Makine Öğrenmesi Sistemi Geliştirmek İçin Yazılım
Sürecini Uyarlamadaki Zorluklar: Bir Vaka Çalışması
Görkem Giray1[0000-0002-7023-9469], Murat Osman Ünalır2[0000-0003-4531-0566], Sena Koçer11 Kokteyl A.Ş., İstanbul
2 Ege Üniversitesi, Bilgisayar Mühendisliği Bölümü, İzmir
[email protected], [email protected], [email protected]
Özet. Makine öğrenmesi alanındaki gelişmeler yazılım mühendisliğini derinden etkilemektedir. Makine öğrenmesi algoritmalarının mevcut yazılım sistemlerine önemli yetenekler kazandırabileceği çok sayıda örnekte görülmüştür. Bundan dolayı birçok yazılım geliştirme takımı mevcut yazılım sistemlerine makine öğ-renmesi yetenekleri kazandırmak için projeler başlatmıştır. Bu çalışmada Kok-teyl şirketinin makine öğrenmesi algoritmaları kullanarak tahmin yapabilen bir bileşen geliştirme projesinde yaşadığı deneyimler anlatılmaktadır. Bu deneyim-ler süreç, veri ve yetkinlikdeneyim-ler başlıkları altında incelenmiştir.
Anahtar Kelimeler: Makine Öğrenmesi, Yazılım Mühendisliği, Yazılım Geliş-tirme.
Challenges in Adapting Software Process for Developing
a Machine Learning System: A Case Study
Görkem Giray1[0000-0002-7023-9469], Murat Osman Ünalır2[0000-0003-4531-0566], Sena Koçer1 1 Kokteyl Corporation, Istanbul
2 Ege University, Computer Engineering Department, Izmir
[email protected], [email protected], [email protected]
Abstract. Developments in the field of machine learning have a profound im-pact on software engineering. It has been seen in many examples that machine learning algorithms can provide significant capabilities to existing software sys-tems. Therefore, many software development teams have initiated projects to provide machine learning capabilities to existing software systems. This study describes the experiences of Kokteyl Company in a component development project that can make predictions using machine learning algorithms. These ex-periences are examined under the titles of process, data and competencies.
Keywords: Machine Learning, Software Engineering, Software Development.
1
Giriş
Büyük verinin işlenebiliyor olması, ucuz veri depolama imkanlarının, esnek hesapla-ma platformlarının ve algoritmik gelişmelerin bir araya gelmesi, çok sayıda hesapla-makine öğrenmesi uygulamasının hayatımıza girmesine yol açmıştır [1], [2]. Bu durum, daha önce görece birbirinden bağımsız gelişen yazılım mühendisliği ve makine öğrenmesi (ya da daha genel olarak yapay zeka) alanlarının birbirine yaklaşmasını zorunlu kıl-mıştır. Bu iki alanın yakınlaşması için “Software Engineering for Machine Learning Applications (SEMLA)” gibi organizasyonlar düzenlenmeye başlanmıştır; hem aka-demik çevrelerden hem de endüstriden uzmanların takip ettiği IEEE Software gibi dergiler yapay zeka ve yazılım mühendisliği alanlarının kesişiminde neler yapılabile-ceği konusunda çalışmalarını paylaşmaları için araştırmacılara çağrıda bulunmuştur (IEEE Software dergisinin 2019 yılındaki bildiri çağrısı: The AI Effect: Working at the Intersection of AI and Software Engineering).
Makine öğrenmesi alanındaki gelişmeler ile paralel olarak Kokteyl şirketi de mev-cut reklam aracısı yazılımına (RAY) makine öğrenmesi yetenekleri kazandıracak bileşenler geliştirmek amacıyla bir araştırma ve geliştirme projesi başlatmıştır. Bu bildiride, proje kapsamında makine öğrenmesi yeteneklerine sahip bileşenler geliştir-mek için şirketin mevcut yazılım mühendisliği sürecinin nasıl değiştirildiği ve bu değişiklikleri yaparken karşılaşılan zorluklar anlatılmaktadır.
2
İş Probleminin Tanımı
Bir reklam aracısı, bir uygulamaya, yani yayıncıya, reklam sağlarken, hangi reklam ağlarından hangi sırada reklam talep edeceğine dair bir karar verir. Bu kararı verirken uygulamanın reklam gelirini (aynı zamanda da kendi reklam gelirini) azami seviyeye çıkarmayı hedefler. Bunun için de reklam gösteriminden en fazla gelir sağlanabilecek reklam ağından başlayarak reklam talebinde bulunur. Mobil reklam sektöründe rek-lam gösterimi başına geliri ifade etmek için eBGBM (Etkin Bin Gösterim Başına Maliyet; İngilizcesi: eCPM – Effective Cost per Mille) kavramı kullanılmaktadır. Mevcut durumda Kokteyl şirketinin Reklam Aracısı Yazılımında (RAY) gerçekleşe-cek eBGBM değerleri alan uzmanları tarafından sezgiye dayalı olarak tahmin edil-mektedir. eBGBM değerini etkileyebilecek değişkenler tespit edilerek, bu değişken-lerle eBGBM arasındaki örüntülerin makine öğrenmesi algoritmalarıyla tespit edilme-si mümkün görünmektedir [3–6]. Dolayısıyla mevcut RAY’ye makine öğrenmeedilme-si yetenekleri kazandırılarak eBGBM tahmini yapan bir bileşen eklemek için bir proje başlatılmıştır.
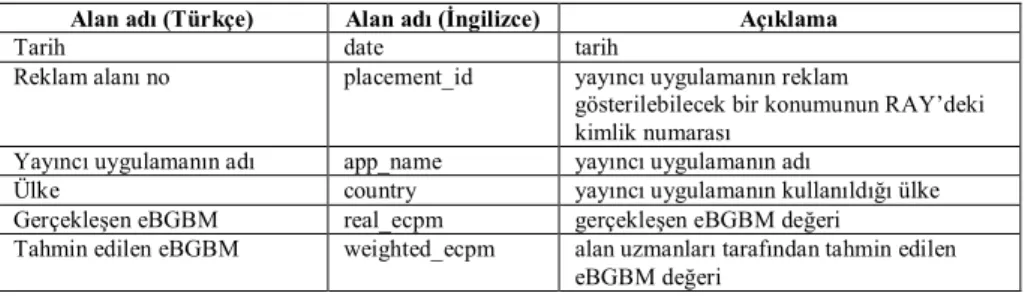
Gerçekleşen eBGBM değerleri ve bağlantılı veriler RAY’de Tablo 1’de gösterilen alanlarda saklanmaktadır. Her yayıncı uygulamanın her bir reklam alanı için ülke bazında günlük olarak gerçekleşen ve daha önce tahmin edilen eBGBM değerleri RAY tarafından kaydedilmektedir. Her ülkede mobil uygulamaların kullanım dina-miklerinin farklı olması nedeniyle eBGBM değerleri ülke bazında ayrı ayrı tahmin
edilmektedir. Bunun yanında reklam ağları da her yayıncı uygulama için ülke bazında gerçekleşen eBGBM değerlerini reklam aracılarıyla paylaşmaktadır.
Tablo 1. eBGBM değerlerinin ve bağlantılı verilerin saklandığı alanlar ve açıklamaları
Alan adı (Türkçe) Alan adı (İngilizce) Açıklama
Tarih date tarih
Reklam alanı no placement_id yayıncı uygulamanın reklam
gösterilebilecek bir konumunun RAY’deki kimlik numarası
Yayıncı uygulamanın adı app_name yayıncı uygulamanın adı
Ülke country yayıncı uygulamanın kullanıldığı ülke
Gerçekleşen eBGBM real_ecpm gerçekleşen eBGBM değeri
Tahmin edilen eBGBM weighted_ecpm alan uzmanları tarafından tahmin edilen eBGBM değeri
Örnek olarak bir yayıncı uygulama için (uygulamanın adı gizlilik nedeniyle verilme-miştir) üç günde, dört ülkede gerçekleşen ve daha önce tahmin edilen eBGBM değerle-ri Tablo 2’de göstedeğerle-rilmektedir.
Tablo 2. Örnek eBGBM değerleri ve bağlantılı veriler
Tarih Reklam alanı no Uygulamanın adı Gerçekleşen eBGBM
Tahmin edilen
eBGBM Ülke
08-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 1,280701754 0,012145187 BR 09-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 0,482967144 0,240236608 BR 10-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 0,769817073 0,323807174 BR 08-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 5,929345644 0,026019300 DE 09-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 1,026119403 0,429765486 DE 10-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 1,941533370 0,460431981 DE 08-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 6,718092567 0,021978022 FR 09-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 0,885636856 0,549004147 FR 10-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 2,264134582 0,626127083 FR 08-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 1,640059765 0,005023753 TR 09-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 0,515668347 0,561521377 TR 10-09-18 00a78a52-7572-4ab6-863c-df5eb77ebe99 yayıncı uygulama 0,684581689 0,535929221 TR
eBGBM tahmini yapan bileşenin görevi reklam alanı no, uygulama, ülke gibi özellik-lerden yola çıkarak gelecekte gerçekleşecek eBGBM için en iyi tahmini yapmaktır. Bu bileşen bu tahminleri ne kadar iyi yaparsa hem yayıncı uygulamaların hem de RAY’nin elde ettiği geliri artacaktır.
3
Yazılım Mühendisliği ve Makine Öğrenmesi
Geleneksel yazılım geliştirme ile makine öğrenmesi sistemlerinin geliştirilmesi ara-sında temel bir fark bulunmaktadır. Pedro Domingos bu farkı Şekil 1’deki gibi gös-termektedir [7]. Geleneksel yazılım geliştirmede, geliştirilecek sistem ile ilgili gerek-sinimler müşteri tarafından net olarak tanımlanabilmekte ve bu gerekgerek-sinimler yazılım geliştiriciler tarafından bir program olarak geliştirilebilmektedir. Bilgisayara veri ve geliştirilen program girdi olarak verilerek beklenen çıktılar elde edilmektedir. Bu süreç deterministik çıktılar üretmektedir. Diğer taraftan bazı problemler için (örneğin nesne tanıma) elde edilecek çıktının nasıl elde edileceği müşteri tarafından tanımla-namayacak kadar karmaşıktır. Bu tür problemlerin bazıları yüksek hacimli veri küme-lerindeki saklı desenleri makine öğrenmesi algoritmaları yardımıyla bularak çözüle-bilmektedir. Bir makine öğrenmesi sisteminin geliştirilmesi sürecinde bilgisayara veri ve elde edilmek istenen çıktı örnekleri girdi olarak verilerek bilgisayarın bir model (aşağıdaki şekilde program olarak adlandırılmıştır) üretmesi beklenmektedir. Aslında bu model, veri kümesi ve çıktı arasındaki bağlantıları, örüntüleri keşfetmekte ve böy-lece sisteme veriböy-lecek yeni veri için modeli kullanarak çıktı için iyi bir tahmin yap-maya çalışmaktadır. Böyle bir sistem için başarımın her zaman yüzde yüz olmasını beklemek mümkün değildir [8]. Bilgisayar Veri Program Çıktı Bilgisayar Veri Çıktı Program
Şekil 1. Geleneksel yazılım geliştirme (solda) ve makine öğrenmesi sistemi geliştirme (sağda).
Geleneksel yazılım geliştirme ve makine öğrenmesi sistemlerinin geliştirilmesi ara-sındaki bu temel farktan dolayı çeşitli problemler ortaya çıkmaktadır. Özellikle maki-ne öğrenmesi yetemaki-neklerinin sağladığı faydalar yazılım endüstrisinde çalışan birçok şirketin ilgisini çekmiştir. Bunun sonucunda geleneksel yazılım geliştiren bazı takım-lar makine öğrenmesi yetenekleri barındıran bileşenler geliştirmeye başlamıştır. Bu proje kapsamında da böyle bir durum söz konusudur ve bundan dolayı edinilen dene-yimler ve yaşanan zorluklar bir sonraki bölümde anlatılmaktadır.
4
Makine Öğrenmesi Sistemi Geliştirme ile İlgili Zorluklar
Proje kapsamında karşılaşılan zorluklar üç başlık altında incelenmiştir: (1) süreç, (2) veri, (3) yetkinlikler ile ilgili zorluklar.4.1 Süreçle İlgili Zorluklar
Yazılım geliştirme sürecindeki etkinlikler gereksinim mühendisliği, analiz ve tasarım, geliştirme, doğrulama ve geçerleme temel başlıkları altında incelenebilir. Bir yazılım
sistemi kullanılmaya başlandıktan sonra da bakım ile ilgili etkinlikler devreye girmek-tedir. Bu etkinliklerin nasıl gerçekleştirilmesi gerektiğini belirten, bu etkinlikler ara-sındaki ilişkileri tanımlayan çok sayıda yazılım geliştirme süreç modeli önerilmiştir. Her şirketin içinde bulunduğu koşullar farklı olduğu için şirketlerin kendi bağlamları-na uygun bir yazılım geliştirme süreci tasarlamaları gerekmektedir [9]. Kokteyl şirke-tinin mevcut yazılım geliştirme süreci [10] çalışmasında anlatılmaktadır.
RAY için eBGBM tahminini makine öğrenmesi algoritmaları kullanarak yapan bir bileşenin geliştirilmesi sürecinde mevcut süreçte çeşitli uyarlamalar yapılmak zorunda kalınmıştır. Bunlardan ilki gereksinimlerin belirlenmesi adımında olmuştur. Gelenek-sel bir yazılımın geliştirilmesi sürecinde gereksinimlerin net biçimde ortaya konulma-sı beklenmektedir [11]. Ancak makine öğrenmesi algoritmakonulma-sı kullanan bir bileşeni geliştirme sürecinde gereksinimlerin her açıdan net olarak tanımlanabilmesi mümkün değildir. Bunun nedeni algoritmaların eldeki veriye ve birçok parametreye göre farklı davranışlar sergilemesidir. Bu proje kapsamında üst seviye gereksinim olarak eBGBM değerinin mevcut tahmin bileşenine göre daha başarılı tahminler yapan bir bileşen geliştirilmesi olarak belirlenmiştir. Bileşenin geliştirilmesi sonrasında geçer-leme için kök ortalama kare hatası metriğinin kullanılmasına karar verilmiştir [12].
Gereksinimlerin sahip olması istenen önemli özelliklerinden birisi de gereksinimin ne kadar sürede gerçeklenebileceğinin tahmin edilebilir olmasıdır [13]. Ancak makine öğrenmesi algoritmalarının bir problemi çözmek için kullanılması sürecinde çok sayı-da belirsizlik bulunmaktadır. Problemi çözme süreci belirsiz sayısayı-da yineleme adımın-dan oluşmaktadır ve sonuçların tahmin edilmesi çok zordur.
Gereksinimlerin belirlenmesi sürecindeki bir başka zorluk gereksinimlerin belge-lenmesi konusunda yaşanmıştır. Her ne kadar şirket çevik yöntemlerin önerdiği pra-tikleri uygulasa da projenin Tübitak tarafından desteklenmesi nedeniyle belirli bir seviyede belgeleme yapılması ihtiyacı doğmuştur. Gereksinimlerin belgelenmesi için Wiegers’ın önerdiği gereksinim belgeleme şablonu [11] kullanılmıştır. Bu şablondaki başlıklar geleneksel yazılım gereksinimleri için yeterli olurken makine öğrenmesi ile ilgili işlevler için şablon üzerinde değişiklikler yapılması gerekmiştir.
Bir başka zorluk ise doğrulama ve geçerleme aşamasında yaşanmıştır. Makine öğ-renmesi uygulamalarının test edilmesi için geleneksel test tekniklerinin yeterli olma-dığı ve bu konuda başka tekniklerin geliştirilmesi gerektiği araştırmacılar tarafından belirtilmiştir [14]. Doğrulama (geliştirilen işlevin gereksinim belirtimleriyle ne ölçüde uyumlu olduğunun kontrol edilmesi) için eldeki veri üç kümeye ayrılmıştır [8]. Birin-ci küme makine öğrenmesi algoritmalarının çalıştırılarak bir model elde edilmesi için kullanılmıştır. İkinci veri kümesi elde edilen modelin parametrelerinin optimize edil-mesi ve modele özellik ekleme/çıkarma işlemlerinin yapılması için kullanılmıştır. Üçüncü veri kümesi ise elde edilen modelin başarımının ölçümü için yani doğrulama için kullanılmıştır. Şekil 2’de model geliştirme ve doğrulama için kullanılan üç veri kümesi gösterilmektedir. Bu çalışmadaki önemli hususlardan birisi hazırlanan veri kümelerinin zaman boyutunun eldeki problemin çözümü için önemidir. eBGBM tah-mini zamana bağlı bir problem olduğu ve geçmişte oluşan değerler ve çeşitli paramet-reler kullanılarak gelecekteki eBGBM değerleri tahmin edilmeye çalışıldığı için oluş-turulan veri kümelerinin zaman aralıkları buna uygun ayarlanmıştır. Model doğrulama veri kümesindeki verilerin zaman aralığı model eğitme ve optimizasyon veri
kümesi-nin zaman aralığını takip etmektedir. Böylece gerçekte modelin gelecek için yapacağı tahmin işlemi simüle edilmiştir.
Model eğitme veri kümesi (training set) Model optimizasyon veri kümesi (dev set) Model doğrulama veri kümesi (test set) zaman
Şekil 2. Model doğrulama için kullanılan üç veri kümesi.
Geleneksel yazılım sistemleri için geçerleme (geliştirilen işlevin kullanıcı gereksinim-leriyle ne ölçüde uyumlu olduğunun kontrol edilmesi) işlemi genellikle kullanıcı ka-bul testleri ile yapılmaktadır. Ancak bu proje kapsamındaki eBGBM tahmin proble-minin çözümü için geliştirilen bileşenin canlı ortamdaki başarımının gözlemlenmesi gerekmektedir. Geliştirilen bileşenin davranışı deterministik olmadığı için geleneksel yazılım sistemleri için yapılan kullanıcı kabul testi bu durumda aynı faydayı sağla-mamaktadır. Bunun için bu proje kapsamında eBGBM tahminini yapan bileşenin canlı ortamda yapılan tahminlerin belirli bir yüzdesini yapacak şekilde kullanıma açılmasına karar verilmiştir.
4.2 Veriyle İlgili Zorluklar
Geleneksel yazılım sistemleri için de veri önemli bir yere sahiptir. Yazılım geliştirici tarafından belirlenen ve kodlanan kurallar veri üzerinde işletilmektedir. Diğer taraf-tan, makine öğrenmesi bileşenleri için veri daha da belirleyici öneme sahiptir [15]. Bunun nedeni makine öğrenmesi uygulamalarında oluşturulan modellerin makine öğrenmesi algoritmalarından çok o modeli eğitmek ve optimize etmek için kullanılan veri kümesine bağlı olmasıdır [16]. Bazı genel problemler için genel amaçlı veri kü-meleri model geliştirmek için kullanılabilir. Örneğin, bir nesne tanıma sistemi geliş-tirmek için ImageNet veri kümesi [17] kullanılabilir. Bu proje kapsamındaki projede ise eBGBM tahmin etme problemi için kamuya açık bir veri kümesi bulunmamakta-dır. Diğer taraftan, şirketin veri deposunda üç yıl öncesine kadar mevcut tahmin algo-ritması ile tahmin edilen ve gerçekleşen eBGBM değerleri bulunmaktadır. Bu veri kümesi kullanılarak bir model geliştirilmesi ve doğrulanması mümkün olmuştur.
Veri ile ilgili karşılaşılan zorluklardan biri veriyi tanımlayan bir üstveri deposunun olmaması noktasında yaşanmıştır. Modeli geliştirecek takım, verinin ne anlama geldi-ği ve veri alanları arasındaki ilişkiler hakkındaki bilgileri ancak alan uzmanları ile çalışarak zaman içinde öğrenmiştir. Bu deneyim de veriyi tanımlayan üstverinin öne-mini makine öğrenmesi uygulamaları için de göstermektedir.
Veri ile ilgili karşılaşılan bir başka zorluk ise model geliştirme sürecinde kullanılan veri kümelerinin versiyonlanmasıdır [18]. Model geliştirme ve doğrulama sürecinde kullanılan veri kümelerinin oluşturulan modellerle bağlantılı olarak uygun biçimde saklanması gerekmektedir. Bu proje kapsamında geliştirilen küçük çaptaki modeller için kullanılan ver kümeleri Excel dosyalarında saklanmaktadır. Ancak bu durum
sürdürülebilir değildir. Yüksek hacimli veri kümelerini ve bu veri kümeleriyle bağlan-tılı modelleri saklayacak bir çözümün geliştirilmesi projede henüz çözülemeyen zor-luklardan birisidir.
4.3 Yetkinliklerle İlgili Zorluklar
Makine öğrenmesi algoritmalarının kullanıldığı bileşenlerin geliştirilmesi için birta-kım yetkinlikler gerekmektedir. Makine öğrenmesi algoritmaları kütüphaneler şeklin-de geliştiricilerin kullanımına hazır olarak sunulsa da bu kütüphaneleri kullanmak için çeşitli yetkinliklere sahip olmak gerekmektedir. Makine öğrenmesi yeteneklerinin geliştirilmesi için gerekli yetkinlikler genellikle veri analitiği uzmanı, makine öğren-mesi uzmanı, veri bilimci gibi unvanlar altında toplanmaktadır [1], [18], [19], [20]. Bu roller altında toplanan sorumlulukların ve dolayısıyla sahip olunması gereken yetkinliklerin farklılaştığı görülmektedir [19], [20]. Bu proje kapsamında, bir veri analitiği uzmanı görev almaktadır. Veri analitiği uzmanı, temel istatistik ve matematik bilgisinin [21] yanında, makine öğrenmesi kütüphaneleri ve model geliştirmek için kullanılabilecek programlama dilleri (Python, R gibi) hakkında eğitim almıştır. Bunun yanında konu alanı uzmanları ile yakın çalışarak mobil reklamcılık sektörü ve bu sektörde oluşan verinin ve bilginin yorumlanması konusunda deneyim kazanmaktadır.
5
Sonuçlar
Bu çalışmada Kokteyl şirketinin makine öğrenmesi algoritmaları kullanarak gelecekte oluşacak eBGBM değerlerini tahmin eden bir bileşenin geliştirme sürecinde elde edilen deneyimler anlatılmaktadır. Gereksinimlerin belirlenmesi ve geliştirilen maki-ne öğrenmesi bileşeninin geçerlenmesi adımlarında gelemaki-neksel yazılım geliştirme sürecine göre farklılıklar gözlemlenmiştir. Model geliştirilirken kullanılan veri küme-lerinin modellerle bağlantılı olarak saklanması bir başka zorluk olarak karşımıza çık-maktadır. Ayrıca, geleneksel yazılım geliştirme kültürüne sahip bir takım içerisinde makine öğrenmesi ile ilgili yetkinliklerin geliştirilmesi bir başka zorluk olarak karşı-mıza çıkmaktadır.
Teşekkür
Bu çalışma TÜBİTAK’ın desteğiyle 3171053 numaralı proje kapsamında yapılmıştır.
Kaynakça
1. Pruss, L.: Infrastructure 3.0: Building blocks for the AI revolution. (2017).
https://venturebeat.com/2017/11/28/infrastructure-3-0-building-blocks-for-the-airevolution/, son erişim tarihi: 23 Haziran 2019.
2. Ozkaya, I. (2019). The Golden Age of Software Engineering [From the Editor]. IEEE Software, (1), 4-10.
3. E. Llach, “System for automatically selling and purchasing highly targeted and dynamic advertising impressions using a mixture of price metrics,” U.S. Patent Application No. 10/767,050, 2004.
4. B. O’Kelley, “Method and system for pricing electronic advertisements,” U.S. Patent App-lication No. 11/006,121, 2006.
5. A. Paunikar and M. Hochberg, “Dynamic pricing for content presentations,” U.S. Patent No. 8,706,547. 22, 2014.
6. O. Chapelle, E. Manavoglu, R. Rosales, “Simple and scalable response prediction for disp-lay advertising,” ACM Transactions on Intelligent Systems and Technology (TIST), vol. 5(4), Article 61, 2015.
7. Domingos, P. (2015). The master algorithm: How the quest for the ultimate learning mac-hine will remake our world. Basic Books.
8. Ng, A. (2017). Machine learning yearning. URL: http://www. mlyearning. org/(96). 9. Clarke, P., O’Connor, R.V.: The situational factors that affect the software development
process: towards a comprehensive reference framework. J. Inf. Softw. Technol. 54(5), 433– 447 (2012).
10. Giray, G., Yilmaz, M., O’Connor, R. V., & Clarke, P. M. (2018, September). The Impact of Situational Context on Software Process: A Case Study of a Very Small-Sized Com-pany in the Online Advertising Domain. In European Conference on Software Process Improvement (pp. 28-39). Springer, Cham.
11. Wiegers, K., & Beatty, J. (2013). Software requirements. Pearson Education.
12. Giray, G., Ünalır, M.O., & Tahmaz, Ş. (2019). Zaman Serisi Analizi için Hiper-Parametre Seçiminde Grid Arama Kullanımı: Reklam Aracısı Yazılımı ile Bir Örnek Durum Senar-yosu. International Data Science & Engineering Symposium – IDSES’19.
13. Essential Scrum: A Practical Guide to the Most Popular Agile Process, 1stEd., Kenneth S. Rubin, Addison-Wesley Professional, 2012.
14. Khomh, F., Adams, B., Cheng, J., Fokaefs, M., & Antoniol, G. (2018). Software Enginee-ring for Machine-Learning Applications: The Road Ahead. IEEE Software, 35(5), 81-84. 15. Amershi, S., Begel, A., Bird, C., DeLine, R., Gall, H., Kamar, E., Nagappan, N., Nushi, B.
& Zimmermann, T. (2019, May). Software engineering for machine learning: a case study. In Proceedings of the 41st International Conference on Software Engineering: Software Engineering in Practice (pp. 291-300). IEEE Press.
16. Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., ... & Dennison, D. (2015). Hidden technical debt in machine learning systems. In Advances in neural infor-mation processing systems (pp. 2503-2511).
17. Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., & Fei-Fei, L. (2009, June). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248-255). IEEE.
18. Simard, P. Y., Amershi, S., Chickering, D. M., Pelton, A. E., Ghorashi, S., Meek, C., Ra-mos, G., Suh, J., Verwey, J., Wang, M., & Wernsing, J. (2017). Machine teaching: A new paradigm for building machine learning systems. arXiv preprint arXiv:1707.06742. 19. Kim, M., Zimmermann, T., DeLine, R., Begel, A.: The emerging role of data scientists on
software development teams. In: Proceedings of the 38th International Conference on Software Engineering, pp. 96-107. ACM (2016).
20. Kim, M., Zimmermann, T., DeLine, R., Begel, A.: Data Scientists in Software Teams: Sta-te of the Art and Challenges. IEEE Transactions on Software Engineering. (2017). doi: 10.1109/TSE.2017.2754374
21. Waller, M. A., Fawcett, S. E.: Data science, predictive analytics, and big data: a revolution that will transform supply chain design and management. Journal of Business Logistics 34(2), pp. 77-84. (2013).