Feature selection and discretization for improving classification performance on CAC data set
Tam metin
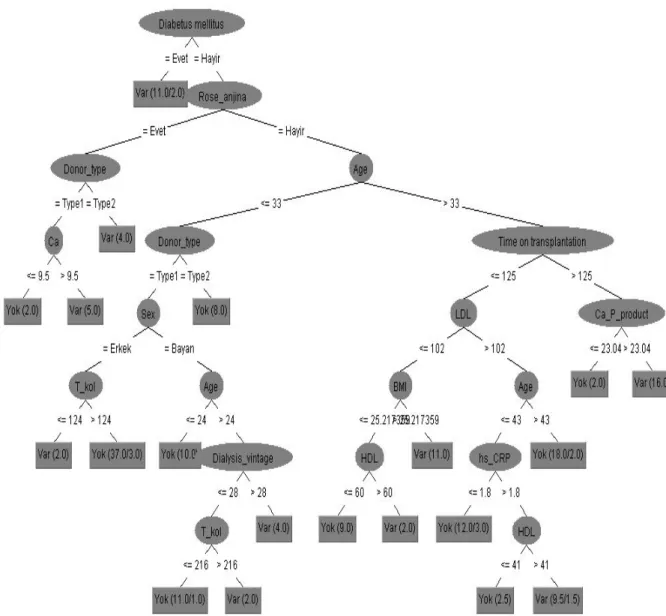
Şekil

Benzer Belgeler
After the subsetting, we compute the rounded mean of the combined fuel economy for the subset and store it in the object called mean.mpg.. After each loop we tell R to concatenate
He firmly believed t h a t unless European education is not attached with traditional education, the overall aims and objectives of education will be incomplete.. In Sir
After sorting all 1000 terms using in the selected-index list and 999 term pairs according to their ( ) in the pair-list, documents were represented in combination
olmaktan çok, Özön’ün uzun yıllar boyu yayımladığı çeşitli si nema kitaplarının yeni bir kar ması niteliği taşıyor. Ancak özel likle, yabana sinema
İşbirliğini sağlamak adına büyük gruplarla çalışılmalıdır (Y3, Y9) 2 İşbirliğini sağlamak adına küçük gruplarla çalışılmalıdır (Y1, Y2, Y6, Y12) 4
Peter Ackroyd starts the novel first with an encyclopaedic biography of Thomas Chatterton and the reader is informed about the short life of the poet and the
The objective of our study was to determine the prevalence, awareness, treatment, and control rates in a population (aged 25 or older) from Derince dis- trict of Kocaeli county,
Show the performance of the model by plotting the 1:1 line between observed and predicted values, by determining the Mean Square Error (MSE) and by calculating
