Image synthesis in multi-contrast MRI with conditional generative adversarial networks
Tam metin
Şekil

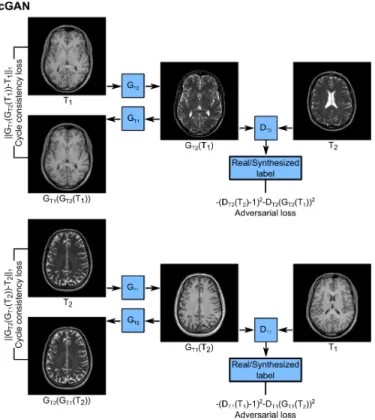
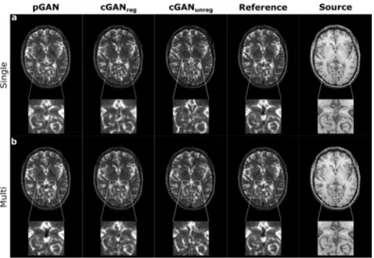

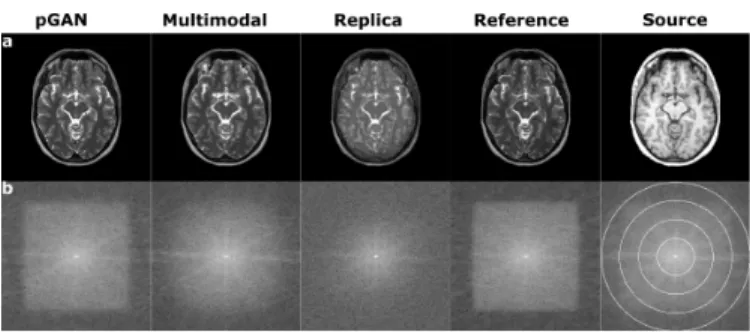
Benzer Belgeler
The interior architecture students’ learning styles were determined using Felder and Soloman’s (2004) ILS, which contains 44 items on four scales (Active/Reflective,
Compared to the early suggested SRR array based structures with a centered metallic mesh [9], the common effect of chirality inspired one-way polarization conversion in the
We also use the main observation to give a new perspective on a few basic results in the theory of defect groups of blocks.. Thanks are due to Laurence Barker and Justin Lynd,
While a few results have been reported on counting series of unlabeled bipartite graphs [ 1 – 4 ], no closed-form expression is known for the exact number of such graphs in
Epictetus Current discussions regarding the issue of cultural diversity have served to expose a set of questions concerning the imposition of aesthetic values in public spaces,
The most important finding of the study is that, themed environments such as three English Pubs in Ankara, often use fixed images derived from mass media. According to the
The literature on second language acquisition (SLA) deals with two different issues which both have been central to second language acquisition research. On one hand, researchers
We now discuss the relationship of time-order representations with the Wigner distribution and the ambiguity function. The Radon transforms and slices of the Wigner distribution and
