Heuristics for scheduling file-sharing tasks on heterogeneous systems with distributed repositories
Tam metin
Şekil
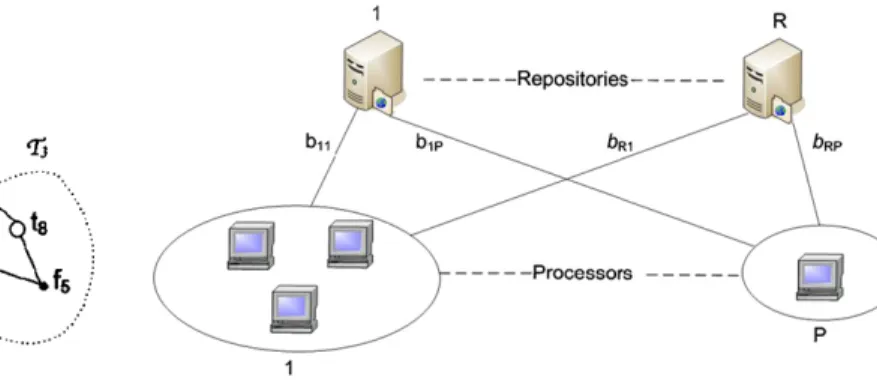
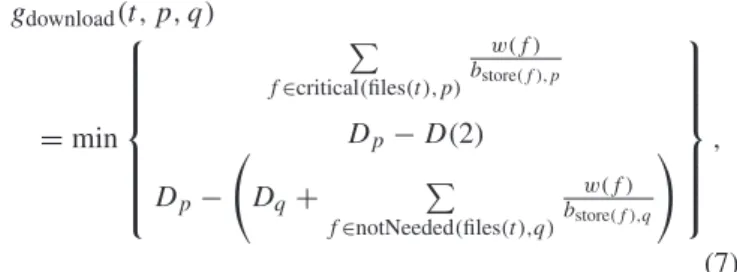
![Fig. 6. The piecewise linear function to estimate task execution times on a processor p [26].](https://thumb-eu.123doks.com/thumbv2/9libnet/5777260.117227/10.892.100.378.113.340/fig-piecewise-linear-function-estimate-execution-times-processor.webp)
Benzer Belgeler
Training and development are one of the most essential part of human resources management and people. Training refers to a planned effort by a company to facilitate employees'
Katılımcıların bedenlerinin herhangi bir yerinde uyuşma veya karıncalanmanın gün içerisin de el yıkama sıklığı değişkenine göre incelendiğinde gün içerisinde
Sonuç olarak, homojen olmayan da ılmı parametreli ortamlarda dalgaların kontrol probleminin çözümü Hilbert uzayındaki moment probleminin çözümüne getirildi.. Anahtar
Bu nedenle, ülke içinde tüm illerin turizm sektörü için önemli olan turistik alanları belirlenmesi ve belirlenen önem derecesine göre turizme yön
We described a new image content representation using spa- tial relationship histograms that were computed by counting the number of times different groups of regions were observed
Öğretim elemanı ile ilişkiler alt boyutunda, öğrencilerin üniversite yaşam kalitesi düzeyleri incelendiğinde, Mühendislik Fakültesi ile Fen-Edebiyat, İşletme,
contribute to the formation of value constructs in the personality structure of a student and the familiarization of students with the global values of humanity
Önerdiğimiz bu çevirinin kullanılması; kaynakların desteklediği ve dilin imkân verdiği bir çeviri olmasının yanı sıra Safiyye annemizden uğursuzluk töhmetini
