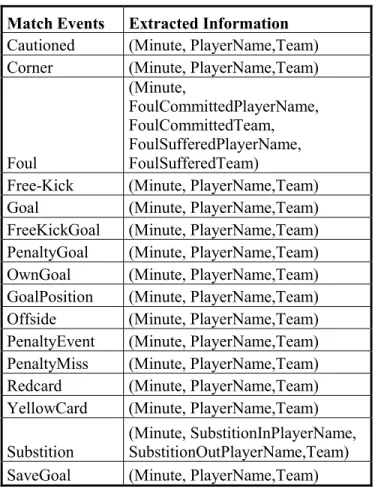
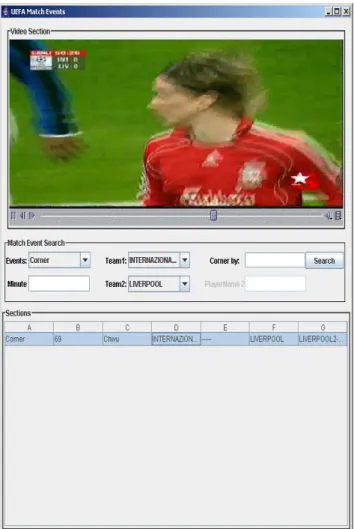
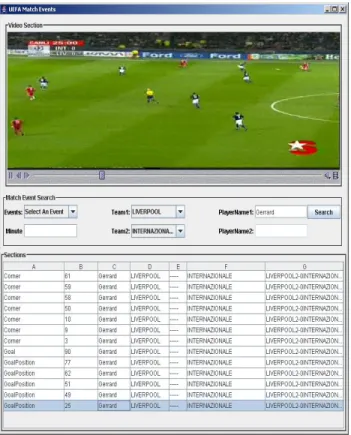
Metadata extraction from text in soccer domain
Tam metin
Şekil

Benzer Belgeler
Basis vectors can be defined as the coordinates of atoms, which lie inside the unit cell paralleloid, defined by the primitive vectors and the origin. The data structure used in
Preprocessing techniques using a static dictionary would replace words in a given text file by a character encoding that represents a pointer to encoded word in the
Then, you should go shopping at Khan Al-Khalili, go for a walk in Zamalek, and spend time in Islamic Cairo.. Mike: Sydney is an excellent place to have an enjoyable holiday,
The growing city has lots of alternatives such as shopping mall, sports activities. Düden waterfall,Konyaaltı beach,Aspendos ancient theatre are some of the most important places
She can play piano.. She can
She can ride a horse.. He can sing
Draw the time shown on each clock.. get on the
Draw the time shown on each clock.. get on the bus
