Privacy protection for spatial trajectories against brute-force attacks
Tam metin
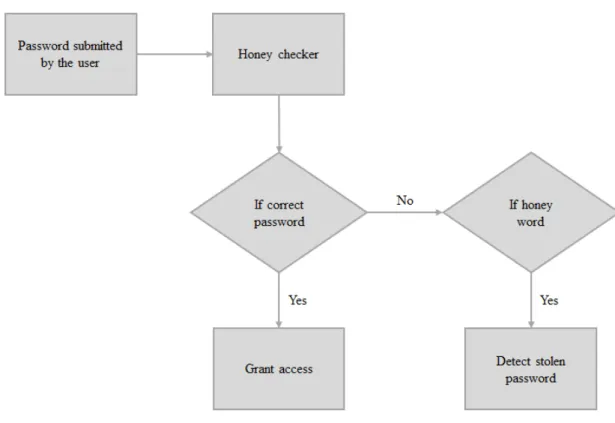
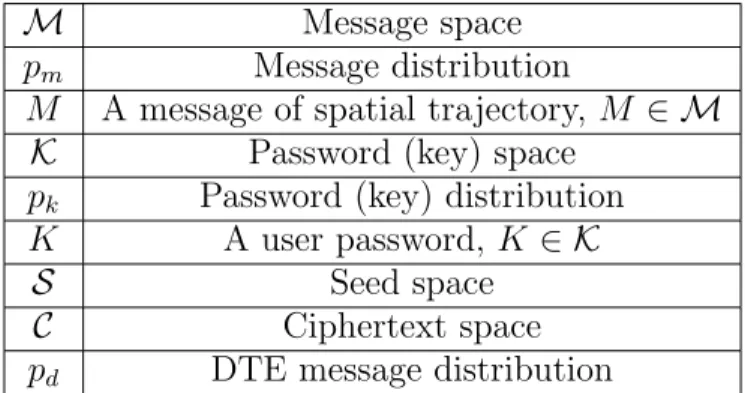
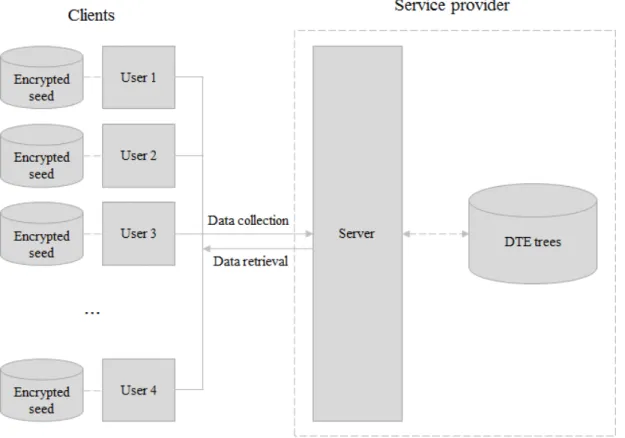
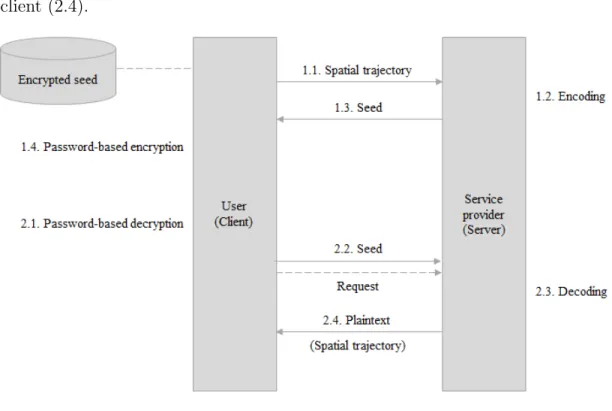
Şekil



Benzer Belgeler
By this device we are constantly reminded of: 1) the extent of the changes that had taken place in the West; and 2) the destiny of their eventual absorption into Ottoman life.
It is suggested (Frerichs, 2008: 3) that random sampling is a statistical sampling method where each unit remaining in the population has the same probability of being
generations and over time (Finch and Mason, 2007, p. It might occupy a mystical value because of concealing a time which cannot be repeated and perceptions of someone lost.
As mentioned in the section “List of Language Aid Programs” above, refugees and asylum seekers living in Sivas have the opportunity to take part in free Turkish courses offered by
The two main features of the interaction to be simulated within our model are (i) the oscillatory energy difference between the ferromagnetic and the antiferromagnetic ground
With contributions from key researchers, this book will be of interest to students and researchers working in materials science, as well as those working on cucurbituril-based
This volume contains the papers presented at the 8th European Conference on Case-Based Reasoning (ECCBR 2006).. Case-Based Reasoning (CBR) is an artificial intelligence approach
Osman Nuri makalesinde, Bulgar ordusunun piyade sınıfının ikiĢer taburlu 36 alaydan meydana geldiğini, harp zamanında alay ve tabur sayısının iki katına kadar
