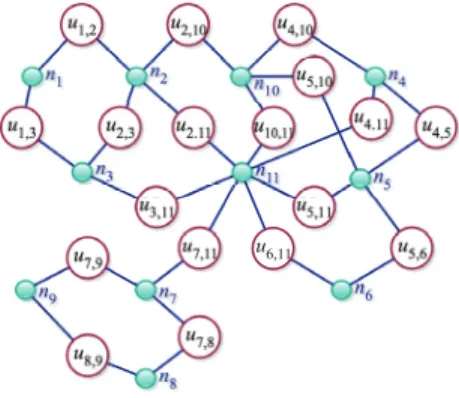
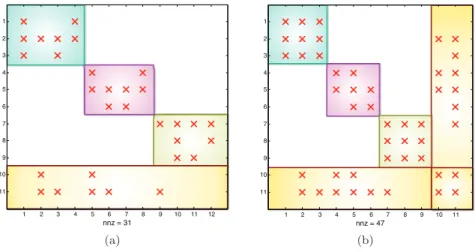
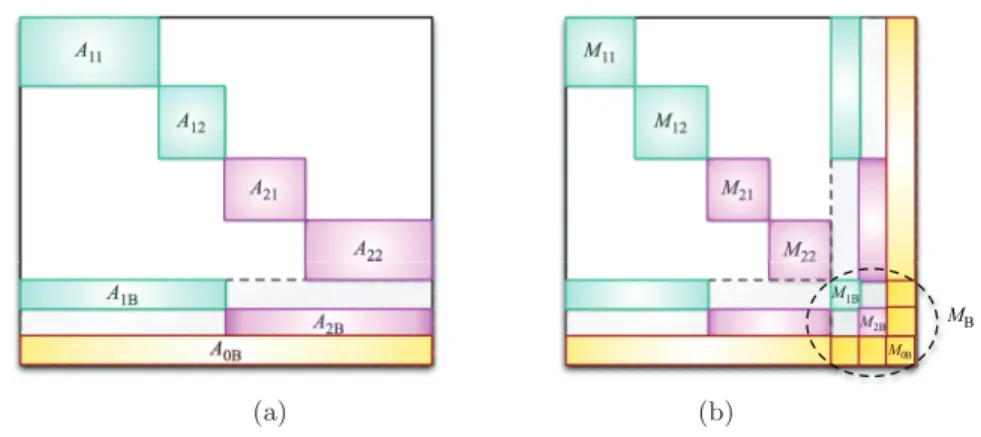
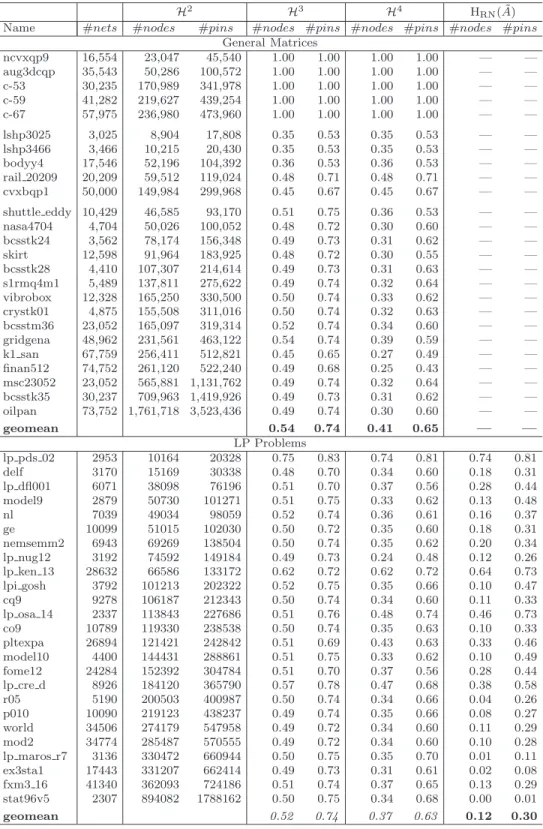
Hypergraph partitioning-based fill-reducing ordering for symmetric matrices
Tam metin
Şekil


Benzer Belgeler
It has been demonstrated that although significant amount of mutual coupling reduction has been achieved by using the dumbbell DGS, the reflector and the cavity, no improvement has
Bennett’s emphasis on the transformative potential of algorithmic methods in relation to discourse analysis and computer-assisted content analysis omits a discussion of the ways
We study the Coulomb drag rate for electrons in a double-quantum-well structure taking into account the electron-optical phonon interactions. The full wave vector and
As the size of the SPP cavity decreases, the width of the new plasmonic waveguide band increases owing to the formation of CROW type plasmonic waveguide band within the band gap
Surface enhanced Raman spectroscopy (SERS) is one of the important applications of these of plasmonic surfaces since multiple resonances exhibited by these
The generalized anisotropic Eliashberg theory is employed to study the critical temperature of layered nonadiabatic superconductors where the relevant phonon energy is comparable to
For example, Borensztein, Zettelmeyer and Philippon (2001) examined how US monetary policy shocks affected the interest rates of various countries (including
This study examined the in fluence of immersive and non-immersive VDEs on design process creativ- ity in basic design studios, through observing factors related to creativity as
