Privacy-preserving aggregate queries for optimal location selection
Tam metin
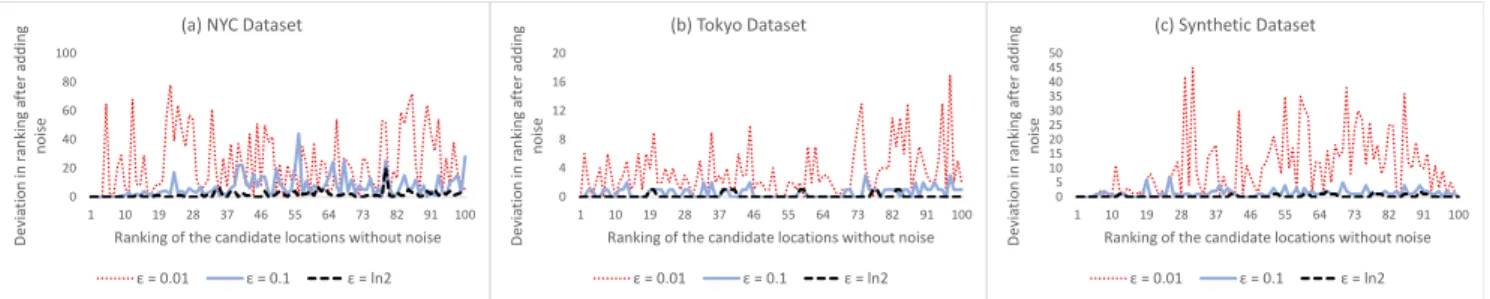
Şekil
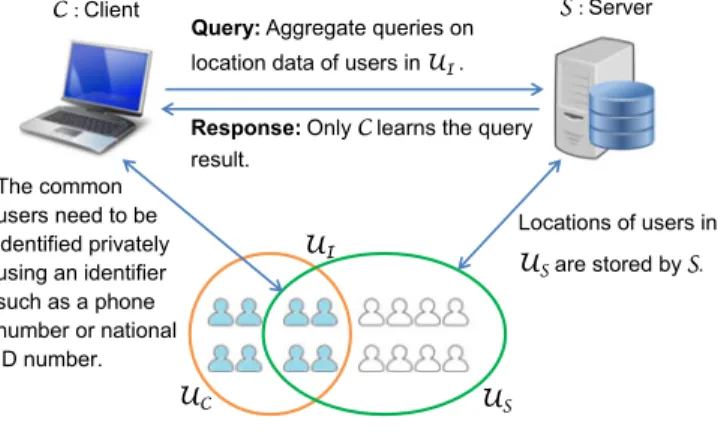

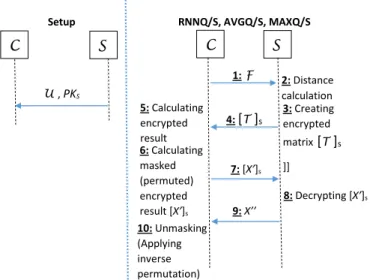
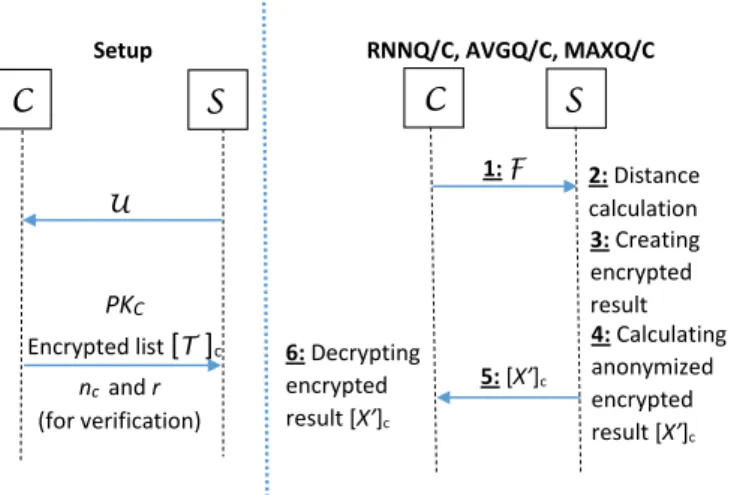
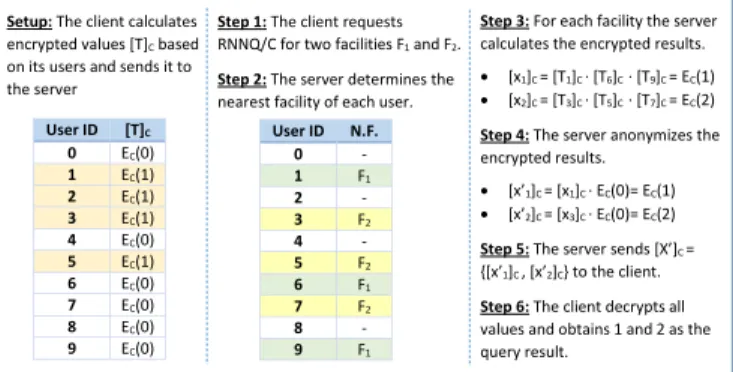

Benzer Belgeler
Eklenen öteki aygıt “Kozmik Kökenler Tayfçekeri” (Cosmic Origins Spectrograph - COS) olarak adlandırılıyor ve bu aygıtın kullanılmasıyla yapılacak gözlemlerin
Bu tür inanışlar yanında çeşitli kesimlere göre Büyük Ortadoğu Projesi (BOP); kısa hatlarıyla ABD'nin İslam coğrafyasını dizayn etmek, Arz-ı
By this device we are constantly reminded of: 1) the extent of the changes that had taken place in the West; and 2) the destiny of their eventual absorption into Ottoman life.
1970 The Five Man Army (MGM, 1970) Rejected on the grounds of dealing with the Mexican Revolution and hence propagating political, economic and social ideologies which contradict
[r]
Bilakis muamelatın yanısıra ibadat hükümlerini de, gerçek ve pratik hukuki meselelerin yanısıra nazari ve farazi meselelerin fetva- larını da ihtiva etmekte,
Taha
Bu çalışmanın amacı gri suyun tama- mının beton üretiminde kullanılmasına imkân veren CLR-S sistemi hakkında bilgi verilmesidir. CLR-S sistemi; gri suyun yoğunluğunu
