ORTAÖĞRETİM ÖĞRENCİLERİNİN FİZİKSEL UYGUNLUK
KARNESİ ÖLÇÜMLERİNİN VERİ MADENCİLİĞİ İLE
SINIFLANDIRILMASI
Hande Buşra Eren
YÜKSEK LİSANS TEZİ
BEDEN EĞİTİMİ VE SPOR ÖĞRETMENLİĞİ ANA BİLİM DALI
GAZİ ÜNİVERSİTESİ
EĞİTİM BİLİMLERİ ENSTİTÜSÜ
i
TELİF HAKKI VE TEZ FOTOKOPİ İZİN FORMU
Bu tezin tüm hakları saklıdır. Kaynak göstermek koşuluyla tezin teslim tarihinden itibaren 3(üç) ay sonra tezden fotokopi çekilebilir.
YAZARIN
Adı : Hande Buşra Soyadı : EREN
Bölümü: Beden Eğitimi ve Spor Öğretmenliği Anabilim Dalı İmza :
Teslim Tarihi: 14.09.2018
TEZİN
Türkçe Adı: Ortaöğretim Öğrencilerinin Fiziksel Uygunluk Karnesi Ölçümlerinin Veri Madenciliği İle Sınıflandırılması
İngilizce Adı: Classifying Of High School Students' Physical Appropriateness Report Measurement With Data Mining
ii
ETİK İLKELERE UYGUNLUK BEYANI
Tez yazma sürecinde bilimsel ve etik ilkelere uyduğumu, yararlandığım tüm kaynakları kaynak gösterme ilkelerine uygun olarak kaynakçada belirttiğimi ve bu bölümler dışındaki tüm ifadelerin şahsıma ait olduğunu beyan ederim.
Yazar Adı Soyadı: Hande Buşra EREN İmza :
iii
JURİ ONAY SAYFASI
Hande Buşra Eren tarafından hazırlanan “Ortaöğretim Öğrencilerinin Fiziksel Uygunluk Karnesi Ölçümlerinin Veri Madenciliği İle Sınıflandırılması” adlı tez çalışması aşağıdaki jüri tarafından oy çokluğu ile Gazi Üniversitesi Beden Eğitimi ve Spor Öğretmenliği Anabilim Dalı’ nda Yüksek Lisans tezi olarak kabul edilmiştir.
Danışman: Doç. Dr. Gökhan ÇALIŞKAN
Beden Eğitimi ve Spor Öğretmenliği Anabilim Dalı, Gazi Üniversitesi ………
Üye: Prof. Dr. Yaprak Arzu ÖZDEMİR
İstatistik Anabilim Dalı, Gazi Üniversitesi ………
Üye: Prof. Dr. Murat ATAN
Yöneylem Anabilim Dalı , Hacı Bayram Veli Üniversitesi ………
Üye: Prof. Dr. Muhsin HAZAR
Beden Eğitimi ve Spor Öğretmenliği Anabilim Dalı, Gazi Üniversitesi ………
Üye: Doç. Dr. Sibel ATAN
Yöneylem Anabilim Dalı , Hacı Bayram Veli Üniversitesi ……… Tez Savunma Tarihi: 14/09/2018
Bu tezin Beden Eğitimi ve Spor Öğretmenli Anabilim Dalı’ nda Yüksek Lisans tezi olması için şartları yerine getirdiğini onaylıyorum.
Prof. Dr. Selma YEL
iv
TEŞEKKÜR
Öncelikle şükrün sahibine sonsuz teşekkür ederim.
Çalışmamın her aşamasında benden yardımlarını esirgemeyen, danışmanım olarak beni onurlandıran, derin bilgi ve birikimini benimle paylaşarak farklı bir bakış açısı kazandıran Doç. Dr. Gökhan ÇALIŞKAN’ a,
Bilgi ve tecrübesiyle çalışmama büyük katkısı olan sayın Prof. Dr. Kazım ÖZDAMAR’ a şükranlarımı sunarım.
Varlıkları ile hayatımın her aşamasında sıcaklıklarını ve sevgilerini yanımda hissettiğim annem Asiye EREN, babam Ersin EREN ve kardeşim Buğra Han EREN’ e gönülden teşekkür ederim.
Desteği ile her zaman yanımda olan kıymetli dostum Zeynep’e sonsuz teşekkürü bir borç bilirim. İyi ki varsınız.
v
ORTAÖĞRETİM ÖĞRENCİLERİNİN FİZİKSEL UYGUNLUK
KARNESİ ÖLÇÜMLERİNİN VERİ MADENCİLİĞİ İLE
SINIFLANDIRILMASI
(Yüksek Lisans Tezi)
Hande Buşra EREN
GAZİ ÜNİVERSİTESİ
EĞİTİM BİLİMLERİ ENSTİTÜSÜ
EYLÜL 2018
ÖZ
Bu araştırmada, “fiziksel uygunluk karnesi” ölçümleri kullanılarak elde edilen bilgilerle öğrencilerin, obezite kategorilerinin sınıflandırılmasında yapay sinir ağları ve lojistik regresyon yöntemlerinin doğru sınıflandırma performanslarının karşılaştırması amaçlanmıştır. İlişkisel tarama modelinde olan araştırmanın çalışma grubunu 2016-2017 eğitim öğretim yılında Konya ili Cihanbeyli ilçesinde öğrenim gören 1050 ortaöğretim öğrencisi oluşturmaktadır. Fiziksel Uygunluk Karnesi sonuçlarında Beden Kitle İndeksi Z-Skoru sonuçlarına göre referans aralıkları belirlenerek Sağlık Bakanlığı Beden Kitle İndeksi sınıflandırması yapılmıştır. Çalışmada Sağlık Bakanlığı sınıflandırmasının yanı sıra Dünya Sağlık Örgütü sınıflandırmasını da dahil ederek iki kuruluşun sınıflandırma performansları karşılaştırılmıştır. Ayrıca fiziksel uygunluk karnesi ölçümlerinde alınan parametrelerin önemlilik derecelerini belirlenerek, hangi parametrelerin sonuçlara ulaşmada daha etkili olduğu saptanmıştır. Veriler SPSS 23 paket programı ile analiz edilmiştir. Araştırma sonucunda lojistik regresyon analizi doğru sınıflandırma oranı yüzde 72,8, yapay sinir ağları analizi doğru sınıflandırma oranı yüzde 90,6 olarak bulunmuştur. Buna göre fiziksel uygunluk karnesi ölçümlerinin obezite sınıflandırmasında yapay sinir ağlarının lojistik regresyon analizine göre daha başarılı sonuçlar verdiği görülmektedir. Ayrıca obezite sınıflandırmasına etki eden bağımsız değişkenler ise kilo, boy, mekik ve şınav olarak belirlenmiştir.
vi
Anahtar Kelimeler : Veri Madenciliği, Yapay Sinir Ağları, Lojistik Regresyon Analizi, Fiziksel Uygunluk Karnesi
Sayfa Adedi :110
vii
CLASSIFYING OF HIGH SCHOOL STUDENTS’ PHYSICAL
APPROPRIATENESS REPORT MEASUREMENT WITH DATA
MINING
(Ph. D Thesis)
Hande Buşra EREN
GAZI UNIVERSİTY
GRADUATE SCHOOL OF EDUCATIONAL SCIENCES
SEPTEMBER 2018
ABSTRACT
ln this research it is aimed comparing the data gained using "physical appropriateness report" measurements and artificial neural networks and logistic regression analysis methods' right classifying performance upon classifying of students' obesity categories. ln associational scanning model 1050 high school students studying in Cihanbeyli, Konya in 2016-2017 academic year consist of the working group of the research. Ministry of Health body mass index is classified determining the referance ranges according to the results of body mass index z score in physical appropriateness report results. ln this research it is compared classifying performances of Ministry of Health and World Health Organisation. Therefore it is set which parameters are more important for getting results determining the importance grades of parameters got through physical appropriateness report measurements. Data was analysed with SPSS 23 packaged software. Following the research results the right classifying rates were found as 72,8 percent for logistic regression analysis and as 90,6 percent for artificial neural networks. Accordingly it is seen that in physical appropriateness report measurements' obesity classification artificial neural networks shows more succesful results than logistic regression analysis. Moreover distinct variables affecting obesity classification are determined as weight, height, sit-up and push-up.
viii
Key Words :Data Mining, Neural Network , Logistic Regression Analysis, Assessment of The Physical Fitness
Page Number :110
ix
İÇİNDEKİLER
ÖZ ... v
ABSTRACT ... vii
İÇİNDEKİLER ... ix
TABLOLAR LİSTESİ ... xii
ŞEKİLLER LİSTESİ ... xiv
SİMGELER VE KISALTMALAR LİSTESİ ... xvi
BÖLÜM I ... 1
GİRİŞ ... 1
1.1.Araştırmanın Amacı ... 4 1.2.Araştırmanın Önemi ... 4 1.3.Sınırlılıklar ... 5 1.4.Tanımlar ... 5BÖLÜM II ... 7
KAVRAMSAL ÇERÇEVE ... 7
2.1.Fiziksel Uygunluk ... 72.1.1.Fiziksel Uygunluk Eğitimi... 7
2.1.2.Fiziksel Uygunluk Karnesi ... 8
2.2. Veri Madenciliği ... 8
2.2.1. Veri Madenciliği Kavramı ... 8
x
2.2.3.Veri Madenciliği Süreci ... 14
2.2.4. Veri Madenciliği Modelleri ... 21
2.3.Yapay Sinir Ağları ... 24
2.3.1.Yapay Sinir Ağlarının Yapısı ... 25
2.3.2.Yapay sinir Ağlarının Sınıflandırılması ... 26
2.3.3.Yapay Sinir Ağlarında Öğrenme ... 27
2.3.4.Yapay Sinir Ağı Tasarımı ... 31
2.3.5.Çok Katmanlı Algılayıcılar (ÇKA) ... 34
2.3.6.Radyal Tabanlı Fonksiyon (RTF) ... 35
2.3.7.RTF Ağları ile ÇKA Ağlarının Karşılaştırılması ... 35
2.4.Lojistik Regresyon... 36
2.4.1.Lojistik Regresyon Analizinde Değişken Seçimi... 36
2.4.2.Lojistik Regresyon Analizinde Yöntem Seçimi... 37
2.5.Veri Madenciliği İle İlgili Yapılmış Çalışmalar ... 39
2.5.1.Türkiye’ de yapılan çalışmalar ... 39
2.5.2.Yurt Dışında Yapılan Çalışmalar ... 40
2.5.3.Spor bilimlerinde veri madenciliği alanında yapılan çalışmalar ... 41
BÖLÜM III ... 43
YÖNTEM ... 43
3.1.Araştırma Modeli ... 43 3.2.Evren ve Örneklem ... 43 3.3.Ölçme Araçları ... 44 3.4.Verilerin Toplanması ... 443.5.Verilerin Çözümlenmesi ve Yorumlanması ... 45
BÖLÜM IV ... 46
xi
BÖLÜM V ... 89
TARTIŞMA ... 89
BÖLÜM VI ... 94
SONUÇ VE ÖNERİLER ... 94
6.1.Sonuç ... 94 6.2.Öneriler ... 95KAYNAKLAR ... 97
EKLER ... 106
Ek 1. Fiziksel Uygunluk Karnesi Örneği ... 107
Ek 2. İl Milli Eğitim Müdürlüğü İzin Yazısı ... 108
xii
TABLOLAR LİSTESİ
Tablo 1 Veri Madenciliğinin Tarihsel Gelişimi ... 13
Tablo 2 Kullanım Amaçlarına Göre YSA Algoritmaları... 32
Tablo 3 Regresyon Analizi Türleri ... 36
Tablo 4 Araştırmaya Katılan Okulların Listesi ... 44
Tablo 5 Öğrencilerin Cinsiyetlerine Göre Dağılımları ... 46
Tablo 6 Öğrencilerin Yaşlarına Göre Dağılımları ... 47
Tablo 7 Öğrencilerin Fiziksel Özelliklerine Göre Dağılımı ... 47
Tablo 8 Dünya Sağlık Örgütü Obezite Kategorileri ... 48
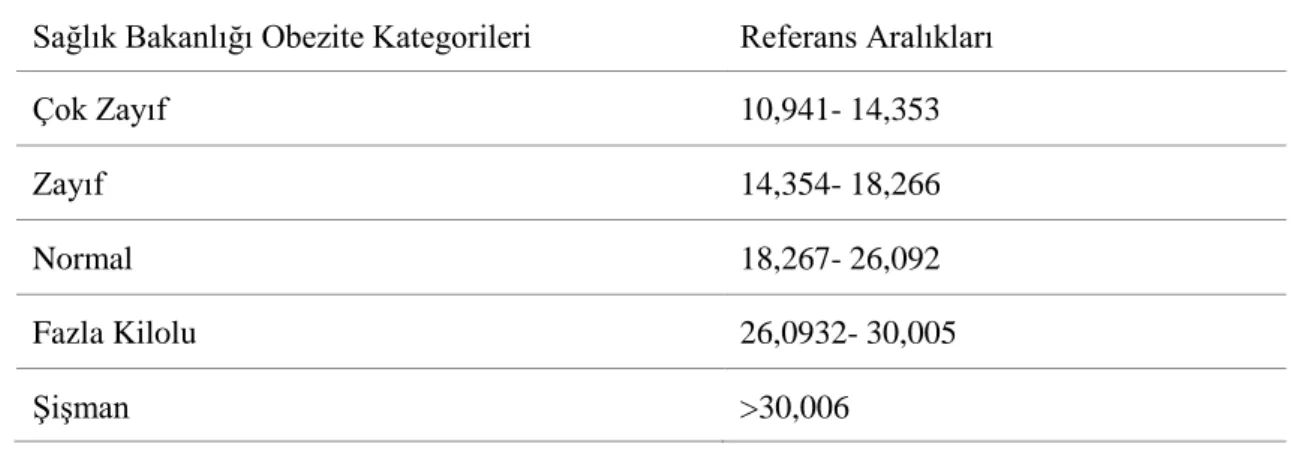
Tablo 9 Sağlık Bakanlığı Obezite Kategorileri ... 48
Tablo 10 Kendall’ S Tau C Uyumluluk Testi ... 49
Tablo 11 YSA’ da Oluşturulan Modeller ... 49
Tablo 12 Model 1 Özeti... 50
Tablo 13 Model 1 Doğru Sınıflandırma Yüzdeleri ... 50
Tablo 14 Model 2 Özeti... 55
Tablo 15 Model 2 Doğru Sınıflandırma Yüzdesi ... 56
Tablo 16 Model 3 Özeti... 60
Tablo 17 Model 3 Doğru Sınıflandırma Yüzdesi ... 60
Tablo 18 Model 4 Özeti... 64
xiii
Tablo 20 Model 5 Özeti... 70
Tablo 21 Model 5 Doğru Sınıflandırma Yüzdesi ... 70
Tablo 22 Model 6 Özeti... 75
Tablo 23 Model 6 Doğru Sınıflandırma Yüzdesi ... 75
Tablo 24 LRA SB Sınıflandırması Model Özeti ... 79
Tablo 25 LRA SB Model Uyum Bilgileri... 80
Tablo 26 Model Uyum İyiliği Testi Sonuçları... 80
Tablo 27 LRA SBSözde R² Değeri Sonuçları ... 81
Tablo 28 LRA SB Modelinin Parametrelerinin Anlamlılıklarının İfade Edilmesi ... 82
Tablo 29 Sağlık Bakanlığı’nın Kategorik Değişkenlerle Oluşturulan Sınıflandırma Tablosu ... 83
Tablo 30 LRA DSÖ Sınıflandırması Modeli Özeti ... 84
Tablo 31 LRA DSÖ Model Uyum Bilgileri ... 84
Tablo 32 Model Uyum İyiliği Testi Sonuçları... 85
Tablo 33 LRA DSÖ Sözde R² Değeri Sonuçları ... 85
Tablo 34 LRA DSÖ Modelinin Parametrelerinin Anlamlılıklarının İfade Edilmesi ... 86
Tablo 35 Dünya Sağlık Örgütü’nün Kategorik Değişkenlerle Oluşturulan Sınıflandırma Tablosu ... 88
xiv
ŞEKİLLER LİSTESİ
Şekil 1.Veri madenciliği ve bilgi keşfi arasındaki ilişki ... 10
Şekil 2. Veri madenciliği süreci ... 15
Şekil 3. Veri indirgeme yöntemleri ... 18
Şekil 4.Veri indirgeme yöntemleri tanımları ... 19
Şekil 5. Veri madenciliği modelleri ve görevleri ... 23
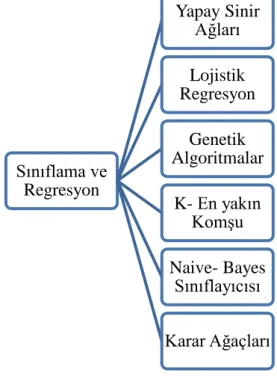
Şekil 6.Sınıflama ve regresyon teknikleri ... 24
Şekil 7. Yapay sinir ağı örneği ... 25
Şekil 8. Çok tabakalı ileri ve geri beslemeli sinir ağları ... 27
Şekil 9. Danışmanlı öğrenme yapısı ... 29
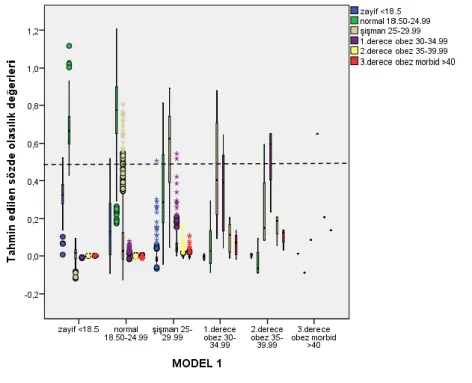
Şekil 10. Model 1 kategorilerin tahmin edilen sözde olasılık değerleri ... 51
Şekil 11. Model 1 hassaslık- özgüllük grafiği ... 52
Şekil 12. Model 1 kazanç grafiği... 53
Şekil 13. Model 1 bağımsız değişkenlerin önemlilik dereceleri ... 54
Şekil 14. Model 2 kategorilerin tahmin edilen sözde olasılık değerleri ... 56
Şekil 15. Model 2 hassaslık- özgüllük grafiği ... 57
Şekil 16. Model 2 kazanç grafiği... 58
Şekil 17. Model 2 bağımsız değişkenlerin önemlilik dereceleri ... 59
Şekil 18. Model 3 tahmin edilen sözde olasılık değerleri ... 61
xv
Şekil 20. Model 3 kazanç grafiği... 62
Şekil 21. Model 3 bağımsız değişkenlerin önemlilik dereceleri ... 63
Şekil 22. Model 4 tahmin edilen sözde olasılıkların sınıflandırılması ... 66
Şekil 23.Model 4 hassaslık- özgüllük grafiği ... 67
Şekil 24. Model 4 kazanç grafiği... 68
Şekil 25. Model 4 bağımsız değişkenlerin önemlilik dereceleri ... 69
Şekil 26. Model 5 tahmin edilen sözde olasılık değerleri ... 71
Şekil 27. Model 5 hassaslık- özgüllük grafiği ... 72
Şekil 28. Model 5 kazanç grafiği... 73
Şekil 29. Model 5 bağımsız değişkenlerin önemlilik dereceleri ... 74
Şekil 30. Model 6 sözde olasılıkların sınıflandırılması ... 76
Şekil 31. Model 6 hassaslık- özgüllük grafiği ... 77
Şekil 32. Model 6 kazanç grafiği... 78
xvi
SİMGELER VE KISALTMALAR LİSTESİ
YSA Yapay Sinir Ağları
LRA Lojistik Regresyon Analizi ÇKA Çok Katmanlı Algılayıcı RTF Radyal Tabanlı Fonksiyon DSÖ Dünya Sağlık Örgütü SB Sağlık Bakanlığı
1
BÖLÜM I
GİRİŞ
Oakland Athletics, MLB (Amerikan Beyzbol Ligi) de yer alan köklü bir beyzbol takımıdır, ancak ligdeki diğer takımlarla rekabet edebilecek kadar parası yoktur. Billy Beane takımın genel menajerlik görevini yürütmektedir. Takım içinde görevi transferler yapmak ve kulüp başkanı, antrenör ve oyuncular arasındaki iletişimi sağlamaktır. Takımın potansiyeline göre iyi geçen bir sezon sonrası altyapıdan yetişen üç oyuncusu olan Jason Giambi, Johnny Damon ve Jason Isringhausen’ı gösterdikleri iyi performansdan dolayı büyük takımlar transfer etmişlerdir. Billy Beane bu üç oyuncunun yokluğunu nasıl dolduracağını düşünürken, Yale Üniversitesi’nde Ekonomi bölümünden mezun olan Peter Brand ile tanışır. Peter’ın beyzbol oyununa bakış açısı ve istatistik konusunda bilgisi onu çok etkiler ve kendisine yardımcı olarak alır. Yeni sezonda istatistik biliminden faydalanarak iyi ve aynı zamanda bütçelerine uygun takımı seçenekler arasından en iyi şekilde kullanarak yeniden kurmaya karar verirler. Billy ve Peter’in yaptığı transfer havuzundaki oyuncuların tamamının istatistiklerini oyuncuların fiyatları ile birleştirerek bir nevi fiyat-kalite oranı çıkarmak ve bu rakamlara göre takımı yeniden kurmaktır. Peter’e göre “İstatistikler oyuncular hakkındaki ön yargıları sıfıra indirir.” Başka bir deyişle Billy ve Peter oyuncunun görünüşü, yaşı, özel hayatı daha doğrusu saha dışında oluşturduğu algıyı istatistik bilimini kullanılarak yok edilebileceğini düşünmektedir. Bu sayede saha dışı sebeplerden dolayı hak ettiklerinden daha az değer biçilen oyuncuları bulup bir çatı altında toplayabilecektir. Çünkü ona göre istatistikler yalnızca saha içi durumlar ile ilgilenecektir. Örneğin topu atış tarzı çok komik göründüğü için kimsenin tercih etmediği Chad Bradford, Billy’ nin ilk tercihi olmuştur. Billy ve Peter’e göre istatistikler oyuncunun neler yapacağının teminatıydı ve bu
2
istatistiksel yöntemleri kullanarak Oakland Athletics, kulüp tarihinin en başarılı dönemini geçirmişti (Lewis, 2003).
Yukarıda Michael Lewis’in kitabından uyarlanan Moneyball adlı filmde Oakland Atletics Beyzbol takımının istatistik bilimini kullanarak nasıl başarılı olduğu açıklanmaya çalışılmıştır. Spor Bilimlerinde; veri madenciliği kullanılmaya başlanmadan önce, sportif kuruluşlar doğru karar verebilmek ve rekabet ortamında avantaj sağlamak için daha çok antrenör, yönetici ve oyuncuların deneyimlerinden faydalanıyorlardı. Bu sayede uzmanların geçmiş deneyimlerinin yararlı bilgi haline dönüştürülebileceğine inanılıyordu. Fakat bu durum zaman içerisinde sübjektif bir hal aldı. Gözlenen bir diğer durum ise günümüzde sporculardan büyük miktarda veri toplanmaktadır. Ancak mevcut veriler genellikle basit araştırmalar ve geleneksel raporlar üretmek için kullanılmaktadır. Verilerin sayısındaki artış beraberinde birtakım problemler meydana getirmiştir. Bunlardan bir tanesi toplanan verilerin bilgi yığını halini alması ve bu bilgiler arasından anlamlı bilgi ortaya çıkartmanın geleneksel yöntemlerle neredeyse imkansız hale gelmesi olmuştur (Leung & Joseph, 2014). Profesyonel sporcular arasındaki rekabetin son yıllarda arttığı görülmektedir. Sadece antrenman yapmanın bu rekabet ortamında avantaj sağlamak için yeterli olmadığı saptanmıştır. Her alanda olduğu gibi sporda da yeni bir çağa girilmiştir. Eski bildik görerek, hissederek, tavsiye ve sezgilere dayalı geleneksel yaklaşımlarla karar alma devrinin yerine, bilimsel keşfe ve güçlü bir analize dayalı değerlendirme yöntemleri ön plana çıkmıştır. Günümüzde sportif performans ile başarıya ulaşmak ve gelecekteki performansın tahminini yapabilmek için büyük veri setlerinin oluşturulması gerekmektedir. Basit istatistiksel yöntemlerle büyük verilerin çözümlenmesi oldukça zor görünmektedir (Leung & Joseph, 2014). Artık antrenörlerin, sporcuların mevcut olan performanslarını arttırabilmek için bilimsel istatistik programlarına yöneldikleri görülmektedir. Bir sisteme sahip, bilimsel yöntemler uygulayan takımların rakiplerine göre daha ön plana çıktığı görülmektedir (Leung & Joseph, 2014). Bu nedenle, büyük veri setlerini çözümlemeye çalışan analistlerin yeni veri analiz yöntemlerine yöneldikleri gözlemlenmiştir. Bu alanda en yeni geliştirilen tekniklerden birisi de veri madenciliği olmuştur (Dasu & Johnson 2003).
Sporda veri madenciliği teknikleri kullanılması ve sporcuların geçmişteki müsabaka kayıtlarının tutulması, onların daha iyi bir performans göstermelerine katkı sağlamaktadır. Bu sebeple spor biliminde çalışan araştırmacıların veri madenciliği alanına odaklandıkları görülmektedir. Geniş, karmaşık ve bilgi açısında zengin verilerin anlaşılması bilim, eğitim
3
ve iş çevreleri için ortak bir gereksinimdir. Bu büyük veri setleri içerisinden değerli bilgileri keşfetmek, değişkenler arasındaki gizli ilişkileri ortaya koymak, kulüplere sportif amaçlarına ulaşmaları konusunda önemli ölçüde katkı sağlayacağı düşünülmektedir (Cao, 2012).
Veri madenciliğinin amacı, yoğun veriler içinden geleneksel yöntemlerle bulunamayacak, fark yaratacak bilgilere ulaşmanın yanı sıra, özellikle günümüzün rekabetçi koşullarına uygun olarak rakiplere karşı fark yaratmaktır. Bu işlem bir madencinin taş ve kaya parçaları arasından bir madeni çıkartması ve işlemesi faaliyetine benzemektedir (Özkan & Boran, 2014). Öngörü yönteminin karar alma sürecinde başarılı kararları beraberinde getireceği ve bu sayede maksimum fayda sağlayacağı gerçeği ileri istatistik yöntemlerine olan ilgiyi arttırmaktadır. Bu alandaki ilginin artmasıyla beraber kullanılan yöntem çeşitliliği de hızla artmaktadır. Bu tekniklerden en önemlileri yapay sinir ağları ve lojistik regresyon analizi’ dir (Yurtoğlu, 2005).
Yapay Zeka çalışmalarında ortaya çıkan ve yapay zekaya destek sağlayan sistemlerden bir tanesi yapay sinir ağları (YSA) teknolojisidir. İnsan beyninin çalışma prensiplerini taklit eden YSA modelleri birçok alanda kullanılmaktadır. YSA, eğitilebilme, genelleme yapabilme ve çok fazla değişkenle çalışabilme gibi ayırt edici özelliklere sahiptir. Programlanmış bilgisayarlara düşünme yeteneği sağlayarak insan gibi düşünen ve davranan sistemler geliştirilmesi çalışmaları 1950 yılından itibaren başlamıştır (Yurtoğlu, 2005). Bugün gelinen noktada insan gibi davranış gösteren ve insan gibi düşüne bilen sistemlerin geliştirilmesi için büyük şirketler yatırımlarının büyük bir kısmını bu alana ayırmaktadır. Bu sayede yapay zeka her geçen gün ciddi ilerlemeler kaydetmektedir.
Veriler arasındaki değerli ve kazanç sağlayan bilgilerin elde edilmesinde veri analizleri uzun sürelerdir kurumlar tarafından kullanılmaktadır. Ancak spor bilimleri alanında başarı tahmini yönteminin kullanılmaması, karmaşık veriler için en doğru tekniğin seçilmesi için istatistik bilgisine sahip personel azlığı ve veri madenciliği teknikleri için bütçe ayrılması gibi sebeplerden dolayı yetersiz kalmıştır (Yurtoğlu, 2005).
Veri madenciliği spor bilimlerinde çok yeni bir alandır ve küçük bir literatüre sahiptir. Veri madenciliğinin başarı ile uygulandığı birçok alan vardır (tıp, mühendislik, ekonomi gibi), ancak spor bilimleri alanında sınırlı sayıda uygulama yapılmıştır. Bu çalışma beden eğitimi alanında yapay sinir ağları yaklaşımının ve lojistik regresyon yönteminin sınıflandırma işlemleri için geçerliliği sorgulama fırsatı verecektir.
4
Bu çalışma esnasında YSA yöntemi kullanılarak hazırlanan sınıflandırma modeli ile LRA yöntemi kullanılarak oluşturulan modelin sınıflandırma başarısı açısından karşılaştırma yapılmıştır. Karşılaştırmada YSA yöntemi kullanılan modelin performansının, eğitim seti ve test setinin dağılımına, kullanılan ağ yapısına, öğrenme yöntemine, öğrenme katsayısına göre değişimleri incelenmiştir.
1.1.Araştırmanın Amacı
Bu çalışmanın amacı, Konya ili Cihanbeyli ilçesinde öğrenim gören 1050 öğrenciye beden eğitimi öğretmenleri tarafından uygulanan fiziksel uygunluk karnesi ölçümlerinin Dünya Sağlık Örgütü ve Sağlık Bakanlığı obezite sınıflandırmasına göre farklı veri madenciliği yöntemleri kullanılarak sınıflandırması ve veri madenciliği yöntemlerinin sınıflandırma performanslarının karşılaştırılarak yorumlanmasıdır. Ayrıca spor bilimlerinde veri madenciliği konusunda altyapıya katkı sağlamak, spor profesyonellerine ve spor bilimcilerine veri madenciliği kullanımı ile ilgili bir örnek ortaya koymaktır. Bunun yanı sıra onlara karar verme süreçleri açısından yeni bir bakış açısı kazandırmak, veri toplama ve veri çözümlemenin önemini ortaya koymaktır. Bu araştırmada aşağıdaki sorulara yanıt aranmıştır:
1. Yapay sinir ağları analizinde Sağlık Bakanlığı sınıflandırması için oluşturulan modellerden en yüksek sınıflandırma yüzdesini veren model hangisidir?
2. Yapay sinir ağları analizinde Dünya Sağlık Örgütü sınıflandırması için oluşturulan modellerden en yüksek sınıflandırma yüzdesini veren model hangisidir?
3. Yapay sinir ağlarının alt çözümleme yöntemlerinden olan çok katmanlı algılayıcı mı daha başarılı olmuştur yoksa radyal tabanlı fonksiyon mu?
4. Lojistik regresyon analizi ve Yapay sinir ağları analizi sonuçlarından hangisi daha yüksek sınıflandırma yapmıştır?
5. Alınan ölçümlerden hangileri sınıflandırmaya daha çok etki etmektedir?
1.2.Araştırmanın Önemi
Bu çalışmanın önemi; yapay sinir ağları ve lojistik regresyon analizi yöntemlerinin sınıflandırma performanslarının karşılaştırılması, yapay sinir ağları yöntemi kullanılarak oluşturulan modellerin, lojistik regresyon analizine bir alternatif oluşturup
5
oluşturamayacağının belirlenmesi, yapay sinir ağlarının beden eğitimindeki kullanım alanlarıyla ilgili yapılan çalışmalara katkıda bulunulması ve spor bilimine fayda sağlayacak bilgiler çıkartılması olarak özetlenebilir.
1.3.Sınırlılıklar
1. 2016-2017 yılları arasında Konya ili, Cihanbeyli ilçesinde yer alan 5 okuldan alınan toplam 1050 veri ile sınırlıdır.
2. Araştırma öğrencilerden sağlıkla ilgili fiziksel uygunluk karnesi adı altında alınan yaş, cinsiyet, boy, kilo, esneklik sağ, esneklik sol, mekik ve şınav verileri ile sınırlıdır.
3. Sınıflandırma tahminlerinde kullanılan YSA ve LRA yöntemlerinin yorumlanmasıyla sınırlıdır.
1.4.Tanımlar
Wald istatistiği: Modelin anlamlılığını ifade eder. Wald istatistiği β’ nın anlamlılığını ve her
bir değişkenin modele olan katkısını ifade eder (Çokluk, Şekercioğlu & Büyüköztürk, 2010).
Odds:Bir olayın gerçekleşme ihtimalinin olmama ihtimaline bölümüdür (Çokluk vd., 2010). Üstel Lojistik Regresyon Katsayısı (Exp(β)): Her bir değişken için hesaplanan odds oranını
ifade eder (Çokluk vd., 2010). Yordayıcı değişkende meydana gelecek bir birimlik değişmeden dolayı, odds oranında meydana gelen değişmeyi gösterir (Çokluk vd., 2010).
-2LL ya da -2log (-2log likelihood): Model uyum için kullanılan bir yöntemdir. Maksimum
olabilirlik kestiriminin ne kadar iyi uyuma işaret ettiğini ifade eder. 2LL minimum sıfır (0) değerini alabilir ve bu değer mükemmel uyum demektir. 2LL = 0 olduğunda olabilirlik= 1’ dir. Olasılık değeri bir modelin diğer bir modelle olan uyumunda meydana gelen farkı karşılaştırılarak değerlendirilir (Çokluk vd., 2010).
Cox&Snell R2 ve Nagelkerke 𝑅2 Değerleri: Bağımlı değişkende model tarafından tanımlanan varyansın iki değişik yoldan tahmin edilmesini gösterir. Lojistik model tarafında tanımlanan varyansın her iki değerdeki miktarını gösterir. 1.00 değeri mükemmel uyum demektir. Cox&Snell 𝑅2 asla 1 olamaz bu sebeple Nagelkerke 𝑅2hesaplanır. Nagelkerke 𝑅2
6
0-1 arasında𝐴 = 𝜋𝑟2 değişmesi için Cox&Snell’in değişime uğramış halidir. Bu sebeple daima Nagelkerke 𝑅2, Cox&Snell 𝑅2’ nin değerinden daha yüksektir (Çokluk vd., 2010).
7
BÖLÜM II
KAVRAMSAL ÇERÇEVE
2.1.Fiziksel Uygunluk
Fiziksel uygunluk, günlük işleri yorgunluk hissetmeden, canlı bir şekilde yapabilecek ve serbest zamanları eğlenceli aktivitelerle geçirebilecek gerekli enerjiye sahip olmaktır (Clarke, 1967). Fiziksel uygunluk içerisinde kas dayanıklılığı, kas kuvveti, kardiyovasküler dayanıklılığı, sürat, esneklik, denge, reaksiyon zamanı ve beden kompozisyonunu yer almaktadır. Bu nitelikler sağlık bakımından ve sportif performans bakımından farklı önemlere sahip oldukları için sağlıkla ilgili fiziksel uygunluk ve beceri ilişkili fiziksel uygunluk olarak ayrılmaktadır. Sağlıkla ilgili fiziksel uygunluk kardiyovasküler dayanıklılık, kas kuvveti ve dayanıklılığı, esneklik ve beden kompozisyonunu içerir (Graham, Hale & Parker, 2001). Sporla ilgili fiziksel uygunluk ise; patlayıcı kuvvet, güç, hız, çabukluk, koordinasyon, denge, reaksiyon zamanı ve yapılan spor branşı ile ilgili diğer özelliklere ilişkin ölçümleri içerir. Bahsedilen bu ölçümlerin sonucunda çıkan yetersizlik ya da o yaş ve cinsiyet grubuna göre belirlenen norm değerin altında bir durum olduğunda bireylerin fiziksel uygunluk düzeyinde yetersizlikten söz edilir (Milli Eğitim Bakanlığı, 2017).
2.1.1.Fiziksel Uygunluk Eğitimi
Fiziksel uygunluk eğitiminin hedefi, öğrencilerin fiziksel uygunluk düzeylerini sadece okul süresince değil okul sonrasındaki yaşamlarında da geliştirebilmeleri ve düzenli olarak fiziksel aktivite yapabilmeleri için gerekli olan bilgi, beceri ve tutumları kazandırarak toplumda yetersiz fiziksel aktivite sebebiyle oluşan sağlık sorunlarını en aza indirmektedir (Milli Eğitim Bakanlığı, 2017).
8
2.1.2.Fiziksel Uygunluk Karnesi
Sağlık Bakanlığı’nın Ulusal Fiziksel Aktivite Rehberi’nde yer alan öneriler kapsamında ve Milli Eğitim Bakanlığı (MEB) ile Sağlık Bakanlığı işbirliğinde öğrencilerde Sağlıklı Beslenme ve Fiziksel Aktivite farkındalığını arttırmak ve teşvik etmek amacıyla bilim kurulu kararı ile “Sağlıkla İlgili Fiziksel Uygunluk Karnesi” geliştirilmiştir (Milli Eğitim Bakanlığı, 2017)
Sağlıkla İlgili Fiziksel Uygunluk Karnesi eğitim ve öğretim yılı başında ve sonunda (15 Eylül- 15 Ekim ve 15 Nisan-15 Mayıs) olmak üzere yılda 2 kez verilecek olup uygulamada mekik, şınav, otur-uzan esneklik ölçümü, vücut ağırlığı ve boy uzunluğu ölçümü değerlendirilecektir. Sağlıkla İlgili Fiziksel Uygunluk Karnesi ana karnedeki beden eğitimi ve spor ders notunu etkilemeyecek ve çocuklara ait bilgiler gizli tutulup her çocuğun kendi ailesiyle paylaşılacaktır. E-okul veri tabanından velilerin diğer karne notlarına erişimleri gibi Sağlıkla İlgili Fiziksel Uygunluk Karnesine de ulaşımlarının sağlanması planlanmaktadır (Milli Eğitim Bakanlığı, 2017).
Gelişmiş ülkelerde uygulanan Sağlıkla İlgili Fiziksel Uygunluk Karnesinin ülkemizde de uygulaması ile uzun vadede ortaokul ve lise öğrencilerinin gelişimlerinin izlenmesi hususunda faydalı olacağı düşünülmektedir (Milli Eğitim Bakanlığı, 2017).
2.2. Veri Madenciliği
2.2.1. Veri Madenciliği Kavramı
Gelişen spor biliminin diğer bilimlerle ilişkisinin artmasıyla elde edilen bilgilerin çoğaldığı görülmektedir. Spor organizasyonlarının sayısının artmasıyla elde edilebilinecek veri sayısı da artmıştır. Dijital verilerin hacmindeki artış beraberinde yeni sorun alanları da yaratmıştır. Bunların başlıcaları; çok miktarda, çok boyutlu ve karmaşık verileri işlemek için yöntem ya da sistemler geliştirmek; yeni türdeki verileri işlemek için yöntem, protokol ya da altyapı geliştirmek; verilerin kullanımı ve güvenliği ile ilgili modeller geliştirmek olarak sıralanmaktadır (Koyuncugil & Özgülbaş, 2009). Veri madenciliği bu tür ihtiyaçlara cevap verebilecek en iyi yöntemlerden birisidir. Çünkü veri madenciliği, veriler arasındaki ilişkilerin altında yatan nedenleri bulmak için kullanılan önemli bir istatistiksel yöntemdir (Han & Kamber, 2001).
9
Veri madenciliği kavramının disiplinler arası bir konu olarak, birçok farklı şekilde tanımlanabiliyor olması şaşırtıcı bir durum değildir. Veri madenciliği, önceden bilinmeyen, gizli, anlamlı ve yararlı örüntülerin büyük ölçekli veri tabanlarından otomatik biçimde elde edilmesini sağlayan veri tabanlarındaki büyük miktarda veriden ilginç modelleri ve bilgileri keşfetme sürecidir (Sever & Oğuz, 2002).
Teknolojik gelişmelere paralel olarak verilerin dijital ortamlarda saklanması nedeniyle veri tabanlarının hacimlerinde olağanüstü bir artış meydana gelmiştir. Bu durum geleneksel sorgulama ve raporlama araçlarının dev veri yığınları karşısında etkisiz kalmasına yol açmıştır (Karacan & Yeşilbudak, 2010). Bunun sonucunda veri tabanlarında ve veri ambarlarında depolanan veri yığınları arasından anlamlı ilişkilerin, kalıpların ve eğilimlerin ortaya çıkartılması ihtiyacı doğmuş, gelecek adına doğru tahminlerin yapılması önem kazanmıştır (Ersöz, 2013, s. 120).
Veri madenciliği profesyonel bir etkinlik olarak geliştikçe, veri madenciliğini önceki istatistiksel modellerden ayırmak gerekli hale gelmiştir. Veri madenciliğinin uygulama alanının giderek gelişmesi, tanımlamalara odaklanılması, bilginin ve bilgi kaynaklarına olan bakış açılarının geliştirilmesine yol açmaktadır. Veri madenciliğinin farklı bakış açılarına odaklanmasıyla birbirinden farklılık gösteren çeşitli tanımlamalar yapılmıştır. Eski tanımlardan biri şudur ki (Nisbet, Elder & Miner, 2009, s. 154) :
Veriler arasında gizli kalmış, önceden bilinmeyen, potansiyel olarak yararlı olabilecek bilgilerin ortaya çıkarılmasıdır (Frawley & Shapira, 1992).
Veri tabanındaki bilgi keşfi, verideki tanımlamaların geçerli, potansiyel olarak yaralı olabilecek ve en nihayetinde anlaşılması çok kolay olmayan bir gelişimsel süreçtir (Nisbet vd., 2009).
10
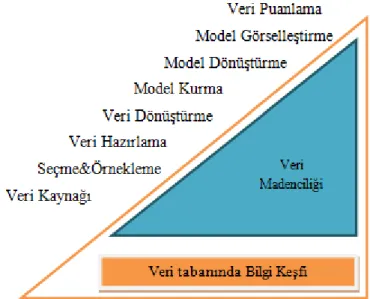
Şekil 1.Veri madenciliği ve bilgi keşfi arasındaki ilişki
Nisbet vd. (2009) ’in bilgilerinden yola çıkılarak yapılan tanım kapsamlı bir bilgiden ziyade verinin içindeki model ve şablonlara odaklanmaktadır. Bu model ve şablonlar belli belirsizdir ve ayırt edilmesi güçtür. Bu model ve şablonlar sadece tahmin edici değişkenler ve birbirleri arasında doğrusal olmayan ilişkileri değerlendirebilen analiz algoritmaları tarafından ayırt edilebilmektedirler. Veri madenciliğinin bu tanımları veri madenciliği için kullanılan makine öğrenme araçlarının git gide fazlalaşmasıyla beraber gelişim gösterdiği görülmektedir. Karar ağaçları ve yapay sinir ağları parametrik istatistiksel algoritmaları içerisinde barındırdığından doğrusal olmayan modellerin analizine daha kolay bir şekilde izin vermektedir. Bunun sebebi ise makine öğrenme algoritmalarının insanların yaptığı şekilde öğrenme gerçekleşmesidir (Nisbet vd., 2009).
Veri tabanındaki modern bilgi keşfi süreci (Knowledge Discovery Database) bilgiyi ortaya çıkararak, bütün süreç ile verideki ilginç modelleri keşfetmek için kullanılan matematiği kombinlemekte ve bunu yaparken bazı amaçlar için bilginin varlığını güçlendirecek diğer veri setlerine başvuran sonuçsal şablonları kullanmaktadır (Nisbet vd., 2009).
Geniş, karmaşık ve bilgi bakımından zengin veri setlerini anlama ihtiyacı neredeyse tüm ticaret, bilim ve endüstrinin bütün alanları için gereklidir. İş dünyasında kurumsal ve müşteri bilgileri stratejik bir kazanç olarak git gide farkındalık yaratmaktadır. Bu veriler içerisinde saklanan yararlı bilgileri ortaya çıkarma ve bu bilgiyi kullanma yeteneği bugünün rekabete dayanan dünyası içerisinde giderek önem kazanmaktadır. Yeni teknikleri içeren bilgisayar
11
uygulamalarının bütün süreci, veri içerisinden bilgiyi keşfetmeyi sağlar ve bu da veri madenciliği olarak adlandırılmaktadır (Kantardzic, 2011, s. 95).
Veri madenciliği tekniğini kullanarak kurumlar, geleceğe yapacakları yatırımlarda daha isabetli ve hızlı kararlar alabilmektedirler. Kurumların daha önce kullandıkları analiz yöntemlerinden farklı olarak, veri madenciliği yöntemlerini kullanarak daha güvenilir sonuçlar elde edebilecektir (İnan, 2003).
Veri madenciliği, otomatik ya da manuel metotlar içerisinden keşfetme yöntemiyle hangi gelişmenin tanımlanacağını içeren tekrarlı bir süreçtir. Veri madenciliği neyin ilginç bir ürün ortaya koyacağı hakkında herhangi bir önceden kararlaştırılmış kavram ya da eğilimin olmadığı keşfe dayalı bir analiz senaryosu için en yararlı yöntemdir. Veri madenciliği büyük veri tabakaları içerisinde yeni, değerli ve anlaşılması zor olan araştırmalara dayalıdır. Bu işlem insanların ve bilgisayarların iş birliği içerisinde çalışmasını içermektedir. En iyi sonuçlar bilgisayarların araştırma kabiliyeti ile problemleri ve amaçları tanımlayan uzmanların bilgilerini dengeleme ile sağlanmaktadır (Kantardzic, 2011). Bu genel açıklamalardan sonra veri madenciliğinin geçmişine bakmak konunun anlaşılması katkı sağlayabilir. Bu bölümden sonra veri madenciliğinin tarihsel gelişimi hakkında bilgi verilecektir.
2.2.2.Veri Madenciliğinin Tarihsel Gelişimi
Günümüzde bilgisayarlar neredeyse her evde bulunmaktadır ve internet erişimi hemen hemen her yerden sağlanmaktadır. Depolanan disk kapasitelerinin artması, istenilen her yerden bilgiye ulaşma imkânı, bilgisayarların büyük miktarda veri saklamasına ve daha hızlı işlem yapmasına imkân sağlamıştır. Geçmişten bu yana veriler sürekli yorumlanmış, bu verilerden bilgi elde etmek istenmiştir. Bu amaçla yeni donanımlar ve programlar oluşturulmuştur. Bu sayede bilgi, geçmişten bugüne taşınmıştır (Savaş, Topaloğlu & Yılmaz, 2012).
1950’li yıllarda mantık, bilgisayar bilimleri alanlarındaki yapay zeka ve makine öğrenme konularında çalışmalara başlanması veri madenciliğine giden yolda adım atılmaya başlandığı yıllardır. Veri madenciliği kullanılmaya başlanmadan önce 1960’lı yıllarda, bilgisayarların gelişmesinin hızlanmasıyla veri tabanı ve verilerin depolanması işlemleri yapılmaya başlamıştır. 1960’ların sonunda bilim adamları basit öğrenmeli bilgisayarlar geliştirebilmişlerdir. Günümüzde sinir ağları olarak bilinen perseptron’ ların çok basit
12
kuralları öğrenebileceği Minsky ve Papert (1969) tarafından ortaya çıkarılmıştır. O yıllarda, bilgisayarlar aracılığıyla yeterince uzun bir tarama yapıldığında, istenilen veriye ulaşılabileceği görülmüş ve bu işleme veri taraması (data dredging), veri yakalanması (data fishing) denilmiştir (Öğüt, 2007).
1970’lerde ilişkisel veri tabanı yönetim sistemleri uygulamaları kullanılmıştır. Programcılar basit kurallara dayanan sistemler geliştirerek basit anlamda makine öğrenimini sağlamışlardır. 1980’lerde veri tabanı yönetim sistemleri yaygınlaşarak mühendislik gibi bilimsel alanlarda uygulanmaya başlanmıştır. Bu sayede şirketler, müşterileri, ürünleri ve rakipleri hakkında bilgiler içeren çok büyük miktarda veri tabanları oluşturmuşlardır. 1990’lı yıllarda bilim adamları içerisinde çok büyük ve sürekli artan veri barındıran veri tabanlarından faydalı ve işe yarayacak bilgilerin çıkarılması için çalışmalar yapmaya başlamışlardır. Bu süreç içerisinde 1992 yılında veri madenciliği için ilk yazılım gerçekleşmiştir. 2000’li yıllardan sonra her geçen yıl veri madenciliği alanında yapılan çalışmalar artmıştır ve veri madenciliğinin alana olan faydası görüldükçe tüm alanlarda uygulanmaya başlanmıştır (Savaş vd., 2012).
13 Tablo 1
Veri Madenciliğinin Tarihsel Gelişimi
Gelişim Adımları Cevaplanan Karar Problemi Kullanılabilen Teknolojiler Ürün Sağlayıcıları Karakteristikler Veri Toplama (1960’lar) “Geride bırakılan 5 sezonda kaç şampiyonluk yaşandı?” Bilgisayarlar, Teypler, Diskler Fortran Geriye dönük, statik veri dağılımı Veri Erişimi (1980’ler) “Türkiye liginde geçen sezon toplam kaç gol atıldı?” Daha hızlı ve ucuz bilgisayarlar, daha fazla depolama alanı, ilişkisel veri tabanları Oracle, Sybase, İnformix, İBM, Microsoft Kayıt düzeyinde geriye dönük, dinamik veri dağıtımı Veri Ambarlama ve Karar Destek Sistemleri (1990’lar) “Türkiye liginde geçen sezon toplam kaç gol atıldı?” Daha hızlı ve ucuz bilgisayarlar, daha fazla depolama alanı, ilişkisel veri tabanları, OLAP, Çok boyutlu, Veri ambarları Pilot, Comshare, Arbor, Cognos, Microstrategy Çoklu düzeylerde, geriye dönük dinamik veri dağıtımı Veri Madenciliği (Bugün) “Gelecek sezon Türkiye liginde muhtemelen kaç galibiyet alınır, niçin?” İleri düzeyde algoritmalar, çok işlemcili bilgisayarlar, büyük veri tabanları Pilot, Lockheed, IBM, SGI, SPSS, SAS, Microsoft vs. Geleceğe dönük, proaktif enformasyon dağıtımı
Veri madenciliğinin tanımı başlangıçta model kurma süreciyle sınırlıydı. Fakat uygulama geliştikçe veri madenciliği uygulama programları (örneğin, SPSS- Clementine), değerlendirme ve modellerin görüntülenmesi ve ayrıca modellerin inşasına fayda sağlamak için gerekli olan diğer araçları da içerisinde barındırmıştır. Kısa bir süre içerisinde veri madenciliğinin tanımı Tablo 1’ deki işlemleri kapsayacak şekilde genişlediği görülmüştür (Nisbet vd., 2009). Veri madenciliğinin kullanıldığı uygulama örnekleri, veri madenciliğinin gelişimini daha iyi anlamamıza fayda sağlayacaktır.
Veri madenciliği teknolojisine, birtakım kanıta dayanan herhangi bir kararın alınacağı herhangi bir yerde başvurulabilir. Geçmişteki uygulama çeşitliliği aşağıda yer almıştır: • Satış Tahmini: Veri madenciliği teknolojisinin en erken kullanımlarından birisidir.
14
• Raf Yönetimi: Satışların tahmininin mantıklı takibi yapılmıştır.
• Bilimsel Keşif: Yarım milyar gösterişli obje içerisinde hangisinin dikkate değer olduğunu tanımlamada bir yol olarak kullanılmıştır.
• Kumar: Hangi müşterinin harcama yapmada en yüksek potansiyele sahip olduğunu tahmin etmede bir yöntem olarak kullanılmıştır.
• Müşteri İlişkileri Yönetimi: Muhafaza, çapraz satış / yukarı satış eğilimi tahmininde kullanılmıştır.
• Müşteri Kazanma: Bir üyelik teklifine cevap vermek için en muhtemel beklentileri tanımlamada bir yol olarak kullanılmıştır.
• Spor: Hangi oyuncu ve oyun durumlarının, yüksek skor için en yüksek potansiyele sahip olduğunu tahmin etmede bir yöntem olarak kullanılmıştır (Silahtaroğlu, 2008). Bunların haricinde Twentieth Century Fox film şirketi müşterilerin fatura bilgilerini veri madenciliği tekniği ile analiz ederek hangi filmin ya da hangi aktörün hangi bölgede daha çok izlendiğini belirleyerek bölgesel olarak film gösterim ağı oluşturmuştur (Levent, 2016).
2.2.3.Veri Madenciliği Süreci
Veri madenciliği çalışmalarının istendiği gibi başarılı bir şekilde sonuçlanması isteniyorsa sistematik bir yaklaşımda bulunmak gerekmektedir. Kullanılan süreçlerde yapılacak hatalar (örneğin, veri boyutlarının ve sınırlarının net olmayışı) ve gözden kaçırılan durumlar araştırmacı için zaman kaybına ve bunun beraberinde ciddi hatalar ortaya çıkarabilmektedir. Veri madenciliğini sistematik bir şekilde yürütebilmek için 1996 yılında Veri Madenciliği için Sektörler Arası Standart konsorsiyumu kurulmuştur. Bu çalışmada bu süreç CRISP-DM adıyla anılacaktır. Bu konsorsiyum tarafından belirlenen veri madenciliği süreci beş aşamadan oluşmaktadır (Gürsoy, 2009, s. 64).
15
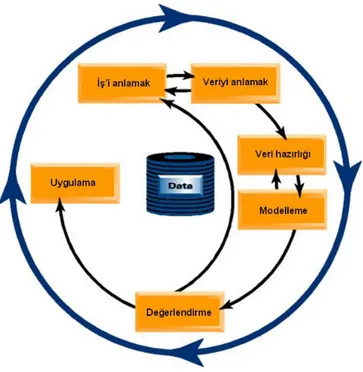
Şekil 2. Veri madenciliği süreci
1. Problemin veya Projenin Tanımlanması (iş’ i anlamak) 2. Veri Anlama
3. Veri Hazırlama 4. Modelin Kurulması
5. Modelin Değerlendirilmesi 6. Modelin Uygulanması
2.2.3.1.Problemin veya Projenin Tanımlanması
Veri madenciliği sürecinin ilk adımı çalışmasının hangi amaç için yapılacağının ve çalışmanın gerekliliklerinin anlaşılmasının ortaya çıkarılmasıdır. Cevap aranan sorunun üzerine odaklanılmalı, net biçimde ifade edilmeli ve sonuç değerlendirme kriterleri tanımlanmalıdır. Araştırmanın ve veri madenciliğinin amacını, mevcut durumun değerlendirilmesiyle planlama sürecinin belirlenmesini kapsar. Çalışma sonucunda ortaya çıkacak sonucun hangi durumlarda kullanılacağına karar verilir. Veri madenciliğinin temel amacı veri arttırmak olduğundan sonuçlar kadar sürecin kendisi de önemlidir. Problemin veya projenin tanımlanması aşaması eldeki verilerin, risklerin ve maliyetler gibi kriterlerin hepsinin değerlendirildiği bir süreçtir (Ergüden & Erşahin, 2008, s. 15).
16
2.2.3.2.Veri Anlama
Verileri inceledikçe proje ile ilgili farklı bakış açısı kazanmak mümkündür. Proje ile ilgili farklı bakış açısı kazandıkça daha farklı verilere bakılır ve bu döngü dahilinde çalışma sürecinde kullanılacak veriler netlik kazanır. Bu süreçte veri toplanarak, toplanan verilerin ihtiyaçlara cevap verip vermediğinin değerlendirmesi yapılır. Çalışmada kullanılacak verilerden eksik verinin olup olmadığının ve verilerin doğru olup olmadığının değerlendirilmesi yapılır (Ergüden & Erşahin, 2008, s. 16).
2.2.3.3.Veri Hazırlama
Veri hazırlanmasını bir süreç olarak ele almak gerekmektedir. Başlangıç verilerinin çalışmada kullanılacak şekilde hazırlanması amaçtır. Bu sürecin belirli bir sırası yoktur, karşımıza çıkan herhangi bir sorunda sıklıkla geriye dönülerek gözden geçirilebilir. Büyük miktardaki veri tabanlarından verilerin kullanımı zor olacaktır. Bu büyük veri setleri içerisinde bulunan veriler, veri madenciliği için uygun hale getirildiğinde veri tabanları, veri madenciliği için daha kaliteli bir çalışma alanı haline getirilmiş olur. Söz konusu süreç aşağıdaki adımları içermektedir (Han & Kamber, 2001, s. 142):
1. Verilerin Toplanması 2. Verilerin Temizlenmesi 3. Verilerin Bütünleştirilmesi 4. Verilerin İndirgenmesi 5. Verilerin Dönüştürülmesi 2.2.3.3.1.Verilerin Toplanması
Modelin kurulabilmesi için gereken bilgilerin hazırladığı bu aşamada problem için gerekli olan verilerin toplanmasında öncelikle veri kaynaklarının belirlenmesi gerekir. Bu veriler birincil veri kaynaklarından bulabileceği gibi farklı veri tabanlarından da bulabilmektedirler. Kullanılacak verilerin sayısı iyi ayarlanmalıdır. Eğer az miktarda veri kullanılırsa istenilen sonuçlar elde edilemeyebilir, çok fazla miktarda veri kullanıldığında ise veri kirliliği meydana gelir ve sürece katkı sağlamayacaktır. Aynı şekilde toplanan verilerin güvenilir olup olmadığı doğru sonuçlara ulaşılıp ulaşılmayacağını etkileyecektir. Bu nedenle veri
17
madenciliğinde doğru sonuçları elde etmek için toplanan verilerin yeterli sayıda ve güvenilir kaynaktan toplanması gerekmektedir (Yıldırım, 2016).
2.2.3.3.2.Veri temizleme
Bazı uygulamalarda, üzerinde çözümleme yapılacak verilerin eksik olması ya da uygun olmaması gibi sorunlarla karşılaşılabilir. Veri tabanlarında yer alan bu hatalı verilere gürültü veri denilmektedir (Han & Kamber, 2001, s. 143). Bu aşamada veri setleri içerisinde bulunan bazı kötü verileri düzeltmek, yanlış girilmiş verileri temizlemek ve çok ayrıntı içeren verileri süzerek onların arasından işe yarayan verileri modelde kullanmak için yapılan işlemleri içerir (Nisbet vd., 2009). Eksik ve hatalı verilerin yerine yenileri belirlenerek konulmalıdır. Eksik verilerin yaratacağı sorunları ortadan kaldırmak için kullanılan teknikler aşağıdakilerden biri olabilir (Han & Kamber, 2001, s. 143):
• Eksik değer içeren kayıtları bulunduğu veri tabanından çıkartmak ya da bu kayıtları iptal etmek,
• Kayıp değerleri tüm değişkenlerde aynı sabit değerle doldurmak. Örneğin “bilinmiyor” değeri kullanılabilir.
• Tüm veriler kullanılarak değişkenin ortalaması hesaplanır ve eksik değer yerine bu ortalama değeri verilebilir.
• Sadece bir sınıfa ait örneklerin ortalaması hesaplanarak eksik değerin yerine konulabilir.
• Regresyon yöntemi kullanarak eksik değer tahmini yapılabilir (Özkan, 2008, s. 40).
2.2.3.3.3.Verilerin Bütünleştirilmesi
Farklı veri kaynaklarından elde edilen verilerin birlikte değerlendirilebilmesi için farklı türdeki verilerin tek bir veri tabanına dönüştürülmesi gerekir. Bu aşamada ilgisiz niteliklerin atılır ve tekrarlı kayıtların temizlenerek farklı kaynaklar arasındaki uyumsuzluklar giderilmeye çalışılır (Ersöz, 2013, s. 59).
18
2.2.3.3.4.Verilerin İndirgenmesi
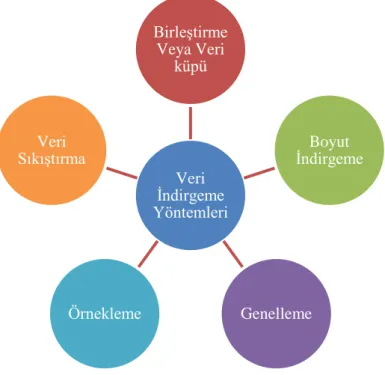
Veri çözümleme işlemi veri madenciliğinde bazen çok uzun zaman alabilmektedir. Değişken sayısının ve veri sayısının çok fazla olduğu durumlarda çözümleme yaparken elde edilecek sonucun değişmeyeceğine inanılıyorsa veri sayısında azaltılma yapılabilir (Han & Kamber, 2001, s. 144). Veri indirgeme yöntemleri Şekil 3’ de şematik olarak gösterilmiştir.
Şekil 3. Veri indirgeme yöntemleri
Veri İndirgeme Yöntemleri Birleştirme Veya Veri küpü Boyut İndirgeme Genelleme Örnekleme Veri Sıkıştırma
19
Şekil 4.Veri indirgeme yöntemleri tanımları
2.2.3.3.5.Verilerin Dönüştürülmesi
Veri madenciliğinde bazı durumlarda kullanılan kaynakları çözümlemeye doğrudan dahil etmek uygun olmayabilir. Değişkenler açısından, her değişkenin ortalama ve varyansları birbirinden önemli ölçüde farklı olacağından büyük ortalama ve varyansa sahip olan değişkenler diğerleri üzerinde daha baskın olacaktır ve bu da diğer değişkenlerin önemini azaltacaktır. Değişkenler içerisinde bulunan çok küçük ya da çok büyük değerler
• Veriler çok boyutlu veri küpleri biçimine dönüştürülür. Dağınık ve düzensiz olan veriler toplanarak yararlı ve düzenli şekle getirilir. Kirli ve gereksiz veriler silinir. Örneğin, aylık bazda kayıtları tutulan satışların, üçer, altışar aylık ya da yıllık olarak gösterilmesi gibi. Veri küpleri ise çok değşkenli birleştirilmiş bilginin saklandığı küplerdir. Örneğin bir firmanın satışı yapılan modelleri, renkleri ve mağazaları aynı küp üzerinde gösterilebilir (Han & Kamber, 2001, s. 145).
Veriyi birleştirme veya veri küpü
• Verilerden ilgisiz, az ilgili veya gereksiz olan değişkenlerin kaldırılmasıdır. Veri kümesi bazen, bir ürünün satışına ilişkin olarak düzenlenen bir veri kümesinde, tüketicilerin telefon numaraları veya e-mailleri gibi gereksiz olarak yüzlerce değişken içerebilir. Bu tür gereksiz değişkenler elde edilecek örüntüleri kalitesizleştirebileceği gibi veri madenciliği sürecinin yavaşlamasına da yol açacaktır (Han & Kamber, 2001, s. 145).
Boyut indirgeme
• Veri seti büyüklüğünü azaltmak amacı ile veri şifreleme veya veri dönüşümü ile yapılan işlemlerdir (Han & Kamber, 2001, s. 145).
Veri sıkıştırma
• Tüm veri kümeleri yerine onu temsil eden küme grupları kullanılır (Han & Kamber, 2001, s. 145).
Örnekleme
• Veriler tek tek değil genel kavramlarla ifade edilir (Han & Kamber, 2001, s. 145).
20
çözümlemenin hatalı sonuç çıkartmasına neden olabilmektedir. Verilerin dönüştürülmesi sayesinde veriler arasında çözümlenin etkilenmemesi sağlanmaktadır (Özkan, 2008, s. 61).
2.2.3.4.Modelin Kurulması
Modelin kurulması aşaması, verilerden anlamlı bilgileri çekmek için ileri çözümleme yöntemleri kullanıldığından veri madenciliğinin en gösterişli aşamasıdır. Veri madenciliği yardımıyla uygun teknikler kullanılarak farklı durumlar için sonuç üretilmektedir. (Olson & Shi, 2007, s. 185). Diğer bir ifadeyle anlatmak gerekirse model için kullanılacak algoritmanın hazırlanan veri üzerinde çalıştırılmasıdır.
Bu aşamada tanımlanan probleme en uygun modelin bulunabilmesi için çok sayıda modelin test edilmesi söz konusudur. Bu nedenle en iyi modele ulaşılıncaya kadar süreç devam eder. Model kuruluş süreci denetimli (supervised) ve denetimsiz (unsupervised) öğrenimin kullanıldığı modellere göre farklılık göstermektedir. Denetimli öğrenme diğer ismiyle örnekten öğrenmede, bir denetçi tarafında önceden belirlenen denetimli sınıflar birtakım kriterlere ayrılarak, her sınıf için çeşitli örnekler verilir. Amaç verilen örneklerden hareketle her bir sınıfa ilişkin özelliklerin bulunmasıdır. Öğrenme süreci tamamlandığında, tanımlanan kurallar verilen yeni örneklere uygulanır ve yeni örneklerin hangi sınıflara ait olduğu kurulan model tarafından belirlenir. Denetimsiz öğrenmede, kümeleme analizinde olduğu gibi ilgili örneklerin gözlemlenmesi ve bu özellikleri arasındaki benzerlikler doğrultusunda sınıfların tanımlanması amaçlanmaktadır (Yavuz, 2009).
Modellerin kurulması aşamasında kullanılan değişkenlerin arasındaki ilişki düzeyleri olması gerekenden fazla ise, daha anlamlı değeri modele almak sağlıklı olacaktır. Model seçimi yapıldıktan sonra eğer en doğru modelin kurulduğu düşünülüyorsa modelin değerlendirilmesi aşamasına geçilir (Ersöz, 2013, s. 83).
2.2.3.5.Modelin Değerlendirilmesi
Bu aşamada kurulan modeller karşılaştırılarak en iyi model seçilir. Kurulan modeller içinden en doğru sonucu verenin bulunabilmesi için bazı teknikler ve yöntemler geliştirilmiştir (Ersöz, 2013, s. 85). Modelin değerlendirilmesi aşamasında kullanılan en basit yöntem geçerlilik testleridir. Büyük veri yığınları için uygulanacak ise basit geçerlilik, küçük veri yığınları için uygulanacak ise çapraz geçerlilik testleri kullanılır. Basit geçerlilik testinde
21
verilerin %5 ile %33 arasındaki bir kısmı test verileri olarak ayrılır. Geri kalan kısım üzerinde modelin öğrenimi gerçekleştirildikten sonra, bu veriler üzerinde test işlemi yapılır. Bir sınıflama modelinde doğru olarak sınıflanan olay sayısının, tüm olay sayısına bölünmesi ile doğruluk oranı, yanlış olarak sınıflanan olay sayısını, tüm olay sayısına bölünmesi ile hata oranı hesaplanır (Doğruluk Oranı= 1- Hata Oranı) (Terzi, Küçüksille, Ergin & İlker, 2011). Çapraz geçerlilik testinde ise veriler rastgele iki eşit parçaya ayrılır. Ayrılan birinci parça üzerinde modelin eğitimi ve ikinci parça üzerinde modelin test işlemi yapılır. Daha sonra ise tam tersi yapılır. Yani; ikinci parça üzerinde modelin eğitimi ve birinci parça üzerinde modelin test işlemi yapılır. Her iki işlem sonucunda ulaşılan hata oranlarının ortalaması kullanılır (Yaralıoğlu, 2004, s. 24).
Kurulan modelin doğruluk derecesi ne kadar yüksek olursa olsun, gerçek dünyayı tam anlamıyla modellediğini garanti etmek mümkün değildir. Modeller yaygın kullanıma alınmadan önce sonuçlarının ve güvenirliliklerinin mutlaka kontrol edilmesi gerekmektedir. Gain, profit, lift ve response grafikleri bu aşamada yararlanılabilinecek uygulamalardandır (Ersöz, 2013, s. 89).
2.2.3.6.Modelin Uygulanması
Modelin uygulanması aşamasında, modelin doğruluğuna ve genelliğine ilişkin faktörlerle ilgilenilir. Kurulan ve geçerliliği kabul edilen model doğrudan bir uygulama olabileceği gibi, bir başka uygulamanın alt parçası olarak kullanılabilir. Zaman içerisinde bütün sistemlerin özelliklerinde ve dolayısıyla ürettikleri verilerde değişiklikler meydana gelebilir. Bu durum kurulan modellerin sürekli olarak izlenmesini ve gerekiyorsa yeniden düzenlenmesini gerektirecektir. Sonuç olarak ortaya çıkan model ihtiyaçları karşılayarak tatmin edici olmalıdır. (Ayık, Özdemir & Yavuz, 2007).
2.2.4. Veri Madenciliği Modelleri
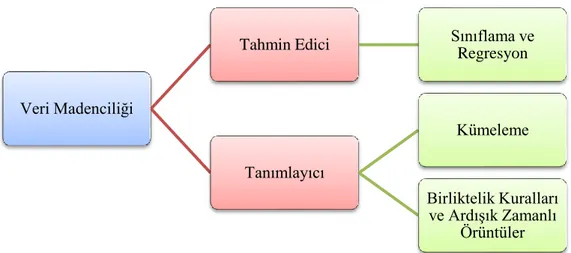
Veri madenciliği kullanıldığı alanlara göre değişik modellere ayrılmaktadır. Bu modeller, Tahmin Edici (Predictive) ve Tanımlayıcı (Descriptive) teknikler olmak üzere iki ana başlık altında incelenebilir (Ersöz, 2013, s. 97).
Tahmin edici modellerde, sonuçları bilinen verilerden hareket edilerek bir model geliştirilmesi ve kurulan bu modelden yararlanılarak sonuçları bilinmeyen veri kümeleri için
22
sonuç değerlerin tahmin edilmesi amaçlanmaktadır (Berry & Linoff, 2000, s. 100). Tanımlayıcı modellerde ise, karar vermeye rehberlik etmede kullanılabilecek mevcut verilerdeki örüntülerin tanımlanması sağlanmaktadır (Kaya & Köymen, 2008). Örüntü, bir veri tablosunda iki ya da daha fazla sütununda aynı değeri bulunduran satırlar olarak tanımlayabiliriz (Azmy, 2004).
Tahmin edici modeller şu sorunun yanıtını ararlar: “Takım bu sene şampiyon olmuş mudur?” ya da “Takım bu sezon kaç galibiyet alabilir?”
Tanımlayıcı bir model ise daha çok veriler arasındaki gizli kalmış ilişkileri ortaya çıkarırlar ve genel olarak şu sonucu elde ederler: “Krampon alan bir müşterinin, futbol topu alma olasılığı diğerlerinden 3 kat daha fazladır.” Ya da “60.000 TL ile 90.000 TL arasında geliri olan aileler; yılda iki ya da daha fazla uluslararası müsabakalara bilet alan ailelere, aylık 40.000 ile 60.000 TL arasında gelir olan ailelerden daha çok benzerler.” (Bounsaytip’ den aktaran Silahtaroğlu, 2013, s. 29).
Veri madenciliğinde kullanılan algoritma, teknik ve modeller bilgisayar yazılımları olduğu içi her ne kadar matematiksel ve algoritmik olarak birbirlerinden ayrılsalar da bazı ortak özelliklere sahiptirler; bu özelliklerden biri yazılımların öğrenme işlemidir. Yazılımlar kendilerine giriş olarak verilen veriler sayesinde değişik algoritmalarla bazı sonuçlar ve kurallar çıkarırlar. Bu inceleme işlemine “öğrenme” denir. Daha sonra, bu çıkarımlar verilerin diğer kısmına uygulanarak sınanırlar. Yazılım bir nevi kendi kendini sınav yapar ve ne kadar öğrendiğini sınar. Bulduğu sonuca göre gerekirse kurallarını günceller. Güncellenen bu uygulamaların yeni bulguların ayrı bir işlemle yeniden doğrulanmasına “doğrulama” denir. Daha sonra “aşırı öğrenme” olup olmadığını kontrol eder. Aşırı öğrenme, algoritmanın çıkardığı kuralların sadece üzerinde çalıştığı veriler için geçerli olması, dışarıdan başka veriler eklendiğinde, mevcut kuralların geçersiz sayılması durumudur. Bu durumda, üzerinde çalışılan verilerle denendiğinde tam sonuca ulaşan çıkarım ve kurallar, aynı performansı alakasız veriler üzerinde gösteremezler (Silahtaroğlu, 2013, s. 30).
23
Şekil 5. Veri madenciliği modelleri ve görevleri
2.2.4.1.Sınıflama (Classification) ve Regresyon (Regression)
Sınıflandırma kavramı, veriyi, tanımlanan sınıflara dağıtmak ya da sınıflara ayırmaktır. Burada ilgilenilen husus verinin bir sınıfa atanıp atanamamasıdır (Levent, 2016). Sınıflandırma kategorik değişkenler için kullanılır. Örneğin, Evet/Hayır, çok iyi- iyi- orta gibi değişkenler veya 1-5 gibi çoktan seçmeli cevaplar içeren değişkenler için kullanılır (Nisbet vd., 2009). Regresyonda ise süreklilik gösteren değerleri tahmin etmek amacıyla kullanılan bir yöntemdir (Ayık vd., 2007). Sınıflandırmada kategorik değerlerin tahmini yapılırken, regresyon da ise süreklilik gösteren değerlerin tahmini yapılır. Örneğin bir sınıflama modeli spor ürünlerini spor branşlarına göre kategorize etmek amacıyla kurulurken, regresyon modeli ise geliri ve mesleği verilen potansiyel müşterilerin spor ürünleri alırken yapacakları harcamaları tahmin etmek için kurulabilir (Özekeş & Çamurcu, 2002).
Veri Madenciliği
Tahmin Edici Sınıflama ve
Regresyon Tanımlayıcı Kümeleme Birliktelik Kuralları ve Ardışık Zamanlı Örüntüler
24
Sınıflama ve regresyon modellerinde kullanılan başlıca teknikler ve algoritmalar;
Şekil 6.Sınıflama ve regresyon teknikleri
Bu çalışmada veri madenciliği yöntemlerinden olan “yapay sinir ağları” ve “lojistik regresyon” analizleri kullanılmıştır. Bu bölümde yapay sinir ağları ve lojistik regresyon analizleri anlatılacaktır.
2.3.Yapay Sinir Ağları
Yapay sinir ağları; insan beyninin çalışma sisteminin yapay olarak benzetimi çabaları sonucu ortaya çıkmış, beynin özelliklerinden olan öğrenme yolu ile yeni bilgiler oluşturabilme, türetebilme ve keşfedebilme gibi yetenekleri yardım almadan kendiliğinden gerçekleştirmek amacıyla ortaya çıkmış bilgisayar sistemleridir (Kantardzic, 2011, s. 199).
Bir başka tanıma göre yapay sinir ağları; insan beyninin sinir ağlarından esinlenerek geliştirilmiş, yapay sinir hücrelerinin birbirleriyle çeşitli şekillerde bağlanmasıyla ve katmanlardan oluşan bilgisayar programlarıdır (Silahtaroğlu, 2008, s.66).
Geleneksel analiz yöntemlerine kıyasla yapay sinir ağları doğrusal olmayan problemleri tahmin etmede daha kolay ve doğru sonuçlar vermektedir. Gene aynı şekilde yapay sinir ağlarıyla çok sayıda problem çok hızlı bir şekilde çözümlenebilmektedir. Yapay sinir hücreleri aynı anda çalışabileceği gibi birbirinden bağımsız olarak da çalışabilirler. Yapay
Sınıflama ve Regresyon Yapay Sinir Ağları Lojistik Regresyon Genetik Algoritmalar K- En yakın Komşu Naive- Bayes Sınıflayıcısı Karar Ağaçları
25
sinir hücrelerinin herhangi birindeki bir sorun ağın geri kalanını etkilememektedir (Esen, 2009).
2.3.1.Yapay Sinir Ağlarının Yapısı
Yapay sinir ağları çok sayıda katmandan ve çok sayıda yapay sinir hücresinden oluşur. Yapay sinir ağları giriş katmanı, gizli katman ve çıkış katmanı olmak üzere üç bölümden oluşur. Giriş katmanından giren giriş değişkenleri buradan geçerek gizli katmana gelir ve daha sonra çıktı katmanına iletilir (Silahtaroğlu, 2008, s.68).
Şekil 7. Yapay sinir ağı örneği
Girdi Katmanı: Bu tabakada, dışarıdan gelen girdileri alan nöronlar vardır. Girdi katmanı
sonuçların tahmin modellemesinde kullanılacak tüm alanları içerisinde barındırır (Yurtoğlu, 2005).
Ara (Gizli) Katman: Giriş katmanından gelen bilgiler bu tabakada işlenir. Girdi ve çıktı
tabakasında iki katman bulunurken, bu tabakada birden fazla katman bulunabilir. Gizli tabaka çok sayıda nöron içerir ve bu nöronlar ağ içerisindeki diğer nöronlarla bağlantılıdır (Silahtaroğlu, 2008, s. 70).
Çıktı Katmanı: Girdi tabakasından alınan girişler, gizli tabakaya iletilir. Daha sonra gizli
tabakaya gelen girdiler gizli tabaka ile çıkış tabakası arasındaki bağlantı ağırlıkları ile çarpılarak çıktı tabakasına iletilir. Çıktı tabakasına gelen girişler sinirler tarafından toplanarak uygun bir çıktıya dönüştürülür (Tosun, 2007).
26
2.3.2.Yapay sinir Ağlarının Sınıflandırılması
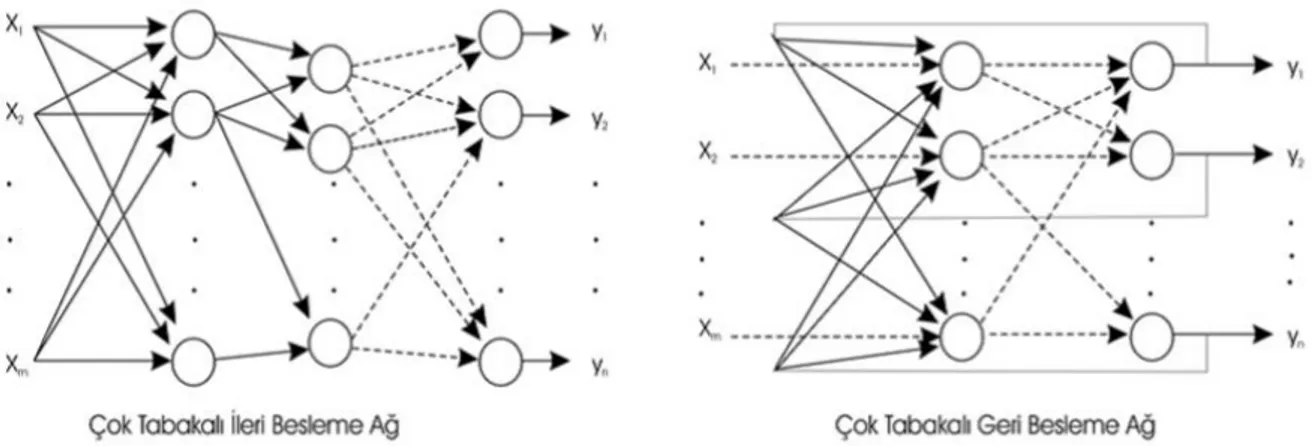
Yapay sinir ağları işleyiş şekillerine göre geri beslemeli (feed back) ve ileri beslemeli (feed forward) ağlar olmak üzere ikiye ayrılır (Gülseçen, 1993).
2.3.2.1.Geri Beslemeli (Feed Back) Yapay Sinir Ağları
Geri beslemeli Yapay Sinir Ağlarında, en az bir hücrenin çıkışı kendisine ya da diğer hücrelere giriş olarak verilir ve genellikle geri besleme bir geciktirme elemanı üzerinden yapılır. Geri besleme, bir katmandaki hücreler arasında olduğu gibi katmanlar arasındaki hücreler arasında da olabilir. Bu ağ yapılarında nöronların çıkışı sadece o anki giriş değerine bağlı değildir önceki giriş değerlerinden de etkilenirler. Bu sebeple, bu ağ yapısı özellikle tahmin etme için uygundur. Bu yapısı ile geri beslemeli yapay sinir ağları, doğrusal olmayan dinamik bir davranış gösterir. Dolayısıyla, geri beslemenin yapılış şekline göre farklı yapıda ve davranışta geri beslemeli YSA yapıları elde edilebilir (Çırak, 2012). Radyal tabanlı fonksiyon (Radial Basis Function) geri beslemeli ağlara örnektir.
2.3.2.2.İleri Beslemeli (Feed Forward) Yapay Sinir Ağları
İleri beslemeli ağlar yapay sinir ağlarının en ilkel ve en basit yapısını oluştururlar. Bu ağ yapısında sinyaller tek yönlü olarak girdi katmanından çıktı katmanına doğru ilerlerler. Ağ çıktısı sadece ağa giren girdilere bağlıdır. Bir katmandan elde edilen çıktı, aynı katmandaki sinirleri etkilemez (Burmaoğlu, 2009). İleri beslemeli yapay sinir ağları hem etkili hem de çok kullanışlı olmalarından dolayı en çok kullanılan ağ türüdür. En büyük özellikleri doğrusal olmayan yapı içeren problemlerde etkili olmasıdır. Çok katmanlı algılayıcı (Multilayer Perseptron- ÇKA ) ileri beslemeli ağlara örnektir. Şekil 8’ de çok tabakalı ileri ve geri beslemeli sinir ağları gösterilmektedir.
27
Şekil 8. Çok tabakalı ileri ve geri beslemeli sinir ağları
Bu çalışmada İleri Beslemeli yapay sinir ağlarından çok katmanlı algılayıcı ve geri beslemeli yapay sinir ağlarından radyal tabanlı fonksiyon kullanılmıştır.
2.3.3.Yapay Sinir Ağlarında Öğrenme
Yapay sinir ağlarının en önemli ayırt edici özelliklerinden birisi öğrenme yeteneğine sahip olmadır. Öğrenme var olan örnekler arasındaki yapının iyi bir davranış göstermesini sağlayabilecek olan bağlantı ağırlıklarının hesaplanması olarak tanımlanabilir (Şen, 2004, s. 35).
Yapay sinir ağları gibi öğrenme yöntemleri örneklerden edindiği tecrübelerle öğrenmeye dayanmaktadır. Örneklerden öğrenmeyi bir olay hakkında gerçekleşmiş örnekleri kullanarak olayın girdi ve çıktıları arasındaki ilişkileri öğrenerek bu ilişkilere göre daha sonra kurulacak olan yeni örneklerin çıktılarını belirlemektir. Bu düşüncede bir olay ile ilgili örneklerin girdi ve çıktıları arasındaki ilişkinin olayın genelini kapsayacak bilgiler içerdiği kabul edilmektedir. Farklı örneklerin olayı farklı açılardan temsil ettiği varsayılmaktadır. Değişik örnekler kullanılarak olay farklı yönlerden öğrenilebilinecektir. Bu işlemlerde bilgisayara yalnızca örnekler gösterilmektedir. Başka herhangi bir ön bilgi verilmemektedir. Öğrenmeyi sağlayacak olan sistem aradaki ilişkiyi kendi algoritmasını kullanarak keşfetmektedir (Öztemel, 2006, s. 64).
Yapay sinir ağlarında işlemci elemanlar arasındaki bağlantıların ağırlık değerlerinin değiştirilmesine “ağın eğitilmesi” denir. İlk olarak rastgele atanan bu ağırlık değerleri sonradan ağa gösterilen örnekler sayesinde değiştirilmektedir. Bunu yapılma amacı, ağa