REDUCING COHERENCY TRAFFIC
VOLUME IN CHIP MULTIPROCESSORS
THROUGH POINTER ANALYSIS
a thesis submitted to
the graduate school of engineering and science
of bilkent university
in partial fulfillment of the requirements for
the degree of
master of science
in
computer engineering
By
Erdem Dereba¸so˘
glu
September 2017
Reducing Coherency Traffic Volume in Chip Multiprocessors Through Pointer Analysis
By Erdem Dereba¸so˘glu September 2017
We certify that we have read this thesis and that in our opinion it is fully adequate, in scope and in quality, as a thesis for the degree of Master of Science.
¨
Ozcan ¨Ozt¨urk(Advisor)
U˘gur G¨ud¨ukbay
S¨uleyman Tosun
Approved for the Graduate School of Engineering and Science:
Ezhan Kara¸san
ABSTRACT
REDUCING COHERENCY TRAFFIC VOLUME IN
CHIP MULTIPROCESSORS THROUGH POINTER
ANALYSIS
Erdem Dereba¸so˘glu M.S. in Computer Engineering
Advisor: ¨Ozcan ¨Ozt¨urk September 2017
With increasing number of cores in chip multiprocessors (CMPs), it gets more challenging to provide cache coherency efficiently. Although snooping based pro-tocols are appropriate solutions to small scale systems, they are inefficient for large systems because of the limited bandwidth. Therefore, large scale CMPs re-quire directory based solutions where a hardware structure called directory holds the information. This directory keeps track of all memory blocks and which core’s cache stores a copy of these blocks. The directory sends messages only to caches that store relevant blocks and also coordinates simultaneous accesses to a cache block. As directory based protocols scaled to many cores, performance, network-on-chip (NoC) traffic, and bandwidth become major problems.
In this thesis, we present software mechanisms to improve effectiveness of di-rectory based cache coherency on CMPs with shared memory. In multithreaded applications, some of the data accesses do not disrupt cache coherency, but they still produce coherency messages among cores. For example, read-only (private) data can be considered in this category. On the other hand, if data is accessed by at least two cores and at least one of them is a write operation, it is called shared data. In our proposed system, private data and shared data are determined at compile time, and cache coherency protocol only applies to shared data. We im-plement our approach in two stages. First, we use Andersen’s pointer analysis to analyze a program and mark its private instructions, i.e instructions that load or store private data, at compile time. Second, we run the program in Sniper Multi-Core Simulator [1] with the proposed hardware configuration. We used SPLASH-2 and PARSEC-2.1 parallel benchmarks to test our approach. Simula-tion results show that our approach reduces cycle count, dynamic random access memory (DRAM) accesses, and coherency traffic.
iv
¨
OZET
C
¸ OK C
¸ EK˙IRDEKL˙I ˙IS
¸LEMC˙ILERDE ˙IS
¸ARETC
¸ ˙I
ANAL˙IZ˙I KULLANARAK ¨
ONBELLEK TUTARLILIK
TRAF˙I ˘
G˙IN˙IN AZALTILMASI
Erdem Dereba¸so˘glu
Bilgisayar M¨uhendisli˘gi, Y¨uksek Lisans Tez Danı¸smanı: ¨Ozcan ¨Ozt¨urk
Eyl¨ul 2017
C¸ ok ¸cekirdekli i¸slemcilerdeki (CMP) ¸cekirdek sayısı arttık¸ca ¨onbellek tutarlılı˘gını verimli bir ¸sekilde sa˘glamak zorla¸smaktadır. Dinleme temelli protokoller k¨u¸c¨uk ¸caplı sistemler i¸cin uygun ¸c¨oz¨umler olsa da bant geni¸sli˘gine bindirdikleri ek y¨ukten dolayı daha geni¸s sistemler i¸cin verimli olmamaktadırlar. Bu sebepten geni¸s ¸caplı CMP’ler dizin temelli ¸c¨oz¨umlere ihtiya¸c duyarlar. Dizinin g¨orevi b¨ut¨un bellek bloklarının hangi ¸cekirde˘gin ¨onbelle˘ginde kopyasının bulundu˘gunu tutmaktır. Dizin sadece ilgili blokları tutan ¨onbelleklere mesaj yollar ve ¨onbelle˘ge yapılan e¸s zamanlı eri¸sim isteklerini d¨uzenler. Dizin temelli protokoller ¸cok sayıda ¸cekirde˘ge ¨
ol¸ceklenirken, ba¸sarım, a˘g trafi˘gi ve bant geni¸sli˘gi ¨onemli problemler olmaktadır.
Bu tezde, payla¸sımlı bellek kullanan CMP’lerde dizin temelli protokollerin ver-imini arttıracak yazılım temelli bir ¸c¨oz¨um sunmaktayız. C¸ ok i¸s par¸cacıklı uygu-lamalarda, veri eri¸simlerinin bazıları ¨onbellek tutarlılı˘gını bozmaz ancak yine de ¸cekirdekler arasında tutarlılık mesajları ¨uretir. ¨Orne˘gin, salt okunur (¨ozel) veriler bu kategoride de˘gerlendirilebilir. ¨Ote yandan, verilere en az iki ¸cekirde˘gin eri¸sti˘gi ve bunların en az birinin bir yazma i¸slemi oldu˘gu takdirde ilgili eri¸silen veriye payla¸sılan veriler denir. ¨Onerdi˘gimiz sistemde, ¨ozel veriler ve payla¸sılan veriler derleme zamanı belirlenir ve ¨onbellek tutarlılık protokol¨u yalnızca payla¸sılan ver-iler i¸cin uygulanır. Bu ¸calı¸smada, yakla¸sımımızı iki a¸samalı olarak uyguluyoruz. ˙Ilk olarak, bir programı analiz etmek ve ¨ozel komutlarını, yani derleme zamanında ¨
ozel veriyi y¨ukleyen veya depolayan talimatları i¸saretlemek i¸cin Andersen’in i¸saret¸ci analizini kullanıyoruz. ˙Ikinci olarak, Sniper Multi-Core Simulator [1] kullanarak ¨onerilen donanım ayarlarında testleri ¸calı¸stırıyoruz. Yakla¸sımımızı test etmek i¸cin SPLASH-2 ve PARSEC-2.1 paralel uygulamalarını kullandık. Sim¨ulasyon sonu¸cları, yakla¸sımımızın d¨ong¨u sayısını, dinamik rastgele eri¸simli
vi
bellek (DRAM) eri¸simlerini ve tutarlılık trafi˘gini azalttı˘gını g¨ostermektedir.
Anahtar s¨ozc¨ukler : ¨Onbellek tutarlılı˘gı, ¸cok ¸cekirdekli i¸slemciler, veri, i¸saret¸ci analizi, dizin.
Acknowledgement
This study was fully funded by the Scientific and Technological Research Council of Turkey (TUBITAK) with grant 113E258.
Contents
List of Figures x
List of Tables xii
1 Introduction 1
1.1 Contributions . . . 2
2 Related Work 4
3 Motivation 8
3.1 Cache Coherency Problem . . . 8
3.2 Directory Based Protocols . . . 11
4 Our Approach 13
4.1 Architecture . . . 13
4.2 Finding Private Data . . . 14
CONTENTS ix
4.4 Increasing Performance by Reducing Network on Chip Traffic . . 22
5 Experiments 25 5.1 Setup . . . 25
5.2 Pointer Analysis Results . . . 26
5.3 Performance and Traffic . . . 28
5.3.1 Cycle Time . . . 28
5.3.2 Coherency Traffic . . . 29
6 Conclusion 32
List of Figures
3.1 Cache coherency problem #1. . . 9
3.2 Cache coherency problem #2. . . 9
3.3 Cache coherency problem #3. . . 10
4.1 A tile used in 8 and 16 core simulations. . . 14
4.2 4-core simulation setup. . . 15
4.3 8-core simulation setup. . . 15
4.4 16-core simulation setup. . . 16
4.5 Points-to graph for p = &a. . . 20
4.6 Points-to graph for p = q. . . 20
4.7 Points-to graph for p = *r. . . 21
4.8 Points-to graph for *p = &a. . . 21
4.9 Points-to graph for *p = q. . . 21
LIST OF FIGURES xi
4.11 MESI protocol state diagram, where PW = processor write, PR = processor read BW = observed bus write, BR = observed bus read S = shared, !S = not shared. . . 23
5.1 Normalized private L1 accesses (%). . . 27
5.2 Normalized cycle time reduction (%). . . 28
5.3 Normalized number of packets reduced over on-chip network (%). 29
5.4 Normalized total traffic volume reduced over on-chip network (%). 30
5.5 Normalized load reduction from other tiles’ L3 caches (%). . . 30
List of Tables
5.1 Simulated hardware configurations. . . 26
Listings
4.1 Example C code. . . 17 4.2 LLVM intermediate representation code for fun1 function. . . 18 4.3 X86 assembly code for fun1 function. . . 19
Chapter 1
Introduction
From the beginning of 80s to 2000s, microprocessor designers usually emphasised two ideas to increase performance: higher clock speed and instruction level paral-lelism (ILP). Next generation silicon technology allowed smaller transistors with high clock speed. Another advancement which provided higher clock speeds is pipelining technique. Pipelining divides instructions into many steps so that in every clock cycle, one step of multiple instructions are executed simultaneously. Therefore, it provides instruction level parallelism. On the other hand, scaling in transistor size allowed more transistors to be placed on the same core. These ad-ditional transistors are used to increase processor performance. Techniques such as dynamic instruction scheduling, multiple instruction issue, register renaming help maximizing efficiency of instruction level parallelism.
Typical processors usually have four pipelines: integer pipeline, memory pipeline, floating-point pipeline, and branch pipeline [2]. Processors are also de-signed to execute independent instructions from multiple threads. Therefore, si-multaneous multithreading (SMT) became widespread [3–5]. For example, Com-paq Alfa 21464, Intel Xeon, and Sun UltraSPARC IV are SMT processors. But setting issue width to more than 6 or 8 instructions increases processor complexity exponentially which makes processor validation costly. In addition, exponential increase of power in these types of processors [6] makes cooling more difficult so
single core processors have not been used since the beginning of 2000s [7]. As a re-sult, CMPs have become more common in systems from embedded to high-end. Currently, almost all chip manufacturers produce multi core processors [8–13]. In some cases, each core in a multicore processor system support SMT. For in-stance, Ultra SPARC T2 processor consists of 8 cores and each core can execute instructions from 8 different threads (but only from 2 threads in the same clock cycle).
Compared to CMPs, caches have been used even longer to provide faster access between random access memory (RAM) and processor. Caches are designed to benefit from locality principle in programs, where a much smaller area compared to RAM stores recently used data, thereby allowing major part of data accesses to be faster. Most of the CMP implementations [10–14] dedicate a cache to each core which is only accessible by the same core.
It is a challenge to maintain cache coherency efficiently in CMPs. It is even more difficult for CMPs with a large number of cores. Snooping based protocols use broadcasting which results in additional load on bandwidth. On the other hand, directory based coherency protocols avoid broadcasting so they can be scaled to more cores easily. This is achieved through the use of a directory by tracking data blocks in caches. However, standard coherency protocols do not distinguish between shared data, which is accessed by two or more cores, and private data which is accessed by only one core. Since private data do not require cache coherency, they can be allowed to bypass the cache coherency protocol to gain performance.
1.1
Contributions
Our goal in this work is to make directory based protocols efficient in terms of performance, network on chip traffic, space, and power consumption. Specifically, our method is based on distinguishing shared data from private data to focus only on shared data to preserve cache coherency. We observe the effects of our
approach for both small scale CMPs and large scale CMPs.
Although there are studies that identify shared and private data at the operat-ing system (OS) level, our approach uses a compiler based technique at runtime. Identification by the OS is done at page granularity, which makes it uncertain whether a data can bypass coherency protocol. For example, when shared data and private data are on the same page, they can both be considered as shared, which reduces efficiency. We decide whether data is shared or private at compile time and manage data at the lowest level (cache block) of the coherency protocol.
Our contributions in this work can be summarized as follows:
• First, we use pointer analysis to determine private data at compile time.
• Second, instructions that use private data are marked so that these can bypass coherency protocol.
• Third, we test our approach on simulated hardware.
Through our approach, private data bypass coherency protocol which improves overall performance. Simulations show that this approach decreases cycle time and coherency traffic in terms of loads from DRAM, loads from remote caches, traffic volume, and number of packets. We see similar results with various settings ranging from 4 to 16 cores.
The rest of this thesis is organized as follows. Chapter 2 discusses background information and related work. Chapter 3 explains our motivation and gives an example of our private data detection method. Chapter 4 shows the hardware model that we used in our experiments and explains our approach. Chapter 5 gives our hardware configuration and experimental results. Finally, Chapter 6 concludes the thesis.
Chapter 2
Related Work
Snooping based protocols are a good solution for CMPs with few cores [8, 15]. There are studies to decrease the pressure that snooping based protocols are generating on the network. For instance, Moshovos proposed RegionScout [16] which is a filter mechanism to detect non-shared regions in memory. This filter can determine beforehand if a request will miss in remoted caches. RegionScout requires no changes to existing snoop-based coherency systems, instead it serves as an extension. However, it requires extra storage and an additional global signal to identify global region misses. Salapura et al. [17] proposed another filtering mechanism called BlueGene/P. Their proposal involves combining stream registers and snoop caches to capture the locality of snoop addresses and their streaming behaviour.
Despite these studies about snooping based protocols, general conclusion is that these protocols do not scale well with manycores. Therefore, large scale CMPs such as TILEPro64 [18] often use directory based cache protocols. Dupli-cate tag directory which is one of the most common directory scheme is inefficient on power consumption because it needs high associativity [19]. Kotfi-Kamran et al. [19] try to reduce directory power consumption using a power-efficient lookup structure. Their filter structure consists of an array of buckets which is used to check if there is a match in the directory. Therefore, it eliminates the need for
costly directory accesses.
On the other hand, sparse directory scheme is efficient on power but inefficient on directory storage cost [20]. Studies about scaling directory schemes are usu-ally about sparse directories. For instance, Ferdman et. al aim to reduce tag leap caused by limited associativity by using Cuckoo hashing [20]. Kelm et al. [21] studied simulating large directory cache by logically combining a small directory with a larger directory in cache. Other studies aim to scale sparse directory scheme to increase number of cores with approximate representation of sharing information about cache blocks [22–25]. Tagless coherency directory has been proposed by Zebchuk et al. [23] which uses bloom filters to summarize the tags in a cache set. Zhao et al. [22] try to improve tagless directory by eliminating the redundant copies of sharing patterns. Their approach exploits the sharing pattern commonality to decouple sharing patterns from bloom filters. In another study, Zhao et al. [24] proposed a method that decouples the sharing pattern from each cache block and holds them in a separate directory table. They take advantage of the fact that many memory locations are accessed by the same set of processors which results in a few sharing patterns that occur frequently. Sanchez et al. [25] proposed a scalable coherency directory which uses highly-associative caches to implement a single-level directory. The directory uses a number of directory tags to represent sharer sets which makes it scalable. However, these techniques either invalidate cache blocks, hence decrease performance, or compli-cate cache coherency protocol and become power-inefficient. Our approach relies on excluding private data from coherency protocol so it does not have these dis-advantages. In addition, our mechanism can be combined with other methods to provide further benefits.
Since sharing information is distributed among cores according to their physical addresses in directory based protocols, messages which provide coherency are sent from the source node to the home node of the block. Then, they are sent from the home node to nodes that have copies of that block. In other words, messages are delivered indirectly. Marty [26] et al. proposed a Multiple-CMP coherency protocol named Token-CMP which prevents indirection to allow messages to reach their destinations faster. They use a flat directory protocol which is simpler than
verifying hierarchical directory protocols. Nonetheless, messages are sent using broadcasting technique in their approach which results in inefficiency in power consumption. Ros et al. [27] keep up-to-date sharing information about blocks in the cache that is responsible for providing the block and allows direct messaging in their DiCo-CMP study. In their approach, caches have to know which private cache has an up-to-date copy of a block needed. For this purpose, each core requires a special cache that stores up-to-date cache locations of blocks. Since our approach eliminates communication about private data, it can be combined with Token-CMP and DiCo-CMP methods to gain extra performance. Tracking only shared blocks can reduce space requirement in DiCo-CMP method where up-to-date cache block locations are stored.
Cache access time in CMPs depends on the distance between cache and core which may result in non uniform cache access (NUCA) [28]. D-NUCA is a study where frequently accessed data blocks are brought to cache segments that are close to a single-core processor [29]. Beckmann and Wood studied the adaptation of D-NUCA to CMPs and its effects on performance [30]. Blocks that are pushed out from local L1 caches are usually needed again soon. Therefore, it can be useful if these blocks have a copy in a nearby L2 cache [31].
There are recent studies to increase cache coherency protocol efficiency by de-tecting private and shared pages. Hardavellas et al. [32] proposed new methods to make cache block replacements more efficient at CMPs with this kind of de-tection. A technique to filter coherency messages in snooping based protocols by placing memory block sharing information in a page table was proposed by Ahn et al [33]. Their proposed method uses sharing information in the page table to determine the cores to send coherency messages to, so it avoids unnecessary communication. Cuesta et al. [34] try to reduce data traffic due to coherency protocol. However, there are important differences between our study and theirs. First, in their implementation, an operating system (OS) based method (proposed in [33]) decides private and shared data. This decision is done at the page size granulatiry. Therefore, private data placed on the same page with shared data is conservatively marked as shared in this method. In other words, a portion of
data can bypass coherency protocol and is forced to be included in coherency pro-tocol. However, we determine private and shared data using compiler and keep data at the lowest size that coherency protocol can use (cache blocks). Second, in our approach, the operating system does not need to be modified while their technique requires changes in page tables and translation lookaside buffer (TLB).
Chapter 3
Motivation
3.1
Cache Coherency Problem
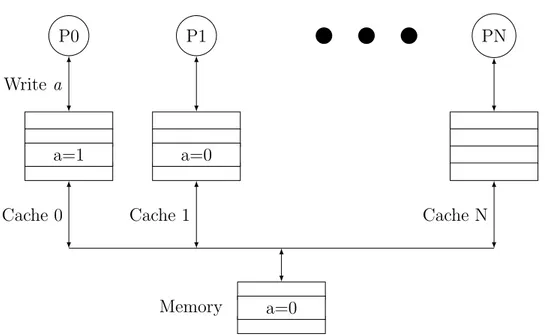
In a parallel system with shared memory accesses, multiple copies of the same variable are stored in multiple caches at the same time. This causes a cache coherency problem as shown in Figures 3.1 - 3.3. Assume there is a system with N+1 cores, where each core has its own cache. In the beginning, variable a is only in memory and its value is 0 as shown in Figure 3.1. After a read request from P0 and P1, data is copied from memory into their subsequent caches as shown in Figure 3.2. All reads from P0 and P1 are satisfied from their private cache. When P0 assigns 1 to a, even if it is a write-through cache, the value of a will not be updated in P1’s cache and will remain as 0. This problem is known as cache coherency problem. To solve this problem, read operation on shared data returns the most up-to-date version. In our example, before P0 assigns a new value to a, it sends a message to other cores to invalidate their copies. Caches that receive this message send confirmation messages to P0 followed by an update in P0. Thus, when P1 accesses a it knows its copy is invalid and brings up-to-date value from P0. Our approach eliminates such coherency messages for data that are not shared among cores.
P0 P1 PN
a=0 Memory
Cache 0 Cache 1 Cache N
Figure 3.1: Cache coherency problem #1.
P0 P1 PN
a=0 a=0
a=0 Memory
Read a Read a
Cache 0 Cache 1 Cache N
P0 P1 PN
a=1 a=0
a=0 Memory
Write a
Cache 0 Cache 1 Cache N
Figure 3.3: Cache coherency problem #3.
Solutions to cache coherency problem are divided to two categories: software based, and hardware based. In software based solutions, the compiler marks data as cacheable and not cacheable. Usually, read-only data is considered cacheable. Other data are marked not cacheable and are stored in shared cache (if exists). Even though software based solutions are cheaper since they do not require extra hardware, they result in loss of performance because they prevent commutative data from being stored in private caches.
Hardware solutions bring extra cost because they require special hardware. Compared to software solutions, hardware solutions where all data access requests are satisfied from level 1 private cache have better performance. Hardware so-lutions are separated into two categories: snooping based and directory based. Snooping based approaches are suitable for multi core systems where cores are connected through a common bus. However, a common bus becomes a bottleneck in CMPs with 16 or more cores. Hence, directory based solutions are preferred for large scale CMPs. In this thesis, our focus is also on directory based CMPs.
3.2
Directory Based Protocols
It requires a huge hardware storage to track all memory blocks in DRAM. Thus, newer commercial CMPs such as AMD Magny Courses [35] track blocks only if they are copied to caches. Sharing information about memory blocks is stored in directories. For each cache block this information consists of which private caches store its copy, whether these copies are dirty, and which cache is the owner (if it has one). As in snooping based protocols, clean copies of a memory block can be stored in multiple private caches. If a copy is to be updated, other copies are first invalidated or updated. Furthermore, directory information is distributed among tiles to avoid conflicts. Note that sharing information about a memory block is held in a single directory entry system-wide. Hence, the directory entry functions as an ordering point for simultaneous requests for a related block. Unlike snooping based protocols, messages about a block are sent only to tiles that have a copy of it; hence reducing bandwidth requirement. Another advantage of directory based protocols is the ability to handle coherency messages for different cache blocks in a parallel manner.
Most common directory designs are duplicate tag directories and sparse di-rectories. Duplicate tag directory organization allow tracing all data blocks on private caches by using a structure that keeps all address tags in private caches. Duplicate tag directory decides which caches will receive a message by comparing the block address tag on the message to all tags in the directory set. In such a tag directory, associativity must be equal to the multiplication of cache associativity and the number of caches in the system. This causes directory structures with high associativity and therefore a massive amount of power consumption on tag comparison. Nowadays, even for 8 or less core CMPs, 4 or 8-way private caches are inefficient in terms of power [20].
Another directory design of directory based protocols is sparse directory or-ganization. In this organization, directory structure way associativity is reduced so that tag comparisons are cheaper in terms of power consumption. Unlike du-plicate tag directories, where there is a one-to-one relationship between directory
records and cache blocks, there is a sharing list for each directory record.
We can summarize advantages and disadvantages of duplicate tag directory and sparse directory as follows. Duplicate tag directories are efficient on storage area but inefficient on power consumption for tag comparison; sparse directories are the opposite, efficient on power but inefficient on storage. Since sparse direc-tories are more scalable, we used full-map sparse direcdirec-tories for our simulations in this thesis.
Chapter 4
Our Approach
Previous studies show that a large part of data accesses on parallel applications are to private data [32]. Only one of the cores is affected by the changes on private data and those changes are made by that same core, allowing private data to by-pass cache coherency protocols. In standard cache coherency protocols, all data blocks must be handled by the protocol, increasing the bandwidth requirement on NoC and inefficiency on directory power consumption and size. This prob-lem becomes more severe since the number of cores in CMPs keep increasing. Our approach allow private data to bypass cache coherency protocol to increase efficiency of directory based protocols.
4.1
Architecture
We tested our approach using two types of cache hierarchies as explained below:
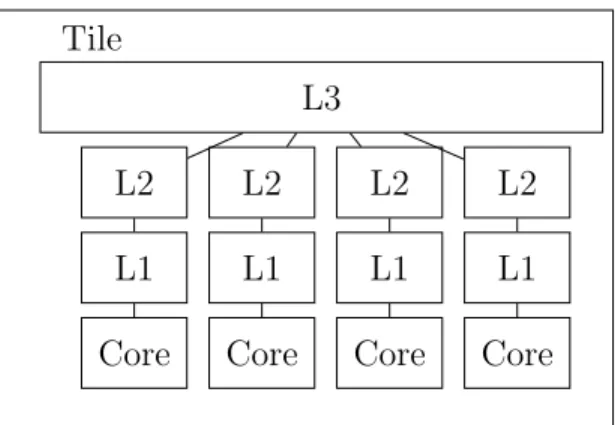
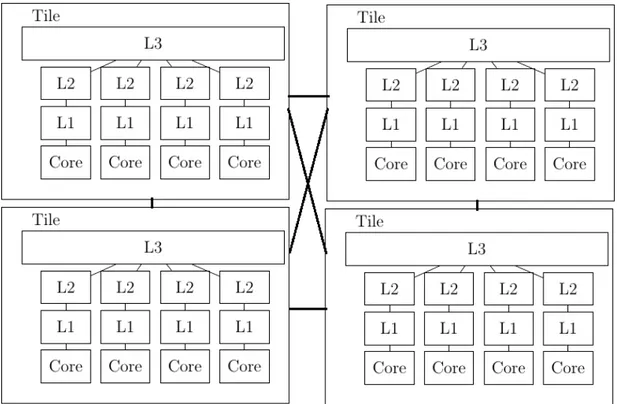
1. Figure 4.1 shows the first type of tile used in our simulations. In this setup, each tile contains 4 cores and a shared last level cache. We used a bus network for intra-tile communication and a mesh network for inter-tile communication. This tile is used in 8 and 16 core simulations which have 2
Core Core Core Core L1 L2 L1 L2 L1 L2 L1 L2 L3 Tile
Figure 4.1: A tile used in 8 and 16 core simulations.
and 4 tiles, respectively. Figures 4.3 and 4.4 shows our 8-core and 16-core simulation setups, respectively.
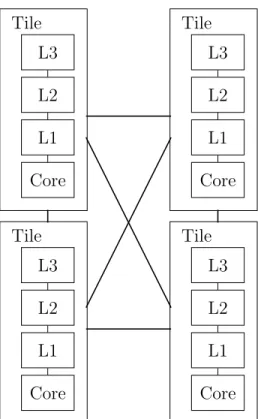
2. The second type, used in our 4-core simulations, has a cache hierarchy as shown in Figure 4.2. Specifically, there is no shared cache among cores and tiles are connected via a mesh network.
Note that, L1 data and L1 instruction caches share next level caches. In other words, L2 and L3 caches store both data and instruction. In Figures 4.1 and 4.2, L1 represents both L1 data and L1 instruction caches for simplicity. The directory structure is a sparse full-map directory where there is a sharing list for each directory record. For every memory block, an N-bit vector is maintained where N is the number of tiles. When the bit is 1, a copy of a block is in that tile’s L3 cache. When the bit is 0, there is no such copy in that cache. Note that, directory protocol is only among tiles, whereas cores in the same tile use snooping protocol to achieve coherency.
4.2
Finding Private Data
Pointer analysis is a static program analysis method which is used to determine the pointers that point to the same object in the program. Our proposed hardware relies on separating private data and shared data at compile time using such
Core Core Core Core L1 L2 L3 L1 L2 L3 L1 L2 L3 L1 L2 L3 Tile Tile Tile Tile
Figure 4.2: 4-core simulation setup.
Figure 4.4: 16-core simulation setup.
analysis. First, we use Andersen’s pointer analysis algorithm [36] to create a points-to graph. Then, if two pointers are not in the same function and they point to the same object, they are marked as shared. Otherwise, they are considered as private. Private objects bypass coherency protocols. We implemented the pointer analysis as a pass on LLVM [37]. LLVM is a collection of libraries built to support compiler development and related tasks. It also provides a powerful intermediate representation (IR), which is in static single assignment (SSA) form, where each variable is assigned exactly once to allow low level analysis.
Listing 4.1 shows a simple C program as an example to explain our approach. In this example, fun1 function is executed in a parallel manner. fun1 takes an argument arg and stores it in data which is a global variable. Therefore, it is considered as shared data. On the other hand, p and q pointers are local and private.
1 #include < s t d l i b . h> 2 #include <s t d i o . h> 3 #include <p t h r e a d . h> 4
5 #define NUM THREADS 2 6 i n t d a t a ; 7 8 void ∗ f u n 1 ( void ∗ a r g ) { 9 d a t a = ( i n t ) a r g ; 10 i n t ∗p , ∗q ; 11 p = q ; 12 p t h r e a d e x i t (NULL ) ; 13 } 14 15 i n t main ( i n t a r g c , char ∗∗ a r g v ) { 16 p t h r e a d t t h r [NUM THREADS ] ; 17 i n t t h r d a t a [NUM THREADS ] ; 18 i n t i ;
19 f o r ( i = 0 ; i < NUM THREADS; ++i ) { 20 t h r d a t a [ i ] = i ;
21 p t h r e a d c r e a t e (& t h r [ i ] , NULL, fun1 , &t h r d a t a [ i ] ) ; 22 }
23
24 f o r ( i = 0 ; i < NUM THREADS; ++i ) { 25 p t h r e a d j o i n ( t h r [ i ] , NULL ) ;
26 } 27
28 return EXIT SUCCESS ; 29 }
Listing 4.1: Example C code.
First, the program in Listing 4.1 is converted into LLVM IR to be ready for analysis. After we conduct the pointer analysis on the program, private load and
store instructions are renamed to loadpr and storepr which are private versions of load and store. Listing 4.2 shows the LLVM IR code of fun1 function after the analysis. Variable q is loaded into %2 and %2 is stored into q. Since p and q are private data, their instructions are also private. In the next step, IR code is converted to assembly as shown in Listing 4.3. Note that, semicolon (;) is used for comments in LLVM IR.
1 @data = common g l o b a l i32 0 , a l i g n 4 2 ; F u n c t i o n A t t r s : nounwind u w t a b l e 3 define i 8 ∗ @fun1 ( i 8 ∗ %a r g ) #0 { 4 e n t r y : 5 %r e t v a l = a l l o c a i 8 ∗ , a l i g n 8 6 %a r g . a d d r = a l l o c a i 8 ∗ , a l i g n 8 7 %p = a l l o c a i32 ∗ , a l i g n 8 8 %q = a l l o c a i32 ∗ , a l i g n 8 9 store i 8 ∗ %arg , i 8 ∗∗ %a r g . a d d r , a l i g n 8 10 %0 = load i 8 ∗ , i 8 ∗∗ %a r g . a d d r , a l i g n 8 11 %1 = p t r t o i n t i 8 ∗ %0 to i32
12 store i32 %1, i32 ∗ @data , a l i g n 4 13 %2 = l o a d p r i32 ∗ , i32 ∗∗ %q , a l i g n 8 14 s t o r e p r i32 ∗ %2, i32 ∗∗ %p , a l i g n 8 15 c a l l void @ p t h r e a d e x i t ( i 8 ∗ n u l l ) #4 16 unreachable 17 18 r e t u r n : 19 %3 = load i 8 ∗ , i 8 ∗∗ %r e t v a l , a l i g n 8 20 ret i 8 ∗ %3 21 }
Listing 4.2: LLVM intermediate representation code for fun1 function.
Listing 4.3 shows the X86 assembly code for fun1 function. In this step, private instructions in the IR code are converted to their assembly counterparts. We mark instructions that handle private data with different names (i.e movqpr). These are different from shared instructions. As such, when Sniper reads a private
instruction, it considers its data as private, thereby letting them bypass coherency protocol. 1 f u n 1 : # @fun1 2 . c f i s t a r t p r o c 3 # BB#0: # %e n t r y 4 pushq %rbp 5 . Ltmp0 : 6 . c f i d e f c f a o f f s e t 16 7 . Ltmp1 : 8 . c f i o f f s e t %rbp , −16 9 movq %r s p , %rbp 10 . Ltmp2 : 11 . c f i d e f c f a r e g i s t e r %rbp 12 subq $32 , %r s p 13 x o r l %eax , %eax 14 movl %eax , %e c x 15 movq %r d i , −16(%rbp ) 16 movq −16(%rbp ) , %r d i 17 movl %e d i , %eax 18 movl %eax , d a t a #s h a r e d 19 movqpr −32(%rbp ) , %r d i #p r i v a t e 20 movqpr %r d i , −24(%rbp ) #p r i v a t e 21 movq %rcx , %r d i 22 c a l l q p t h r e a d e x i t
Listing 4.3: X86 assembly code for fun1 function.
4.3
Andersen’s Pointer Analysis
This section provides insight to Andersen’s pointer analysis. Andersen’s analysis is a flow-insensitive and context-insensitive analysis. In other words, it does not take the input program’s control-flow graph into consideration. It also does not
consider the calling context when analyzing function calls. Andersen’s analysis can be summarized as follows:
1. The algorithm iterates over statements that create pointers, one by one and in any order. It uses each statement to update the points-to graph if a statement creates new relationships on the graph.
2. Here are 6 types of statements and how they are used to update the points-to graph:
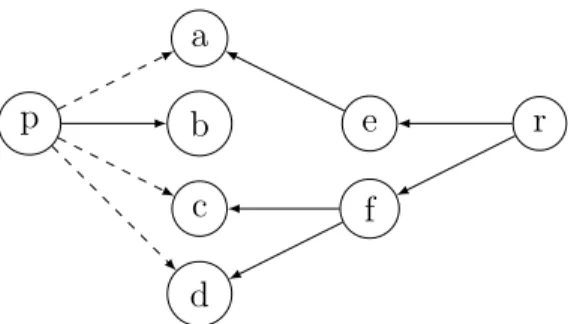
• p = &a: This statement adds an edge from p to a showing p can point to a. In this representation; dashed lines are new edges. (Figure 4.5).
p a
Figure 4.5: Points-to graph for p = &a.
• p = q: Edges from p to everything that q points to are added to the graph. If new edges are added later from q, we add edges from p to the same set of nodes as shown in Figure 4.6.
p
a b c
q
Figure 4.6: Points-to graph for p = q.
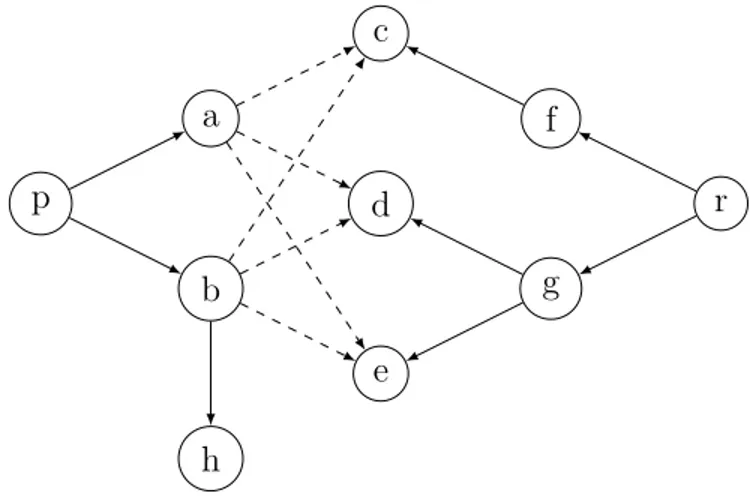
• p = *r: Let S be the set of nodes r points to. Let T be all the nodes members of S point to. Then, we add edges from p to all nodes in T. If new nodes are added to T or S later, new edges from p are also added (Figure 4.7).
p a b c d e f r
Figure 4.7: Points-to graph for p = *r.
• *p = &a: Let S be the set of nodes P points to. From all nodes of S, an edge to a is added. If a new edge from p is added, an edge to a is also added (Figure 4.8).
p
r
a q
Figure 4.8: Points-to graph for *p = &a.
• *p = q: Let S be the set of nodes p points to. Let T be the set of nodes q points to. Edges from all nodes of S to all nodes of T are added. If more nodes are added to T or S later, corresponding edges are added (Figure 4.9).
p
a
b c
d
q
Figure 4.9: Points-to graph for *p = q.
• *p = *r: Let S be the set of nodes r points to. Let T be the set of nodes which members of S point to. Let W be the set of nodes p points to. Edges from all members of W to all members of T are added. If new
nodes are added later to S, T, or W, new edges are added accordingly (Figure 4.10). p a b c d e f g r h
Figure 4.10: Points-to graph for *p = *r.
In addition to Andersen’s analysis, a faster technique called Steensgaard’s analysis has also been proposed [38]. However, it trades speed for precision. Speed of the analysis is not our concern because it does not have any impact on execution time of the benchmarks. Moreover, although worst case running time of Andersen’s method is O(n3) where n is the number of statements, Sridharan et al. [39] proved
that we can compute the analysis in quadratic time if the input program is k-sparse, namely, it has at most k statements dereferencing each variable and it has a sparse flow graph. This is usually the case for real-world applications.
4.4
Increasing Performance by Reducing
Net-work on Chip Traffic
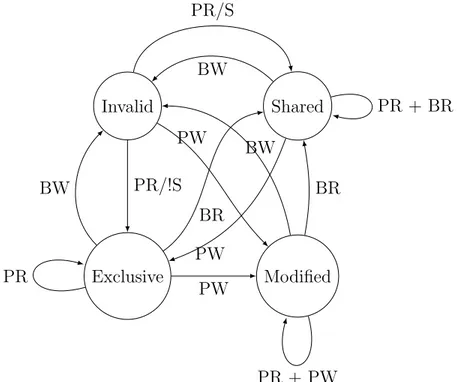
When only shared data is subject to cache coherency protocol, this eliminates unnecessary messages and reduces NoC traffic. Figure 4.11 shows the state tran-sition diagram in a MESI [40] directory based protocol. At any point of time, each cache line is in one of these four states:
• Invalid: Cache line is not present in cache.
• Exclusive: The content is in no other cache. It is exclusive to this cache and can be overwritten without consulting to other caches.
• Shared: Cache line is in this cache and other caches. All copies are identical to memory.
• Modified: Cache line is present only in this cache and memory copy is out of date. Exclusive Modified Invalid Shared PW BW BR PR PR/!S PR/S PW PR + BR BW PW BR PR + PW BW
Figure 4.11: MESI protocol state diagram, where PW = processor write, PR = processor read BW = observed bus write, BR = observed bus read
S = shared, !S = not shared.
In our proposed method, shared data uses the non-modified directory protocol (MESI). However, load and store operations executing on private data do not produce coherency messages. None of the messages in the state diagram in Figure
4.11 is applicable to private data. Below examples show where private and shared data can be handled differently:
• CPU tries to read a0 which is shared but it is not there. Then, it sends
coherency messages to other cores to check if a0 is in another cache.
• CPU tries to read a1 which is private but it is not there. It does not send
messages to other cores because it is certain that a1 is not there either.
• CPU writes a2 which is shared. Then, it sends messages to other cores to
invalidate their copies.
• CPU writes a3 which is private. It does not send invalidation messages to
other cores because they do not have copies of a3.
These read and write examples show two cases where private data do not send coherency messages and shared data do. Our approach reduces traffic by saving from these and other kinds of messages. Moreover, our proposed system does not require any extra hardware. Note that, we use L1 cache for both private and shared data.
Chapter 5
Experiments
5.1
Setup
We experimented on Ubuntu 16.04 with AMD A10-5750M CPU and 16GB us-ing Sniper Multi-Core Simulator to test our approach. Carlson et al. proposed Sniper as a x86 simulator for parallel programs which is based on the interval core model [1]. Interval simulation is a simulation approach for multi-core systems. This method uses a mechanistic analytical model to simulate core performance by running the timing simulation of each core without tracking individual instruc-tions through pipeline stages, hence allowing fast simulation.
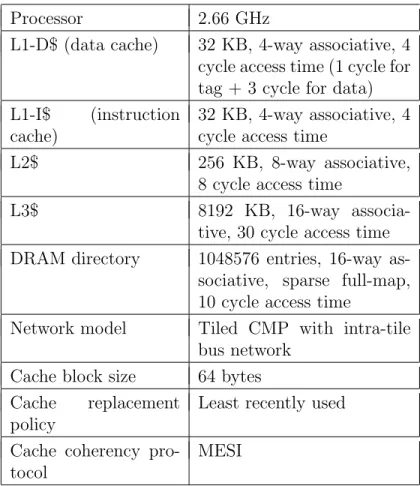
System configurations used in the simulator are a modified version of Intel’s Xeon X5550 Gainestown [41]. Details of our experimental setup is shown in Table 5.1. In this setup, each core has a private L1 and L2 cache. There is a shared L3 cache for every 4 cores in 8-core and 4-core simulations. In 4-core simulations, L3 caches are also private. Our system has an inclusive cache model, where lower level caches store all data found in the higher level caches. We tested our approach on SPLASH-2 and PARSEC 2.1 benchmarks with the number of threads being equal to the number of cores in the simulations. Table 5.2 shows the input files used in our simulations. Note that, tables in this section only take the parallel
Table 5.1: Simulated hardware configurations. Processor 2.66 GHz
L1-D$ (data cache) 32 KB, 4-way associative, 4 cycle access time (1 cycle for tag + 3 cycle for data) L1-I$ (instruction
cache)
32 KB, 4-way associative, 4 cycle access time
L2$ 256 KB, 8-way associative, 8 cycle access time
L3$ 8192 KB, 16-way associa-tive, 30 cycle access time DRAM directory 1048576 entries, 16-way
as-sociative, sparse full-map, 10 cycle access time
Network model Tiled CMP with intra-tile bus network
Cache block size 64 bytes Cache replacement
policy
Least recently used
Cache coherency pro-tocol
MESI
region of the program (region of interest) into account.
In order to have a fair comparison, we first ran the benchmarks without having them analyzed with Andersen’s analysis. Then, we ran the benchmarks again after applying the proposed technique. Our results given in the rest of this chapter use non-analyzed benchmark runs as the baseline.
5.2
Pointer Analysis Results
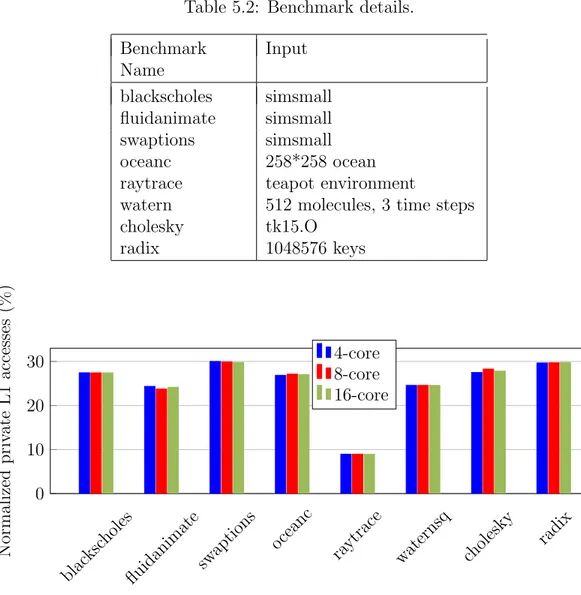
Results of the pointer analysis is shown in Figure 5.1. Specifically, we give the ratio of number of private data accesses to total data accesses. Benchmarks have 20-30% private data except raytrace which has 9%. In raytrace benchmark,
Table 5.2: Benchmark details. Benchmark Name Input blackscholes simsmall fluidanimate simsmall swaptions simsmall oceanc 258*258 ocean raytrace teapot environment
watern 512 molecules, 3 time steps cholesky tk15.O radix 1048576 keys blac ksc holes fluidanimatesw
aptions oceanc raytrace waternsq cholesky radix 0 10 20 30 Normalized priv ate L1 accesses (%) 4-core 8-core 16-core
Figure 5.1: Normalized private L1 accesses (%).
threads access shared objects concurrently using semaphores. Therefore, our analysis considers those data blocks as shared. Although the total number of L1 cache accesses increase with the number of cores, since some benchmarks generate a larger input when executed with more threads, private data to total data access ratio did not change more than 1%.
blac kscholes
fluidanimatesw
aptions oceanc raytrace waternsq cholesky radix 0 2 4 6 8 Normalized cycle time reduction (%) 4-core 8-core 16-core
Figure 5.2: Normalized cycle time reduction (%).
5.3
Performance and Traffic
5.3.1
Cycle Time
We observed in our simulations that this approach can reduce cycle time up to 9% as can be seen in Figure 5.2. Reduction in coherency traffic resulted in cycle time reduction as expected. Furthermore, Figure 5.6 shows normalized load reduction from DRAM. Results in Figure 5.2 are similar to Figure 5.6 since DRAM access causes more latency than coherency traffic. The gains increased with the number of cores because as we increase the number of cores, the probability of sharing increases. On the contrary, as we reduce the number of cores, it becomes similar to a single core system where this approach would not benefit. The same reason also affects loads from DRAM and loads from remote L2 caches. Therefore, the last two figures (Figure 5.5 and Figure 5.6) show similar results to Figure 5.2. Loads from other cores’ L2 caches and loads from DRAM decrease more as the number of cores increases. Our approach increase efficiency of caches by preventing frequently used data getting evicted, thereby locating the data in cache and the need to fetch data from DRAM is reduced.
blac kscholes
fluidanimatesw
aptions oceanc raytrace waternsq cholesky radix 0 5 10 Normalized n um b er of pac k ets reduced (%) 4-core 8-core 16-core
Figure 5.3: Normalized number of packets reduced over on-chip network (%).
5.3.2
Coherency Traffic
There are two types of packets transferred on our CMP network. One with data (named as with-data) and one without data (named as no-data). With-data pack-ets are assumed as 73 bytes and no-data packpack-ets are assumed as 9 bytes since cache block size is 64 bytes in 64-bit systems. Figure 5.3 and 5.4 show the reduc-tion in coherency message packets over the on chip network. From these results, we conclude that with-data and no-data packet reduction is usually proportional except a few cases. The outliers are swaptions on 4-core and cholesky on 16-core where no-data packet reduction is more than with-data packet reduction. We can also see that our gains do not increase proportionally with the number of cores. 16-core runs give highest gains, then comes 4-core, and the least gain is with 8-cores. Note that, there are 4 tiles in 16 and 4-core runs but 2 tiles in 8-core simulations. Therefore, we can deduct that number of tiles is more important in decreasing packet traffic than the number of cores. Since directory protocol is between tiles, packet traffic is only between tiles, not between cores within the same tile.
blac kscholes
fluidanimatesw
aptions oceanc raytrace waternsq cholesky radix 0 5 10 Normalized total tr affic v olum e reduced (%) 4-core 8-core 16-core
Figure 5.4: Normalized total traffic volume reduced over on-chip network (%).
blac kscholes
fluidanimatesw
aptions oceanc raytrace waternsq cholesky radix 0 5 10 Normalized load re duction from remote tiles (%) 4-core 8-core 16-core
blac ksc
holes
fluidanimatesw
aptions oceanc raytrace waternsq cholesky radix 0 2 4 6 Normalized load re duction from DRAM (%) 4-core 8-core 16-core
Chapter 6
Conclusion
In this thesis, we presented a compiler-based approach to improve execution time and coherency traffic of parallel programs. First, thread-private data are marked using Andersen’s pointer analysis using LLVM at compile time. Private data is allowed to bypass coherency protocol during runtime, thereby eliminating co-herency messages, whereas shared data is handled with standard MESI protocol. Second, we investigate effects of our approach on performance and network-on-chip traffic.
Our pointer analysis detected that 20-30% of all data accesses are to private data in most of the benchmarks. To be considered private, analysis requires each object to be allocated in a different location. Therefore, programs that do not use global variables have a higher chance to benefit from our approach.
Experimental results show that our approach reduces cycle time up to 10%, loads from memory up to 6%, loads from remote tiles up to 13%. We can also observe that loads from memory causes more latency than coherency traffic so it has the highest impact on cycle time. Moreover, reduction in these values are proportional to the number of cores. We can argue that performance gains will increase to a certain point if this approach is used with systems that have more than 16 cores because the probability of sharing increases. However, we used full
mesh topology in our experiments which does not scale well with the number of cores since each additional tile increases the number of links exponentially. Therefore, it is unlikely to have a full mesh topology being used in very large systems. On the other hand, our approach does not require mesh topology and should work with other topologies as well.
Number of packets and total traffic volume over on-chip network both reduced up to 12%. Moreover, results show that tile size is more effective than number of cores in reducing coherency traffic. Although our gains increase with the number of cores, our approach focuses on reducing traffic among tiles since directory protocol works only between tiles and not between cores in the same tile.
This study can be extended by adding a different analysis and optimizations as future work. In addition, our study can be implemented in conjunction with studies which are proposed by Marty and Ros [26,27] since our approach is orthog-onal to theirs. Our approach can be easily combined with other studies as well because it requires no extra hardware or changes in existing coherency protocols.
Chapter 7
Bibliography
[1] T. E. Carlson, W. Heirman, S. Eyerman, I. Hur, and L. Eeckhout, “An evaluation of high-level mechanistic core models,” ACM Trans. Archit. Code Optim., vol. 11, pp. 28:1–28:25, Aug. 2014.
[2] D. Alpert and D. Avnon, “Architecture of the pentium microprocessor,” IEEE Micro, vol. 13, pp. 11–21, June 1993.
[3] D. M. Tullsen, S. J. Eggers, and H. M. Levy, “Simultaneous multithreading: Maximizing on-chip parallelism,” in Proceedings 22nd Annual International Symposium on Computer Architecture, pp. 392–403, June 1995.
[4] M. Gulati and N. Bagherzadeh, “Performance study of a multithreaded superscalar microprocessor,” in Proceedings of the 2Nd IEEE Symposium on High-Performance Computer Architecture, HPCA ’96, (Washington, DC, USA), pp. 291–, IEEE Computer Society, 1996.
[5] J. L. Lo, J. S. Emer, H. M. Levy, R. L. Stamm, D. M. Tullsen, and S. J. Eg-gers, “Converting thread-level parallelism to instruction-level parallelism via simultaneous multithreading,” ACM Trans. Comput. Syst., vol. 15, pp. 322– 354, Aug. 1997.
[6] T. Mudge, “Power: a first-class architectural design constraint,” Computer, vol. 34, pp. 52–58, Apr 2001.
[7] V. Agarwal, M. S. Hrishikesh, S. W. Keckler, and D. Burger, “Clock rate versus ipc: The end of the road for conventional microarchitectures,” in Proceedings of the 27th Annual International Symposium on Computer Ar-chitecture, ISCA ’00, (New York, NY, USA), pp. 248–259, ACM, 2000.
[8] L. A. Barroso, K. Gharachorloo, R. McNamara, A. Nowatzyk, S. Qadeer, B. Sano, S. Smith, R. Stets, and B. Verghese, “Piranha: a scalable archi-tecture based on single-chip multiprocessing,” in Proceedings of 27th Inter-national Symposium on Computer Architecture (IEEE Cat. No.RS00201), pp. 282–293, June 2000.
[9] P. Kongetira, K. Aingaran, and K. Olukotun, “Niagara: a 32-way multi-threaded sparc processor,” IEEE Micro, vol. 25, pp. 21–29, March 2005.
[10] J. A. Kahle, M. N. Day, H. P. Hofstee, C. R. Johns, T. R. Maeurer, and D. Shippy, “Introduction to the cell multiprocessor,” IBM Journal of Re-search and Development, vol. 49, pp. 589–604, July 2005.
[11] “Intel core i7 processor.” http://www.intel.com/products/processor/ corei7ee/. Accessed: 2017-09-20.
[12] H. Q. Le, W. J. Starke, J. S. Fields, F. P. O’Connell, D. Q. Nguyen, B. J. Ronchetti, W. M. Sauer, E. M. Schwarz, and M. T. Vaden, “Ibm power6 microarchitecture,” IBM J. Res. Dev., vol. 51, pp. 639–662, Nov. 2007.
[13] “Amd magny-course.” http://developer.amd.com/documentation/ articles/pages/magny-cours-direct-connect-architecture-2.0. aspx. Accessed: 2013-01-15.
[14] J. Chang and G. S. Sohi, “Cooperative caching for chip multiprocessors,” in Proceedings of the 33rd Annual International Symposium on Computer Ar-chitecture, ISCA ’06, (Washington, DC, USA), pp. 264–276, IEEE Computer Society, 2006.
[15] P. Mak, C. R. Walters, and G. E. Strait, “Ibm system z10 processor cache subsystem microarchitecture,” IBM J. Res. Dev., vol. 53, pp. 13–24, Jan. 2009.
[16] A. Moshovos, “Regionscout: exploiting coarse grain sharing in snoop-based coherence,” in 32nd International Symposium on Computer Architecture (ISCA’05), pp. 234–245, June 2005.
[17] V. Salapura, M. Blumrich, and A. Gara, “Design and implementation of the blue gene/p snoop filter,” in 2008 IEEE 14th International Symposium on High Performance Computer Architecture, pp. 5–14, Feb 2008.
[18] “Tilera tilepro64.” http://www.tilera.com/products/processors/ TILEPro_Family. Accessed: 2013-01-15.
[19] P. Lotfi-Kamran, M. Ferdman, D. Crisan, and B. Faisafi, “Turbotag: Lookup filtering to reduce coherence directory power,” in 2010 ACM/IEEE Interna-tional Symposium on Low-Power Electronics and Design (ISLPED), pp. 377– 382, Aug 2010.
[20] M. Ferdman, P. Lotfi-Kamran, K. Balet, and B. Falsafi, “Cuckoo directory: A scalable directory for many-core systems,” in 2011 IEEE 17th Interna-tional Symposium on High Performance Computer Architecture, pp. 169–180, Feb 2011.
[21] J. H. Kelm, M. R. Johnson, S. S. Lumetta, and S. J. Patel, “Waypoint: Scaling coherence to 1000-core architectures,” in 2010 19th International Conference on Parallel Architectures and Compilation Techniques (PACT), pp. 99–109, Sept 2010.
[22] H. Zhao, A. Shriraman, S. Dwarkadas, and V. Srinivasan, “Spatl: Honey, i shrunk the coherence directory,” in 2011 International Conference on Par-allel Architectures and Compilation Techniques, pp. 33–44, Oct 2011.
[23] J. Zebchuk, V. Srinivasan, M. K. Qureshi, and A. Moshovos, “A tagless coherence directory,” in Proceedings of the 42Nd Annual IEEE/ACM In-ternational Symposium on Microarchitecture, MICRO 42, (New York, NY, USA), pp. 423–434, ACM, 2009.
[24] H. Zhao, A. Shriraman, and S. Dwarkadas, “Space: Sharing pattern-based directory coherence for multicore scalability,” in Proceedings of the 19th
International Conference on Parallel Architectures and Compilation Tech-niques, PACT ’10, (New York, NY, USA), pp. 135–146, ACM, 2010.
[25] D. Sanchez and C. Kozyrakis, “Scd: A scalable coherence directory with flexible sharer set encoding,” in Proceedings of the 2012 IEEE 18th Interna-tional Symposium on High-Performance Computer Architecture, HPCA ’12, (Washington, DC, USA), pp. 1–12, IEEE Computer Society, 2012.
[26] M. R. Marty, J. D. Bingham, M. D. Hill, A. J. Hu, M. M. K. Martin, and D. A. Wood, “Improving multiple-cmp systems using token coherence,” in Proceedings of the 11th International Symposium on High-Performance Computer Architecture, HPCA ’05, (Washington, DC, USA), pp. 328–339, IEEE Computer Society, 2005.
[27] A. Ros, M. E. Acacio, and J. M. Garcia, “A direct coherence protocol for many-core chip multiprocessors,” IEEE Transactions on Parallel and Dis-tributed Systems, vol. 21, pp. 1779–1792, Dec 2010.
[28] C. Kim, D. Burger, and S. W. Keckler, “Nonuniform cache architectures for wire-delay dominated on-chip caches,” IEEE Micro, vol. 23, pp. 99–107, Nov 2003.
[29] C. Kim, D. Burger, and S. W. Keckler, “An adaptive, non-uniform cache structure for wire-delay dominated on-chip caches,” in Proceedings of the 10th International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS X, (New York, NY, USA), pp. 211–222, ACM, 2002.
[30] B. M. Beckmann and D. A. Wood, “Managing wire delay in large chip-multiprocessor caches,” in Proceedings of the 37th Annual IEEE/ACM In-ternational Symposium on Microarchitecture, MICRO 37, (Washington, DC, USA), pp. 319–330, IEEE Computer Society, 2004.
[31] M. Zhang and K. Asanovic, “Victim replication: Maximizing capacity while hiding wire delay in tiled chip multiprocessors,” in Proceedings of the 32Nd Annual International Symposium on Computer Architecture, ISCA ’05, (Washington, DC, USA), pp. 336–345, IEEE Computer Society, 2005.
[32] N. Hardavellas, M. Ferdman, B. Falsafi, and A. Ailamaki, “Reactive nuca: Near-optimal block placement and replication in distributed caches,” in Pro-ceedings of the 36th Annual International Symposium on Computer Archi-tecture, ISCA ’09, (New York, NY, USA), pp. 184–195, ACM, 2009.
[33] J. Ahn, D. Kim, J. Kim, and J. Huh, “Subspace snooping: Exploiting tem-poral sharing stability for snoop reduction,” IEEE Trans. Comput., vol. 61, pp. 1624–1637, Nov. 2012.
[34] B. Cuesta, A. Ros, M. E. Gmez, A. Robles, and J. Duato, “Increasing the effectiveness of directory caches by deactivating coherence for private mem-ory blocks,” in 2011 38th Annual International Symposium on Computer Architecture (ISCA), pp. 93–103, June 2011.
[35] P. Conway, N. Kalyanasundharam, G. Donley, K. Lepak, and B. Hughes, “Cache hierarchy and memory subsystem of the amd opteron processor,” IEEE Micro, vol. 30, pp. 16–29, March 2010.
[36] L. O. Andersen, “Program analysis and specialization for the c programming language,” tech. rep., 1994.
[37] C. Lattner and V. Adve, “Llvm: A compilation framework for lifelong pro-gram analysis & transformation,” in Proceedings of the International Sympo-sium on Code Generation and Optimization: Feedback-directed and Runtime Optimization, CGO ’04, (Washington, DC, USA), pp. 75–, IEEE Computer Society, 2004.
[38] B. Steensgaard, “Points-to analysis in almost linear time,” in Proceedings of the 23rd ACM SIGPLAN-SIGACT Symposium on Principles of Program-ming Languages, POPL ’96, (New York, NY, USA), pp. 32–41, ACM, 1996.
[39] M. Sridharan and S. J. Fink, “The complexity of andersen’s analysis in prac-tice,” in Proceedings of the 16th International Symposium on Static Analysis, SAS ’09, (Berlin, Heidelberg), pp. 205–221, Springer-Verlag, 2009.
[40] M. S. Papamarcos and J. H. Patel, “A low-overhead coherence solution for multiprocessors with private cache memories,” in Proceedings of the 11th
Annual International Symposium on Computer Architecture, ISCA ’84, (New York, NY, USA), pp. 348–354, ACM, 1984.
[41] “Intel xeon processor x5550 (8m cache, 2.66 ghz, 6.40 gt/s intel qpi) product specifications.” http://ark.intel.com/products/37106. Accessed: 2017-09-19.