Hypergraph partitioning based models and methods for exploiting cache locality in sparse matrix-vector multiplication
Tam metin
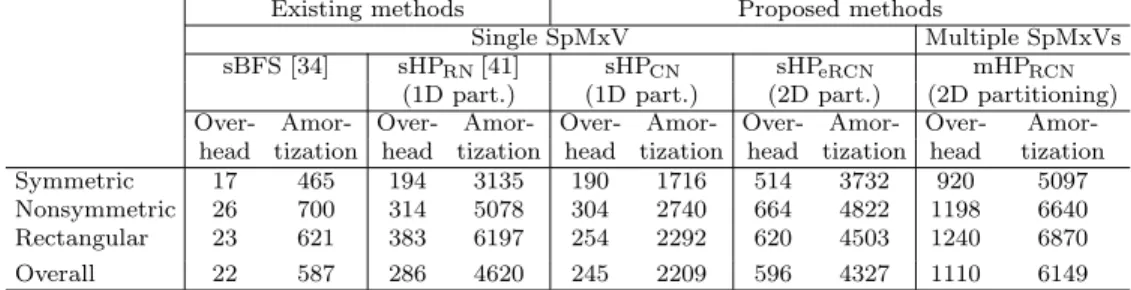
Şekil
Benzer Belgeler
Analysis of Volvo IT’s Closed Problem Management Processes By Using Process Mining Software ProM and Disco.. Eyüp Akçetin | Department of Maritime Business Administration,
Coupled optical microcavities in one-dimensional photonic bandgap structures Λ Photonic Crystal Localized Cavity Modes x..
We study the collective excitation modes of coupled quasi-one-dimensional electron gas and longitudinal-optical phonons in GaInAs quantum wires within the random-phase
As the size of the SPP cavity decreases, the width of the new plasmonic waveguide band increases owing to the formation of CROW type plasmonic waveguide band within the band gap
Keywords: Surface Plasmons, Grating Coupling, Optical Disks, Filter, Prism Coupling, MIM Waveguide, Mode Splitting, Plasmonic
Measured transmission spectra of wires (dashed line) and closed CMM (solid line) composed by arranging closed SRRs and wires periodically... Another point to be discussed is
• The topic map data model provided for a Web-based information resource (i.e., DBLP) is a semantic data model describing the contents of the documents (i.e., DBLP
This study examined the in fluence of immersive and non-immersive VDEs on design process creativ- ity in basic design studios, through observing factors related to creativity as
