A Novel Family of Adaptive Filtering Algorithms Based on the Logarithmic Cost
Tam metin
Şekil


![TABLE I: h G (e t ) and h U (e t ) corresponding to the stochastic costs e 2 t and |e t |, where σ e 2 = E[e 2 t ] and λ = 2ασ 1 2 e = ακ](https://thumb-eu.123doks.com/thumbv2/9libnet/5911527.122526/6.918.71.851.60.1139/table-i-g-corresponding-stochastic-costs-ασ-ακ.webp)
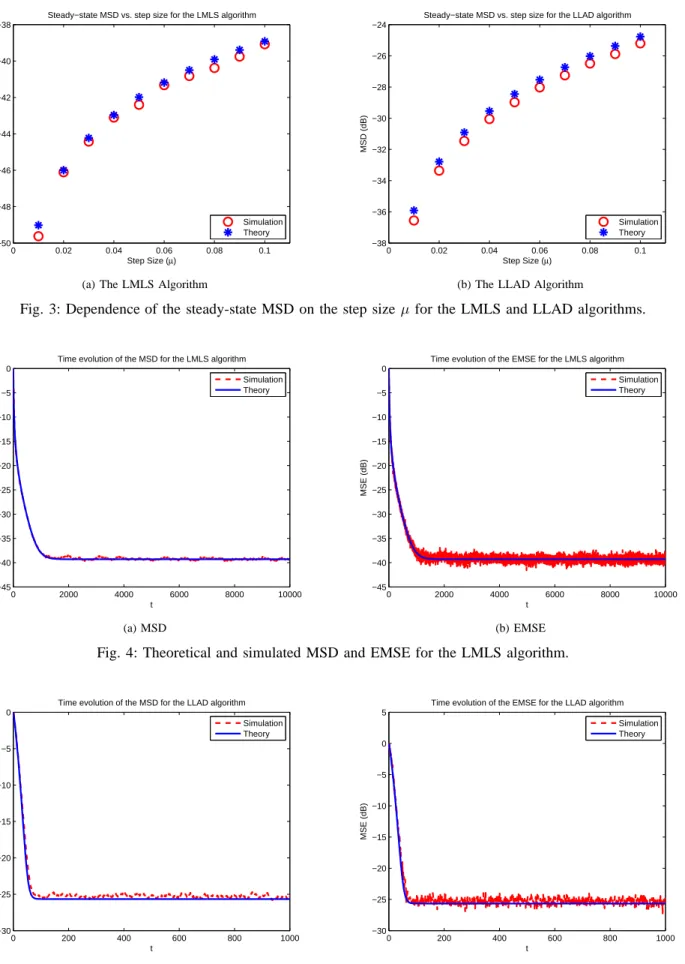


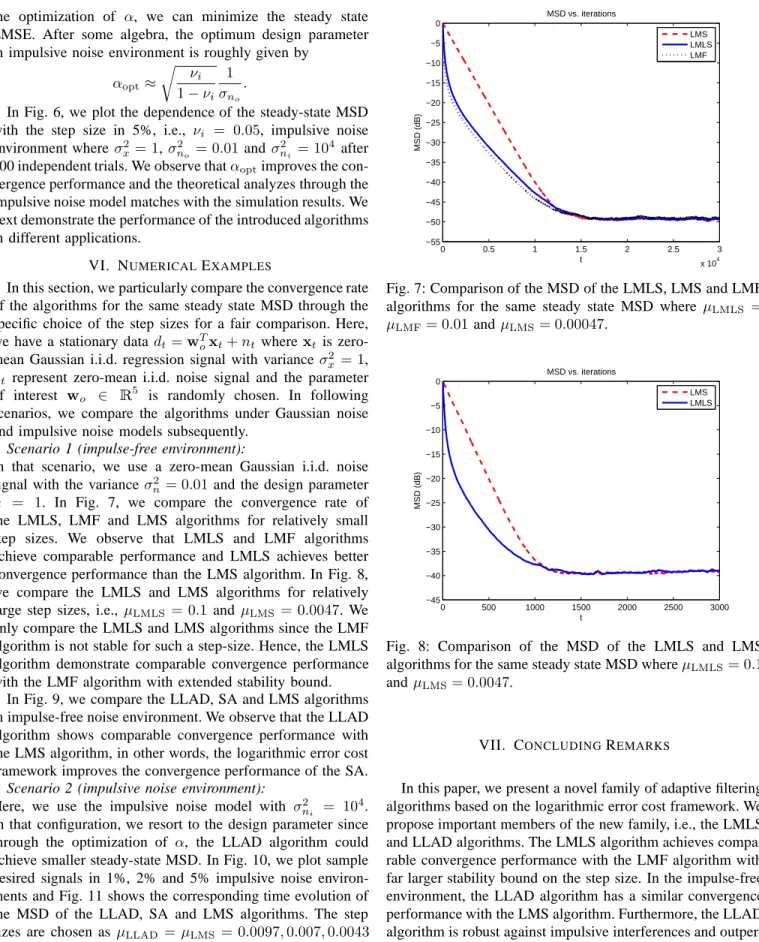
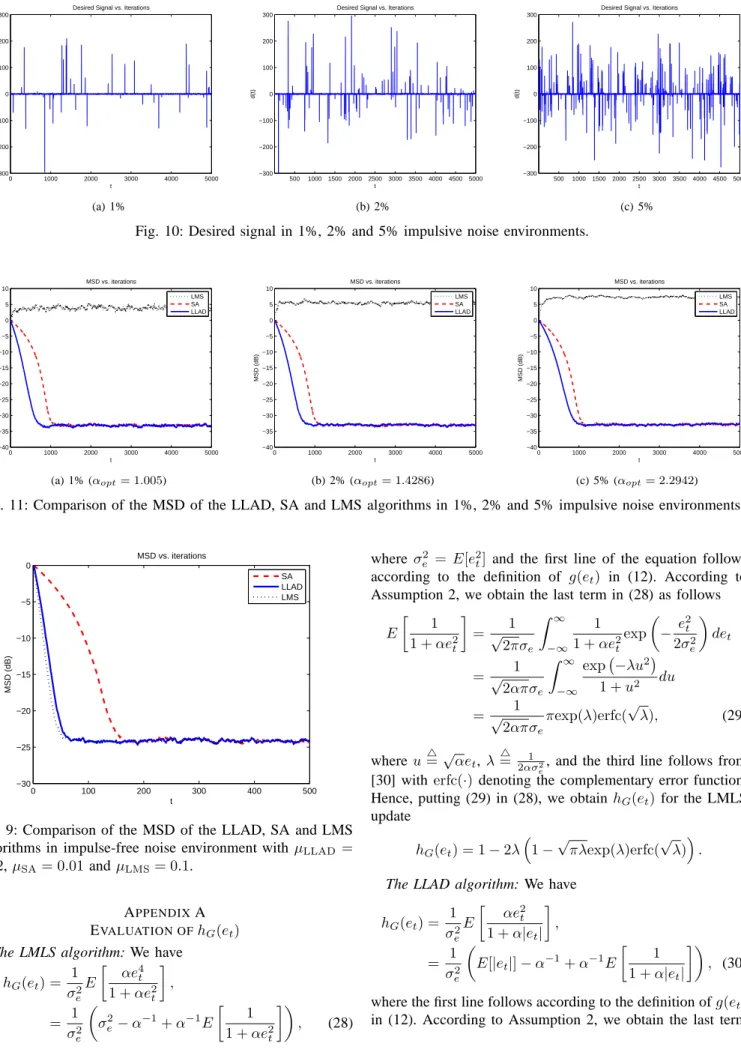
Benzer Belgeler
2 Temperature dependence of the frequency of the CH2 anti- symmetric stretching mode of pure DPPC multilamellar liposomes in the absence and presence of 20 mol% cholesterol and/or
Evidently there were conflicting versions of the Grand Siècle (and other pe- riods of French history, for example the sixteenth century) circulating in the 1830s and 40s, but
Last but not least, we derive new theoretical tools for ”Fractionally integrated process with non-stationary volatility” as the construction of the proposed unit root test
Günümüze gelebilen devrinin ve Mehmet A~a'n~n en önemli eserleri ise Edirneli Defterdar Ekmekçio~lu Ahmet Pa~a'n~n yapt~ r~ p Sultan I.Ah- met'e hediye etti~i Ekmekçio~lu Ahmet
In Figure 3.8 and Figure 3.9, COMSOL simulations for MUMPS diaphragm for Si are shown. Finite element analysis results are agreeable with the math- ematical model. Thus, the
Negative charges flow from metal electrode (ME) to ground and from ground to base electrode (BE) simulta- neously by contact charging; that is, the negative charge produced on
“Ülkücü” kadın imgesi Türk romanında “cinsiyetsizleştirilmiş” ve “idealist” bir kadın olarak karşımıza çıkarken, “medeni” kadın tezde ele
Sonuçlar, firmaların enerji sektöründeki finansal konumunu istedikleri düzeyde gerçekleştirebilmeleri için önemlidir. Ayrıca, sonuçlar sayesinde firma yöneticileri en
