Analysis of simple inventory control systems with execution errors: Economic impact under correction opportunities
Tam metin
Şekil
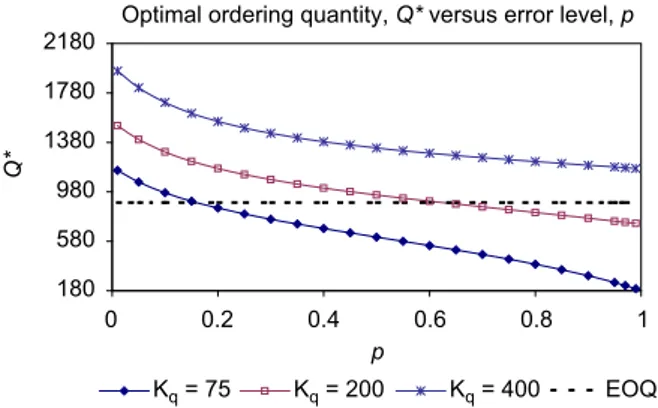
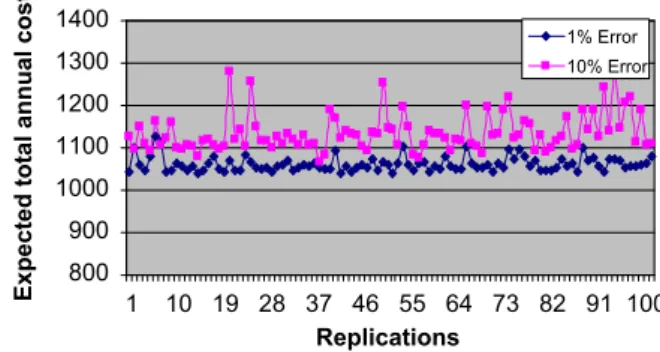
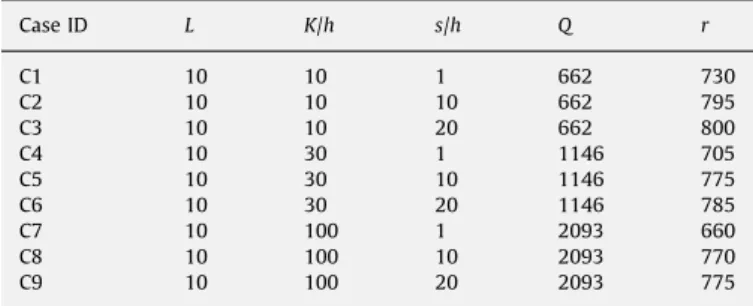

Benzer Belgeler
S OYADINI Atatürk’ün verdiği, ünlü keman ustalarından Nubar Tekyay’m İstanbul Yedikule Balıklı Ermeni Mezarlığındaki kabri, yeniden düzenlenerek anıt mezar
For solving this puzzle that why FLPR in Iran is low relative to other developing countries, despite of low fertility rate and high level of education, this
Finally, the result of inflation variance decomposition test indicated that the largest source of variation in inflation rate is a change in exchange rate followed by
From the fore going, Nigeria adopted four exchange rate regimes in this study namely; fixed exchange rate regime which is decided by the monetary authorities was
However, the objective of this study is to represent the analysis of impact of monetary policy on the economic growth in Turkey through using independent variables like money
Rusya ekonomisinin, özellikle de nükleer enerji endüstrisinin teknolojik modernizasyonu ve yenilikçi gelişiminin sağlanması için atom enerjisinin barışçıl
İki gün sonra Malatya’da, ondan sonra da İstanbul’da ailelerimiz için birer tören daha yaptık. Ne kadar da çabuk
means that losing all demands result in less costs. Therefore, our experiment set consists of 174 points. For Erlang cirid Normal demand distributions, a
