Comparison of local and global computation and its implications for the role of optical interconnections in future nanoelectronic systems
Tam metin
Şekil
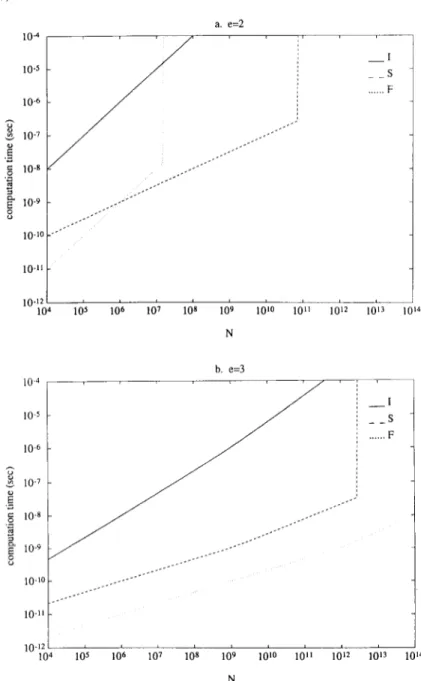
Benzer Belgeler
52 Figure 4.15: Cell viability data (MTT assay) of MCF7 cells treated with siRNA CHRNA5 and mimic-mir-497 single or alone with different doses A) by using 1.2µl transfection
East European Quarterly; Summer 2000; 34, 2; Wilson Social Sciences Abstracts pg... Reproduced with permission of the
One of the rare attempts to bring these two lines of research together is made in Boyle and Guthrie (2003). They assign uncertainty not only to project value, but also
Tabiat Parkı alanı sınırları birçok koruma alanında olduğu gibi yerleşim alanlarını dışarıda bırakacak şekilde geçirilmiştir.
Hence, in order to reduce and gradually overcome the resistance to price changes and therefore eventually remove an important barrier to the success of a market
On the enhancer side, if we used same thickness and material of thin film instead of superenhancer wire, we would observe typical thin film interference based enhancement (i.e.
Türkiye’de yapılan yasadışı maddelerle ilgili yaygınlık çalışmaları ve Türkiye Uyuşturucu ve Uyuşturucu Bağımlılığı İzleme Merkezi’nin (TUBİM)
Öz: Pîr Ahmed Efendi, XVI. yüzyılda Kütahya’da yaşamış, neslinden Müftî Derviş, Sunullâh-ı Gaybî gibi âlimler yetişmiş önemli bir zattır. Halvetî gelenekten gelen
