Automatic categorization of Ottoman poems
Tam metin
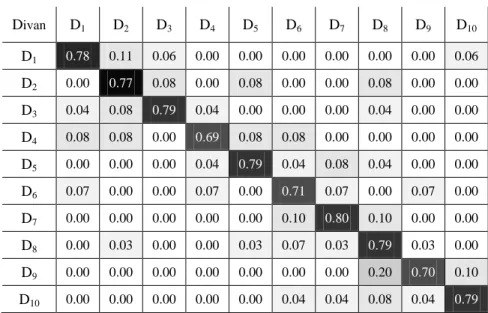
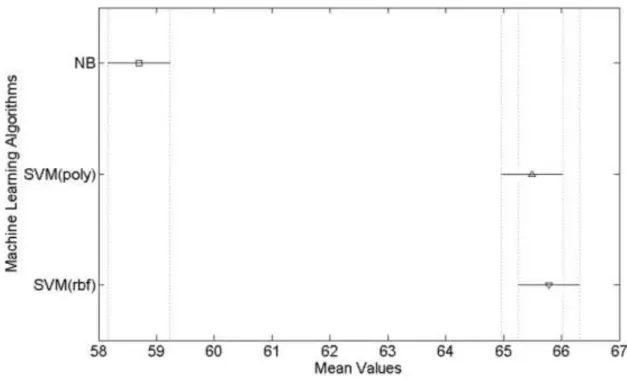
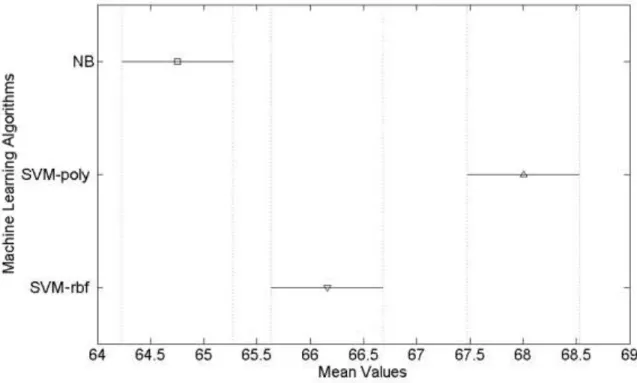
Şekil

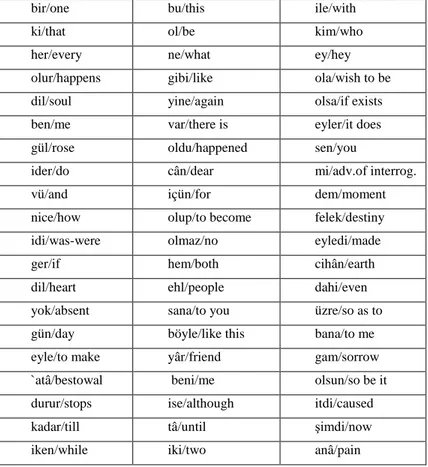
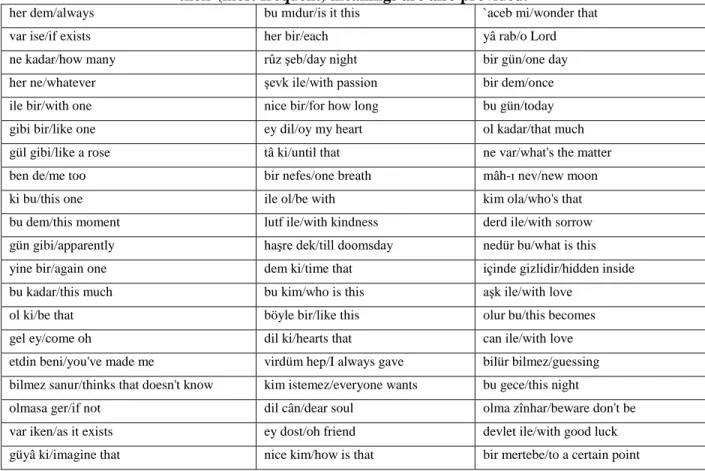
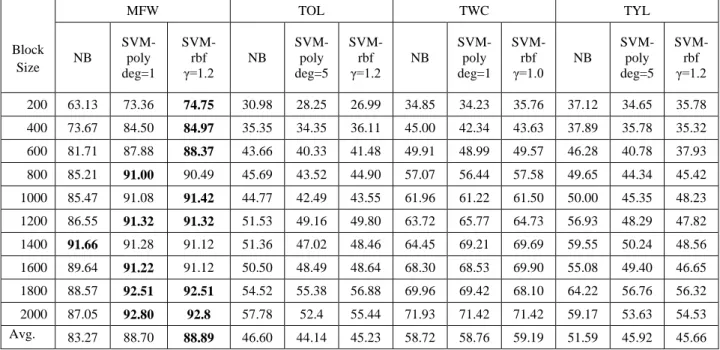
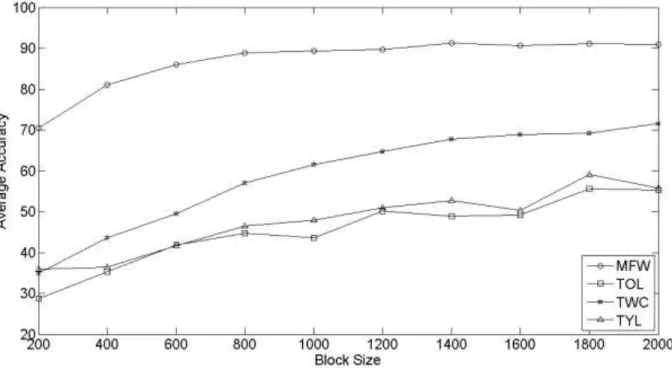
Benzer Belgeler
Anahtar Kelimeler: Şavşat, Düz Dokuma, Kilim, Duvar Kilimi, Kedel, Cami
The primary objective of this study was to describe the way Turkish foreign policy makers perceive foreign policy options as regards the water conflict between
On the other hand, optimal stochastic signaling further reduces the average probability of error by using all the available power and assigning some of the power to a large
vehicle to the rendezvous point at nearly t = 5 whereas the rendezvous time was specified as t f i = 10 initially, and no change were made during the travel... This result is
1988 yılında "Ellinci Sanat Yılı ve Türk Resim Sanatı’na katkılarından ötürü” TC Kültür Bakanlığı tarafından "O n u r Ödülü” ile ödüllendirilen,
Ozet: Sinonazal karsinomalar nadir tiimorler olup erken tam konulamadlgl durumlarda intrakranial invazyon gosteren agresif ve kotii prognozlu tiimorlerdir. intrakranial
This low latency is an important factor for selecting the HTC Vive and SteamVR platform for developing virtual reality music instruments, where as the competition
Deniz, sade bir manzara değildir; yalnız beşer hayalini doğuran, ona me deniyetler yaratmak için kaynak olan ve sonsuzluğu düşünmesini öğreten bir varlık olmadığı
