MAKİNE ÖĞRENME YÖNTEMLERİ İLE KARACİĞER HASTALIĞININ TEŞHİSİ
Özden Burcu KARSLI YÜKSEK LİSANS TEZİ
Matematik Anabilim Dalı-Bilgisayar Bilimleri Doç. Dr. Aytürk KELEŞ
AĞRI – 2019 (Her hakkı saklıdır.)
T.C.
AĞRI İBRAHİM ÇEÇEN ÜNİVERSİTESİ FEN BİLİMLERİ ENSTİTÜSÜ MATEMATİK ANABİLİM DALI
Özden Burcu KARSLI
MAKİNE ÖĞRENME YÖNTEMLERİ İLE KARACİĞER
HASTALIĞININ TEŞHİSİ
YÜKSEK LİSANS TEZİ
TEZ YÖNETİCİSİ Doç. Dr. Aytürk KELEŞ
.../…./20....
FEN BİLİMLERİ ENSTİTÜSÜ MÜDÜRLÜĞÜNE
Ağrı İbrahim Çeçen Üniversitesi Lisansüstü Eğitim-Öğretim ve Sınav Yönetme-liğine göre hazırlamış olduğum “...” adlı tezin tamamen kendi çalışmam olduğunu ve her alıntıya kaynak gösterdiğimi taahhüt eder, tezimin kâğıt ve elektronik kopyalarının Ağrı İbrahim Çeçen Üniversitesi Fen Bilimleri Enstitüsü arşivlerinde aşağıda belirttiğim koşullarda saklanmasına izin verdiğimi onaylarım.
Lisansüstü Eğitim-Öğretim yönetmeliğinin ilgili maddeleri uyarınca gereğinin yapılmasını arz ederim.
Tezimin tamamı her yerden erişime açılabilir.
Tezim sadece Ağrı İbrahim Çeçen Üniversitesi yerleşkelerinden erişime açılabilir.
Tezimin …… yıl süreyle erişime açılmasını istemiyorum. Bu sürenin sonunda uzatma için başvuruda bulunmadığım takdirde, tezimin tamamı her yerden erişime açılabilir.
[Tarih ve İmza] [Öğrencinin Adı Soyadı]
TEZ KABUL VE ONAY TUTANAĞI
FEN BİLİMLERİ ENSTİTÜSÜ MÜDÜRLÜĞÜNE
...danışmanlığında, ... tarafından hazırlanan bu çalışma .../.../... tarihinde aşağıdaki jüri tarafından. ... Anabilim Dalı’nda ...tezi olarak kabul edilmiştir.
Başkan : ………... İmza: ……….. Jüri Üyesi : ……….. İmza: ……….. Jüri Üyesi : ……….. İmza: ……….. Jüri Üyesi : ……….. İmza: ……….. Jüri Üyesi : ……….. İmza: ………..
Yukarıdaki imzalar adı geçen öğretim üyelerine ait olup;
Enstitü Yönetim Kurulunun …/…/201.. tarih ve . . . . / . . . . nolu kararı ile onaylanmıştır.
…. /……/……. Doç. Dr. İbrahim HAN
ii
ÖZET
YÜKSEK LİSANS TEZİ
MAKİNE ÖĞRENME YÖNTEMLERİ İLE KARACİĞER HASTALIĞININ TEŞHİSİ
Karaciğer hastalıkları dünya çapında oldukça yaygın görülen hastalıklardandır. Hem çok sık görülme hem de yüksek ölümle sonuçlanma oranı nedeniyle bu hastalıkların erken ve doğru teşhisi hayati önem taşımaktadır. Tıpta geleneksel teşhis yöntemleri hala kullanılmaktadır. Ancak bugün gelişen yapay zekâ teknolojileri sayesinde hastalık teşhis, tanı ve tedavi süreçlerinde hekimlere destek olacak güçlü araçlar sunulabilmektedir. Bu tez çalışmasında yapay zekânın bir alt alanı olan makine öğrenme algoritmaları karaciğer hastalıklarının teşhisi için kullanılmıştır.
Bu çalışmada WEKA veri madenciliği aracından faydalanılarak J48, Lojistik Model Ağacı (LMT), Decision Stump, Hoeffding Tree, REP Tree, Random Forest, Random Tree ve IBk makine öğrenme algoritmaları ile Karaciğer Hasta Veri Seti (ILPD) üzerinde çalışılmıştır. Amaç, bu algoritmalar ile en iyi teşhis sonucuna ulaşmaktır. Çalışmada alanyazından farklı veri önişleme işlemeleri de kullanılmıştır.
Çalışmanın birinci bölümünde karaciğer hastalıkları ve makine öğrenmesinin önemine vurgu yapılarak literatürdeki benzer çalışmalara yer verilmiştir. İkinci bölümde ise makine öğrenme ve veri madenciliği ile ilgili kuramsal temeller yer almıştır. Üçüncü bölümde; kullanılan veri seti hakkında ayrıntılı bilgiler verilmiş, uygulamadaki algoritmalar tanıtılmış ve verilerin önişlemlerden geçirilerek WEKA aracında algoritmalar ile nasıl kullanıldığı anlatılmıştır. Dördüncü bölümde elde edilen modellerin genel geçer sınıflandırma performansları değerlendirme ölçütlerine göre analiz edilmiştir. Beşinci ve son bölümde ise analizlerden elde edilen sonuçlar değerlendirilerek yorumlanmıştır.
Makine öğrenme algoritmalarından elde edilen en iyi sınıflama modelleri hastalık teşhis ve tedavileri için geliştirilecek akıllı sistemlerin çıkarım mekanizmalarını oluşturma potansiyeline sahiptir. Bu tez çalışmasından elde edilen bilgiler ışığında bu çalışma, hastane bilgi yönetim sistemlerine dâhil olan, laboratuvar sonuçlarına erişebilen ve karaciğer hastalıkları taramasını otomatik gerçekleştirerek doktorlara hastaları ile ilgili gerekli uyarılarda bulunabilen akıllı bir sisteme dönüştürülebilir. İlerleyen süreçte öngörülen bu sistemin kapsamlı bir sağlık projesi haline dönüştürülmesi hedeflenmektedir.
Bu çalışma karaciğer hastalıklarının erken teşhis ve tarama açısından kullanılan sınıflama algoritmaları ile karaciğer hastalıkları alanında hekimlere yardımcı olmak amacıyla karaciğer hastalığın teşhisi bakımından önem arz etmektedir.
iii
Anahtar Kelimeler: Karaciğer Hastalıkları, WEKA, Makine Öğrenme, Makine Öğrenme Algoritmaları, Veri Madenciliği
ABSTRACT
MASTER'S THESIS
DIAGNOSIS OF LIVER DISEASE WITH MACHINE LEARNING METHODS
Liver diseases are one of the common discomforts in all around the world. Early and accurate diagnosis of these diseases is of vital importance due to their very frequent occurrence and high mortality rate. Traditional diagnostic methods are still used in medicine. However, today, thanks to the emerging artificial intelligence technologies, powerful tools can be provided to support physicians in disease diagnosis, diagnosis and treatment processes. In this thesis, Machine learning algorithms, a subfield of artificial intelligence, have been used for the diagnosis of liver diseases.
In this study, using WEKA data mining tool, J48, Logistic Model Tree (LMT), Decision Stump, Hoeffding Tree, REP Tree, Random Forest, Random Tree and IBk machine learning algorithms and Liver Patient Data Set (ILPD) were studied. The aim is to achieve the best diagnostic result with these algorithms. The study also used data preprocessing processes different from literature were used.
The first part of the study emphasized the importance of liver diseases and machine learning and included similar studies in the literature. In the second part, theoretical foundations related to machine learning and data mining were included. In the third section, detailed information about the data set used, the algorithms in the application were introduced, and how the data was passed through preprocessing and used with the algorithms in the weka tool was explained. In the fourth chapter, the general valid classification performances of the obtained models are analyzed according to the evaluation criteria. In the fifth and final section, the results obtained from the analyzes were evaluated and interpreted.
The best classification models derived from machine learning algorithms have the potential to create inference mechanisms of intelligent systems to be developed for Disease Diagnosis and treatments. In the light of the information obtained from this thesis, this study can be transformed into an intelligent system that is included in hospital information management systems, can access laboratory results and perform liver cancer screening automatically and make necessary warnings to doctors about their patients. It is aimed to transform this system envisaged in the following process into a comprehensive health project.
This study is important for the diagnosis of liver diseases in order to assist physicians in the field of liver diseases with the classification algorithms used for early diagnosis and screening of liver diseases.
iv
Key Words: Liver Diseases, WEKA, Machine Learning, Machine Learning Algorithms, Data mining
v TEŞEKKÜR
Bu tez çalışmam boyunca, ilgi ve deneyimleri ile bana ışık tutan çok kıymetli hocam Sayın Doç. Dr. Aytürk Keleş’e en içten teşekkürlerimi sunarım.
Ayrıca bu süreçte bilgi ve deneyimlerine sıklıkla başvurduğum değerli hocam Sayın Dr. Ali Keleş’e teşekkür ederim.
Dünyaya geldiğim o günden beri benim için her türlü fedakârlığı gösteren, maddi manevi tüm sorunlara göğüs gerip beni bugünlere getiren babam Tuna KARSLI ve annem Saniye KARSLI’ ya ve varlıklarıyla her zaman en büyük destekçilerim olan kız kardeşlerime en içten sevgi ve teşekkürlerimi sunarım.
…/…/2019 Özden Burcu KARSLI
vi
İÇİNDEKİLER
ÖZET ...ii
TEŞEKKÜR ... v
SİMGELER VE KISALTMALAR DİZİNİ ... viii
ŞEKİL ve ÇİZELGELER DİZİNİ ... x
1. GİRİŞ ... 1
2. KURAMSAL TEMELLER ... 3
2.1. Makine Öğrenme( Machine Learning)... 3
2.1.1. Makine öğrenme türleri ... 5
2.2. Genel Makine Öğrenme Algoritmaları ... 7
2.2.1. Karar ağaçları: ... 8
2.2.2. Destekçi vektör makineleri (support vector machines): ... 9
2.2.3. Yapay sinir ağları (YSA): ... 9
2.2.4. Adaptif yükseltme algoritması (AdaBoost): ... 12
2.2.5. K-En yakın komşu (K-nearest neighbor): ... 12
2.2.6. Naive bayes algoritması: ... 14
2.3. Veri Madenciliği (VM) ... 15
2.3.1. Veri Madenciliği Tanımı ... 15
2.3.2. Veri Madenciliğinin Kısa Tarihi ... 17
2.3.3. Veri Madenciliğinde Bilgi Keşif Süreci ... 18
2.3.4. Veri Madenciliğinin Kullanım Alanları ... 21
2.3.5. Veri Madenciliği Yazılımları ... 23
3. MATERYAL ve YÖNTEM... 32
3.1. Uygulama Veri Seti: Karaciğer Hasta Veri Seti Analiz Bilgisi ... 32
3.2. Karaciğer Hastalığının Teşhisi ve Önemi ... 38
3.2.1. Karaciğer hastalıkları ... 40
3.2.2. İstatistiksel verilerle karaciğer hastalıkları ... 43
3.3. Veri Setine Uygulanan Ön İşlemler ... 49
3.4. Kullanılan Algoritmalar ve Analizleri ... 54
3.4.1. J48 algoritması ... 54
3.4.2 Lojistik model ağacı (LMT) algoritması ... 64
vii
3.4.4. Hoeffding tree algoritması ... 68
3.4.5. REP tree algoritması ... 70
3.4.6. Random forest algoritması ... 72
3.4.7. Random tree algoritması ... 74
3.4.8. IBk algoritması ... 76
4. ARAŞTIRMA BULGULARI ... 78
4.1. Sınıflandırma Performanslarını Değerlendirme Ölçütleri ... 78
4.2. Algoritmaların Genel Değerlendirmesi ... 81
4.2.1. J48 algoritması ... 81
4.2.2. Lojistik model ağacı (LMT) algoritması ... 82
4.2.3. Decision stump algoritması ... 83
4.2.4. Hoeffding tree algoritması ... 84
4.2.5. REP tree algoritması ... 85
4.2.6. Random forest algoritması ... 86
4.2.7. Random tree algoritması ... 87
4.2.8. IBk algoritması ... 88
5. SONUÇ, TARTIŞMA ve ÖNERİLER ... 90
KAYNAKLAR ... 96
viii
SİMGELER VE KISALTMALAR DİZİNİ
ARFF Attribute-Relation File Format
AUC Area Under The Curve
CLI Command Line Interface
DVM Destekçi Vektör Makineleri
FN False Negative
FP False Positive
GNU Genel kamu lisansı
IBk Instance Based Learner
ILPD Indian Liver Patient Dataset
KEEL Knowledge Extraction based on Evolutionary Learning
KNIME Konsatanz Information Miner
k-NN k Nearest Neighbor
LMT Lojistik model ağacı
MATLAB MATrix LABoratory
MCC Matthews Correlation Coefficient
NEFCLASS-J Neuro-Fuzzy Classification-Java
REP Tree Reduced Error Pruning Tree
RO Random Forest
ROC Receiver Operating Characteristic
SML Supervised Machine Learning
SMOTE Synthetic Minority Oversampling Technique
TN True Negative
TP True Positive
ix
VM Veri madenciliğini
WEKA Waikato Environment for Knowledge Analysis
WHO Dünya Sağlık Örgütü
YSA Yapay Sinir Ağları
x
ŞEKİL ve ÇİZELGELER DİZİNİ
Şekil 2.1. Makine öğrenmesi süreci ... 5
Şekil 2.2. Denetimli öğrenme modeli süreci ... 6
Şekil 2.3. Karar ağacı yapısı ... 8
Şekil 2.4. Sinir hücresi yapısı ... 10
Şekil 2.5. Yapay sinir hücresinin yapısı ... 11
Çizelge 2.1. Biyolojik sinir hücrelerinin yapay sinir hücreleriyle kavram benzerlikleri ... 11
Şekil 2.6. K-En yakın komşu algoritma görüntüsü ... 14
Şekil 2.7. Veri madenciliğine ait tarihsel gelişim süreci ... 18
Şekil 2.8. Bilgi keşfi süreci ... 19
Şekil 2.9. Veri madenciliğinin diğer disiplinlerle ilişkisi ... 23
Şekil 2.10. Rapidminer arayüzü ... 24
Şekil 2.11. KEEL arayüzü ... 26
Şekil 2.12. MATLAB arayüzü ... 28
Şekil 2.13. WEKA aracının arayüzü ... 29
Şekil 2.14. WEKA aracının kullandığı .arff türü örnek veri seti dosyası ... 32
Çizelge 3.1. Karaciğer hasta veri setinin özellik bilgileri ... 33
Çizelge 3.2. Karaciğer hasta veri setinde kullanılan özelliklerin istatistik bilgileri ... 34
Şekil 3.1. Kullanılan veri setinden örnek kayıtlar... 35
Şekil 3.2.Veri seti yaş-sıklık grafiği ... 36
Şekil 3.3. Hastalık durumunun cinsiyete göre dağılım grafiği ... 36
Şekil 3.4. İnsan vücudunda karaciğer ve safra kesesinin yeri ... 40
Şekil 3.5. Normal ve büyümüş karaciğer görünümü ... 42
Şekil 3.6. Karaciğer ve intrahepatik safra kanalı kanserinin ABD’deki tüm yeni kanser vakalarına göre dağılımı (2019 yılı) ... 45
Çizelge 3.3. Genel kanser türleri içinde karaciğer ve intrahepatik safra kanalı kanserinin görülme sıklığı ... 45
Şekil 3.7. Siroz sebebiyle erkeklerde ölüm oranı ... 47
Şekil 3.8. Siroz sebebiyle kadınlarda ölüm oranı ... 48
Şekil 3.9. Normalize filtresinin kullanımı ... 50
Şekil 3.10. Ver setinin normalize edilmiş şekli ... 50
Şekil 3.11. Hastalık sınıfının yüzdelik dağılımı... 51
Şekil 3.12. SMOTE ara yüzünde özellik seçimleri ... 52
Şekil 3.13. SMOTE filtresi uygulandıktan sonra veri setindeki sınıf dağılımı ... 52
Şekil 3.14. Sınıflamada kullanılan test opsiyonları ve çapraz geçerlilik ... 53
Şekil 3.15. Veri seti dosyasının (ilpd.arff) içeriği ... 55
Şekil 3.16. WEKA preprocess ekranı ... 56
Şekil 3.17. J48 Algoritmasının seçimi ... 57
Şekil 3.18. J48 Algoritmasının sınıflandırma sonuçları... 57
Şekil 3.19. J48 algoritmasının ağaç yapısının açılması ... 59
Şekil 3.20. J48 algoritması ile elde edilen karar ağacı yapısının bir kısmı ... 60
Şekil 3.21. ROC Eğrisi ... 62
xi
Şekil 3.23. J48 algoritmasının ROC eğrisi ... 64
Şekil 3.24. Lojistik model ağacı algoritması sınıflandırma sonuçları... 65
Şekil 3.25. Lojistik model ağacı (LMT) algoritmasının ROC eğrisi ... 66
Şekil 3.26. Decision stump ağacı algoritması sınıflandırma sonuçları ... 67
Şekil 3.27. Decision stump algoritmasının ROC eğrisi ... 68
Şekil 3.28. Hoeffding tree algoritması sınıflandırma sonucu ... 69
Şekil 3.29. Hoeffding tree algoritmasının ROC eğrisi ... 70
Şekil 3.30. REP tree algoritması sınıflandırma sonucu ... 71
Şekil 3.31. REP tree algoritmasının ROC eğrisi ... 72
Şekil 3.32. Random forest algoritması sınıflandırma sonucu ... 73
Şekil 3.33. Random forest algoritmasının ROC eğrisi ... 74
Şekil 3.34. Random tree algoritması sınıflandırma sonucu ... 75
Şekil 3.35. Random tree algoritmasının ROC eğrisi... 76
Şekil 3.36. IBk algoritması sınıflandırma sonucu ... 77
Şekil 3.37. IBk algoritmasının ROC eğrisi ... 78
Çizelge 4.1. Karışıklık matrisi ... 79
Şekil 4.1. J48 algoritmasına ait Confusion Matrix (Karışıklık Matrisi) ... 82
Çizelge 4.2. J48 algoritmasına ait sınıflandırma modeli değerlendirme ölçüt ve değerleri ... 82
Şekil 4.2. LMT algoritmasına ait Confusion Matrix (Karışıklık Matrisi) ... 83
Çizelge 4.3. LMT algoritmasına ait sınıflandırma modeli değerlendirme ölçüt ve değerleri 83 Şekil 4.3. Decision Stump algoritmasına ait Confusion Matrix (Karışıklık Matrisi) ... 84
Çizelge 4.4. Decision Stump algoritmasına ait sınıflandırma modeli değerlendirme ölçüt ve değerleri ... 84
Şekil 4.4. Hoeffding Tree algoritmasına ait Confusion Matrix (Karışıklık Matrisi) ... 85
Çizelge 4.5. Hoeffding Tree algoritmasına ait sınıflandırma modeli değerlendirme ölçüt ve değerleri ... 85
Şekil 4.5. Rep Tree algoritmasına ait Confusion Matrix (Karışıklık Matrisi) ... 86
Şekil 4.6. Random Forest algoritmasına ait Confusion Matrix (Karışıklık Matrisi) ... 86
Çizelge 4.6. REP Tree algoritmasına ait sınıflandırma modeli değerlendirme ölçüt ve değerleri ... 86
Şekil 4.7. Random Tree algoritmasına ait Confusion Matrix (Karışıklık Matrisi) ... 87
Çizelge 4.7. Random Forest algoritmasına ait sınıflandırma modeli değerlendirme ölçüt ve değerleri ... 87
Şekil 4.8. IBk algoritmasına ait Confusion Matrix (Karışıklık Matrisi) ... 88
Çizelge 4.8. Random Tree algoritmasına ait sınıflandırma modeli değerlendirme ölçüt ve değerleri ... 88
Çizelge 4.9. IBk algoritmasına ait sınıflandırma modeli değerlendirme ölçüt ve değerleri .. 89
Çizelge 5.1. Kullanılan algoritmaların performans değerleri ... 92
Çizelge 5.2. Çalışmanın literatürdeki benzer çalışmalar ile sadece doğruluk değeri üzerinden karşılaştırılması ... 95
1 1. GİRİŞ
Karaciğer insan vücudundaki en fazla göreve sahip olan aktif ve bir o kadar karmaşık organlarından biridir. Kanı ilaç, alkol gibi birçok yabancı ve toksik maddelerden arındırma, vücuttaki yağları sindirme, atıkları vücuttan uzaklaştırma ve safra üretme gibi hayati fonksiyonları yerine getirme açısından oldukça önemli bir organdır.
Karaciğer hastalıkları dünya genelinde en sık rastlanılan hastalıklardandır. Aynı zamanda ölümlerin en büyük sebeplerindendir. 2019 yılında, ABD’de 42.030 yeni karaciğer ve intrahepatik safra kanalı kanseri vakası olacağı ve bu hastalıktan 31.780 kişinin öleceği tahmin edilmektedir (url 1).
Karaciğer hastalıkları vücutta büyük tehlikeler oluşturabilmektedir. Bu sebeplerden ötürü alkolden bağımsız karaciğer yağlanması, alkolik karaciğer yağlanması, hepatit a, hepatit b, hepatit c, hepatit d, karaciğer büyümesi, karaciğer kanseri, karaciğer ve intrahepatik safra kanalı kanseri, karaciğer yetmezliği ve siroz gibi karaciğer hastalıklarının mümkün oldukça erken bir aşamada teşhisi ve tedavisi hayati öneme sahiptir.
Son yıllarda pek çok alanda büyük bir başarı ile kullanılan Yapay Zekâ teknolojilerinin bugün özellikle tıp alanında hastalıkların tanı, teşhis ve tedavi süreçlerinde sıkça kullanılmaya başlandığı görülmektedir. Bunun en önemli sebebi YZ teknolojilerinin altında yer alan ve Veri Madenciliğinin önemli bir parçası olarak kabul edilen makine öğrenme algoritmalarının örüntüler arasındaki gizli ilişkileri ortaya çıkarabilme gücüdür. Bu sayede benzer semptomlar gösteren, belirsizliklerin yoğun yer aldığı ve bir birinden ayırt edilmesi güç hastalıkların teşhisinde çok ciddi oranlarda başarı sağlanabilmektedir.
Gelişmiş ülkelerde YZ araştırma departmanları hastaneler ile ortak AR-GE çalışmaları yürütmektedir. Çünkü YZ teknolojilerindeki gelişmeler sadece hasta ve doktoru değil sağlık sisteminin tümünü yakından etkilemektedir. Öyle ki Özellikle “Artificial Intelligence in Medicine” yani “Tıpta Yapay Zekâ” karmaşık tıbbi
2
verileri analiz etme ve hekimin hasta sonuçlarını iyileştirme konusunda yardımcı olma kapasitesine sahip bir bilgisayar bilimi dalı olarak tanımlanmaya başladı.
Hastanelerde her dakika sisteme dâhil olan veri sayısı düşünüldüğünde bu kadar büyük veriyi yönetebilmek için insan kapasitesinin üstünde bir bilgi işleme kabiliyetlerine ihtiyaç duyulmaktadır. Bu gün YZ teknolojileri sayesinde hastalardan alınan kan, idrar ve diğer laboratuvar örnekleri güçlü öğrenme algoritmalar ile işlenerek öngörüye dayalı keşifler yapılabilmektedir. Bu keşifler sayesinde doktor hasta hakkında karar verirken artık daha güçlü olabilmektedir.
Bu tez çalışmasında karaciğer hastalıklarının teşhisine yönelik makine öğrenme algoritmaları çalışılmıştır. Bu bağlamda öncelikle literatürde bu konuda yapılan çalışmalar araştırılmış ve bu bölümde söz konusu araştırmalara yer verilerek yorumlanmıştır.
Neshat et al. (2008) tarafından BUPA karaciğer bozuklukları veri setini kullanarak karaciğer bozukluklarını teşhis etmek için bir bulanık sistem geliştirildi. Bu sistem karaciğer bozukluklarının teşhisinde %91 oranında başarı gösterdi. Ayrıca bu sistemin benzer teşhis sistemlerden daha ucuz, daha hızlı ve daha doğru sonuç verdiğini belirttiler.
Ribeiro et al. (2011), SVM, Bayesian ve K-En Yakın Komşu Sınıflandırıcılarını karaciğer bozukluklarının teşhisi için kullandılar. Elde ettikleri sonuçlara göre en yüksek keskinlik değeri % 80,68 oranı ile K-En Yakın Komşu Sınıflandırıcısına aitti.
Alkuşak ve Gök (2015) karaciğer yetmezliğini teşhis etmek için makine öğrenmesi algoritmalarını ILPD ve BUPA veri setleri üzerinde WEKA aracında çalıştılar. Yaptıkları analizlerde 10-kat çapraz doğrulama test tekniği kullandılar. Bu araştırma sonucunda YSA ile ILPD için % 76, BUPA için % 78 sınıflama doğruluğunu elde ettiler.
Lakshmi et al. (2017) ILPD veri setinde yer alan 11 özelliğin sınıflandırıcı performansında ayrı ayrı öneminin bulunduğunu dile getirdiler. Ancak yaptıkları çalışmada, Toplam Bilirubin, Doğrudan Bilirubin, Alkalen Fosfataz, Alanin
3
Aminotransferaz, ve Aspartat Aminotransferaz’ın sınıflandırma performanslarına çok özel katkıları olduğunu ve bunların diğer özelliklerle karşılaştırıldığında sınıflandırmaya daha yüksek katkı sağladıklarını gördüler.
Pathan et al. (2018) ILPD veri setini WEKA aracında önce k-Means Kümeleme Algoritması ile kümeleme yaptıktan sonra Naive Bayes, Ada Boost, J48, Bagging ve Random Forest algoritmaları ile sınıflandırmaya çalıştılar. Çalışma sonucunda en iyi sonucu veren algoritmanın Random Forest olduğunu belirttiler.
Priya et al. (2018), karaciğer hastalığının teşhis doğruluğunu arttırmak için ILPD veri setine PSO (Dash and Liu 1997) özellik seçim metodolojisi uygulayarak teşhiste etkili olan özellikleri çıkardılar. Sınıflandırma işlemi için J48, MLP, SVM, Random Forest ve Bayesnet algoritmalarını kullandılar. Algoritmaları sadece doğruluk değerleri üzerinden karşılaştırdıklarında en iyi sonucu J48 algoritmasının verdiğini gördüler.
Jacob et al. (2018) python dili kullanılarak geliştirdikleri bir grafiksel arayüzde ILPD ver seti özelliklerini kullanarak yaptıkları çalışmada; Logistic Regression K-NN, SVM ve ANN algoritmaları üzerinde çalıştılar. Sonuç olarak % 92.8 ile en iyi doğruluk değeri ile en iyi sonucu veren algoritmanın ANN olduğunu tespit ettiler.
Bu çalışmada, karaciğer veri seti WEKA aracında yer alan 8 farklı algoritma ile çalışılmıştır. Bu algoritmalar sırasıyla J48, Lojistik Model Ağacı (LMT), Decision Stump (Karar Kütüğü) , Hoeffding Tree, REP Tree, Random Forest, Random Tree ve IBk algoritmalarıdır. Algoritma sonuçları elde edilen karışıklık matrisleri tıpta kullanılan genel geçer değerlendirme ölçütleri ile tek tek hesaplanmıştır. Bu ölçütler sayesinde karaciğer hastalığının tanı ve teşhisinde en etkili kullanılabilecek algoritmalar belirlenebilmiştir.
2. KURAMSAL TEMELLER 2.1.Makine Öğrenme( Machine Learning)
Makine öğrenmesi, günümüzde nesne tanıma, görüntü işleme, yüz tanıma, sanal gerçeklik, artırılmış gerçeklik, ses tanıma, iris tanıma, pazarlama, sağlık,
4
müşteri hizmetleri, uydu görüntüleri, yer bilimi, sahtekârlık yakalama (fraud) gibi pek çok alanda kullanılan yapay zekânın bir alt ve en geniş koludur.
Temelde makine öğrenmesi gerçekleştiren sistemlerden; öğrendiği bilgiyi saklama, tıpkı insan ve hayvan beyni gibi öğrendiği, sakladığı bilgileri tecrübe haline getirerek yeni durumlara uyarlayıp kullanması beklenir.
Makine öğrenme diğer adıyla yapay öğrenme; bilgisayarlara daha önceden tanıtılan bilgiyi özümseyerek her olası yeni durum için tekrar programlamaya ihtiyaç duymayan, hazır bulunan verilerden çıkarımlar yapan ve bu çıkarımlarla bilinmeyene dair tahminlerde bunulan yapay zekânın en önemli kullanım alanlarında biridir.
Turing makinelerin de insanlar gibi düşünebileceği ve yeni durumlar içi kararlar alabileceği fikrini ilk ortaya atan kişidir (1950). Çalışmalarında makinelerin de tıpkı insanlar gibi düşünüp öğrenebileceğinden bahsederek günümüzde yaygın olarak kullanılan yapay zekâ alanına temel oluşturacak çıkarımlarda bulunmuştur.
Öztemel (2003)’e göre makine öğrenmesi bir diğer ifade ile mekanik öğrenme bilgisayarın bir durumla alakalı elde ettiği bilgileri ve edindiği tecrübeleri kullanarak sonraki zamanlarda karşılaşabileceği yeni bir duruma uyarlayıp karar verebilmesi ve problemlere yeni çözümler getirebilmesidir.
Makine öğrenmesi (machine learning) için bazı şartlar bulunmaktadır. Öğrenme sürecinin esası öğrenenin insan ya da makine olmasına bakılmaksızın benzerlikler gösterir. Ayrıca birbiri ile ilişkili dört unsur bulunmaktadır. Bunlar:
• Depolama: Görsel deneylerden, bellekten ve çağrışımlardan yararlanır. • Soyutlama: Hafızadaki dataları genişletir ve kavramsal öğelere dönüştürür. • Genelleştirme: Bir önceki adımdaki kavramsal öğeleri kullanır ve genel
ifadelere dönüştürür.
• Değerlendirme: Öğrenilen kavramların uygulanabilirliğini test etmek ve tahmin için ön bildirim sistemi kullanır (url 2).
Makine öğrenme süreci Şekil 1.1 (Buçan Kırkbir 2017)’ de verildiği gibi gerçekleşmektedir.
5 Şekil 2.1. Makine öğrenmesi süreci
2.1.1. Makine öğrenme türleri
Makine öğrenmesi yöntemlerinde birçok öğrenme türleri bulunmaktadır. Öğrenmenin nasıl gerçekleştireceğini belirleyen sistem ve bu sistemde kullanılan öğrenme algoritması öğrenme türlerine göre değişkenlik göstermektedir (Öztemel 2012). Bu öğrenme türleri aşağıdaki gibi sıralanabilir:
• Denetimli Makine Öğrenmesi (SML: Supervised Machine Learning) • Denetimsiz Makine Öğrenme (UML: Unsupervised Machine Learning) • Yarı-Denetimli öğrenme (Semi-supervised Learning)
• Pekiştirerek öğrenme (Reinforcement Learning)
Bu makine öğrenme türlerinden denetimli ve denetimsiz makine öğrenme, en çok kullanılan öğrenme türleridir.
Denetimli makine öğrenmesi (SML: supervised machine learning)
Denetimli öğrenme (gözetimli öğrenme); sisteme eğitim veri seti ile test veri setinin yüklenmesiyle başlar. Veri setinde her bir veri için gerekli etiketlenmenin yapılması ve bu sayede girdi veri seti ile çıktı veri seti arasında ilişki kurulması süreçleridir. Bu süreçte, girdiler ve çıktılar arasındaki ilişkiyi tanımlayan bir fonksiyon ya da algoritma öğrenilir. Önceden bilinen çıktılar üstünde sınıflama gerçekleştirildikten sonra sonuçları henüz bilinmeyen veri kümelerinde olası sonuçlar tahmin edilmeye çalışılır. Denetimli öğrenme modeline ait süreç Şekil 1.2’de (Afrin and Nahar 2017) gösterilmiştir.
6 Şekil 2.2. Denetimli öğrenme modeli süreci
Başka bir deyişle gözetimli öğrenme; bilinen örnekleri yani girdi ve çıktıları kullanarak bir model oluşturup yeni bir girdi verisi üzerinden çıktı değişkenini tahmin etme eylemidir.
Denetimsiz Makine Öğrenme (UML: Unsupervised Machine Learning)
Denetimsiz (gözetimsiz) makine öğrenme modeli gözlemlere bağlı bir makine öğrenmesi tekniğidir. Bu yöntem denetimli makine öğrenmenin aksine çıktı verilerini kullanmaz. Öğrenme işlemini yalnızca girdi verileri üzerinden sağlamaya çalışır.
Denetimsiz makine öğrenmede, sınıfları tanımlayan bir öğretici söz konusu değildir. Bu yüzden sistem kendi sınıfını bulmak durumundadır. Bu yöntemlere kendi kendine öğrenebilen modeller de denilmektedir. Denetimsiz öğrenmede çıktıları olan bir eğitim seti kullanılmamaktadır ve eğitim için sadece girdilerin olması yeterlidir. Bu giriş değerine göre çıkış değerleri sınıflandırma ya da
7
gruplandırma olarak keşfedilir. Ayrıca çokça kullanılan amaçlarından bazıları kümeleme, boyut indirgeme, olasılık yoğunluk tahmini ve özniteliklere arasındaki ilişkinin keşfidir.
Yarı-Denetimli öğrenme (Semi-Supervised Learning)
Oluşturulacak veya yapılan öğrenme modelinde elimizde az sayıda ilişkilendirilmiş yani çıktıları belli olan data ve buna karşılık çok daha fazlaca ilişkilendirilmemiş yani çıktıları belli olmayan data varsa hem denetimli hem de denetimsiz öğrenme oldukça yetersiz kalabilir. Böyle zamanlarda en uygun yöntem elde bulunan az sayıdaki ilişkilendirilmiş datalardan yola çıkarak ilişkilendirilmemiş veya ilişkilendirilememiş datalar hakkında, bilgi sahibi olmaya çalışmak ve toplanabildiği kadar bilgi toplamaktır. Bunu yapabilmek için “class” yöntemi kullanılmalı yani datalar sınıflandırılmalıdır. Bu şekilde yapılan öğrenmeye yarı denetimli öğrenme denilir.
Yarı denetimli öğrenme modelinin denetimli öğrenme modelinden ayrıldığı en önemli nokta ilişkilendirilmemiş dataların fazlalığıdır. Denetimli öğrenmede ilişkilendirilmiş data sayısı fazla, tahmin edilmeye ihtiyaç duyulan data sayısı azken yarı denetimlide tam tersi bir durum söz konusudur.
Pekiştirerek öğrenme (Reinforcement Learning)
Pekiştirmeli öğrenme modelinde, öğrenme sürecinde icra edilen eylemlerin amaca ne kadar hizmet ettiğini gösteren bir önleme yani geri besleme sistemi vardır. Öğrenme sürecinde amaca götüren icra eylemleri kümesi için pozitif geri bildirim alınır. Böylece amaca hizmet eden ve etmeyen eylemler ilişkilendirilmiş olur.
2.2.Genel Makine Öğrenme Algoritmaları
En çok kullanılan makine öğrenme algoritmaları arasında bulunan Karar Ağaçları, Destekçi Vektör Makineleri (DVM), Yapay Sinir Ağları (YSA),Yükseltme Algoritmasından (AdaBoost), K-En Yakın Komşu (K-Nearest Neighbor) ve Naive Bayes Algoritmasından bahsedilecektir.
8
2.2.1. Karar ağaçları:
Karar ağaçları, tek kökten başlayarak karar düğümlerine doğru ilerleyen ve etiketlenmiş yapraklarda son bulan bir sınıflandırıcıdır. Karar ağaçları denetimli (gözetimli) makine öğrenmesi kapsamında yer almaktadır (Akı 2017). Karar ağaçları;
• Kolay uygulanabilmesi
• Veri tabanı sistemleri ile kolaylıkla birleştirilebilmesi • Kolay yorumlanabilmesi
• Maliyetinin düşük olması
• Tüm değişkenlere (nitel, nicel, sürekli, kesikli) uygulanabilen algoritmalara sahip olması
• Güvenilir sonuçlar vermesi gibi sebeplerden dolayı sık kullanılan algoritmalardan biridir (Akşehirli 2012).
Algoritma kök, karar düğümleri, dallar ve yapraklardan oluşmaktadır. İşlemin başladığı yer kök kısmıdır. Karar düğümlerinde nitelik sınanma işlemleri gerçekleşir. Dallarda sınama sonuçları görülebilir ve son olarak yapraklar ise sınıfları temsil eder. Karar ağaçları tümevarım yöntemini kullanarak büyük veriyi küçük gruplara böler. Basit bir karar ağacı yapısı Şekil 1.3’de de görülmektedir.
9
2.2.2. Destekçi vektör makineleri (support vector machines): Destekçi vektör makineleri (DVM), 1960’lı yılların sonunda Vladimir Vapnik ve Alexey Chervonenkis tarafından geliştirilmiş bir makine öğrenme yöntemidir. Bu öğrenme yöntemi kontrollü sınıflandırma algoritması olup istatiksel öğrenme teorisine dayanmaktadır (Güven ve Bilgin 2014)
DVM, yüksek boyutlu verilerde sıkça kullanılan bir sınıflandırma yöntemidir. Veri üzerinde eğitilerek uygulanır. Bu yüzden denetimli makine öğrenmesi kapsamındadır.
DVM (Destekçi Vektör Makineleri), uygun değerde bir çizgi bulunmasını sağlayarak sınıfların ayrılması işlemini yapar. Çizilen çizgilerin sınıflara en uzak noktadan geçecek şekilde çizilmesi gerekir. İlk kez iki sınıflı doğrusal verilerin modellenmesi için kullanılmıştır. Zamanla gelişen DVM, ikiden fazla sınıflı ve doğrusal olmayan verilerin modellenmesinde de kullanılmıştır. DVM’nin çalışma prensibi en uygun karar fonksiyonun tahmin edilmesine (hiper-düzlemin tanımlanmasına) dayanır (Vapnik 1995).
Destekçi Vektör Makineleri, sınıflama yapma işlemini kareli optimizasyon işlemine çevirerek oluşturmaktadır. Böylece öğrenme sırasında yapılan işlemlerde nicelik azalmaktadır. Bu sayede diğer algoritmalara nazaran daha hızlı çözümler üretilebilmektedir. Bu becerisi sayesinde hacmi büyük veri setlerinde oldukça kullanışlıdır (Kaya 2017).
2.2.3. Yapay sinir ağları (YSA):
Biyolojik sinir ağları baz alınarak tasarlanan makine öğrenme algoritması olan Yapay sinir ağları (YSA), biyolojik sinir sistemine ait nöron, hücre gövdesi, dendrit ve aksondan oluşmaktadır. Aksonlar, bilgi aktarımını sağlayan uzantılardır. Ana görevi diğer nöron hücreleri ile sinaps olarak adlandırılan birleşme noktaları yoluyla haberleşmeyi sağlamaktır. Sinir hücrelerinin her biri pek çok sinir hücresiyle iletişim halindedir. Aynı anda birçok sinir hücresinden gelen uyarıları alır. Şayet bu uyarılar belli bir eşik seviyesinin üstünde ise diğer nöronlara ulaştırır (Akı 2017).
10
Bir sinir hücresine ait gövde, dendrit ve aksonlar Şekil 1.4’te gösterilmiştir.
Şekil 2.4. Sinir hücresi yapısı
Yapay sinir ağları (artifical neural networks), insandaki sinir sistemini oluşturan ağlardan ilham alınarak geliştirilmiş olan bir bilgi işleme sistemidir. Biyolojik sinir ağlarına benzetilerek yapılan bilgisayar programlarıdır. Yani her biri kendi hafızasına sahip işlem birimlerinden oluşan paralel ve dağıtılmış bilgi işleme yapılarını birbirine bağlayan ağırlıklı bağlantılar mevcuttur (Elmas 2003).
Yapay sinir ağları bilgileri örnekleriyle beraber toplar, genellemeler yaptıktan sonra daha önce karşılamadığı yeni durumlarla karşılaştığı zaman önceden öğrenmiş olduğu bilgilere dayanarak yeni durumlar hakkında bir yargıya varabilmektedir. Yapay sinir ağlarının bu öğrenebilme ve genelleme yapabilme yetenekleri sayesinde bilimin pek çok dalında hızla yayılarak uygulanma sahaları bulmuş ve çok karışık problemlere başarılı bir şekilde çözümler bulmuştur (Ergezer vd 2003).
11 Şekil 2.5. Yapay sinir hücresinin yapısı
Çizelge 2.1’de biyolojik sinir hücresinde kullanılan kavramların yapay sinir hücresindeki karşılıkları yer almaktadır.
Çizelge 2.1. Biyolojik sinir hücrelerinin yapay sinir hücreleriyle kavram benzerlikleri
Sinir Sistemi Yapay Sinir Ağı
Nöron İşlem Elemanı
Dentrit Toplama Fonksiyonu
Hücre Gövdesi Aktivasyon Fonksiyonu
Akson Eleman Çıkışı
12
2.2.4. Adaptif yükseltme algoritması (AdaBoost):
AdaBoost algoritması İngilizce Adaptive Boosting kelimelerinden türetilmiştir. AdaBoost’ı ilk öneren isimler Yoav Freund ve Robert Schapire’dır. AdaBoost’ı en popüler makine öğrenme algoritması yapan önemli özelliklerinden biri hız olarak diğerlerinden üstün olması, diğeri ise az hafıza kullanmasıdır. Bunun yanında uygulanabilir olması ve kuramsal temelinin güçlü olması da AdaBoost’ı tercih sebebi kılmıştır.
AdaBoost, topluluk öğrenme algoritmalarından biri olup sınıflandırmayı ya da gerilemeyi belirlemede kullanılabilmektedir. Başlangıç durumda her bir örnek için eşit dağılım ile başlar. Ardından sergilediği performansa göre en güçlü zayıf kalmış sınıflayıcıyı bulur. Daha sonra ağırlıkları günceller ve yanlış sınıflandırılmış örneğe odaklanır. Bu sayede belli sayıdaki iterasyon sonunda en güçlü olan zayıf sınıflayıcılar bir araya toplandığı için güçlü bir sınıflayıcı oluşturulur. Bu durum sınıflandırma başarısını arttırılır ( Doğruyol Başar vd 2016).
Aktivite ve kişi tanıma gibi birçok örüntü tanıma problemine uygulanmıştır. AdaBoost ağırlıklı olarak sınıflandırma yapmada kullanılan algoritmaların, daha iyi bir doğruluk oranı elde etmek için performanslarını arttırmayı amaçlamıştır. Bu bağlamda sınıflandırma algoritmalarının, yanlış sınıflandırdığı öznitelikleri düzeltmeye çalışır (Erdaş 2017).
2.2.5. K-En yakın komşu (K-nearest neighbor):
Çok kullanılan yöntemlerden biri olan “K-En Yakın Komşu” algoritması, sınıflandırma maksatlı denetimli öğrenme yöntemleri arasında bulunmaktadır. Bu algoritmada sınıflandırılmak istenen örnek, önceden sınıflandırılmış olan veri setinde en yakın komşusu ya da komşularının sınıfıyla eşleştirilir. Uzaklıkları dikkate alınan komşu sayısı k ile gösterilir. Bundan dolayı bu algoritma kısaca k-NN (k Nearest Neighbor) olarak isimlendirilir (Akı 2017). K-en yakın komşu algoritması kullanılırken hesaplanmak istenen uzaklıklar için Öklit, Manhattan gibi uzaklık hesaplama yöntemlerinden faydalanılır. Bilinmeyen veriler, k-en yakın komşuya en çok benzeyen sınıf değerine atanır (Başarslan 2017).
13 a) Öklid mesafesi
En çok tercih edilen mesafe ölçüm türlerinden biridir.
A = (a1, a2, …, an) ve B = (b1, b2, …, bn) noktaları arasındaki mesafe (d) aşağıdaki gibidir: 𝑑 = √∑(𝑎𝑖− 𝑏𝑖)2 𝑘 𝑖=1 2 b) Manhattan mesafesi
Manhattan ölçüm yöntemi tek boyutta ve kareli ölçüm yapar. İki tek boyutta hareket eder; iki veya daha fazla boyutta ilerlemez. A ve B noktaları arasındaki Manhattan uzaklığı (d) aşağıdaki formül kullanılarak hesaplanır (Kaya 2017).
𝑑 = ∑ |𝑎
𝑖− 𝑏
𝑖|
𝑘
𝑖=1
Kaya (2017)’ ya göre K-NN algoritmasının çalışma sırası şöyledir: • Mesafe tespitinin yöntemi belirlenir (Öklit-Manhattan vs.).
• K sayısı belirlenir.
• Yeni veriye en yakın k adet veri belirlenir.
• Bu k adet verinin en çok içinde bulunduğu sınıf tespit edilir. • Üzerinde çalışılan verinin bu sınıftan olduğu kabul edilir.
14 Şekil 2.6. K-En yakın komşu algoritma görüntüsü
2.2.6. Naive bayes algoritması:
Algoritmaya adını İngiliz matematikçi Thomas Bayes'ten almıştır. Algoritması istatistiki sınıflandırma modelleri arasında yer alan Naive Bayes’in temelinde olasılık teorisi kullanılmaktadır (Başarslan 2017). Tekniğin amacı olasılık teorisi kullanılarak varsa belirsizlik durumlarının tespit edilmesidir. En yaygın kullanım alanı metin dokümanlarının sınıflandırılmasıdır.
Bayes teoreminin matematiksel ifadesi: P(Ci|X)=(P(X|Ci)P(Ci))/P(X) şeklindedir.
Burada,
X = (x1, x2, …, xn), data setindeki her bir örnektir. n sayısı setteki bağımsız değişken sayısını gösterir.
15
Eğer A’nın oluşum boyutları (değişkenler, özellikler) birbirinden bağımsız ise aşağıdaki matematiksel ifade kullanılabilir.
P(Ci|A) = P(a1|Ci) P(a1|Ci) P(a2|Ci) ... P(an|Ci)
Kullanılan olasılık modeline göre naive Bayes algoritması gözetimli öğrenmede çok verimli bir şekilde kullanılmaktadır. Çalışmalarda metotların veri girdileri için maksimum benzerlik metodunun kullanıldığı görülmektedir.
2.3. Veri Madenciliği (VM)
2.3.1. Veri Madenciliği Tanımı
Veri madenciliğini (VM) “Data Mining” çeşitli meslek grupları kullanmaktadır. Bu meslekler içerisinde veri analizcileri ve istatistikçiler de bulunmaktadır. Veri madenciliği kullanımı istatistikçiler tarafından ilk olarak, bir miktarda olsa olumsuzluk ifade edecek şekilde, doğruluğu araştırılacak olan bir olgu ya da hipotez olmaksızın bilginin işlenmemiş ham haliyle ilişkilendirilmesini hedefleyecek şekilde olmuştur (Kiremitçi 2005).
Veri madenciliği hakkında birçok tanımlama bulunmasına rağmen sık kullanılan bazı tanımlamalar şöyledir:
Jacobs (1999), veri madenciliğini, işlenmemiş verinin tek olarak gösteremediği bilgiyi ortaya çıkaran değerlendirme süreci olarak ifade etmiştir (Savaş vd 2012).
Doğan ve Türkoğlu (2007)’na göre ise büyük veriler arasından tahminde bulunmamızı sağlayan ilişkilerin, bazı bilgisayar algoritmaları kullanarak taranması işine veri madenciliği denir.
Veri madenciliğini Hand (1998), ortaya yeni çıkan bir disiplin olarak özellikle istatistik, makine öğrenmesi ve örüntü tanıma ile etkileşim bulunduran ve önceden tahmin edilemeyen bağlantıların ikinci ya da sonraki bir analizi olarak ifade etmiştir.
16
Veri madenciliğini Kitler and Wang (1998), istenilen tahmin değişkenlerinin birçok potansiyel değişkenden ayırt edilmesini sağlayabilmek olarak tanımlamışlardır.
Cabena et al. (1998) veri madenciliğini, büyük miktarda veriler arasından veri çıkarımını amaçlayan ve farklı teknikleri bir arada kullanan disiplinler arası bir alanı olarak ifade etmişlerdir (Irmak 2009).
Veri madenciliğini Hand et al. (2001), genellikle ve özellikle büyük veri yığınlarının kullanıcı için anlaşılabilir ve yararlı hale getirilmesi maksadıyla işlenmesi ve sözel şekilde sunulması olduğunu dile getirmişlerdir (Irmak 2009).
Tang and MacLennan (2005)’ın tanımladığı veri madenciliği, verilerin otomatik ya da yarı-otomatik olarak analize tabi tutularak gizli kalmış örüntülerin açığa çıkarılmasıdır (Irmak 2009).
Witten and Frank (2005)’a göre veri madenciliği datalardaki örüntülerin keşif işidir. Daha çok yarı otomatik olan, zaman zaman da otomatik olabilen süreç ile açığa çıkarılan örüntüler anlamlı olmalıdır ve ekonomik üstünlük temelli olacak şekilde yarar sağlamalıdır (Irmak 2009).
Tan et al. (2006) göre veri madenciliği, veri depolarında bulunan yararlı bilgi keşiflerini otomatik olarak icra edilmesidir (Irmak 2009).
Gartner Group (2007) ’a göre veri madenciliği, özellikle veri depoları ve veri ambarlarında depolanan verilerin örüntü tanıma yöntemlerinden de yararlanılarak istatistiksel ve matematiksel tekniklerle incelenmesi, bu inceleme sonucunda da anlamlı sayılan yeni bağlantılar, örüntüler ve yönelimler elde edilmesi sürecidir (Irmak 2009).
Veri madenciliği, büyük veri setlerinde, veri ambarı veya veri tabanlarında olan veriler arasında bilindik yöntemlerle tespit edilemeyen ve rutin dışı bağlantıları, örüntüleri ve belirli modellerin tespiti için matematiksel ve istatistiksel süreçlerin işletilerek analizi ve elde edilen sonuçların anlamlandırılıp görselleştirilmesidir. (Irmak 2009).
17
Anlatılanlarla beraber Han and Kamber (2006)’ e göre, veri madenciliği kendine has bazı özelliklere sahip olması gerekmektedir. Veri madenciliği sistemi olarak kabul edilecek sistemin yaygın ağ sistemi üzerinde işletilebilmesi, birleşik sorgulara doğru cevap verebilmesi ve yapılan işlemlerin geri alınabilir özellikte olması gerekmektedir (Irmak 2006).
Bu tanımlamalardan da faydalanarak şöyle bir tanım yapmak yerinde olacaktır: Veri madenciliği, çok fazla, yoğun ve karmaşık bilgilerin depolandığı farklı farklı veri tabanlarından, kullanıcının isteğine göre, geleceğe dair tahmin yürütülmesini sağlayacak şekilde anlamlı olan veriyi açığa çıkarabilme ve gereken yerde kullanabilme sürecidir.
2.3.2. Veri Madenciliğinin Kısa Tarihi
İlk bilgisayarlar 1950’li yıllarda bazı sayımları yapmak için kullanılmaya başlanmıştır. Veri tabanı, veri depolama gibi kavramlar 1960’lı yıllarda ön plana çıkmıştır. Basit öğrenme kabiliyetine sahip bilgisayarlar 1960’ların sonlarında geliştirebilmiştir. Bugün sinir ağları olarak da bilinen perceptron’ların yalnızca çok basit olan kuralları öğrenebileceğini gösterenler Marvin Minsky ve Seymour Papert’tır (Savaş vd 2012).
1970’li yıllara gelindiğinde İlişkisel Veri Tabanı Yönetim Sistemleri kullanılmaya başlanmış. Bu sayede oldukça basit kurallara dayanan sistemler geliştirilerek temel makine öğrenimi başarmışlardır.
Veri tabanı yönetim sistemlerinin 1980’li yıllarda kullanıldığı göze çarpmaktadır. Veri tabanı yönetim sistemleri mühendislik de dâhil olmak üzere birçok alanda kullanılmıştır. Bu yıllarda firmalar müşterileri, ürünleri ve rakiplerinin bilgilerini tutan veri tabanları oluşturmuşlardır. Bu veri tabanlarında fazlaca veri bulunmaktadır ve bu verilere çeşitli veri tabanı oluşturma ve sorgulama programları ile ulaşılabilmektedir.
1990’larda veri miktarı katlanarak artan veri tabanlarından istenilen verilerin nasıl çekilebileceği üzerine çalışmalar başlamıştır. Ayrıca bu konuda yayımlanan bazı yayınlar göze çarpmaktadır. Veri madenciliği için ilk program 1992 yılında hayata geçirilmiştir. 2000’li yıllarda gelişimi devam eden veri madenciliği zaman
18
içinde tüm alanlarda uygulanma alanı bulmuştur. Özellikle karar verme aşamalarında verimliliği arttıkça veri madenciliğine olan ilgide artmıştır. Veri madenciliğine ait tarihsel gelişim süreci Şekil 2.1’de gösterilmiştir ( Savaş vd 2012).
Şekil 2.7. Veri madenciliğine ait tarihsel gelişim süreci
2.3.3. Veri Madenciliğinde Bilgi Keşif Süreci
Veri madenciliğinin diğer bir adı da veri tabanından bilgi keşfidir. Yani veri tabanlarında bilgilerin işe yarar hale getirilme sürecidir. Gorunescu (2011)’e göre bu bir süreç olduğundan belirli basamakların icra edilerek bilgiye ulaşılması gerekir (Çığşar 2017).
19
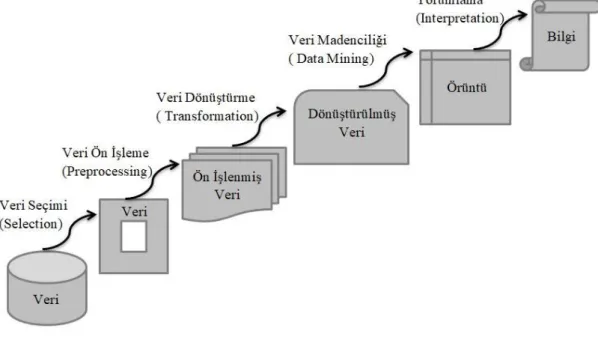
Bilgi keşfi süreci Şekil 2.2 ile gösterilmiş ve aşağıdaki basamaklarla tanımlanmıştır (Şeker 2013):
1. Veri Seçimi( Selection)
2. Veri Ön İşleme( (Preprocessing) 3. Veri Dönüştürme( Transformation) 4. Veri Madenciliği ( Data Mining) 5. Yorumlama ( Interpretation)
Şekil 2.8. Bilgi keşfi süreci
Aşağıda bilgi keşif süreci adımları kısaca açıklanarak tez çalışmasında bu adımların kullanılan veri seti üzerinde nasıl gerçekleştirildiği izah edilmiştir.
Veri Seçimi (Selection): Veri tabanında uygulanan basit seçme işlemi, ilgili bilgi çıkarımı için gereken veriler ile sınırıdır. Yani çok sayıdaki veriden sadece ilgili veriler seçilerek işleme başlanır.
Kullandığımız karaciğer veri seti; yaş, cinsiyet, toplam bilirubin, doğrudan bilirubin, alkalen fosfataz, alanin aminotransferaz, aspartat aminotransferaz, toplam protein, albümin albümin/globülin oranı ve sınıf bilgisi verilerinden oluşmaktadır.
20
Veri Ön İşleme (Preprocessing): Veri tabanından seçilen veri üzerinde ön işleme yapılır. Bu ön işleme süreci, çoğu zaman kirli verinin( gürültülü veri, noisy data) çözülmesi işlemidir.
Kullandığımız veri seti üzerinde bu adımda veriler arasındaki farkı azaltan normalize filtresi ve sınıflar arasındaki dengesiz dağılımı gidermek için sentetik veri üreten SMOTE filtreleri kullanılmıştır.
Veri Dönüştürme (Transformation): Üçüncü aşama olan verinin dönüştürülmesi (transformation) işleminde bir önceki basamakta temizlenmiş olan veri üstünde bir takım dönüşüm işlemleri uygulayarak verinin veri madenciliğine uygun hale getirilmesi amaçlanır.
Kullandığımız veri setinin sınıflama işlemine uygun hale getirilebilmesi için sınıf bilgisi alanında yer alan “1” sayısı ile temsil edilen veriler “Yes” (karaciğer hastalığının olması durumu) ile “0” sayısı ile temsil edilen veriler “No” (karaciğer hastalığının olmama durumu) ile değiştirilmiştir. Sınıf bilgisinin temsil şekli kullanılacak VM aracının kabullerine göre değiştirilebilmektedir.
Veri Madenciliği (Data Mining): Veri üzerinden, yorumlamaya uygun, anlamlı sonuçları olan ve çıkarılmak istenen bilgiye hizmet edecek işlemler yapılır.
Bu tez çalışmasında veri madenciliği için özel yazılmış olan WEKA aracı kullanılmıştır. Bu araçta yer alan pek çok makine öğrenme algoritması ile karaciğer veri seti analiz edilerek yüksek doğrulukta karaciğer hastaları tespit edilebilmiştir. Bu süreçte kullanılan makine öğrenme algoritmaları ve elde edilen sonuçlara materyal ve yöntem kısmında yer verilmiştir.
Veri Yorumlama (Interpretation): Veri madenciliği aşamasından çıkarılan örüntünün (pattern) yorumu yapılarak bu çıkarılan örüntünün anlamı sorgulanır.
Bu adımda makine öğrenme algoritmaları ile gerçekleştirilen sınıflama işlemlerinin anlamlılığı performans değerlendirme ölçütleri kullanılarak değerlendirilmiştir. Bu sayede en iyi teşhisi gerçekleştiren sınıflama modeli tespit edilmiştir.
21
2.3.4. Veri Madenciliğinin Kullanım Alanları
Veri madenciliğinin gün geçtikçe daha çok kullanıldığı ve kullanım alanlarının artarak yayıldığı görülmektedir. Temel anlamda veri madenciliğinin yaygın olarak kullanıldığı alanlar şunlardır:
• Pazarlama
• Banka ve Sigortacılık • Biyoloji, Tıp ve Genetik • Kimya
• Yüzey Analizi ve Coğrafi Bilgi Sistemleri • Görüntü Tanıma ve Robot Görüş Sistemleri • Uzay Bilimleri ve Teknolojisi
• Meteoroloji ve Atmosfer Bilimleri • Sosyal bilimler ve Davranış bilimleri • Metin Madenciliği (Text Mining) • İnternet madenciliği (Web Mining)
a) Pazarlama: müşterilerin ürün alma serpintileri, coğrafi bilgileri, yeni müşteri kazanma, pazar sepeti analizi, müşteri ilişkileri (CRM – Customer Relations Management), hangi ürünün kampanya edileceğini tespit etme, satış tahmini alanları en yaygın veri madenciliği uygulama alanlarıdır.
b) Banka ve Sigortacılık: Çeşitli ekonomik göstergeler arasında korelasyon tespiti, kredi kartı dolandırıcılıklarının tespiti, borç taleplerinin sonuçlandırılması, banka kartı kullanım alanlarına göre müşteri profili tespiti, sigorta dolandırıcılıklarının belirlenmesi ve yeni müşterilerin tahmininde yoğun olarak kullanılmaktadır.
c) Biyoloji, Tıp ve Genetik: Familya türleri tespiti, gen haritasının ortaya çıkarılması, genetik rahatsızlıkların belirlenmesi, hasta hücrelerin bulunması, yeni virüs tiplerinin keşfi ve sınıflandırılması, fizyolojik analiz ve değerlendirilmesinde kullanılmaktadır.
d) Kimya: Yeni kimyasal moleküllerin bulunması ve gruplandırılması, yeni ilaç cinslerinin bulunmasında kullanılmaktadır.
22
e) Yüzey Analizi ve Coğrafi Bilgi Sistemleri: coğrafi özelliklerine göre
bölgelerin gruplandırılması, şehirlerde yerleşim alanlarını
zenginlik/yoksulluk-suç oranını tespit etme, kentlere yerleştirilecek ATM’lerin yerleri gibi insanlara sunulacak hizmetlerin konumlarının belirlenmesinde kullanılmaktadır.
f) Görüntü Tanıma ve Robot Görüş Sistemleri: Bazı algılayıcılar ile elde edilen görüntülerden yararlanarak engel, yol, yüz, parmak izi, göz tanıma gibi uygulamalarda kullanılmaktadır.
g) Uzay Bilimleri ve Teknolojisi: Gezegen yerleşimleri, yeni gezegen ve yıldız keşfi, gezegen ve yıldızların konumlarına göre sınıflandırılmasında kullanılmaktadır.
h) Meteoroloji ve Atmosfer Bilimleri: meteoroloji tahminleri, iklimlendirme faaliyetleri, deniz ve okyanus hareketlerinin tespiti, hava tabakalarında oluşan deliklerin belirlenmesinde kullanılmaktadır.
i) Sosyal Bilimler ve Davranış Bilimleri: Seçimlere yönelik tahminler, halk yoklamaları değerlendirme, genel yönelim belirleme kullanılmaktadır.
j) Metin Madenciliği (Text Mining): Dağınık ve çok farklı yerlerde bulunan metinler arasında anlamlı ilişkiler oluşturmakta kullanılmaktadır.
k) İnternet Madenciliği (Web Mining): İnternet üzerindeki bilgiler çığ gibi büyüyerek artmaktadır. Aynı zamanda bu veriler giderek karmaşık hale gelmektedir. Basit metinler haricinde kayan fotoğraflar (slider) gibi verilerde bu verilerin arasında bulunmakta olduğundan veriye ulaşım ve verinin işlenme süresinin azaltılması web madenciliğinin temel amacıdır.
l) Eğitim: Veri analizi ile öğrencilerin başarı ve başarısızlık öykülerinin tespiti, öğrencilerin başarılarının devam ettirilmesi ve arttırılmasına yönelik uygulamalar, bir üst okula giriş puanı ve mevcut okul başarısı arasındaki belirlenerek eğitim kalitesini yükseltmeyi amaçlayan uygulamalar gerçekleştirilebilir.
Fayyad (1994)’a göre veri madenciliği, örüntü tanıma, makine öğrenmesi, veri tabanı teknolojileri, yapay zeka, uzman sistemler, istatistik, veri görselleştirme (data visualization) gibi alanlarının ortak noktası olarak doğmuş ve bu kapsamda
23
gelişmesini devam etmektedir (Dinçer 2006). Bu ilişki genel olarak Şekil 2.3’de olduğu gibi görselleştirilebilir.
Şekil 2.9. Veri madenciliğinin diğer disiplinlerle ilişkisi
2.3.5. Veri Madenciliği Yazılımları
Veri Madenciliği uygulamalarını gerçekleştirmek için birçok program geliştirilmiştir. Bu programlara örnek olarak RapidMiner (YALE), R, KoNstanz Information MinEr (KNIME), Knowledge Extraction based on Evolutionary Learning (KEEL), Orange, Nefclass-J ve Waikato Environment for Knowledge Analysis (WEKA), gibi açık kaynak programlar verilebilir. Bu bölümde kısaca en çok kullanılan veri madenciliği programlarına yer verilmiştir.
24 Rapidminer (Yale)
RapidMiner bir yazılım platformu olup, makine öğrenmesi, veri madenciliği, metin madenciliği, tahmin edici analiz ve iş analizi alanlarına yönelik olarak Amerika’daki YALE üniversitesi bilim insanlarınca tasarlanmıştır. Bu yazılım Java dili kullanılarak oluşturulmuştur.
Aml, arff, att, bib, clm, cms, cri, csv, dat, ioc, log, mat, mod, obf, bar, per, res, sim, thr, wgt, wls, xrff uzantısına sahip dosyaları desteklemektedir. Diğer programların aksine format sayısı bakımından zengin olması Rapidminer’ın önemli özelliklerinden biridir (Dener vd 2009).
Açık kaynak kodlu bir platform olduğu için 500’e yakın veri madenciliği metodunu desteklemektedir.Şekil 2.4’de Rapidminer’ın açılış ekranı gösterilmiştir.
25 R
R, istatistiksel hesaplama ve grafikler için geliştirilen bir yazılım ortamıdır. R aynı zamanda programlama dili olup S diline benzeyen bir GNU (GNU Genel kamu lisansı) projesidir (url 5).
R&R olarak da bilinen yazılımın yaratıcıları Yeni Zelanda Auckland Üniversitesinden Ross Ihaka ve Robert Gentleman’dır. R, bazı farklı uygulamaları ile S diline üstündür. Bünyesinde Lineer ve lineer olmayan modelleme, klasik istatistiksel testler, zaman serileri analizi, sınıflandırma, kümeleme gibi özellikleri barındırmaktadır. Ayrıca R, Windows, MacOS X ve Linux işletim sistemlerinde çalışabilmektedir. Ancak Windows veya MacOS üzerinde R’yi çalıştırmak için bilirkişi yardımına ihtiyaç duyulmaktadır. Bu yüzden kullanıcılar genellikle R’yi Unix makineler üzerinde çalıştırmayı tercih ederler.
KNIME
KNIME (Konsatanz Information Miner) adlı veri madenciliği geliştirme yazılımı Konstanz Üniversitesi görsel veri madenciliği araştırmacıları tarafından Eclipse Rich Client Platformu üzerinde geliştirilmiştir.
Knime’ın genişletilebilme özelliği onu bir adım öne çıkmaktadır. Kullanıcılarına sunduğu bir yazılım geliştirme kiti ile onların kendi modüllerini yazabilmelerini sağlaması açısından tek uygulamadır (url 6). Program kurulum şartı olmaksızın çalışabilmekte olan Knime yazılımına .txt uzantılı metin dosyalarından ya da .arff, .table formatından veri yüklenebilmektedir. Bununla beraber en zengin görselleştirme araçları sunan yazılımlarından biridir.
KEEL
KEEL (Knowledge Extraction based on Evolutionary Learning) Java dilinde yazılmış açık kaynak kodlu bir yazılımdır. Granada Üniversitesi tarafından geliştirilen yazılıma İspanya Ulusal Bilim Projeleri Kurumu destek vermiştir. Klasik veri madenciliği algoritmaları bakımından zengin olmayan KEEL, Bulanık sınıflandırıcılar, Yapay zekâ tabanlı sınıflandırma ve Kural tabanlı kümeleme algoritmalarının birçok çeşidini barındırmaktadır (url 7). Ancak KEEL veri
26
madenciliğinde veri görselleştirme bakımından en zayıf yazılımlardan biridir. Şekil 2.5’de KEEL arayüzü verilmiştir.
Şekil 2.11. KEEL arayüzü
Orange
Orange, açık kaynak kodlu bir yazılımdır. Slovenya Ljubljana Üniversitesi Bilgisayar ve Enformatik Bilimleri bölümünde görev yapan ve yapay zekâ araştırmaları üzerinde çalışan ekip tarafından geliştirilmiştir. Qt3 kütüphanesi ve Python kullanılarak geliştirilen ara yüz ve grafik ortamına sahip olan bu yazılım, C++ dili ile yazılmıştır.
Veri madenciliği programı olan Orange veri hazırlama, keşifsel veri analizi, modelleme gibi imkânları kullanıcısına sunar. Veri ön işleme, özellik skorlama ve filtreleme, modelleme, model değerlendirme ve keşif teknikleri gibi geniş kapsamlı bileşenlere sahiptir. Çapraz-platform üzerinde yapılandırılan grafik kullanıcı ara yüzüne sahip Orange, GPL (Genel Kamu Lisansı) altında kullanıcılarına ücretsiz hizmet vermektedir (url 8).
Orange, Linux ve Microsoft Windows gibi pek çok işletim sisteminin çeşitli versiyonlarını desteklemektedir.
27 MATLAB
Temelde grafiksel veri gösterimi ve programlamayı içeren teknik ve bilimsel hesaplamaların yanında nümerik hesaplama yapan yüksek performanslı bir yazılım ve dördüncü nesil programlama dili olan MATLAB’ın genel kullanım alanları şöyle sıralanabilir (url 9) :
• Çeşitli matematiksel ve hesaplama işlemleri • Algoritma geliştirme ve programlama
• Lineer cebir, istatistik, fourier analizi, filtreleme, optimizasyon, sayısal integrasyon vb. konularda matematik fonksiyonlar.
• 2 boyutlu ve 3 boyutlu grafik çizme
• Modelleme, simülasyon (benzetim) ve ön tipleme • Grafik kullanıcı arayüzü oluşturma
• Veri analizi ve görsel efektler ile destekli gösterim • Bilimsel ve mühendislik grafikleri
• Uygulama geliştirme şeklinde özetlenebilir.
MATLAB ismi, MATrix LABoratory (Matrix Laboratuvarı) kelimelerinden türetilmiştir. MATLAB, ilk zamanlar Linpack ve Eispack projeleri ile geliştirilip daha sonraları bu projelere daha kolay erişim elde etmek amacı ile 1970’li yılların sonlarında Amerika Birleşik Devletleri merkezli MathWorks şirketi tarafından yazılmıştır. Başlarda bilim insanlarına yardım etme biçimi problemlere matris temelli teknikler ile çözüm üretmekteydi. Günümüzde ise geliştirilen yerleşik kütüphanesinin yanı sıra sahip olduğu uygulama ve programlama özellikleri sayesinde, özellikle matematik ve mühendislik alanları olmak üzere tüm bilim dallarında kullanılmaktadır. Ayrıca sanayi sektöründe de yüksek verimli araştırma, geliştirme ve analiz aracı olarak kendisine yaygın bir kullanım alanı bulmuştur. İlaveten Toolbox altında çeşitli alanlarda hizmet veren alt programları ile özel ve oldukça kolaylaştırılmış seçenekler sunmaya devam etmektedir. Sinir ağları, wavelet, bulanık analiz sadece bunlardan birkaçıdır (url 10).
28 Şekil 2.12. MATLAB arayüzü
NEFCLASS-J
NEFCLASS-J, JAVA'da yazılmış nöro-bulanık sınıflandırma aracıdır. NEFCLASS-PC ve NEFCLASS-X gibi modellerde olduğu gibi NEFCLASS modeline dayanmaktadır.
Uygulama, örneğin, bulanık kümelerin ya da kullanılacak olan çıkarım işlevlerinin (bağlanma, ayrılma) çok esnek seçimlerine izin verir. Ayrıca, nefclass modelinin mevcut uzantılarının çoğu bu uygulamaya dâhil edilmiştir. Bu uzantıların çoğu, gerçek dünyadaki veriler ve analizi ile ilgili özel karakteristik ve problemleri ele almaktadır (url 11).
WEKA
WEKA, “Waikato Environment for Knowledge Analysis” kelimelerinin kısaltılmasıdır. Bu araç, Yeni Zelanda’da bulunan Waikato Üniversitesi’nde 1993 yılında C diliyle yazılmaya başlanan bir veri madenciliği yazılımıdır. 1996’da ilk
29
resmi sürümü yayınlanmıştır. 1997 yılında ise geliştirilerek Java diliyle güncellenmiştir. Sonraki sürümleri de Java dili ile geliştirilmeye devam etmektedir. Açık kaynak kodlu (opensource) bir yazılımdır. Açıldığında Şekil 2.7’deki gibi bir arayüzle karşılaşılır. Ara yüzde yer alan ve WEKA’ nın logosu olan kuş, programa ismini verdiği, sadece Yeni Zelanda adalarında bulunan ve nesli tükenmiş bir kuş türüdür (Şeker 2016).
Şekil 2.13. WEKA aracının arayüzü
Bir çeşit veri dosya türü olan “.arff” (Attribute Relationship File Format) WEKA’ya özel tasarlanmış bir dosya formatıdır. WEKA bu format üzerinde çalışır. Bunun dışında metin tabanlı csv, c45, libsvm, svmlight, Xarff formatları, desteklemektedir. Ayrıca “jdbc” (Java Derby Client) sürücüsü bulunan veri tabanlarına doğrudan bağlantı yapabilmektedir. İnternet üzerinden http protokolünü kullanarak bu formatlara uygun dosyaları okuyabilme yeteneğine sahip olması da bir diğer özelliğidir.
WEKA, makine öğrenmesi yazılımı olup temel olarak sınıflandırma (classification), kümeleme (clustering), demetleme, birliktelik analizi (association
30
analysis), veri ön işleme (pre-processing) gibi temel veri madenciliği işlemlerini yapılabilmektedir. Bu anlamda veri madenciliği çalışmaları için oldukça kullanışlıdır. WEKA beş farklı modülden oluşmaktadır. Bunlar:
1) Explorer: Ana işlemlerin yürütüldüğü ara yüzdür. Bu kısımda veri kümesi görüntülenebilir, veriye ön işleme yapılabilir, sınıflandırma, kümeleme ve birliktelik işlemleri gerçekleştirilebilir.
2) Experimenter: Deneylerin gerçekleştirildiği ve öğrenme şemaları arasında istatistiksel testlerin yürütüldüğü ortamdır.
3) KnowledgeFlow: Explorer ortamında var olan özelliklerin sürükle bırak tekniğiyle gerçekleştirilebildiği bölümdür. Explorerdan farklı olarak veri seti üzerinde zincirleme işlemler yapılan ve veri seti üzerinde modüler tasarım yapılabilen bölümdür.
4) Workbench: WEKA’nın en gelişmiş makine öğrenim koleksiyonudur. Kullanıcıların yeni veri setleri üzerinde mevcut makine öğrenme yöntemlerini hızlı bir şekilde ve çok esnek yollarla uygulayabilmesini mümkün hale getirmek için tasarlanmıştır. Tüm standart veri madenciliği yöntemlerini barındırmaktadır. Birçok veri görselleştirme olanağı ve veri ön işleme araçları sunmaktadır.
5) Simple CLI (Command Line Interface): WEKA yazılımı komut satır ara yüzü ile kullanıcıların kendi algoritmalarını yazmalarına, eklentiler yapmalarına olanak tanır.
ARFF Dosya Yapısı:
ARFF, WEKA programına özgü olan basit bir metin dosya formatıdır. Attribute Relationship File Format kelimelerinin kısaltmasından oluşmaktadır (Şeker 2016).
ARFF dosyası bir metin editörü kullanılarak açıldığında Şekil 2.8’de gösterildiği gibi ‘%’ işareti ile başlayan satırlar ekrana çıkmaktadır. Bu satırlar program tarafından dikkate alınmayan, sadece kullanıcıya veri seti hakkında veya veri setini hazırlayan kişiler hakkında kısa bilgiler sunan yorum ya da açıklama satırlarıdır.
31
@RELATION ifadesi ile veri setinin başlığı verilir. Burada yazılan başlık aynı zamanda veriler programa yüklenirken görülen veri seti ismidir.
@ATTRIBUTE ile tanımlanan özellikler veri kümesinin kolonlarını oluşturmaktadır. Özellikler girilirken kullanılan bazı temel veri tipleri vardır. Bunlar; REAL, NUMERIC, DATE, STRING ve NOMINAL’dir. REAL ve INTEGER sayısal yani nümerik veriler için tanımlanan veri tipleridir. Farkları INTEGER tam sayıları ifade ederken REAL ise tüm gerçel sayıları ifade etmektedir. DATE veri tipi tarih tipli değişkenler için tanımlanırken STRING veri tipi ise metin yada karakter tipli değişkenler için tanımlanır. Bir küme şeklinde olan veriler ise NOMINAL olarak tanımlanır. Kullanımı @ATTRIBUTE class{…} şeklindedir (Şekil 2.8).
@DATA ifadesi ile başlayan kısım ise verilerin bulunduğu kısımdır. Bu kısımda yazılan veriler @ATTRIBUTE kısmında tanımlanan özelliklerin sırasına göre oluşturulur. Ayrıca veriler girilirken veri aralarına ‘,’( virgül) koyulmaktadır. Bu kurallara uyulmazsa WEKA’ ya veri seti yüklemesi yapılamaz.
Yukarıda anlatılan kurallara uygun şekilde hazırlanan ve WEKA programına sorunsuz şekilde yüklenilebilen hazır veri seti “Segment Challenge” örnek olarak şekil 2.8’de verilmiştir.
32
Şekil 2.14. WEKA aracının kullandığı .arff türü örnek veri seti dosyası
3. MATERYAL ve YÖNTEM
3.1. Uygulama Veri Seti: Karaciğer Hasta Veri Seti Analiz Bilgisi
Bu çalışmada kullanılan veri seti, http://archive.ics.uci.edu/ml/index.php Internet adresinden ücretsiz olarak erişilebilen ve herkesin kullanımına açık olan UCI Machine Learning Respository veri tabanında bulunan Karaciğer Hastalığı Veri Seti (Indian Liver Patient Dataset (ILPD))’dir.
Bu veri seti 583 hasta kaydından oluşmaktadır. Bu hastalardan 416 tanesi karaciğer hastası olup 167 tanesi diğer hastalardır. Veri seti Hindistan'ın Andhra Pradesh’in kuzey doğusunda toplanmıştır. Bu veri seti 441 erkek hasta kaydı ve 142
Veri seti başlığı
Veri seti değişkenleri