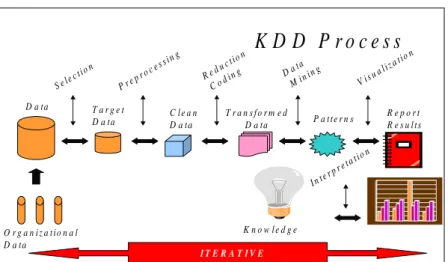
Frequent itemset mining, and association rules
Tam metin
Şekil
Benzer Belgeler
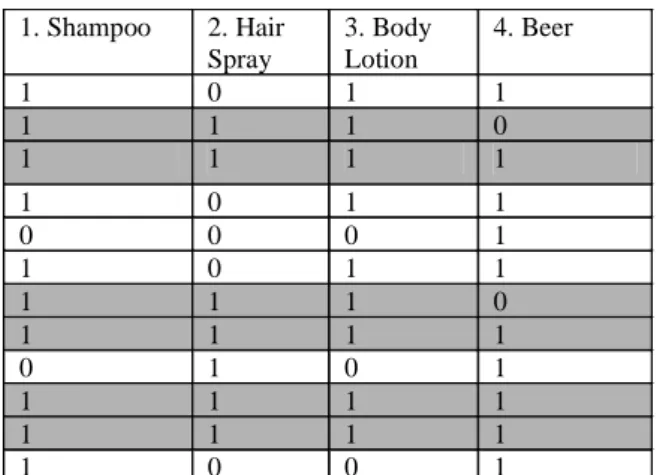
Partition 2: The k -Map is created for partition 2 which is given in Table 12 and the table is used to evaluate the support numbers of candidate k -itemsets in every stage
İn this paper vve report a case of meningioma vvhich subsequently developed in a patient vvith primary breast carcinoma.. Key Words: Breast cancer, menengioma,
C) Verilen kelimelerle aşağıdaki boşlukları doldurunuz.. I can look after
Ve uçtu tepemden birdenbire dam; Gök devrildi, künde üstüne künde.. Pencereye koştum: Kızıl
Wenn man den inneren Hof der Festung betritt, die seit 514 Jahren in der M itte des Bosporus den kommenden und gehenden Schif fen vom Prunk der Vergangenheit
Böylece Hacı Bektaş Velî, Mélikoff’un ifade ettiği gibi, Bektaşîliğin esin kaynağı olmaktadır (Mélikoff, 2007: 13). Hacı Bektaş Velî, tasavvufî, dinî ve ahlakî
[r]
In our study, we investigated a possible association of C677T and A1298C polymorphisms in MTHFR gene on unexplained male infertility in a group of Turkish infertile men
