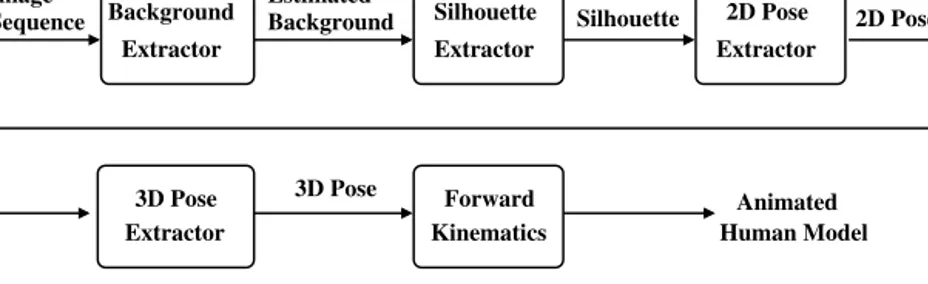
Motion capture and human pose reconstruction from a single-view video sequence
Tam metin
Şekil



Benzer Belgeler
Beyin kabuğu (serebral korteks) ... Somatosensoriyel korteks ve plastisite ilişkisi ... Hipokampus ve plastisite ilişkisi ... Beyin Plastisitesi ... EEG dalga şekilleri ...
model controller performance when the uncertainty introduced to the plant dynamics are 1) 20% delay uncertainty and 2) 10% wall-wetting time constant uncertainty, (b)
We envision to solve this through a heavily assisted, semi-automated process: First we will use text mining agents to automatically create a draft visual diagram
From the micrographs of the 3T3 cells seeded on the foams, it was seen that the cells were distributed quite uniformly in the foam around the initial seeding site. However, the
The standard deviation of the wavelet coefficients in a subband is estimated from the data and the threshold value for each subband is selected as 2.5 σ to determine
This stAidy is concerned with the identification and the analysis of errors in tense (ET) in the written English of Turkish students and the implications of
To determine how accurately the civic education textbooks reflect the status of women and men in Turkey a content analysis was conducted on civic education textbooks throughout the
Figure 5b shows the average NRET rate for a CdTe D −A pair as a function of the distance, when the donor is an NW and the acceptor is a QW.. In this computation, we made
