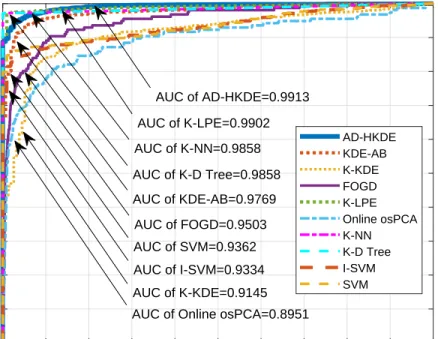
Online anomaly detection with kernel density estimators
Tam metin
Şekil
![Figure 2.1: In this example, a depth-2 binary tree partitions the observation space S = [−A, A] × [−A, A]](https://thumb-eu.123doks.com/thumbv2/9libnet/5925749.123108/20.918.196.761.381.949/figure-example-depth-binary-tree-partitions-observation-space.webp)
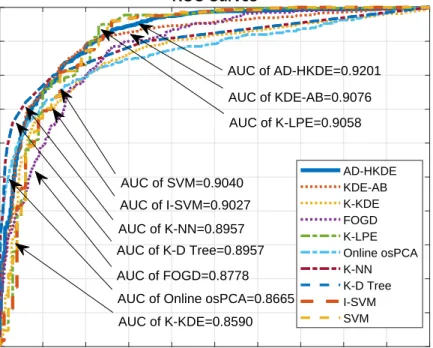

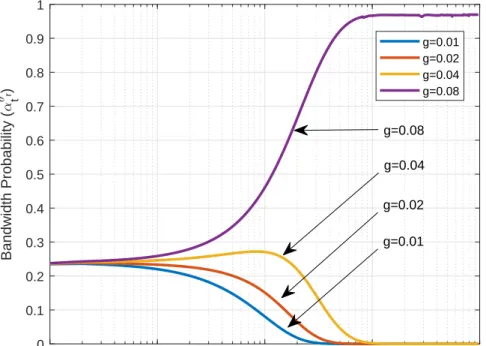
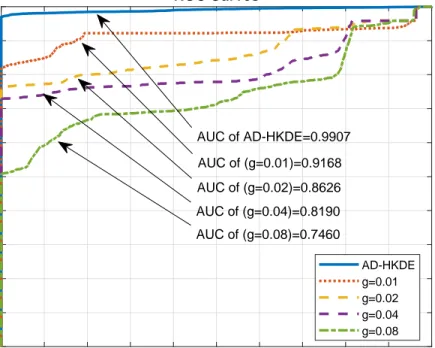
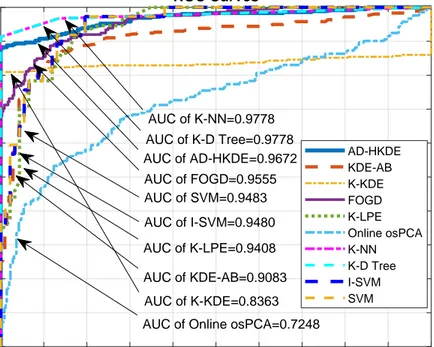

Benzer Belgeler
Abstract The purpose of this note is to give a probability bound on symmetric matrices to improve an error bound in the Approximate S-Lemma used in establishing levels of
The basic idea of our method is that the detector reading is maximum at some positions and the corresponding positional values of the sensors can be used for range estimation
Table 1 lists the number of iterations for 10 −6 residual error, solution time in seconds (s), and memory in megabytes (MB) per processor, when GMRES is used to solve the original
In this part of the study, the values of performance and permeability of PGAs have been obtained by taking stable migration interval 80 with increasing and
You are one o f the participants who has been selected randomly to complete this questionnaire. The aim o f this study is not to evaluate writing instructors, English
Batının şövalye sistemine göre kurgulanmış olan bu aşk modeli, evli bir kadınla yaşanması bakımından mesnevideki şehzade ve padi şah kızı arasında vuslatla
We are proposing a different modelling perspective for the post-disaster assess- ment problem by considering assessment of population points and road segments through
Gebeliğin sezaryan yolu ile erken dünyaya getirilmesi ve sonrasında nöroşirürjikal müdahalenin gerçekleştirilmesi anne adayının sağlığı ve tedavi ekibinin
