Slicing based code parallelization for minimizing inter-processor communication
Tam metin
Şekil
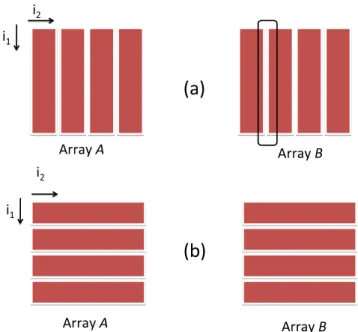
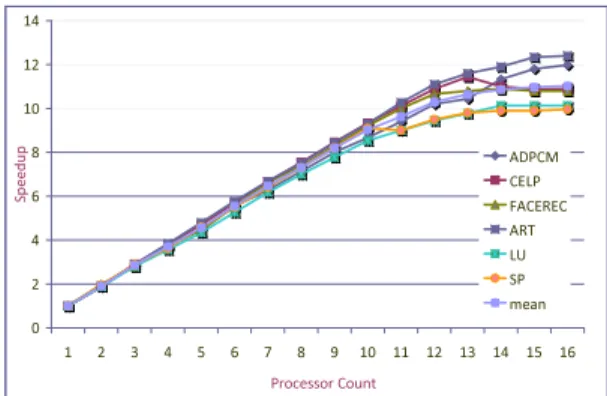
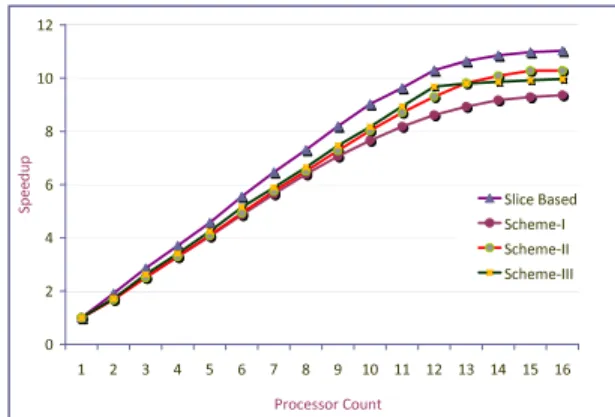
Benzer Belgeler
CHARACTERIZATION OF VIRGIN OLIVE OILS FROM AK DELICE WILD OLIVES (OLEA EUROPAEA L.
Mali yerelleşme ile aynı zamanda, seçilen yöneticilerin halka karşı sorumlu hale geldiği ve halkın da hesap sorabilme konusunda güçlendirilmiş olması (bilgi
Araştırmada FATİH Projesi matematik dersi akıllı tahta kullanımı seminerleri- nin Balıkesir merkez ve ilçelerde görev yapan lise matematik öğretmenlerinin etkileşimli
en temel ve en önemli dersler arasında yer almaktadır. Programlama Dilleri dersinde ise Algoritma konusu önemli bir yere sahiptir. Algoritma ve Akış diyagramları
Finally, I would like to thank all my friends, especially Ferruh and Bora, for their helps... It is known that the eigenfunctions of the continuous spectrum of
ELISA detection of IgG antibodies directed against mitochondrial carrier homolog 1 (Mtch1) in sera of neuro-Behçet's disease (NBD) patients, Behçet's disease patients with no
It has been demonstrated that although significant amount of mutual coupling reduction has been achieved by using the dumbbell DGS, the reflector and the cavity, no improvement has
(λ PL =548 nm) and mixed cyan- and green-emitting CdSe/ZnS core/shell nanocrystals (λ PL =490 and 548 nm, respectively) on near-UV LED (λ EL =379 nm) and (b) the total optical power
