 olarak, diğer değiş-kenler var=1 yok=0 olarak kodlandı.
BULGULAR VE TARTIŞMA
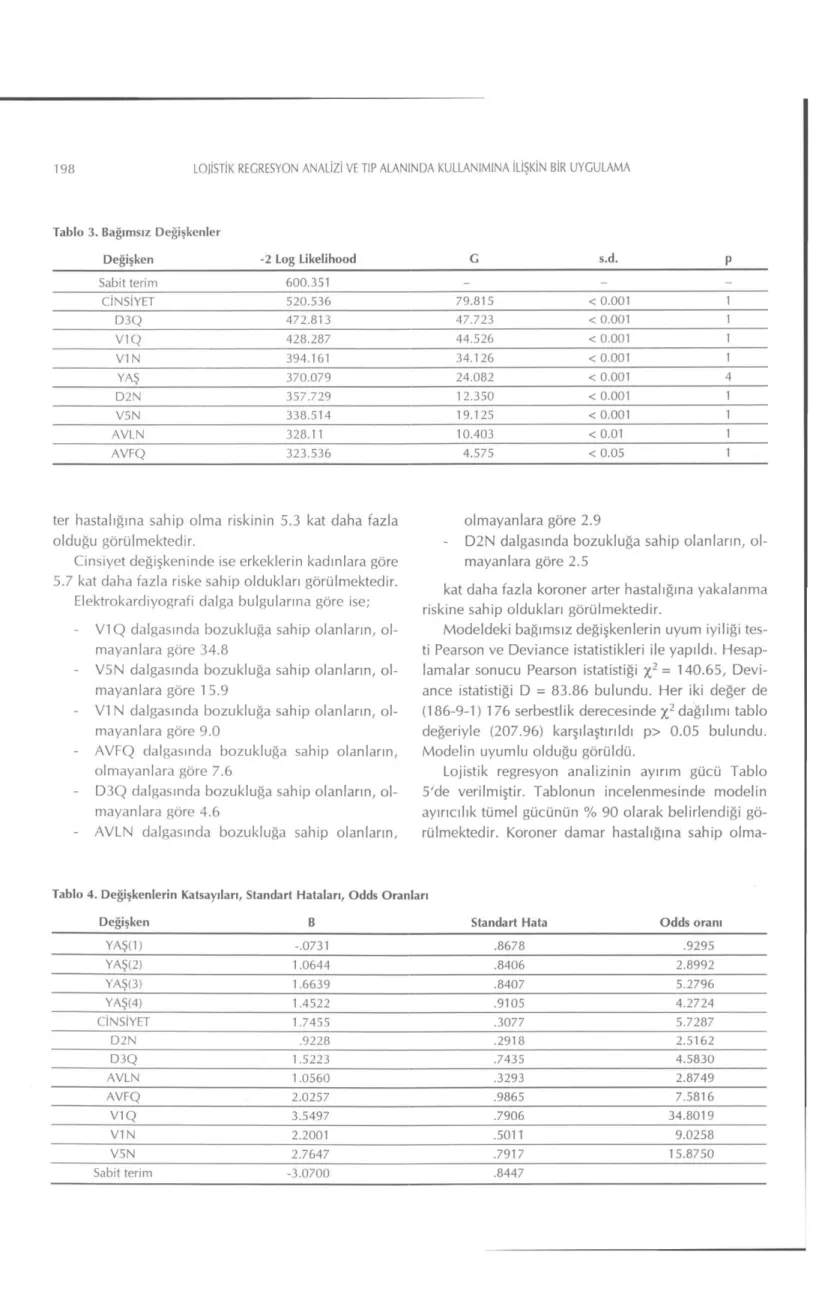
Çalışmamızda SPSS istatistik paket programının Lojistik Regresyon Analizi modülünden yararlanılmış-tır (7). İlk aşamada her değişken için tek tek değişken-li anadeğişken-lizler yapılarak anadeğişken-liz sonucunda p<0.25 değe-rine sahip olan ; YAŞ, CİNSİYET, D1Q, D1 N, D2N, D3Q, AVLQ, AVLN, AVFQ, AVFN, V I Q , V1N, V2N,V3Q, V3N, V4N, V4N, V6N 18 adet değişken çok değişkenli regresyon analizine aday olarak seçil-di. İkinci aşamada bağımlı değişken seçilen KOR ile en fazla ilişkili değişkenden başlanarak bağımsız de-ğişkenler modele birer birer ilave edildi ve önemlilik testleri G istatistiği ile yapıldı. Önemliliği p < 0.05 'in altında olan bağımsız değişkenler modele dahil edildi-ler (Tablo 3).
Modele alınan değişkenlerin kestirilen katsayıları, standart hataları ve odds oranları Tablo 4'de verilmiştir.
Aşağıdaki formül yardımıyla, verilen bir hastanın koroner damar hastalığına sahip olma olasılığı hesap-lanabilir:
P(KAR)=
Y(1)=YAŞ(1), Y(2)=YAŞ(2), Y(3)=YAŞ(3), Y(4)=YAŞ(4), C=CİNSİYET Tablo 4'ün odds oranlarına göre irdelenmesi yapıl-dığında 34 ve altındaki yaş grubuna göre; diğer yaş grupları içerisinde en yüksek odds oranına 55-64 yaş grubunun sahip olduğu, bu yaş grubunun koroner
ar-Tablo 2. Yaş Gruplarına Göre Değişkenler
Yaş grupları Grup no Frekans Yaşgrl Yaşgr2 Yaşgr3 Yaşgr4 < 34 1 17 0 0 0 0 35 - 44 2 88 1 0 0 0 45 - 54 3 1_64 0 1 0 0 55 -64 4 168 0 0 1 0
Tablo 3. Bağımsız Değişkenler
Değişken -2 Log Likelihood G s.d. p
Sabit terim 600.351 - - -CİNSİYET 520.536 79.815 < 0.001 1 D3Q 472.813 47.723 < 0.001 1 V1Q 428.287 44.526 < 0.001 1 V1N 394.161 34.126 < 0.001 1 YAŞ 370.079 24.082 < 0.001 D2N 357.729 12.350 < 0.001 1 V5N 338.514 19.125 < 0.001 1 AVLN 328.11 10.403 < 0.01 1 AVFQ 323.536 4.575 < 0.05 1
ter hastalığına sahip olma riskinin 5.3 kat daha fazla olduğu görülmektedir.
Cinsiyet değişkeninde ise erkeklerin kadınlara göre 5.7 kat daha fazla riske sahip oldukları görülmektedir.
Elektrokardiyografi dalga bulgularına göre ise; - V1Q dalgasında bozukluğa sahip olanların,
ol-mayanlara göre 34.8
- V5N dalgasında bozukluğa sahip olanların, ol-mayanlara göre 1 5.9
- V1 N dalgasında bozukluğa sahip olanların, ol-mayanlara göre 9.0
- AVFQ dalgasında bozukluğa sahip olanların, olmayanlara göre 7.6
- D3Q dalgasında bozukluğa sahip olanların, ol-mayanlara göre 4.6
- AVLN dalgasında bozukluğa sahip olanların,
olmayanlara göre 2.9
- D2N dalgasında bozukluğa sahip olanların, ol-mayanlara göre 2.5
kat daha fazla koroner arter hastalığına yakalanma riskine sahip oldukları görülmektedir.
Modeldeki bağımsız değişkenlerin uyum iyiliği tes-ti Pearson ve Deviance istates-tistes-tikleri ile yapıldı. Hesap-lamalar sonucu Pearson istatistiği %2 = 140.65,
Devi-ance istatistiği D = 83.86 bulundu. Her iki değer de (186-9-1) 176 serbestlik derecesinde %2 dağılımı tablo
değeriyle (207.96) karşılaştırıldı p> 0.05 bulundu. Modelin uyumlu olduğu görüldü.
Lojistik regresyon analizinin ayırım gücü Tablo 5'de verilmiştir. Tablonun incelenmesinde modelin ayırıcılık tümel gücünün % 90 olarak belirlendiği gö-rülmektedir. Koroner damar hastalığına sahip
olma-Tablo 4. Değişkenlerin Katsayıları, Standart Hataları, Odds Oranları
Değişken B Standart Hata Odds oranı
YAŞ(1) -.0731 .8678 .9295 YAŞ(2) 1.0644 .8406 2.8992 YAŞ(3) 1.6639 .8407 5.2796 YAŞ (4) 1.4522 .9105 4.2724 CİNSİYET 1.7455 .3077 5.7287 D2N .9228 .2918 2.5162 D3Q 1.5223 .7435 4.5830 AVLN 1.0560 .3293 2.8749 AVFQ 2.0257 .9865 7.5816 V1Q 3.5497 .7906 34.8019 V1N 2.2001 .5011 9.0258 V5N 2.7647 .7917 15.8750 Sabit terim -3.0700 .8447
Tablo 5. Lojistik Regresyon Analizinin Ayırım Gücü
KESTİRİLEN (KOR) SINIFLAMA GÖZLENE N (KOR) KOR (-) KOR (+) YÜZDESİ KOR (-) 116 28 80.56 KOR (+) 22 334 93.82
TÜMEL 90.00
yanları doğru olarak sınıflandırılma, seçicilik oranı olanların doğru olarak sınıflandırılma, duyarlılık oranı (specificity) % 80.56, koroner damar hastalığına sahip (sensitivity) % 93.82 olarak saptandı.
K A Y N A K L A R
1. Hosmer D.W., Lemeshovv S.: Applied Logistic Regression, J,Wiley&Sons, New York, 1989.
2. Agresti A. : Categorical Data Analysis, J.VVİley&Sons, New York, 1990.
3. Schlesselman J.J.: Case Control Studies, Oxford University Press, New York, 1982
4. Aggarwal A.R., Singh P.: Estimation of Relative Risk Control Studies Thrrough Logistic Regression Analysis, Bi-om.J.Vol:35 No.4,479-485, 1993.
5. Christensen R.: Log-Lineer Models, Springer-Verlag, New York, 1990.
6. Alpman A. et ali : Importance of Notching and Slurring of the Resting QRS complex in the Diagnosis of Coronary Artery Disease, Journal of Electrocardiology Vol:28 No.3 ,199-209,1995.
7. Norusis M.J.: SPSS For VVİndovvs 6.0 Advences Statistics, SPSS Inc. Chicago, 1993.