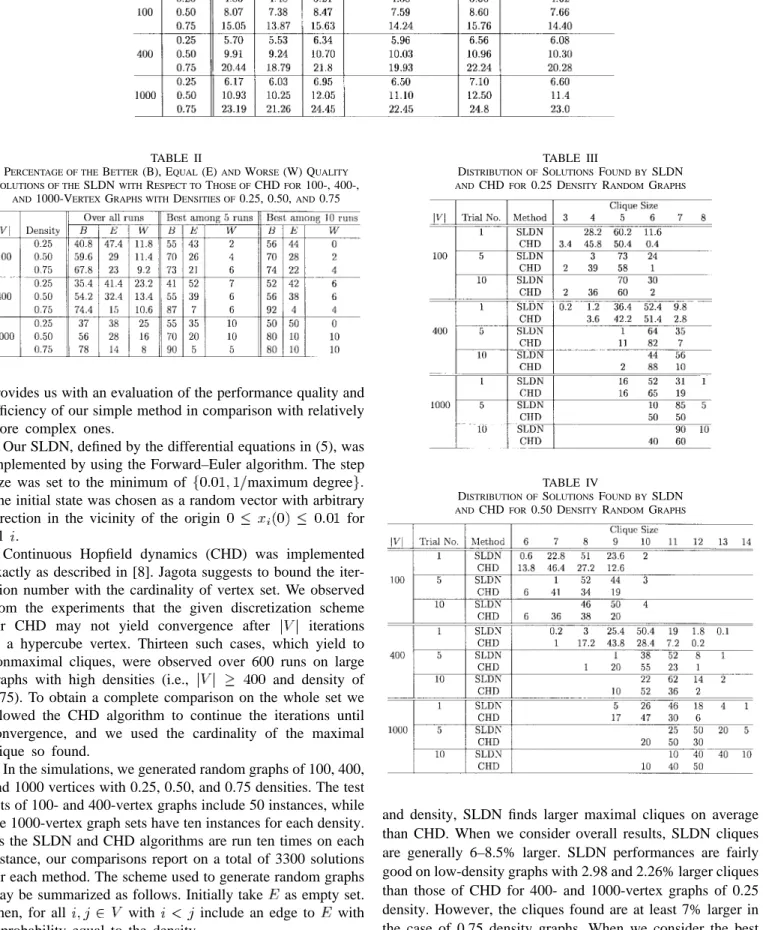
A saturated linear dynamical network for approximating maximum clique
Tam metin
Şekil
Benzer Belgeler
Onun her şeyin hür nedeni olması, her şeyi irade hürlüğü ya da mutlak keyif ve hevesle değil, mutlak (zorunlu) tabiatının yani sonsuz gücünün eseri olarak
We carried out measurements of mm-wave excitation spectra of high- order whispering gallery modes in free-space cylindrical disk resonators as functions of resonator thickness L
(A) PS beads suspended in 500 ppm, PEO 5MDa dissolved in 1X PBS solution. At low flow rates particles are aligned at the corners and the center of the channel. At higher flow rates
But we included it to emphasize that, although many schemes proposed in the literature may seem different mainly because of the order of the proposed response systems, they could
Physical Medicine and Rehabilitation, Magnet Hospital, Kayseri, Turkey Background: In the treatment of chronic neck pain (CNP), education, medical treatment, exercise and
Bu bağlamda, Sürdürülebilir Toprak Yönetimi Ulusal Eylem Planı (STY - UEP), FAO Türkiye Ülke Ofi si tarafından desteklenen ve T.C Tarım ve Orman Bakanlığı ile yapılan
The power capacity of the hybrid diesel-solar PV microgrid will suffice the power demand of Tablas Island until 2021only based on forecast data considering the
Cerrahi düşünülmeyerek tüm hastalarda baştan definitif kemoradyoterapi planlanmış olan çalışmamızda ise iki yıllık lokal kontrol ve genel sağkalım oranları sırasıyla %22
