T.C.
SELÇUK ÜNİVERSİTESİ FEN BİLİMLERİ ENSTİTÜSÜ
VERİ MADENCİLİĞİNDEN BİRLİKTELİK KURALI İLE ONKOLOJİ VERİLERİNİN
ANALİZ EDİLMESİ: MERAM TIP FAKÜLTESİ ONKOLOJİ ÖRNEĞİ
Adnan KARAİBRAHİMOĞLU
DOKTORA TEZİ İstatistikAnabilim Dalı
Ağustos-2014 KONYA Her Hakkı Saklıdır
iii
Bu tezdeki bütün bilgilerin etik davranış ve akademik kurallar çerçevesinde elde edildiğini ve tez yazım kurallarına uygun olarak hazırlanan bu çalışmada bana ait olmayan her türlü ifade ve bilginin kaynağına eksiksiz atıf yapıldığını bildiririm.
DECLARATION PAGE
I hereby declare that all information in this document has been obtained and presented in accordance with academic rules and ethical conduct. I also declare that, as required by these rules and conduct, I have fully cited and referenced all material and results that are not original to this work.
İmza
Adnan KARAİBRAHİMOĞLU Tarih: 12/08/2014
iv
ÖZET DOKTORA TEZİ
VERİ MADENCİLİĞİNDEN BİRLİKTELİK KURALI İLE ONKOLOJİ VERİLERİNİN ANALİZ EDİLMESİ: MERAM TIP FAKÜLTESİ ONKOLOJİ
ÖRNEĞİ
Adnan KARAİBRAHİMOĞLU Selçuk Üniversitesi Fen Bilimleri Enstitüsü
İstatistik Anabilim Dalı Danışman: Prof. Dr. Aşır GENÇ
2014, 126 Sayfa Jüri
Prof. Dr. Aşır GENÇ Doç. Dr. Coşkun KUŞ Prof. Dr. Melih Cem BÖRÜBAN
Doç. Dr. Buğra SARAÇOĞLU Yrd. Doç. Dr. Aydın KARAKOCA
Teknoloji ile birlikte yaşamın her alanında artan veri miktarı “veri ambarları” kavramını gündeme getirmiştir. Veri madenciliği, ortaya çıkan çok büyük veri kümelerinin oluşturduğu veri ambarlarının analiz edilerek yararlı bilgiler elde edilmesini sağlayan yaklaşımlar bütünüdür. Veri miktarının büyük olduğu ve her geçen gün arttığı alanlardan birisi de sağlık sektörüdür. Her gün binlerce hastaya ait gerek kişisel gerek tıbbi veriler kayıt altına alınmakta ve bu enformasyon depolanmaktadır. Ancak bu verilerin çok az bir kısmı analiz edilebilmekte ve geriye kalan kısmından faydalı olabilecek enformasyon elde edilememektedir. Özellikle hastane yönetim sistemleri, tedavi yöntemleri ve koruyucu hekimlik konusunda maliyetleri azaltıcı yöntemlerin geliştirilmesi için ambardaki verilerin analiz edilmesi gerekmektedir. Klasik istatistiksel yöntemler ile büyük veri kümelerini analiz etmek zor olduğu için, çeşitli veri madenciliği yöntemleri geliştirilmiş ve bilgisayar programcılığı yardımıyla analiz yapmak daha uygulanabilir hale gelmiştir. Birliktelik kuralı, sağlık alanında yeni kullanılan analiz yöntemlerinden birisi olup; değişkenlerin birlikte görülme olasılıkları üzerinden örüntü oluşturmak ve buna bağlı olarak destek ve güven değerlerini hesaplamak için kullanılmaktadır. Bu çalışmada, Meram Tıp Fakültesi Onkoloji Hastanesine ait retrospektif çalışma sonucu elde edilen göğüs kanseri verileri üzerinde APRIORI algoritması uygulanacak ve verilerdeki birliktelik örüntüleri ortaya çıkarılmaya çalışılacaktır.
Anahtar Kelimeler: Apriori algoritması, Birliktelik kuralı, Destek, Güven, Veri madenciliği
v
ABSTRACT Ph.D. THESIS
ANALYZING BREAST CANCER DATA USING ASSOCIATION RULE MINING: MERAM FACULTY OF MEDICINE ONCOLOGY DEPARTMENT
Adnan KARAİBRAHİMOĞLU
THE GRADUATE SCHOOL OF NATURAL AND APPLIED SCIENCE OF SELÇUK UNIVERSITY
DOCTOR OF PHILOSOPHY IN STATISTICS Advisor: Prof. Dr. Aşır GENÇ
2014, 126Pages Jury
Prof. Dr. Aşır GENÇ Assoc. Prof. Coşkun KUŞ Prof. Dr. Melih Cem BÖRÜBAN Assoc. Prof. Buğra SARAÇOĞLU
Asst. Prof. Aydın KARAKOCA
The amount of data, increasing together with the technology, has brought the concept of “data warehouse” in every field of life. Data Mining is a set of approaches analyzing these data warehouses formed by very large data sets and allows to gather useful information. One of the fields where the amount of data is large and getting larger everyday is the health sector. Many personal and medical data belonging to thousands of patients are recorded and stored. However, small part of these data can be analyzed and the remaining part may not be helpful to obtain useful information. The data in warehouses must be analyzed to improve the methods for hospital management systems, treatment and health care systems to reduce the costs. Since analyzing large data sets using classical statistical methods is difficult, various data mining methods have been developed and these methods have become more feasible with the help of certain softwares. Association rule is an important data-mining task to find hidden patterns between the variables and used recently in the field of healthcare. In this study, we will calculate the support and confidence of the associations in data set. APRIORI algorithm will be applied onto the retrospectively obtained breast cancer data belonging to Oncology Hospital of Meram Faculty of Medicine.
vi
ÖNSÖZ
“İlim ilim bilmektir İlim kendin bilmektir
Sen kendin bilmezsen Bu nice okumaktır”
dizeleriyle “Beşikten mezara kadar ilim öğreniniz” sözünün açılımını yapmış olan Yunus Emre, içimdeki öğrenme duygusunu harekete geçirerek bugünlere getirdi. Fakat bu yolculuk tek başına olmazdı. Bir eğitim süreci olduğundan her zaman minnetle anacağım hocalarım oldu.
Yüksek Lisans döneminden danışman hocam Prof. Dr. Hamza EROL’a; doktora eğitimine başladığımda ilk danışmanım olan Prof. Dr. Necati YILDIZ’a; Selçuk Üniversitesi’nde İstatistiğin kapılarını bana açan ve akademik dünyaya girebilmem için elinden geleni yapan danışmanım ve değerli hocam Prof. Dr. Aşır GENÇ’e teşekkürlerimi borç bilirim.
Bu tez, nasıl bir konu üzerinde çalışsam diye düşünürken işyerindeki bir arkadaşımın fikir vermesiyle ortaya çıktı. Bunun üzerine makale taramaya ve konuyu öğrenmeye başladım. Şu an geldiğim seviye istediğim düzeyde olmasa da üç yıl öncesine göre kendimi ilerlemiş hissediyorum.
Ayrıca, Tıp Eğitimi ve Bilişimi Anabilim Dalı başkanı Doç. Dr. Nazan KARAOĞLU’na doktora eğitimi boyunca desteklerini esirgemedikleri; veri kümesini analizler için benimle paylaşan değerli dostum Tıbbi Onkoloji bölüm başkanı Prof. Dr. Melih Cem BÖRÜBAN’a çok teşekkür ederim.
Ve tabi ki ailem…
Başta dualarıyla manevi olarak yardımını hiçbir zaman esirgemeyen annem; kendileri ile daha fazla zaman geçirmem gerekirken tezle ilgilenmek zorunda kalarak vakit ayırmadığım çocuklarım Zeynel, Ceyda ve Onur; yıllardan beri tüm sıkıntılara benimle beraber göğüs geren, çoğu zaman beni sırtlayan, beni cesaretlendiren desteğini her zaman yanımda hissettiğim çok sevgili eşim Nesrin; sizlere çok ama çok teşekkür ediyorum.
Adnan KARAİBRAHİMOĞLU KONYA-2014
vii İÇİNDEKİLER ÖZET ... iv ABSTRACT ...v ÖNSÖZ ... vi İÇİNDEKİLER ... vii SİMGELER VE KISALTMALAR ... ix 1. GİRİŞ ...1 2. KAYNAK ARAŞTIRMASI ...3 3. MATERYAL VE YÖNTEM ...5
3.1. Veri Madenciliği’nin Tarihçesi ...5
3.2. Enformasyon Kavramı ...7
3.3. Keşfedici Veri Analizi ...8
3.4. Veri Tabanları ... 11
3.5. Veri Ambarları... 13
3.5.1. Veri Ambarı Oluşturulması ... 14
3.5.2. Veri Ambarının Özellikleri ... 16
3.6. Veri Madenciliği Süreci ... 19
3.6.1. Verilerin Hazırlanması ... 22
3.6.2. Veri Madenciliği Yönteminin Uygulanması ... 25
3.6.3. Sonuçların Değerlendirilmesi ve Sunulması ... 28
3.6.4. Veri Madenciliği Uygulama Programları ... 35
3.6.5. Veri Madenciliği Uygulamasında Karşılaşılan Sorunlar ... 35
3.7. Veri Madenciliği Yöntemleri ... 36
3.7.1. Sınıflandırma Yöntemleri... 37
3.7.1.1. Karar Ağaçları ... 38
3.7.1.2. Bayes/Naïve-Bayes Sınıflandırma ... 41
3.7.1.3. k-En Yakın Komşu (k-ortalama) algoritması ... 42
3.7.1.4. k-medoid ... 43
3.7.1.5. Destek Vektör Makineleri (SVM) ... 43
3.7.1.6. Yapay Sinir Ağları (Artificial Neural Networks) ... 44
3.7.1.7. Genetik Algoritma ... 46
3.7.1.8. Bellek Temelli Nedenleme (Memory Based Reasoning) ... 47
3.7.1.9. Regresyon ... 48
3.7.2. Kümeleme Yöntemleri ... 48
3.7.2.1. Hiyerarşik Yöntemler ... 51
3.7.2.2. Bölümlemeli Yöntemler ... 51
3.7.2.3. K-Ortalamalar (K-Means) Bölümleme Yöntemi... 52
3.7.2.4. K-Medoids Bölümleme Yöntemi ... 53
3.7.2.5. PAM Algoritması ... 54
3.7.2.6. CLARA Algoritması ... 54
viii
3.7.3. Yoğunluğa Dayalı Yöntemler ... 55
3.7.4. Izgara Tabanlı Yöntemler ... 56
3.7.5. Dalga Kümeleme (Wave Cluster) ... 57
3.7.6. Kohonen Ağlar (Kohonen Networks) ... 57
3.8. Birliktelik Kuralı (Association Rule Mining) ... 58
3.8.1. İlişki Analizi (Affinity Analysis) ... 58
3.8.2. Market Sepeti Analizi (Market Basket Analysis) ... 59
3.8.3. Destek, Güven ve Kaldıraç Kavramları (Support, Confidence and Lift) ... 61
3.8.4. Büyük Nesne Kümeleri (Large Itemsets) ... 63
3.8.5. Örüntü ve Kural Çıkarma (Pattern Recognition and Rule Extraction) ... 64 3.8.6. Algoritmalar ... 65 3.8.6.1. AIS Algoritması ... 65 3.8.6.2. SETM Algoritması ... 65 3.8.6.3. Apriori Algoritması ... 66 3.8.6.4. Apriori-TID Algoritması ... 68
3.8.6.5. Paralel Veri Madenciliğinde Birliktelik (Parallel Data Mining) ... 69
3.8.7. Negatif Birliktelik Kuralı (Negative Association Rule) ... 69
3.9. Önerilen İlginçlik Ölçütü ... 75
3.10. Genelleştirilmiş Birliktelik Kuralları (Generalized Rule Extraction) .. ... 78
3.11. Birliktelik Kuralı Uygulama Alanları ... 80
3.12. Veri Madenciliği ve Sağlık Sektörü Uygulamaları ... 81
4. ARAŞTIRMA SONUÇLARI VE TARTIŞMA ... 83
4.1. Kanser ve meme kanseri ... 83
4.2. Verinin Hazırlanması ... 85
4.2.1. Analizler İçin Paket Programlar ... 85
4.2.2. SPSS Clementine ile Veri Madenciliği ... 85
4.2.2.1. Modelleme ... 87
4.2.2.2. Clementine ve Association Rules... 89
4.2.2.3. Apriori Kural Keşfi ... 90
4.3. Teze İlişkin Veriler ... 91
4.4. Bulgular ... 93 5. SONUÇLAR VE ÖNERİLER ... 104 5.1. Sonuçlar ... 104 5.2. Öneriler ... 106 KAYNAKLAR ... 107 EKLER ... 115 6. ÖZGEÇMİŞ ... 116
ix
SİMGELER VE KISALTMALAR
ARM: Association Rule Mining-
BKA: Biçimsel Kavram Analizi
CARMA: Continuous Association Rule Mining Algorithm
CCD: Count Distribution
CCPD: Common Candidate Partitioned Database
CEMI: Clementine External Module Interface
CLARA: Clustering LARge Applications (Geniş Uygulamaların Kümelenmesi)
CLARANS: Clustering Large Applications based on RANdomized Search (RasgeleAramaya Dayalı Geniş Uygulamaların Kümelenmesi)
CLIQUE: Clustering in Quest
DBMS: Database Management Systems
DBSCAN: Density Based Spatial Clustering of Applications with Noise
DD: Data Distribution
DENCLUE: Algoritması DENsity Based CLUestEring
DVM: Destek Vektör Makineleri
EDA: Explanatory Data Analysis
GRI: Generalized Rule Induction
HRA: Hash-based Parallel Mining of Association Rules
IDD: Intelligent Data Distribution
KDD: Knowledge Discovery from Data Mining (Veri Tabanlarından
Bilgi Keşfi)
KVA: Keşfedici Veri Analizi
MAP: Maximum A Posteriori Classification
MBR: Memory Based Reasoning (Bellek Temelli Nedenleme)
OCD: Off-line Candidate Determination
OLAP: On-Line Analytical Processing
PAM: PartitioningAroundMedoids (Temsilciler Etrafında Bölümleme)
PAR: Parallel Association Rule
PCA: Principal Component Analysis
PDM: Parallel Data Mining
RBF: Radial Base Function
RDBMS: Relational Database Management Systems
RVM: Relevance Vector Machine-
SOM: Self OrganizingMap
SVM: Support Vector Machines
TID: Transaction Identification
VM: Veri Madenciliği
1. GİRİŞ
İstatistik ve bilgi sistemlerinin karar sistemleri ile olan etkileşimi dünya dinamiklerini, ülkeleri, sektör, alt sektör ve firmaları önemli düzeyde etkilemektedir. Bu etkilerin ortaya çıkarılması ve yorumların içselleştirilmesi bilimsel katma değeri yüksek bir olgudur (Güvenen, 2011).
Önceki çağların tek bir adı olmasına karşın içinde bulunduğumuz çağ için birçok isim kullanılmaktadır. "Enformasyon Çağı”, “Teknoloji Çağı”, Bilgisayar Çağı” örneklerden birkaçıdır. Teknoloji ilerledikçe bilgisayar kullanımı artmakta, bu artışa paralel olarak ta “veriler” oluşmaktadır. Veri miktarındaki hızlı artış, depolama sorunlarını beraberinde getirmekte ve her geçen gün depolama ünitelerinin daha yüksek kapasiteli ve daha hızlı bir yapıya sahip olmasını gerektirmektedir. Bu durumda iki temel sorun karşımıza çıkmaktadır. Birincisi, depolanan verilerin güvenlik sorunu; ikincisi ise arşivlenen veri yığınları ile nelerin yapılacağıdır. Veritabanı denilen bu yığınların içerisinde belki de stratejik öneme sahip bilgiler gizli olabilir. O halde, bir sürü ağacın olduğu bir yerde orman hakkında ne gibi anlamlı sonuçlar çıkarılabilir?
Sorunun cevabı veri madenciliğidir. Dünya çapındaki yenilikçi organizasyonlar veya işletmeler müşterilerinin şikâyetlerini değerlendirmek, ürünlerini yeniden düzenlemek veya kayıplarını en aza indirgemek için kısacası gelirleri artırmak, masrafları azaltmak için veri madenciliğini kullanmaktadırlar (Edelstein, 1999).
Veri madenciliği, veriler arasındaki ilişkiyi bulup geçerli tahminler yapmak ve model ortaya koymak için çeşitli veri analiz yöntemlerini kullanan bir süreçtir. İlk adım, veriyi tanımlamaktır. İstatistiksel özelliklerini (örneğin; ortalama veya standart sapma), grafik veya şekiller yardımıyla görsel yapısını ve değişkenler arasındaki potansiyel olarak anlamlı ilişkileri ortaya koymaktır. Veriyi tanımlamak yalnız başına planımızı harekete geçirmez. İkinci aşama, tahminleyici bir model oluşturmaktır. Model, orijinal örneğin haricindeki veriler üzerinde test edilir. İyi bir model hiçbir zaman gerçekle karıştırılmamalıdır fakat sonuçları anlamak açısından çok faydalı olacaktır. Son basamak ise modelin deneysel olarak doğrulanmasıdır (Alpaydın, 2000).
Bu çalışmada genel olarak veri madenciliği yöntemleri konusu ele alınacaktır. Çalışmanın ikinci bölümünde veri madenciliği yöntemleri ve özellikle birliktelik kuralının gelişimi ve literatürdeki uygulamaları üzerinde durulacaktır. Üçüncü bölümde veri madenciliği tanımı, tarihsel seyri, ilişkili olduğu disiplinler ve yöntemleri geniş
olarak anlatılacaktır. Ayrıca sınıflandırma analizi başlığı altında karar ağaçları (decision
trees), yapay sinir ağları (artificial neural networks), k-en yakın komşu (k-nearest neighbour) ve kümeleme analizi başlığı altında birliktelik kuralı (association rule),
k-ortalama (k-means algorithm) algoritması yöntemleri detaylı olarak anlatılacaktır. Dördüncü bölümde hastane verileri ile birliktelik kuralı uygulaması yapılacak ve sonuçları ortaya konulacaktır. Son bölümde ise çalışmaya ait sonuç ve önerilere yer verilecektir.
2. KAYNAK ARAŞTIRMASI
Veri madenciliğinin tarihi J. Tukey’nin (1977) ortaya attığı Keşfedici Veri Analizi (Exploratory Data Analysis) çalışmalarına kadar dayanır. Klasik istatistiksel yöntemlerin katı varsayımları nedeniyle veri setlerinin yeterince analiz edilemediğinden hareketle yeni teknikler ortaya atılmış ve veri örüntüleri arasındaki ilişkilerin ortaya çıkarılması için her geçen gün sağlam (robust) ve keşfedici yöntemler geliştirilmiştir. KVA (EDA) teknikleri için Tukey (1977) ve Hoaglin et al. (1983)’e, sağlam (robust) teknikler için ise yine Hoaglin et al. (1983) ve Huber (1981)’e başvurulabilir. 90lı yıllarda bilgisayar teknolojilerinin de gelişmesi ile birlikte bilgisayar mühendisleri tarafından “veri madenciliği” kavramı ortaya atıldı. Daha önceki dönemlerde taramalar oldukça uzun sürüyordu fakat istenilen verilere ulaşmak mümkündü. Bu nedenle, büyük miktarda veriler üzerinde yapılan işlemler için veri taraması (data dredging), veri yakalama (data fishing), bilgi çıkarımı (knowledge extraction), örüntü analizi (pattern analysis) veya veri arkeolojisi (data archeology) gibi isimler kullanılmıştır. Keşfedici Veri Analizi kavramıyla birlikte Veri Tabanlarından Bilgi Keşfi (Knowledge Discovery from Data Mining-KDD) kavramı gelişmiş ve bu haliyle kullanılmaya devam edilmiştir. Kimileri veri madenciliği ile KDD’yi eş anlamlı görürken kimileri ise veri madenciliğini bilgi keşfi sürecinin bir adımı olarak görmektedirler.
Veri madenciliği çalışmaları geniş haliyle Fayyad et al.(1996) tarafından ortaya konulmuş ve bilgi keşfi konusunda yeni teknikler geliştirmişlerdir. Fayyad “veri madenciliği, verideki geçerli, alışılmışın dışında, kullanışlı ve anlaşılabilir örüntülerin(pattern) belirlenmesi sürecidir” tanımını yapmaktadır. Daha çok regresyon çalışmaları ile veri madenciliğine katkıda bulunan Friedman (1997) ise “veri madenciliği, geniş veri tabanlarında bilinmeyen ve beklenmeyen bilgi örüntülerini araştıran bir karar destek sürecidir” şeklinde bir tanım getirmektedir. Aynı şekilde, Zekulin (1997), Ferruza (1998), John (2009) gibi veri madenciliği konusunda çalışan önemli isimler de aynı yönde tanımlar getirmişlerdir.
Veri madenciliğinde en önemli iki analiz sınıflandırma analizi ve kümeleme analizidir. Sınıflandırma analizi, istatistiğin birçok dalında çalışmalar yapmış olan Fisher (~1920)’in çalışmalarına dayanır. Sınıflandırma analizi tekniklerinden olan yapay sinir ağları konusu Anderson (1977), Kohonen (1977) ve Hopfield (1982) tarafından geliştirilmiştir. Dasarathy (1991) ise k-en yakın komşu algoritmaları üzerinde çalışmış, Shakhnarovish ve Darrel (2005) bu algoritmayı daha da geliştirmişlerdir.
Kümeleme analizi aynı tip verilerin bir arada bulunarak gruplandırılması temeline dayanan bir analiz yöntemidir. Sibson (1977)’ın çalışmaları ile başlayan yöntem, Ng ve Han (1994) tarafından CLARANS tekniği olarak, ayrıca Zhang (1996) tarafından BIRCH tekniği şeklinde geliştirilerek günümüze kadar gelmiştir. Kümeleme analizi yöntemlerinden olan ve bu tezde uygulamasını göstereceğimiz teknik, birliktelik kuralı (Association Rule) dır. 1994 yılında IBM Almaden Araştırma Merkezi’nde Agrawal ve Srikant tarafından geliştirilmiştir.
3. MATERYAL VE YÖNTEM 3.1. Veri Madenciliği’nin Tarihçesi
İkinci Dünya Savaşı’nın en hareketli ve kızıştığı dönemlerde askeri amaçlı, şifre çözmeye yarayan bir makine geliştirildi. ENIAC adı verilen makine, daha sonraları von
Neumann (1945) mimarisi ile geliştirilerek 80’lerde kişisel kullanım (PC) makinelerine
kadar gelişti. Büyük alan kaplayan, tonlarca ağırlığa sahip yüzlerce tüp ile çalışan ENIAC’tan artık avuç içine sığacak kadar küçülen, fakat hızı ve işlem kapasitesi çok yüksek olan bilgisayarlara ulaşıldı. Günümüz bilgisayarları hala aynı mimari mantığıyla çalışmaktadır. Dolayısıyla daha önceki yıllarda çeşitli makineler geliştirilmesine karşın, bilgisayarın atası ENIAC-EDVAC kabul edilmektedir. Başlarda hızlı hesap yapması için tasarlanan bilgisayarlar zamanla bilgi depolamak zorunda kaldılar. PunchCard (Delikli Kart) ile başlayan hafıza ünitelerini disketler, CD’ler, DVD’ler, taşınabilir flash bellekler izledi. Depolama kapasitesi son derece arttı. Günümüzde depolama ünitelerinin kapasitesi “terabayt”lar şeklinde ifade ediliyor. 1 TB, yaklaşık 106 MB’a ve o da yaklaşık 8*1012 bit’lik bilgiye karşılık gelmektedir. İlerleyen yıllarda TB ifadesi de çok küçük kalacak ve yeni üniteler geliştirilecektir.
Ülkemizde ise ilk bilgisayar IBM-650 olup, yol hesapları yapması için 1960 yılında Karayolları Genel Müdürlüğü tarafından getirilmiştir. Bunu diğer kurumlar ve çeşitli üniversiteler takip etmiştir. Son yapılan araştırmalara göre yaklaşık %35 oranında hanelerde bilgisayar ve %42 oranında internet kullanımı vardır. Resmi kurumların tamamı bilgisayar ve internet kullanımına sahipken girişimlerde ise %92 lik bir oranda bilgisayar kullanımı ve internet erişimi mevcuttur. Teknolojiyi kullanmak açısından ülkemiz, birçok dünya ülkesi ile paralel gitmektedir.
Modern çağda insanın etkileşim içinde olduğu her alanda bilgisayarlar ve internet yoğunluklu bir şekilde kullanılmaktadır. Her alışverişte, her bankacılık işleminde, her telefon kullanımında veya her medya kaynaklarına ulaşmada veriler oluşmaktadır. Sadece uydu ve diğer uzay araçlarından elde edilen görüntülerin saatte 50 gigabyte düzeyinde olması, bu artışın boyutlarını daha açık bir şekilde göstermektedir.1995 yılında birincisi düzenlenen Knowledge Discovery in Databases konferansı bildiri kitabı sunuşunda, enformasyon teknolojilerinin oluşturduğu veri dağları, aşağıdaki cümleler ile vurgulanmaktadır.
“Dünyadaki enformasyon miktarının her 20 ayda bir ikiye katlandığı tahmin edilmektedir. Bu ham veri seti ile ne yapmamız gerekmektedir? İnsan gözleri bunun ancak çok küçük bir kısmını görebilecektir. Bilgisayarlar bilgelik pınarı olmayı vaat etmekte, ancak veri sellerine neden olmaktadır. “
Dünyadaki büyük işletmelerin veri tabanlarının belirlenmesi amacı ile Winter Corporation tarafından yapılan bir araştırmada, Sears, Roebuckand Co.’nun sadece karar destek amaçlı kullanılan veri tabanının 1998 yılında 4630 gigabyte’a eriştiği görülmektedir. Veri tabanı sistemlerinin artan kullanımı ve hacimlerindeki bu olağanüstü artış, organizasyonları elde toplanan bu verilerden nasıl faydalanılabileceği problemi ile karşı karşıya bırakmıştır (Yaralıoğlu, 2013).
Bilgisayar sistemlerinin her geçen gün ucuzlaması ve güçlerinin artması, daha büyük miktardaki veriyi işlemeleri ve depolamaları anlamına gelmektedir. Ayrıca, ortaya çıkan bu verilere başka bilgisayarların da hızla ulaşabilmesi demektir. Dijital teknolojinin yaygın olarak kullanılması büyük veri tabanlarının ortaya çıkmasına neden olmaktadır.
Bilgisayar sistemleri her geçen gün hem daha ucuzluyor, hem de güçleri artıyor. İşlemciler gittikçe hızlanıyor, disklerin kapasiteleri artıyor. Artık bilgisayarlar daha büyük miktardaki veriyi saklayabiliyor ve daha kısa sürede işleyebiliyor. Bunun yanında bilgisayar ağlarındaki ilerleme ile bu veriye başka bilgisayarlardan da hızla ulaşabilmek olası. Bilgisayarların ucuzlaması ile sayısal teknoloji daha yaygın olarak kullanılıyor. Veri doğrudan sayısal olarak toplanıyor ve saklanıyor. Bunun sonucu olarak da detaylı ve doğru bilgiye ulaşabiliyoruz. Veri kelimesi Latince’de “gerçek, reel” anlamına gelen “datum” kelimesine denk gelmektedir. “Data” olarak kullanılan kelime ise çoğul “datum” manasına gelmektedir. Her ne kadar kelime anlamı olarak gerçeklik temel alınsa da her veri daima somut gerçeklik göstermez. Kavramsal anlamda veri, kayıt altına alınmış her türlü olay, durum, fikirdir. Bu anlamıyla değerlendirildiğinde çevremizdeki her nesne bir veri olarak algılanabilir. Veri, oldukça esnek bir yapıdadır. Temel olarak varlığı bilinen, işlenmemiş, ham haldeki kayıtlar olarak adlandırılırlar. Bu kayıtlar ilişkilendirilmemiş, düzenlenmemiş yani anlamlandırılmamışlardır. Ancak bu durum her zaman geçerli değildir. İşlenerek farklı bir boyut kazanan bir veri, daha sonra bu haliyle kullanılmak üzere kayıt altına alındığında, farklı bir amaç için veri halini koruyacaktır (Öğüt, 2009). Veriler ölçüm, sayım, deney, gözlem ya da araştırma yolu ile elde edilmektedir. Ölçüm ya da sayım yolu ile toplanan ve sayısal bir değer bildiren veriler nicel veriler, sayısal bir değer
bildirmeyen veriler de nitel veriler olarak adlandırılmaktadır. Veriler, enformasyon parçacıklarıdır. Bu nedenle, enformasyon kavramını açıklamamız gerekir. Derlenen verilerin oluşturmuş olduğu bütüne enformasyon denir. Belli bir konuya yöneliktir. Ayıklanıp düzenlendikten sonra kullanıma sunulacak ve bir problemin çözümüne katkı sağlayacak bilgi haline dönüşmüş olur. Öğüt’ün düşüncesine göre (2009) bilgi, bu süreçteki üçüncü aşamadır. Bireyin algılama yeteneği, yaratıcılığı, deneyimi ve kişisel becerileri ile enformasyonun özümsenerek sonuç çıkarılmasıyla gerçekleşir. Bilgelik ise ulaşılmaya çalışılan nihai noktadır ve bu kavramların zirvesindeyer alır. Bilgilerin kişi tarafından toplanıp bir sentez haline getirilmesiyle ortayaçıkan bir olgudur. Yetenek, tecrübe gibi kişisel nitelikler birer bilgelik elemanıdır.
3.2. Enformasyon Kavramı
Shannon ve Weaver’ın 1949’da ortaya koydukları Enformasyon Kuramı daha sonraki yıllarda iletişimin temeli olmuştur. Shannon’a göre iletişimde 5 temel unsur vardır:
Aslında bu iletişim sistemini, alıcı, verici ve mesaj şeklinde 3 temel bileşen olarak görmek mümkündür. Diğer bileşenler sistemin yapısına göre eklenebilir. Verici, enformasyon kaynağıdır. Gerek kendisi gerekse çevreden aldığı enformasyonu iletiye (sinyal) çevirir ve gönderir. İletiler, kanallarda yol alır. Sinyali bozucu çevre elemanları olabilir. Bunlara gürültü kaynakları denir. İleti kanalında kodlayıcılar vardır. Kodlama ile iletiler alıcının anlayacağı mesaj haline dönüşür. Mesaj ile hedefe ulaşılmış olur. İdeal bir iletişimde minimum enerji ile maksimum mesaj iletilmeli, gürültülerden minimum oranda etkilenmeli ve alıcı, iletiyi maksimum oranda hedefe dönüştürecek yapıda olmalıdır.
Şekil 3.1. Enformasyon teorisine göre iletişim sistemindeki elemanlar
Aksini düşünürsek; veri kaynağındaki sorunlar, vericinin ilettiği sinyallere parazitlerin etkisinin fazla olması, iletiyi dönüştüren veya kodlayan sistemlerde problem olması, alıcının gelen sinyali mesaja dönüştürecek yeteneğinin az olması gibi problemler nedeniyle hedefe istenilen ölçüde ulaşılamayacaktır. Zaman dinamiğinde, artan bilgi akışı; bilimi ve dolayısıyla karar sistemlerini teorik ve deneysel düzeyde etkilemektedir. Bilginin işlenmesinin kolaylaşmasıyla birlikte, karar sistemlerinin etkinliği artmış ve dünya dinamiklerinde önemli değişikliklerin gerçekleşmesine neden olmuştur. Ancak karar sistemlerine yaptığı etkiden dolayı bilgi akışının doğru bir şekilde izlenmesi, kaos ve belirsizliğin yüksek olduğu alanlarda bilgi tahrifinden olabildiğince arındırılması gerekmektedir. Kısacası, iletişim sorunu enformasyon sorununa dönüşür ve kalitesiz hedefler ortaya çıkar. Bu nedenle, sistemin başlangıcı olan kaynakta “veri kalitesi” sağlanmalıdır (Güvenen, 2011).
3.3. Keşfedici Veri Analizi
Veri üzerinde klasik istatistiksel tekniklerin uygulanabilmesi için bazı varsayımların yerine getirilmesi gerekmektedir. Ancak, pratikte bu tür varsayımların gerçekleşmediği birçok durum ile karşılaşmak mümkündür. Bu nedenle, klasik istatistiksel teknikler geçerli sonuçları vermekten uzak kalmaktadırlar. İstatistiksel
analizlerin etkililiğini arttırmak için sağlam (robust) ve keşfedici yöntemlerin geliştirilmesi ve uygulamaları giderek genişlemektedir.
Keşfedici Veri Analizi (Exploratory Data Analysis), belli bir veri kümesinin yapısı hakkında hızlı ve kolay bir şekilde bilgi sahibi olmamıza yardımcı olan teknikler bütünüdür. İstatistiksel tekniklerin ve analizlerin doğru kullanımı için, özet bazı istatistikleri elde etmeden veya hipotez testlerini gerçekleştirmeden önce veriler, oldukça detaylı bir şekilde incelenmelidir.
Kısaca keşfedici veri analizi (KVA), verilerin ne anlattığını anlamak ile ilgilidir. Tukey (1977), KVA’nin “polisiye” bir çalışma olduğunu vurgulamaktadır. Bir suçu incelemeye alan bir polisin hem bazı araç gerece hem de kavrama veya anlayış gücüne gereksinimi vardır. Eğer polisin parmak izi tozu yoksa birçok yüzeydeki parmak izlerini bulmada başarısız olacaktır. Diğer taraftan, suçun nerede işlendiği ve parmak izlerinin nerede olabileceğini anlamazsa, parmak izlerini doğru alanlardan alamayacaktır. Benzer şekilde, veri analizi yapanların da hem bazı araçlara hem de verileri anlama yeteneğinin olması gerekmektedir. Hoaglin et al. (1983), KVA’nde dört temanın göründüğünü ve bunların sıklıkla birlikte kullanıldığını belirtmiştir. Bunlar, direnç (resistance), artıklar (residuals), yeniden açıklama (re-expression) ve açığa çıkarma (revealation) olarak verilmektedir.
Direnç, verilerde bulunan aşırılıklara karşı duyarsızlığı sağlar. Dirençli bir yöntem kullanıldığında, verilerin az bir miktarı oldukça farklı başka sayılarla yer değiştirilse bile, fazla değişmeyecektir. Bunun nedeni, dirençli yöntemlerin veriler içerisindeki sapanlardan (outliers) ziyade verilerin çoğunluğunun bulunduğu yere odaklanmasıdır. Örneğin medyan sapanlara karşı dirençli bir istatistik iken aritmetik ortalama değildir. Direnç ile benzer bir kavram olan sağlamlık (robustness) ise genellikle verilerin geldiği kabul edilen belli bir olasılıksal modelin varsayımlarındaki zayıflamalara karşı duyarsızlığı ifade etmektedir. Medyan bir örneğin merkezi eğilimini ölçmede oldukça dirençli bir istatistik iken, sağlamlık açısından kendisinden daha sağlam tahminleyiciler de vardır. Aritmetik ortalama ise dirençli olmamakla beraber sağlam bir tahminleyici de değildir.
Artıklar, verilerin özetlenmesi veya bir model uyumu yapılmasından sonra, veriler ile modele göre yapılan kestirimler arasındaki farktır:
ı = – ( 3.1)
i
i a bx
yˆ ( 3.2)
şeklinde tanımlanmış doğru ise artıklar da i
i
i y y
r ˆ ( 3.3)
olacaktır. Keşfedici veri analizinin anahtar özelliği, artıkların detaylı bir analizi yapılmadan veri kümesinin analizinin tamamlanmadığını söylemesidir. Artıkların analizi verilerdeki hâkim olan davranış ile anormal davranış arasında açık bir ayırım yapılabilmesi için dirençli analizleri de kullanmalıdır. Verilerin çoğunluğu tutarlı bir örüntü gösteriyorsa, bu örüntü dirençli bir doğru bulunmasını sağlar. Ardından elde edilen dirençli artıklar, şansa bağlı olarak artıp azalanların yanında, örüntüden oldukça fazla uzak olan artıkları da içerecektir. Anormal artıklar, bunları ortaya çıkaran ilgili gözlemlerin hangi koşullarda nasıl toplandığının üzerinde durulması gerektiğine işaret etmektedir. Uygun yöntemler kullanılarak incelenen artıklar, verilerin davranışındaki başka önemli sistematik durumlara (eğrisellik, etkileşimler, varyansın sabit olmaması, başka bir faktörün varlığı vb.) da işaret edebilirler.
Yeniden açıklama, verilerin analizini kolaylaştıracak uygun ölçeğin (logaritmik, karekök vb.) bulunması ile ilgilidir. Keşfedici veri analizi, öncelikle verilerin orijinal ölçeğinde yapılan ölçümlerin tatmin edici olup olmadığının ele alınması gerektiği üzerinde durmaktadır. Eğer bu ölçümler tatmin edici değilse, yeniden açıklama, verilerin yapısına bağlı olarak, simetrinin sağlanmasına, değişkenliğin sabitlenmesine, ilişkilerin doğrusallaştırılmasına veya etkilerin eklenebilirliğinin sağlanmasına yardımcı olabilir.
Açığa çıkarma, araştırmacılar için, verilerin, uyumların, tanı (diagnostic) ölçülerinin ve artıkların (residuals) davranışlarını görme gereksinimini karşılar. Açığa çıkarma yönteminde ağırlıklı olarak grafik teknikleri kullanılmaktadır. Özellikle gövde-yaprak, histogram ve kutu grafikleri en yaygın ifade yöntemleridir. Bu grafiklerin oluşturulması için veri üzerinde çok sayıda işlem uygulanır. Çünkü çoğu zaman veriler işleme hazır halde değildirler. Veriler üzerinde bir takım dönüşümler uygulayarak, verileri temizleyerek, verileri düzleştirerek veya harf değerlerine dönüştürerek verilerin analizleri yapılmaktadır (Hoaglin, 1983).
KVA’nın makine öğrenimi, uzman sistemler ve istatistik ile sıkı bir ilişkisi vardır. Bu ilişkilerden birisi de veriler ile ilgili modelleme yapmaya yarayan Biçimsel Kavram Analizi (BKA) dir. Rudolf Wille (1982) tarafından kafes teorisinin genişletilmesiyle ortay çıkmıştır. Matematiksel anlamda biçimsel mantık esasına
dayanır. BKA kavramı birçok disiplinde genel bir mekanizma olarak karşımıza çıkmaktadır. Analiz iki bölümden oluşur: kapsam (extent) ve içerik (intent). İçerik kavramın özelliklerini, kapsam ise kavramda yer alan nesneleri verir. Nesnelerin taşıdıkları özelliklere göre gruplandırılmasına kavramlaştırma denir. BKA, kavramları verilen bir bağlam içerisinde tanımlar ve aralarındaki ilişkiyi bağlama karşılık gelen kafes yapısını kullanarak inceler. Biçimsel olarak bağlam, nesneler (G), özellikler (M) ve ilişkilerden (I) oluşan üçlü bir cebirsel yapıyla ifade edilir. g nesnesi ve m niteliği için (g,m) ∈ I gösterimi “g nesnesi m niteliği taşır” anlamına gelmektedir (Sever, 2003). Bu tanımlamalar ışığında Biçimsel Kavram Analizi, veri madenciliğindeki birliktelik kuralının temelini oluşturmuş ve Agrawal et al. (1993) tarafından matematiksel temele oturtularak algoritma geliştirilmiştir.
KVA ile ilgili yöntemler ve bilgiler detaylı incelendiğinde veri madenciliğinin temeli olduğu görülecektir. Veri madenciliği de veri kümesi üzerindeki veri keşfi ile ilgilidir. Ancak, veri madenciliği daha ileri teknik ve algoritmaları kullanmaktadır. Keşfedici veri analizinin yalnızca hipotez testleri öncesi veri hakkında detaylı bilgi sahibi olmak ve sonuçları görselleştirmek için kullanıldığı görmekteyiz. Bu nedenle veri madenciliği KVA’nın bir sonraki ve ileri aşaması olmaktadır.
3.4. Veri Tabanları
Çevremizde olup biten tüm olaylar sonucunda “veri” oluşmaktadır. Veriler, göndericiler tarafından iletilmek üzere kullanılır. Ancak veriler, kullanım hızından daha süratli artmaktadır. Artan verilerin depolanması gerekmektedir. Düzenli verilerin bir araya gelerek oluşturduğu bilgiler topluluğuna “veri tabanı” adı verilir. Veri tabanı terimi, ilk yıllarda “kütük (file)” kavramının bir devamı olarak kullanılmıştır. Bilgisayar terminolojisinde ise veri tabanı, sistematik erişim imkanı olan, yönetilebilir, güncellenebilir, taşınabilir, birbirleri arasında tanımlı ilişkiler bulunabilen bilgiler kümesidir. Bir başka tanımı da, bir bilgisayarda sistematik şekilde saklanmış, programlarca istenebilecek veri yığınıdır. Her veri kümesi veri tabanı olarak kabul edilmez. Veri tabanı aşağıdaki özellikleri taşımalıdır:
Veri tabanı belli bir kuruluşun birçok uygulamasında kullanılan, birbiriyle ilişkili işletimsel verilerden oluşur.
Veri tabanında saklanan veriler kuruluşun birden çok uygulamasında kullanılan sürekli verilerdir.
Giriş/çıkış verileri ve geçici veriler veri tabanında yer almaz.
Veri tabanındaki veriler gereksiz yinelemelerden arınmış olarak, düzenli bir biçimde bilgisayar belleklerinde saklanır ve bu veriler ilgili kuruluşun birden çok uygulaması tarafından paylaşılan ortak verilerdir.
Veri tabanında saklanan veriler değişmeyen statik veriler değildir. Ekleme, silme ve güncelleme işlemleriyle veri tabanındaki veriler değiştirilebilir. Ayrıca sorgulama ve raporlama işlemleri de yapılabilmektedir.
Veri tabanındaki veriler üzerinde merkezi bir denetim vardır.
Kullanıcılar işletim sistemi komutları ya da genel amaçlı programlama dilleri ile yazılmış uygulama programlarını kullanarak, doğrudan veri tabanındaki verilere erişemezler ve bu verileri değiştiremezler.
Bir veri tabanını oluşturmak, saklamak, çoğaltmak, güncellemek ve yönetmek için kullanılan programlara Veri Tabanı Yönetme Sistemi (DBMS – Database Management Systems) adı verilir. DBMS özelliklerinin ve yapısının nasıl olmasını gerektiğini inceleyen alan Bilgi Bilimi (Information Science)'dir. Veri Tabanında asıl önemli kavram, kayıt yığını ya da bilgi parçalarının tanımlanmasıdır. DBMS aracılığıyla, veri tabanının bilgisayar belleklerindeki fiziksel yapısı kullanıcılardan gizlenir. Kullanıcılara daha yalın mantıksal yapılar sunulur.
Veri tabanı yazılımı ise verileri sistematik bir biçimde depolayan yazılımlara verilen isimdir. Birçok yazılım bilgi depolayabilir ama aradaki fark, veri tabanın bu bilgiyi verimli ve hızlı bir şekilde yönetip değiştirebilmesidir. Veri tabanı, bilgi sisteminin kalbidir ve etkili kullanmakla değer kazanır. Bilgiye gerekli olduğu zaman ulaşabilmek esastır. Bağıntısal Veri Tabanı Yönetim Sistemleri (Relational Database Management Systems - RDBMS) büyük miktarlardaki verilerin güvenli bir şekilde tutulabildiği, bilgilere hızlı erişim imkânlarının sağlandığı, bilgilerin bütünlük içerisinde tutulabildiği ve birden fazla kullanıcıya aynı anda bilgiye erişim imkanının sağlandığı programlardır. Oracle veri tabanı da bir bağıntısal veri tabanı yönetim sistemidir (Usgurlu, 2010).
İlişkisel Veri Tabanı Sistemleri
• PostgreSQL • MySQL • Oracle
• Sybase • BerkeleyDB • Firebird
Veri Tabanı Dilleri
• SQL • PL/SQL • Tcl
Veri tabanının sağladığı faydalar şu şekilde özetlenebilir: Herhangi bir evrakın saklanmasına gerek kalmaz
Bilgiler daha hızlı güncellendiğinden zamandan tasarruf edilir. Yalnızca istediğimiz bilgiye istediğimiz zaman ulaşma imkanı vardır. Verilerin kontrolü merkezi idare tarafından sağlanır.
Veri tekrarları azalır.
Tutarsız (hatalı) bilgi girişi engellenir. Verilerin paylaşımı sağlanır.
Veri deseninde bütünlük sağlanır.
Genel veya özel raporlar almak mümkündür (Çıngı, 2007).
3.5. Veri Ambarları
Veri ambarı kavramının babası olarak nitelenen William H. Inmon’un 1992 yılında yapmış olduğu “Developing the Data Warehouse” çalışmasına göre veri ambarı, konu odaklı, kara verme sürecini etkinleştiren, bütünleşik ve kalıcı veri topluluğudur. Bir veri ambarı, analizler ve sorgular için kullanılabilir, bütünleşmiş bilgi deposudur. Veri ve bilgiler, üretildiklerinde heterojen kaynaklardan elde edilirler. Veri Ambarları, sağlık sektöründen coğrafi bilişim sistemlerine, işletmelerin pazarlama bölümünden üretime, geleceğe dönük tahminler yapmada, sonuçlar çıkarmada ve işletmelerin yönetim stratejilerini belirlemede kullanılmakta olan bir sistemdir. Pahalı bir yatırım maliyeti olsa bile sonuç olarak getirisi (yararı) bu maliyeti kat kat aşmaktadır.
Belirli bir döneme ait, yapılacak çalışmaya göre konu odaklı olarak düzenlenmiş, birleştirilmiş ve sabitlenmiş işletmelere ait veri tabanlarına “veri ambarı” denir. Veri ambarları üzerinde çeşitli stratejiler hakkında karar vermek için yapılan veri analizi ve sorgulama işlemlerine OLAP (On-Line Analytical Processing) denir. Günlük sorgulamalardan farklı olarak olasılık barındır. Haftalık alış-satış oranı OLAP değilken;
süt ürünleri satışlarının 10 bin’i aşma olasılığı OLAP olur. OLAP ile veri madenciliği birbirinden farklıdır. OLAP analizcisi hipoteze dayalı örüntü ve ilişkileri üretir ve onları veri kümesi üzerinde ispat etmeye çalışır. Veri madenciliği analizcisi ise hipoteze dayalı hareket etmektense bizzat veri kümesi üzerinde örüntüler ve ilişkiler bulmaya çalışır. Buna karşın OLAP ve VM birbirlerini tamamlarlar. Araştırmacı önce olasılıksal düşünerek ilişkileri belirlemeye çalışır ve sonrasında veri kümesi üzerinde işlemler uygulayarak bu ilişkileri ortaya çıkarır (Küçüksille, 2010).
3.5.1. Veri Ambarı Oluşturulması
Veri ambarı aşaması veri madenciliği sürecinde önemli bir aşamadır. Bu süreç, toplam maliyet ve zamanın önemli bir kısmını almaktadır. Madenciliği yapılacak veri tek bir yapı içerisinde bulunmayabilir. Bu nedenle bilginin tek çatı altında toplanması gerekir. Fakat veriyi tek çatı altında toplamak veri ambarı oluşturma anlamına gelmez. Veri kümeleri üzerinde ayrıca başka işlemlerin de yapılması gerekmektedir.
İş organizasyonlarında veri ambarları iki amaçla oluşturulmaktadır:
1. Hareketsel ve organizasyonel görevler arasındaki depo ve analitik stratejik verilerin birikimini sağlar. Bu veriler daha sonra yeniden kullanılmak üzere arşivlenir. Veri ambarları verilerin sorgulanabildiği ve analiz yapılabilindiği bir depodur.
2. Veri Ambarlarının pazarda yeni fırsatlar bulmaya, rekabete katkı, yoğun proje çevirimi, iş, envanter, ürün maliyetlerinin azalmasının yanında farklı işlere ait verilerin ilişkilendirilmesi, karar destek ve alınan bilgiye hızlı cevap verebilme gibi birçok katkısı vardır.
Veri ambarı oluşturma aşamaları:
i. Toplama: farklı kaynaklarda olan verilerin tek kaynakta birleştirilmesi
işlemidir. Örneğin, hastaların tıbbi verileri yanı sıra bazı demografik özelliklerinin de bilinmesi gerekebilir. Bu tür verilerin farklı kaynaklardan alınarak tıbbi veriler ile birleştirilmesi yani toplanması gerekebilir.
ii. Uyumlandırma: farklı kaynaklardan alınan veriler arasında uyumsuzluklar
ortaya çıkabilir. Veri madenciliği sürecinin başarısında veri uyumu önemli rol oynamaktadır. Örneğin, cinsiyet verileri bir kaynakta 1/0 şeklinde tutulurken diğer bir kaynakta E/K, veya Erkek/Bayan şeklinde tutuluyor olabilir. Dolayısıyla veriler toplanırken bu uyumsuzluğun giderilmesi gerekmektedir.
iii. Birleştirme ve Temizleme: Uyumlandırma işlemi sırasında verilerin dikkatli bir
biçimde birleştirilmesi ve fazlalıkların temizlenmesi gerekir.
iv. Seçme: Kurulacak model için uygun verinin seçilmesi işlemidir. Özellikle
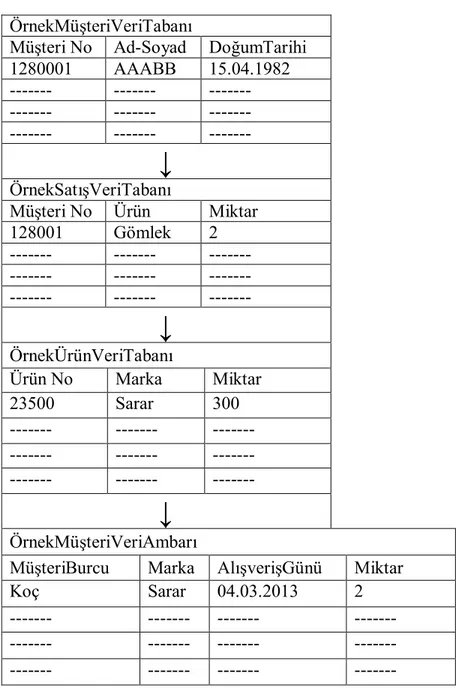
sınıflandırma uygulamalarında özniteliklere uygun verinin belirlenmesi önem göstermektedir. Çünkü veri tabanlarındaki işlem hızları artmasına rağmen uygun seçilmemiş veriler ile model denemesi yapılması zaman ve maliyet açısından kayıplara neden olmaktadır (Kaya, 2010). Veri Ambarı oluşturmasına bir örnek verelim.
ÖrnekMüşteriVeriTabanı
Müşteri No Ad-Soyad DoğumTarihi
1280001 AAABB 15.04.1982 --- --- --- --- --- --- --- --- ---
↓
ÖrnekSatışVeriTabanı Müşteri No Ürün Miktar 128001 Gömlek 2 --- --- --- --- --- --- --- --- ---↓
ÖrnekÜrünVeriTabanı Ürün No Marka Miktar 23500 Sarar 300 --- --- --- --- --- --- --- --- ---↓
ÖrnekMüşteriVeriAmbarıMüşteriBurcu Marka AlışverişGünü Miktar
Koç Sarar 04.03.2013 2
--- --- --- ---
--- --- --- ---
--- --- --- ---
Çizelge 3.1. Müşteri, satış ve Ürün veri tabanlarının kullanılarak Müşteri Veri Ambarı
3.5.2. Veri Ambarının Özellikleri
Bir veri ambarının taşıması gereken özellikler şunlardır:
Konu Odaklılık: Bir veri ambarı, karar vericiler için de kullanıcılar için de yalnızca gerekli olan verilere odaklı olup, o konu hakkında basit ve kısa görüş elde etmeyi sağlamalıdır.
Bütünleşik olma: Bir veri ambarı, genellikle ilişkisel veri tabanları, standart dosyalar ve online işlem kayıtları gibi çoklu heterojen yapıdaki kaynakların bütünleştirilmesiyle oluşturulmaktadır.
Belirli zaman dilimine ait olma: Tarih açısından belli bir trend yakalamak amacıyla son 5-10 yılın verileri saklanmaktadır. Her veri, dolaylı veya doğrudan bir zaman değişkeni ile ilişkilendirilir.
Kalıcılık (Uçucu olmayan): Ambardaki veri, yönetimin ihtiyaçlarına cevap vermek üzere tasarlandığından günlük işlemlere tabi tutulmamakta; yani silme veya güncelleme işlemi yapılmamaktadır. Veriler yalnızca okunabilir (read-only) yapıda tutulmaktadır. Ambarlarda “veri yükleme (loading)” ve “veriye erişim (access)” olmak üzere yalnızca iki tür işlem uygulanır.
Veri tabanları üzerinde dönüşüm yapılarak konu odaklı olarak veri ambarları oluşturulur. Veri ambarının belli bir konuya göre düzenlenmiş, sadece belli bir bölümünü ilgilendiren parçasına veri pazarı (data mart) denir (Silahtaroğlu, 2008).
Veri ambarlarında özelliklerine göre şu tür veriler bulunur:
Metaveri: Veriye ilişkin temel veri olarak tanımlayabileceğimiz metaveri, veri ambarının en temel bileşenlerinden birisidir. Konu ile ilgilenen karar destek analizcilerine yardım etmek üzere tasarlanmış bir dizindir ve ilgili ambarın içeriğinde neler olduğunu belirtir. Verinin konumu, hangi algoritmaya göre oluşturulduğu, içeriği, kapsamı, çerçevesi vb. gibi bilgileri içeren bir kılavuz niteliğindedir.
Çizelge 3.2Hanehalkı Bilişim Teknolojileri Anketine ait verilerin bulunduğu
ambardaki metaveri örneği(Kaynak: TÜİK internet sitesi-
Hanehalkı Bilişim Teknolojileri Kullanım İstatistikleri
Analitik Çerçeve, Kapsam, Tanımlar ve Sınıflamalar Amaç:
Hanehalkı Bilişim Teknolojileri Kullanım Araştırması, hanelerde ve bireylerde sahip olunan bilgi ve iletişim teknolojileri ile bunların kullanımları hakkında bilgi derlemek amacıyla 2004 yılından itibaren uygulanmakta olup, söz konusu teknolojilerin kullanımı hakkında bilgi veren temel veri kaynağıdır.
Bu araştırma ile aşağıdaki alanlarda veri derlenmektedir: - Hanelerde bulunan bilgi ve iletişim teknolojileri - Bilgisayar (Bireylerin bilgisayar kullanımı, sıklığı v.b.)
- İnternet (Hanelerde İnternet erişimi sahipliği, bağlantı tipleri, bağlı araçlar, bireylerin İnternet kullanım sıklığı, kullanım amaçları v.b)
- e-Ticaret
- e-Devlet uygulamaları - Bilişim güvenliği
Tanımlar:
Hanehalkı: Aralarında akrabalık bağı bulunsun ya da bulunmasın aynı konutta veya konutlarda,
aynı konutun bir bölümünde yaşayan, kazanç ve masraflarını ayırmayan, hanehalkı hizmet ve yönetimine katılan bir veya birden fazla kişiden oluşan topluluk.
Kent: 20 001 ve daha fazla nüfuslu yerleşim yerleridir. Kır: 20 000 ve daha az nüfuslu yerleşim yerleridir.
bir işte çalışmış olanlar, Uluslararası İşteki Durum Sınıflamasına (ICSE,1993) uygun olarak sınıflandırılmakta ve yayımlanmaktadır.
Şekil 3.2. Hanehalkı Bilişim Teknolojileri Anketine ait verilerin bulunduğu ambardaki
Şekil 3.3. İşsizlik Oranları Çalışmasına ait verilerin bulunduğu ambardaki metaveri
örneği (Anonymous14) 3. Statistical presentation
3.1. Data description
The Unemployment - LFS adjusted series (including also Harmonised long-term unemployment) is a collection of monthly, quarterly and annual series based on the quarterly results of the EU Labour Force Survey (EU-LFS), which are, where necessary, adjusted and enriched in various ways, in accordance with the specificities of an indicator.
Harmonised unemployment is published in the section 'LFS main indicators', which is a collection of the main statistics on the labour market.
Other information on 'LFS main indicators' can be found in the respective ESMS page. General information on the EU-LFS can be found in the ESMS page for 'Employment and unemployment (LFS)' (see link in section 21.2).
Detailed information regarding the survey methods, organization and comparability issues is available on the EU-LFS webpage.
3.2. Classification system
The 'LFS main indicators' are produced in accordance with the relevant international classification systems. The main classifications used are NACE Rev.1 (NACE Rev.1.1 from 2005) and NACE Rev. 2 (from 2008) for economic activity, ISCO 88 (COM) for occupation and ISCED 1997 for the level of education. For more details on classifications, levels of aggregation and transition rules, please view the EU-LFS webpage: Statistical classifications in EU-LFS.
3.3. Sector coverage Not applicable
3.4. Statistical concepts and definitions
Definitions of employment and unemployment, as well as other survey characteristics, follow the definitions and recommendations of the International LabourOrganisation. The definition of unemployment is clarified further in Commission Regulation (EC) No 1897/2000. This domain comprises collections of monthly averages of unemployed persons and unemployment rates. The relevant definitions are as follows:
Unemployed persons are all persons 15 to 74 years of age (16 to 74 years in ES, SE
(1995-2000), UK, IS and NO) who were not employed during the reference week, had actively sought work during the past four weeks and were ready to begin working immediately or within two weeks. Figures show the number of persons unemployed in thousands.
The duration of unemployment is defined as the duration of a search for a job or as the length of the period since the last job was held (if this period is shorter than the duration of search for a job).
Unemployment rate is the number of people unemployed as a percentage of the labour
force. The labour force is the total number of people employed and unemployed. 3.5. Statistical unit
Persons
3.6. Statistical population
The EU-LFS results cover the total population usually residing in Member States, except for persons living in collective or institutional households. While demographic data are gathered for all age groups, questions relating to labour market status are restricted to persons in the age group of 15 years or older. For exceptions, please consult EU-LFS webpage: Comparability of results.
Ayrıntı veri: veri ambarında en son olayları içeren ve henüz işlenmediği için diğerlerine oranla daha büyük hacimli ve disk üzerinde saklandığından erişimleri ve yönetimleri pahalı olan verilerdir.
Eski ayrıntı veri: Ayrıntı verinin dışında kalan ve daha eski tarihe ait olan verilerdir. Ayrıntılı veriye göre daha düşük bir ayrıntı düzeyine indirgenerek saklanmaktadır.
Düşük düzeyde özetlenmiş veri: Ayrıntı veriden süzülerek elde edilen düşük seviyede özetlenmiş verilerdir. Veri ambarının tasarımı esnasında hangi verinin özetleneceği ve özetleme işleminin ne düzeyde olacağı belirlenmelidir.
Yüksek düzeyde özetlenmiş veri: Ayrıntı veri daha yüksek düzeyde özetlenerek, kolayca erişilebilir hale getirilebilir. Bu tür veriler de veri ambarının bir bileşeni olarak yer alabilir.
Kısacası Veri Ambarları, stratejik kararları verme konusunda bir organizasyonun ihtiyacı olan bilgiyi depolayan ve yapısal veya amaca özel sorgulamaların yapılabildiği, birçok veri türünü bütünleştiren bir mimari olarak görülmektedir (Atılgan, 2011).
3.6. Veri Madenciliği Süreci
Veri madenciliği, belli belirsiz tanımlanmış bir alandır. Yapılan tanımlar uygulama zeminine veya uygulayıcılara göre değişmektedir.
Veri madenciliği veri içindeki, geçerli, yeni, potansiyel olarak faydalı ve nihai olarak anlaşılır örüntüleri anlamanın basit olmayan bir yoludur (Fayyad).
Veri madenciliği büyük veri tabanlarındaki daha önceden bilinmeyen, kavranabilir ve işlemeye uygun bilginin ortaya çıkarılması ve bu bilginin önemli iş kararları verilmesinde kullanılması sürecidir (Zekulin).
Veri madenciliği veri içindeki daha önceden bilinmeyen ilişki ve örüntüleri ayırt etmede bilgi keşif sürecinde kullanılan yöntemlerin kümesidir (Ferruza).
Veri madenciliği veri içindeki faydalı örüntüleri keşi sürecidir (John).
Veri madenciliği büyük veri tabanlarında bilinmeyen ve beklenmeyen bilgi örüntülerini araştırdığımız kara deste sürecidir (Parsaye).
Veri madenciliği ile ilgili yapılan yüzlerce tanımda iki orak kavram ortaya çıkmaktadır. İlki “çok fazla” miktarda verinin olması, ikincisi ise bu verilerden “anlamlı” bilgiler elde edilmesidir. Veri madenciliği uygulamaları günümüzde daha çok
ticari eksenli gelişmiştir ve kamu alanında yapılan uygulama sayısı başlarda az olmuştur. Bu nedenle istatistik kurumlarının ve ofislerinin her geçen gün artan veri yığınlarıyla baş edebilmeleri için veri madenciliği uygulamalarına gerekmiştir. Bunun sonucunda verilerin temiz ve tutarlı hale getirilmesinde ve veri giriş performanslarının incelenmesinde kullanılmaya başlayan veri madenciliği teknikleri sayesinde kamu alanında da veri kalitesi artmaya başlamıştır (Babadağ, 2006).
Tüm bu tanımlamalara rağmen Veri Madenciliği (VM) ticari bir girişimin konusu olarak günümüze kadar gelmiş ve madencilikten ziyade madencilere yazılım ve donanım satmanın bir aracı olmuştur. Firmalar, büyük veritabanlarını yönetme ihtiyacı içerisindedirler. Rekabet amacıyla her firma kendi sahip olduğu verilerden örüntü çıkarma peşine düşmektedir. Bu durum, daha büyük disk alanları, daha hızlı işlem yapan bilgisayarlar ve daha çabuk analiz yapacak yazılımların ihtiyacını doğurmaktadır. Hem donanım hem de yazılım tacirleri abartılı reklamlar ile firmaların rekabetçi damarını kaşırlar. Dolayısıyla, VM için çok büyük bir yazılım, donanım ve eğitim pazarı oluşmuştur. Pazarın büyüklüğü milyar dolarlar ile ifade edilmektedir. Başlarda birçok firma veritabanlarını idare edecek kapsayıcı paketler üretirken günümüzde birçok firma tek bir amaç için uzmanlaşmış paketleri pazarlama çabası içerisine girmişleridir. Mevcut VM ürünleri genel olarak aşağıdaki özelliklere sahiptirler:
Çekici bir grafik ara yüzü Sorgulama dili
Veri çözümleme prosedürleri dili, Esnek uygun girdi
Tıklama ikonları ve menüler Girdi için iletişim kutuları
Çözümlemeleri betimleyen diyagramlar Çıktıların çok yönlü ve hızlı grafikleri
Bunun yanı sıra istatistiksel çözümleme için şu yöntemleri de barındırırlar: Karar ağaçları
Kural çıkarma
Kümeleme yöntemleri İlişkilendirme kuralları Örüntü tanıma
Yapay sinir ağları Bayesian ağları
Genetik algoritma
Kendini örgütleyen haritalar Bulanık sistemler
Bununla birlikte VM paketlerinin neredeyse tamamında Hipotez testleri Deneysel tasarım (M)ANOVA GLM Regresyon Diskriminant Analizi Kanonik Korelasyon Faktör Analizi
gibi istatistiki analiz yöntemleri bulunmaz. Bu tür temel analizler istatistik paketlerinin içeriğidir ve VM paketleri istatistik alanı dışında geliştirildiğinden temel yöntemler büyük ölçüde göz ardı edilmiştir. Bu durum, VM’nin görünürde istatistik ile ilgisinin yüksek olmadığı izlenimini uyandırmaktadır. Çünkü VM kavramını büyük çoğunlukla bilgisayarcılar geliştirmektedir. Oysa olayın geri planında teorik istatistik ve matematik yoğun olarak kullanılmaktadır. Bu nedenle, “VM entelektüel bir disiplin midir?” veya “VM istatistiğin bir parçası olmalı mıdır?” sorularının yanıtı net olmadığından henüz kesin olarak cevaplanamamaktadır. Ancak VM’nin ticari düşünceden uzaklaşması ve astronomik, meteorolojik, uzaktan algılama veya endüstriyel proses gibi büyük veri tabanlarının bilim ile daha ilgili olmaları nedeniyle gelecekte verilebilecek cevap şüphesiz: “evet!” olacaktır.
Ticari de düşünsek bilimsel de düşünsek teknolojiyle beraber verilerin hızla arttığı gerçeğini de göz önünden uzaklaştırmamak gerekmektedir. SLAC firması Muhasebe Müdürü Chuck Dickens: “Hesap gücümüz her on katına çıktığında, neyi nasıl hesaplamak istediğimizi yeniden düşünmeliyiz.” demektedir. Bunun anlamı şudur: Veri miktarı hızla artmaktadır ve her on katlık artışta, nasıl bir analiz yapılması gerektiğinin yeniden düşünülmesi ve sürekli yeni yöntemlerin veya algoritmaların geliştirilmesi gerekmektedir. Bu anlamda, VM gelişiminin yalnızca bilgisayarcılar tarafından değil de istatistikçilerin de katkılarıyla yapılması gerekir. İstatistikçilerin klasik analiz yöntemleri yanı sıra programlama ve VM sürecine dahil olmaları gerekmektedir. VM’de bilgisayar amaç değil bir araçtır.
Sonuçta, VM süreci istatistiksel analiz süreçlerinden ayrı düşünülemez. Her ikisinde de bir akış şeması vardır ve VM sürecinin % 70’ini verilerin ön işleme süreci oluşturur. VM modelleri kara vericiler için en önemli yardımcı haline geldiğinden aykırı, yanlış ve tutarsız veriler ile karar modelleri oluşturmak çok riskli olacaktır (Friedman, 2012).
Veri madenciliği büyük veri kümeleri üzerinde oluşan bir süreç olduğundan çok sayıda alanda kullanılmaktadır:
1) Pazarlama
a) Müşterilerin satın alma örüntüleri b) Demografik özellikler
c) Posta kampanyalarına cevap verme d) Mevcut müşterilerin elde tutulması e) Market sepet analizi
f) Risk yönetimi ve dolandırıcılık saptama
2) İletişim: Telekomünikasyon hatlarındaki parazitlenmeyi tespit etme, gürültü giderme
3) Biyoloji: DNA ve gen teknolojisi
4) Sağlık: Kesin teşhis yöntemleri, cerrahi risk, hastane yönetim sistemleri, sağlıkta maliyet düşürme, radyolojik görüntüleme
5) Bankacılık: Müşteriler arası bilgiler, sahte kart ve kredi olaylarını saptama (Silahtaroğlu, 2008).
3.6.1. Verilerin Hazırlanması
Tüm veri madenciliği aktiviteleri, verinin özellikleri ve sunulması üzerine kuruludur. Eğer veri işleme hazır semantik model halinde değilse kullanıcı verinin uygun hale getirilmesi için bir takım tedbirler alır. Eksik veriler sorunu; tutarsız, gürültülü ve gereksiz veriler ile ilgili işlemler sürecin bir parçasıdır. Veri madenciliği yapanlar kayıtları kullanılabilir hale getirmek zorundadırlar, genellikle ikili veya sıralı değişkenler şeklinde hazırlanır. Verilerin standart forma dönüştürülemediği durumlar da olabilmektedir. Aynı şekilde VM, sıralı nümerik değerleri analiz etmeye tasarlanmıştır, kategorize verileri kolaylıkla analiz edemez (Benoit, 2002).
Veri madenciliğinde kullanılan modeller, tahmin edici (predictive) ve tanımlayıcı (descriptive) şeklinde iki ana gruba ayrılır. Tahmin edici modellerde, bilinen
sonuçlara sahip modellerden hareket edilerek sonuçları bilinmeyen veri kümeleri için sonuç değerlerinin tahmin edilmesi amaçlanır. Örneğin, bir sigorta şirketi eski müşterilerine ait elinde olan verileri kullanarak bilgi sahibi olmadığı yeni müşterilerinin risk durumlarını tahmin edebilir. Burada bağımsız değişkenler müşterilerin bilgileri, bağımlı değişken ise sigortalanma riskidir. Veriler kullanılarak model oluşturulur ve yeni müşterilerin risk analizi yapılabilir. Tanımlayıcı modelde ise eldeki mevcut veriler arasındaki ilişkiler ortaya çıkarılmaya çalışılır. Ortaya konan örüntüler yardımıyla ilgili gruba giren kayıtlar ile ilgili bilgi sahibi olunur. Bir bankanın, konut kredisi kullanan ailelerin özel araca sahip olma durumu ile araç kredisi kullanan müşterilerin kendi konutuna sahip olma durumları arasındaki örüntüyü ortay çıkarması tanımlayıcı modele örnek olabilir (Özekes, 2003).
Veri madenciliği uygulamasına başlamadan önce verilerin dikkatlice gözden geçirilmesi gerekmektedir. Ham veri tabanlarındaki kayıtların büyük çoğunluğu işlenmemiş, eksik ve gürültülü veri içerirler. Dolayısıyla bu verilerin elden alınması gerekmektedir. Veritabanında eksik kayıtlar olabildiği gibi kayıtların bir kısmı aşırı uç ya da yanlış girilmiş olabilirler. Bunlara gürültü terimi (noisy data) denir. Bazı değişkenlerin birleştirilmeleri gerekebilir. Veri hazırlama aşamaları şöyledir:
1) Verilerin temizlenmesi:Eğer veri tabanında eksik verilerin olduğu kayıtlar varsa; a) Eksik (kayıp) verilerin bulunduğu kaydı çıkarmak: Analizi yapacak kişi ya da
ekip tarafından belirlenecek olan eksik verilerin bulunduğu kayıtlar veri kümesinden çıkarılır. Ancak çıkarılacak olan kayıt sayısına dikkat etmek gerekir. Çok sayıda verinin çıkarılması yapılacak analizin sonuçlarını etkileyebilir.
b) Eksik verileri elle teker teker doldurmak: eksik verilerin bulunduğu değişkenin dağılımı tespit edilerek bu dağılımdan üretilecek olan rastgele (random) sayılar ile eksik veriler doldurulur.
c) Tüm eksik verilere aynı bilgiyi girmek: analizi yapacak işi veya ekip tarafından belirlenecek bir sabit sayı ile tüm eksik veriler doldurulur.
d) Eksik verilere tüm verilerin ortalama değerini vermek: var olan kayıtların ortalaması hesaplanarak eksik olan verilere ortalama değeri verilir. Böylece genel ortalama etkilenmemiş olur.
e) Regresyon yöntemi ile eksik verileri tahmin etmek: eksik verilere ait olan değişken kayıtları regresyon uygulamaya uygun ise elde olan veriler ile
varsayımlar sağlanarak regresyon uygulaması yapılır. Elde edilen denklemden faydalanılarak eksik değerler ait gözlemler elde edilerek doldurulur.
2) Verilerin yeniden yapılandırılması:
a) Yanlış gruplandırılmış veriler: Veri setindeki değişkenlere ait kayıtlarda farklı gruplarda olmaları gerekirken aynı grupta işaretlenmiş veriler varsa bunların uygun grup kategorilerine alınması gerekir.
b) Aykırı değerlerin tespit edilmesi: Aykırı değerler veri setindeki değişkene ait kayıtları sınırları dışında kalan veya verinin trendinin tersine giden değerlerdir. Mutlaka tespit edilip düzeltilmeleri gerekir. Çünkü analiz sonuçlarında hataya sebep olurlar. Bu amaçla, daha çok istatistiksel yönetmelere başvurulur. Histogram, saçılım veya kutu grafikleri aykırı değerleri tespit etmenin en öncelikli yöntemlerinden bir kaçıdır.
c) Veri dönüştürme: Bazı durumlarda, değişkenlerin içinde bulunması gereken aralıktan farklı değerler ile karşılaşılır. Eğer bir değişkenin belli bir aralıkta olması ile ilgileniyorsak ve karşımıza çıkan veri bu aralığın dışında ise bu durumda elimizdeki verilerin kullanılacak algoritmaya uygun hale getirilmesi ve verilerin yeniden yapılandırılması gerekir. Bunun için bazı yöntemler vardır. En yaygın kullanılan iki tanesi:
Min-Maks normalizasyon: Her bir değerin minimum ile farkının Min-Maks aralığından ne kadar büyük olduğu esasına göre hesaplanır. = { , , … , } şeklinde bir değerler dizisi ve , . normalleştirilen değer olmak üzere
(0,1) aralığındaki normal değerler için Min-Maks yöntemi:
= ( )
( ) ( ) ( 3.4)
Herhangi bir (a,b) aralığı için Min-Maks yöntemi:
= _ ve = _ olmak üzere
= ( )
( ) ( ). ( _ − _ ) + _ ( 3.5)
Sıfır ortalamalı standart normalizasyon: Her bir değerin ortalamaları ile farkının standart sapması değerine bölünmesiyle hesaplanır. , dizisinin ortalama değeri ve , dizinin standart sapması olmak üzere
= ( 3.6)
d) Veri boyutunu indirgeme: Genellikle iki yöntem kullanılır: Dalga Dönüşümü (Wavelet Transform) ve Temel bileşenler analizi (Karhunen – Loéve) (Larose, 2005).
3.6.2. Veri Madenciliği Yönteminin Uygulanması
Veri madenciliğinin hızla gelişmesinin nedenlerinden birisi de kuruluşların (kamu veya özel) büyük miktarda veriyi otomatik olarak toplamasıdır. Bu nedenle toplanan verilerin hızla artan veri yığınının üzerinden zaman geçmeden veya rekabete dayalı olarak daha önce bilgiyi ortaya koyma amaçlı analiz edilmesi gerekmektedir. Bazı işletmelerde uyuşukluk, tembellik ve veri madenciliğine karşı gelişigüzel bir yaklaşım sergilenmesi nedeniyle endüstriler arası standart kavramının geliştirilmesi gerekli olmuştur. Tarafsız sanayi, tarafsız malzeme ve tarafsız uygulama sloganıyla ortaya çıkan Cross Industry Standard Process for Data Mining (CRISP-DM) kavramı ilk olarak 1996 yılında Daimler-Chrysler, SPSS ve NCR firmalarının analizcileri tarafından geliştirilmiştir. CRISP yaklaşımı, veri madenciliği ile model oluşturmada tescilli olmayan ve özgür standart süreçler sağlar. CRISP-DM yaklaşımına göre bir veri madenciliği projesi altı aşamadan oluşur. Aşama sıralaması adaptifdir. Yani her bir aşama bir önceki aşamanın gerçekleşmesine bağlıdır. CRISP süreci bir döngü ile sembolize edilir (Cespivova, 2004)
CRISP-DM döngüsünün aşamaları altı tanedir.
1 Amacın belirlenmesi (Business Understanding): Hangi konuda çalışma
yapılacaksa bu çalışmaya ait genel amaç ve alt hedefler belirlenir. Problemin doğru tanımlanması ve gereken çözüm süreci için önemli bir aşama olup taslak plan oluşturulur.
2 Veriyi Anlama (Data Understanding): Hazırlanan hedeflere veya plana göre
mevcut verilerin durumu veya derlenmesi gereken veriler ile ilgili temel özellikler ortaya konulur. Verilerin türleri, veri kalitesi, alt kümelere ait özellikler, verilerdeki hata durumu ve eksik veri durumu tespit edilir.
3 Veriyi Hazırlama (Data Preperation): verilerin analiz edilemeden önceki tüm
süreçlerini kapsayan bir aşamadır ve çok önemlidir. Uygun hazırlanmayan bir veri yanlış sonuçların çıkmasına neden olabilir. Verilerin ön analizleri yapılarak
Şekil 3.4. CRISP-DM adaptif süreç döngüsü
İşletmeye / Araştırmaya ait amacın belirlenmesi aşaması Verinin anlaşılması aşaması Verinin hazırlanması aşaması Modelleme aşaması Uygulama aşaması Değerlendirme aşaması VERİ