ÖLÇEKLERİN FAKTÖR YAPISINI BELİRLEMEDE KULLANILAN AÇIMLAYICI FAKTÖR ANALİZİ VE KÜMELEME ANALİZİ İLE VERİLERİN
SINIFLANDIRILMASINDA KULLANILAN DİSKRİMİNANT VE LOJİSTİK REGRESYON ANALİZİ TEKNİKLERİNİN KARŞILAŞTIRILMASI
ZAFER ERTÜRK
YÜKSEK LİSANS TEZİ
EĞİTİM BİLİMLERİ ANABİLİM DALI
EĞİTİMDE ÖLÇME VE DEĞERLENDİRME BİLİM DALI
GAZİ ÜNİVERSİTESİ
EĞİTİM BİLİMLERİ ENSTİTÜSÜ
i
TELİF HAKKI ve TEZ FOTOKOPİ İZİN FORMU
Bu tezin tüm hakları saklıdır. Kaynak göstermek koşuluyla tezin teslim tarihi itibariyle tezden fotokopi çekilebilir.
YAZARIN
Adı : Zafer
Soyadı : Ertürk
Bölümü : Eğitimde Ölçme ve Değerlendirme
İmza :
Teslim Tarihi :
TEZİN
Türkçe ad: Ölçeklerin Faktör Yapısını Belirlemede Kullanılan Açımlayıcı Faktör Analizi ve Kümeleme Analizi ile Verilerin Sınıflandırılmasında Kullanılan Diskriminant ve Lojistik Regresyon Analizi Tekniklerinin Karşılaştırılması
İngilizce adı: The Comparison of Explanatory Factor Analysis and Clustering Analysis Which are Used for Determining Scale Factor Structure, and The Comparison Of Discriminant And Logistic Regression Analysis Techniques Which are Used for Data Classification
ii
ETİK İLKELERE UYGUNLUK BEYANI
Tez yazma sürecinde bilimsel ve etik ilkelere uyduğumu, yararlandığım tüm kaynakları kaynak gösterme ilkelerine uygun olarak kaynakçada belirttiğimi ve bu bölümler dışındaki tüm ifadelerin şahsıma ait olduğunu beyan ederim.
Yazar Adı Soyadı: Zafer Ertürk
iii
JÜRİ ONAY SAYFASI
Zafer ERTÜRK tarafından hazırlanan “Ölçeklerin Faktör Yapısını Belirlemede Kullanılan Açımlayıcı Faktör Analizi ve Kümeleme Analizi İle Verilerin Sınıflandırılmasında Kullanılan Diskriminant Ve Lojistik Regresyon Analizi Tekniklerinin Karşılaştırılması” adlı tez çalışması aşağıdaki jüri tarafından oy birliği ile Gazi Üniversitesi Eğitim Bilimleri Anabilim Dalı, Eğitimde Ölçme ve Değerlendirme Bilim Dalı’nda Yüksek Lisans Tezi olarak kabul edilmiştir.
Danışman: Prof. Dr. Mehtap ÇAKAN ………
Eğitim Bilimleri Anabilim Dalı, Eğitimde Ölçme ve Değerlendirme Bilim Dalı Gazi Üniversitesi
Başkan: Doç. Dr. Nuri DOĞAN
....……… Eğitim Bilimleri Anabilim Dalı, Eğitimde Ölçme ve Değerlendirme Bilim Dalı
Hacettepe Üniversitesi
Üye: Doç. Dr. Şeref TAN ……….
Eğitim Bilimleri Anabilim Dalı, Eğitimde Ölçme ve Değerlendirme Bilim Dalı Gazi Üniversitesi
Tez Savunma Tarihi: 29.01.2016
Bu tezin Eğitim Bilimleri Anabilim Dalı, Eğitimde Ölçme ve Değerlendirme Bilim Dalı’nda Yüksek Lisans tezi olması için şartları yerine getirdiğini onaylıyorum.
Eğitim Bilimleri Enstitüsü Müdürü
iv
v
TEŞEKKÜR
Çalışmalarım süresince düşünce, bilgi ve deneyimlerini benimle paylaşırken aynı zamanda farklı bakış açılarıyla da görmeyi öğreten, değerli hocam Sayın Prof. Dr. Mehtap ÇAKAN’a sonsuz teşekkürlerimi sunarım.
Veri toplama ve analiz etme ayrıca tez hazırlama süresince görüş, öneri ve bilgilerinden yararlandığım çok kıymetli hocalarım Doç. Dr. Şeref Tan, Yrd. Doç. Dr. Emine ÖNEN’e ve çok değerli arkadaşlarım Arş. Gör. Mehmet Şata, Okt. Dr. Ayfer Sayın, Arş. Gör. Vildan Bağcı, Arş.Gör Elif Sezer ve bu çalışmada yardımlarını gördüğüm Gazi Üniversitesi Eğitimde Ölçme ve Değerlendirme anabilim dalı öğretim üyeleri ve elemanlarına çok teşekkür ediyorum.
Ders dönemi ve tez dönemi boyunca bana her türlü ilgi ve desteğini veren, bu kocaman dünyada tek dayanağım ve her zaman yanımda olan anne ve babama çok teşekkür ediyorum.
vi
ÖLÇEKLERİN FAKTÖR YAPISINI BELİRLEMEDE KULLANILAN
AÇIMLAYICI FAKTÖR ANALİZİ VE KÜMELEME ANALİZİ İLE
VERİLERİN SINIFLANDIRILMASINDA KULLANILAN
DİSKRİMİNANT VE LOJİSTİK REGRESYON ANALİZİ
TEKNİKLERİNİN KARŞILAŞTIRILMASI
(Yüksek Lisans Tezi)
ZAFER ERTÜRK
GAZİ ÜNİVERSİTESİ
EĞİTİM BİLİMLERİ ENSTİTÜSÜ
OCAK, 2016
ÖZ
Bu araştırma üniversite öğrencilerinin akdemik güdülenmelerine etki eden faktörlerin belirlenmesi ve öğrencilerin güdülenme durumlarına göre sınıflandırılmasında faktör analizi, kümeleme analizi, diskriminant analizi ve lojistik regresyon tekniklerinin karşılaştırmalı olarak incelenmesi amacını taşımaktadır. Çalışmanın evrenini 2014-2015 eğitim öğretim yılında Gazi Üniversitesi Gazi Eğitim Fakültesi öğrencileri, örneklemini ise uygun örnekleme yöntemi ile seçilen 562 kız ve 109 erkek öğrenci olmak üzere toplam 671 öğrenci oluşturmaktadır. Araştırmaya katılan üniversite öğrencilerinin akademik güdülenmelerini belirlemek amacıyla Pintrich, Smith, Garcia ve McKeachie (1991) tarafından geliştirilen güdülenme ve öğrenme stratejileri ölçeğindeki güdülenme alt ölçeği kullanılmıştır. Öğrencilerin sosyo-demografik bilgileri ise araştırmacı tarafından oluşturulan “Kişisel Bilgi Formu” aracığıyla toplanmıştır. Verilerin analizinde SPSS 21 paket programı ile LISREL 8.8 paket programı kullanılmıştır. Hem açımlayıcı faktör analizi hem de kümeleme analizi ölçeğin faktör yapısını açıklamada benzer sonuçlar vermiştir. Öğrencilerin
vii
güdülenme durumlarına göre sınıflandırılmasında ise genel doğru sınıflandırma yüzdelerine bakıldığında diskriminant analizi %93,9’luk bir doğru sınıflandırma performansı gösterirken, lojistik regresyon analizi %91,2’lik doğru sınıflandırma performansı göstermiştir.
Bilim Kodu:
Anahtar Kelimeler: faktör analizi, kümeleme analizi, diskriminant, lojistik regresyon Sayfa Adedi: 138
viii
THE COMPARISON OF EXPLANATORY FACTOR ANALYSIS AND
CLUSTERING ANALYSIS WHICH ARE USED FOR DETERMINING
SCALE FACTOR STRUCTURE, AND THE COMPARISON OF
DISCRIMINANT AND LOGISTIC REGRESSION ANALYSIS
TECHNIQUES WHICH ARE USED FOR DATA CLASSIFICATION
(M.S THESIS)
ZAFER ERTÜRK
GAZI UNIVERSITY
GRADUATE SCHOOL OF EDUCATIONAL SCIENCES
JANUARY, 2016
ABSTRACT
The purpose of the study is compare the techniques of factor analysis, clustering analysis, discriminant analysis and logistic regression analysis in terms of the determination of factors affecting academic motivation of the university students and the classification of the students by their motivational level. The population of the study is Gazi University Gazi Education Faculty students who studied in 2014-2015 educational year and the sample of the study consists of 671 students (562 male and 109 female) who were selected by using convenient sampling. In order to determine academic motivational level of the university students, motivation sub-scale in “Motivated Strategies for Learning Questionnaire,” which was developed by Pintrich, Smith, Garcia and McKeachie (1991) was used. Personal information form that was created by the researcher was used for collecting data on students’ socio-demographic information. SPSS 21 package program and LISREL 8.8 package program
ix
were used for analyzing data. In the analysis conducted by using SPSS 21, both explanatory factor analysis and clustering analysis produced same results on explaining factor structure of the scale. In terms of the classification of the students’ motivational level, discriminant analysis and the logistic regression analysis performed 93,9% and %91,2% accurate classification performance, respectively.
Science Code:
Key Words: factor analysis, cluster analysis, discriminant analysis, logistic regression analysis.
Page Number: 138
x
İÇİNDEKİLER
TELİF HAKKI ve TEZ FOTOKOPİ İZİN FORMU... i
ETİK İLKELERE UYGUNLUK BEYANI ... ii
TEŞEKKÜR ... v
ÖZ ... vi
ABSTRACT ... viii
İÇİNDEKİLER ... x
TABLOLAR LİSTESİ ... xiv
ŞEKİLLER LİSTESİ ... xvi
SİMGELER VE KISALTMALAR LİSTESİ... xvii
BÖLÜM I ... 1 GİRİŞ ... 1 Problem Durumu ... 1 Problem İfadesi ... 8 Araştırma Soruları ... 8 Araştırmanın Amacı ... 9 Araştırmanın Önemi ... 10 Sınırlılıklar ... 10 BÖLÜM II ... 11 KURAMSAL TEMELLER ... 11
xi
Açımlayıcı Faktör Analizine İlişkin Temel Kavramlar ... 11
Korelasyon Matrisi ... 12
Öz Değer ... 12
Yamaç-Birikinti Grafiği ... 12
Faktör Yük Değeri ... 13
Ortak Faktör Varyansı, Varyans Oranı ve Kovaryans Oranları ... 13
Faktörleştirme ... 13
Faktör Döndürme ... 15
Sayıltılar ve Analizin Diğer Gereklilikleri ... 17
Örneklem Büyüklüğü ... 17 Kayıp Değerler... 18 Normallik ... 18 Doğrusallık ... 18 Çoklu Bağlantı ... 19 Uç Değerler ... 19 Kümeleme Analizi ... 20
Kümeleme Analizinin Aşamaları... 22
Değişkenlerin Dönüştürülmesi ... 23
Kümeleme Analizinin Sayıltıları ve Diğer Gereklilikleri ... 24
Kümeleme Analizinde Benzerlik ve Farklılık Ölçüleri ... 24
Uzaklık Ölçüleri ... 25
Kümeleme Yöntemleri ... 27
Hiyerarşik Yöntemler ... 28
xii
Diskriminant Analizi ... 33
Diskriminant Analizinin Varsayımları ... 36
Lojistik Regresyon Analizi ... 41
BÖLÜM III ... 47
İLGİLİ ARAŞTIRMALAR ... 47
Açımlayıcı Faktör, Kümeleme, Diskriminant ve Lojistik Regresyon Analizleri ile İlgili Yapılan Araştırmalar ... 47
BÖLÜM IV ... 57
YÖNTEM... 57
Araştırmanın Deseni ... 57
Evren ve Örneklem ... 57
Veri Toplama Aracı ... 58
Güdülenme Ölçeğinin Geçerlik ve Güvenirlik Çalışması ... 61
Veri Analizi ... 65
BÖLÜM V... 69
BULGULAR VE YORUMLAR ... 69
Birinci Araştırma Sorusuna İlişkin Bulgular ve Yorumlar ... 69
1.1 Güdülenme Ölçeğinin faktör yapısını belirlemek için uygulanan Açımlayıcı Faktör Analizi sonuçları nasıldır? ... 69
1.2 Güdülenme Ölçeğinin faktör yapısını belirlemek için uygulanan Kümeleme Analizi sonuçları nasıldır? ... 72
1.3 Güdülenme Ölçeğinin Faktör Yapısını Belirlemek İçin Uygulanan Açımlayıcı Faktör Analizi ile Kümeleme Analizi Tekniklerinin Sonuçları Arasındaki Benzerlik ve Farklılıklar Nelerdir? ... 77
xiii
2.1 Güdülenme Ölçeğine İlişkin Bulunan Faktörler Göz Önüne Alındığında;
Diskriminant Analizinin Öğrencileri Sınıflandırma Performansı Nasıldır? ... 85
2.2 Güdülenme Ölçeğine İlişkin Bulunan Faktörler Göz Önüne Alındığında; Lojistik Regresyon Analizinin Öğrencileri Sınıflandırma Performansı Nasıldır? ... 91
2.3 Güdülenme Ölçeğine İlişkin Bulunan Faktörler Göz Önüne Alındığında; Öğrencilerin Diskriminant Analizi ve Lojistik Regresyon Analizlerinin Sonuçları Arasındaki Benzerlik ve Farklılıklar Nelerdir? ... 95
BÖLÜM VI ... 99
SONUÇ TARTIŞMA ve ÖNERİLER ... 99
Sonuçlar ... 99
Birinci Araştırma Sorusuna İlişkin Sonuçlar... 99
1.1 Açımlayıcı Faktör Analizi ile Elde Edilen Sonuçlar ... 99
1.2 Kümeleme Analizi ile Elde Edilen Sonuçlar ... 100
1.3 Açımlayıcı Faktör Analizi ve Kümeleme Analizi’nin Karşılaştırılmasına İlişkinElde Edilen Sonuçlar ... 100
İkinci Araştırma Sorusuna İlişkin Sonuçlar ... 102
2.1 Diskriminant Analizine İlişkin Elde Edilen Sonuçlar ... 104
2.2 Lojistik Regresyon Analizine İlişkin Elde Edilen Sonuçlar ... 105
2.3 Diskriminant Analizi ve Lojistik Regresyon Analizi’nin Karşılaştırılmasına İlişkin ile Elde Edilen Sonuçlar ... 106
Öneriler ... 109
xiv
TABLOLAR LİSTESİ
Tablo 1. Öğrencilerin Cinsiyet, Sınıf ve Bölümlere Dağılımına İlişkin Frekans ve Yüzde
Değerleri ... 58
Tablo 2. Güdülenme Ölçeğinin Toplam Puanlarına Ait Betimsel İstatistikler ... 59
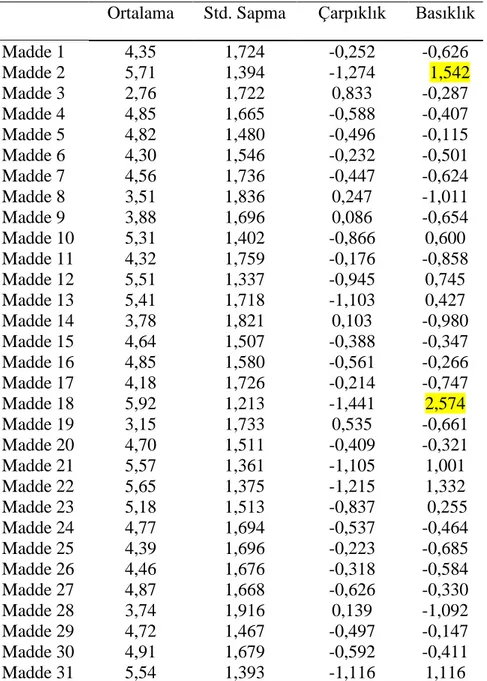
Tablo 3.Güdülenme Ölçeğinin Maddelerine İlişkin Betimsel İstatistikler ... 60
Tablo 4. Güdülenme Ölçeği Uyum İndeksleri ve Uyum İndekslerinin Kabul Sınırları ... 63
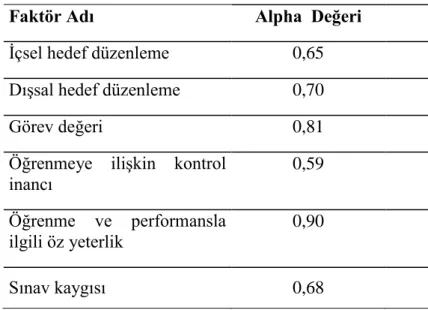
Tablo 5. Güdülenme Ölçeğinin Cronbach Alpha Katsayıları ... 65
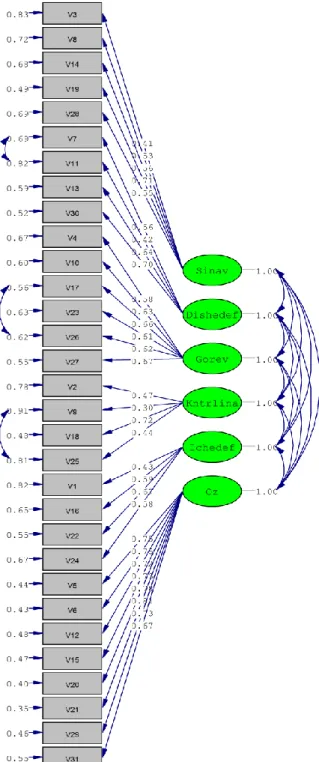
Tablo 6. Güdülenme Ölçeğinin Kuramsal Alt Yapısı (Modeli) ... 66
Tablo 7. Güdülenme Ölçeğine Ait Faktörlerin Faktör Yükleri ve Faktörlerin Açıkladıkları Varyans Miktarı ... 71
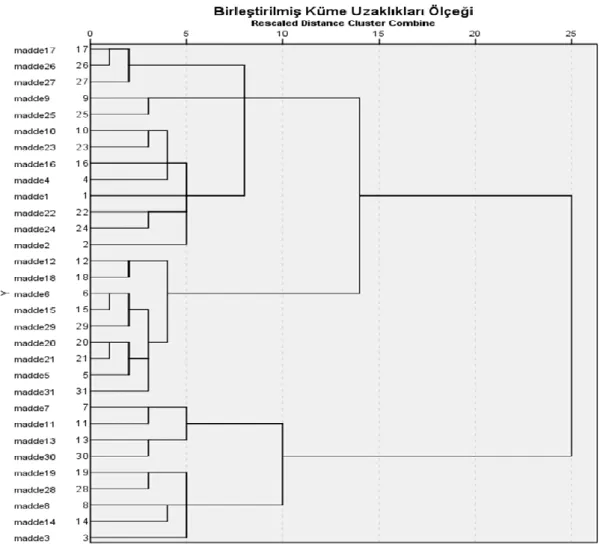
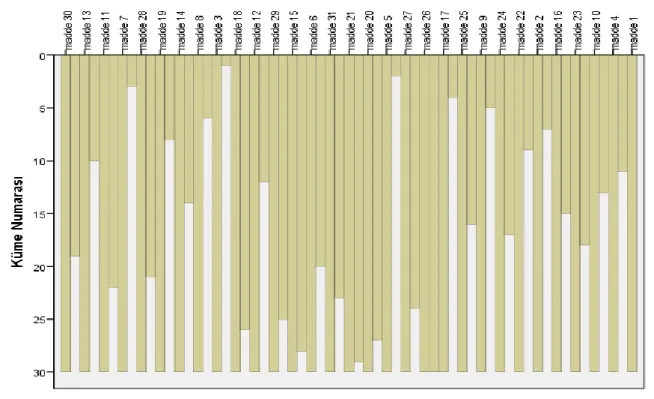
Tablo 8. Ward Kümeleme Yöntemi ile Oluşturulan Birleştirme Tablosu………...75
Tablo 9. Ward Kümeleme Tekniği İle Elde Edilen Kümeler ve Kümelerde Yer Alan Maddeler ... 76
Tablo 10. Açımlayıcı Faktör Analizi ve Kümeleme Analizi Sonuçlarına Göre Kurulan Modellerin Doğrulayıcı Fakötr Analizi Sonuçlarının Karşılaştırılması ... 77
Tablo 11. AFA ve KA Sonuçlarına Göre Elde Edilen Faktör Yapısı ve Faktörlere Düşen Maddeler ... 79
Tablo 12. KA ve AFA’ ya Göre Elde Edilen Faktörlerin Cronbach Alpha Güvenirlik Katsayıları ... 81
Tablo 13. K-ortalamalar Tekniğine Göre Başlangıç Küme Üyelikleri………82
Tablo 14.K-ortalamalar Tekniğine Göre İterasyon Hikayesi ... 82
xv
Tablo 16. Son Küme Merkezleri Arasındaki Mesafeler ... 83
Tablo 17. K-ortalamalar Tekniğine Göre Elde Edilen ANOVA Tablosu ... 84
Tablo 18. K-ortalamalar Tekniğine Göre Kümelerdeki Kişi Sayısı ... 84
Tablo 19. Diskriminant Analizindeki Küme İstatistikleri... 86
Tablo 20. Diskriminant Analizinde Öz Değer İstatistik Tablosu ... 87
Tablo 21.Diskriminant Analizinde Wilks' Lambda İstatistiği ... 88
Tablo 22. Diskriminant Analizi Sonucu Elde EdilenWilks' Lambda Grup Ortalamalarının Eşitliği Testi ... 89
Tablo 23. Diskriminant Fonksiyonlarına İlişkin Standartlaştırılmış Katsayılar ... 89
Tablo 24.Diskriminant Analizi Sonucu Elde EdilenYapı Matrisi Katsayıları ... 90
Tablo 25. Diskriminant Analizi Sınıflandırma Sonuçları ... 91
Tablo 26. Lojistik Regresyon Analizi Değişkenlere İlişkin Log-Olabilirlik Değerleri ... 92
Tablo 27. Lojistik Regresyon Analizine İlişkin Kurulan Modelin Log Olabilirlik Uyum İndeksi ... 92
Tablo 28.Lojistik Regresyon Analizine İlişkin Elde Edilen Model Özeti ... 93
Tablo 29. Lojistik Regresyon Modelindeki Değişkenlere İlişkin İstatistikler ... 93
Tablo 30. Lojistik Regresyon Analizi Sonucu Elde Edilen Sınıflandırma Sonuçları ... 95
Tablo 31. Diskriminant Analizi (D.A) ve Lojistik Regresyon Analizi (L.R.A) Sınıflandırma Yüzdesi Karşılaştırması ... 96
xvi
ŞEKİLLER LİSTESİ
Şekil 1. Tek bağlantı yöntemi………..29 Şekil 2. Tam bağlantı yöntemi……….29 Şekil 3. Ortalama bağlantı yöntemi………...30 Şekil 4. Güdülenme ölçeğinin faktör yapısına ilişkin tanımlanan birinci düzey ölçme modeli………...…64 Şekil 5. Ward kümeleme yöntemi ile yapılan kümeleme analizinin dendrogram grafiği………...73 Şekil 6. Ward kümeleme yöntemiyle yapılan kümeleme analizi……….74
xvii
SİMGELER VE KISALTMALAR LİSTESİ
AFA Açımlayıcı Faktör Analizi
KA Kümeleme Analizi
ÇBÖ Çok Boyutlu Ölçekleme
DA Diskriminant Analizi
LRA Lojistik Regresyon Analizi
GÖSÖ Güdülenme ve Öğrenme Stratejileri Ölçeği GÖ Güdülenme Ölçeği
1
BÖLÜM I
GİRİŞ
Bu bölümde problem durumu, araştırma soruları, araştırmanın amacı, önem, sınırlılıkları ve sayıltılarına yer verilmiştir.
Problem Durumu
Yapılan araştırmaların geçerliliği ve güvenilirliğini artırabilmek için araştırma konusu olayları olabildiğince tüm yönleriyle değerlendirmek gerekir. Bunu yapabilmek içinde araştırmacılar amaçlarına uygun olan bir takım istatistiksel işlemlerden faydalanmaktadırlar. Kullanılacak istatistiksel işlemler ise araştırma verisinin yapısına ve araştırmada kullanılan ölçme aracının psikometrik niteliklerine göre farklılık göstermektedir.
Günümüzde yapılan bazı araştırmalarda karşılaşılan sorunlardan birisi elde edilen iki ya da daha fazla özellik arasındaki ilişkiyi incelerken tek değişkenli istatistik yöntemlerinin yeterli olmamasıdır. Bunun nedeni bir verinin sahip olduğu bir özelliği, çok sayıda özelliğin etkilemesi ve bu özellikler arasında ilişkilerin bulunmasıdır. Bir problemin çözümünde problemi etkileyen birçok faktör vardır. Problemin çözümünde bu faktörlerin olabildiğince fazlası dikkate alınması ve eşzamanlı olarak incelenmesi gerekmektedir. Tek değişkenli istatistikler yöntemler bunu sağlayamazlar. Çok değişkenli istatistiksel yöntemler ise karmaşık veri setlerindeki çok sayıdaki bağımsız ve bağımlı değişkenler arasındaki ilişkileri eşzamanlı olarak analiz etmeyi sağlarlar. Ayrıca çok değişkenli istatistiksel teknikler, çalışmaların sonunda elde edilen verilerin özetlenmesi ve yorumlanmasında da kullanılmaktadır (Mertler ve Vannatta, 2005).
Aynı amaçlar doğrultusunda kullanılabilen birden fazla çok değişkenli istatistiksel yöntem bulunmaktadır. Bu yöntemler arasında benzerlik ve farklılıklar bulunmaktadır. Yöntem
2
karşılaştırmasına dayalı yapılan çalışmalarda bu analiz yöntemlerinden elde edilen sonuçlar karşılaştırılarak tekniklerin benzer ve farklı yönleri belirlenmeye çalışılmıştır. Yöntemler arasındaki benzerlik ve farklılıkların belirlenmesi araştırmacıların veri yapısına ve değişkenlerin türüne uygun yöntemi seçmelerinde yardımcı olacaktır.
Bir araştırmada kullanılan bir ölçeğin faktör yapısını belirlemede en çok kullanılan ve bilinen yöntem açımlayıcı faktör analizidir. Fakat açımlayıcı faktör analizinin dışında, kümeleme analizi de ölçeklerin faktör yapısını ve sayısını belirlemede kullanılabilmektedir. Açımlayıcı faktör analizi, aralarında ilişki bulunan çok sayıdaki değişkeni bir araya getirerek, kavramsal olarak anlamlı daha az sayıda yeni değişkenler (faktörler, boyutlar) bulmayı, keşfetmeyi amaçlayan çok değişkenli bir istatistik analiz tekniğidir. Araştırmacı, açımlayıcı faktör analizini verilerin kovaryans ya da korelasyon matrisinden yararlanılarak birbirleri ile ilişkili p sayıda değişkenden daha az sayıda (k<p) ve birbirlerinden bağımsız yeni değişkenler türetmek üzere kullanabilir (Thompson, 2004). Açımlayıcı faktör analizinden farklı olarak kümeleme analizi ise gruplamaları kesin olarak bilinmeyen X veri matrisindeki birimleri, değişkenleri veya birim ve değişkenleri aralarındaki benzerlik ya da farklılıklara dayalı olarak hesaplanan bazı ölçümlerden yararlanarak birbirleri ile benzer olan alt gruplara ayırır (Hair, Black, Babin, Anderson, ve Tatham, 2006).
Tabachnick ve Fidell (2013 ) tarafından faktör analizi, faktörleştirme ya da ortak faktör adı verilen yeni kavramları (değişkenleri) ortaya çıkarma ya da maddelerin faktör yük değerlerini kullanarak kavramların işlevsel tanımlarını elde etme süreci olarak tanımlanmaktadır. Faktör analizi, araştırmacının kullanım amacına göre açımlayıcı faktör analizi (AFA) ve doğrulayıcı faktör analizi (DFA) olmak üzere ikiye ayrılır.
AFA, araştırmacının ölçme aracının ölçtüğü faktör yapısı hakkında bilgi sahibi olmadığı durumlarda, ölçme aracının faktör yapısı hakkında bilgi edinmek amacıyla yaptığı bir analiz türüdür (Crocker ve Algina, 2006). DFA’ nın ise, daha çok AFA’dan sonra uygulanan bir teknik olduğu ve araştırmacıların AFA ile belirlemiş oldukları faktör yapılarını DFA’ ya tabi tuttukları ifade edilmektedir (Kline, 2011). AFA ile elde edilen faktörlerin hangi değişkenler ile yüksek düzeyde ilişkili olduğunu belirlemede, elde edilen faktörlerde yer alan değişkenlerin bu faktörlerce temsil edilip edilmediğinin belirlenmesinde ise DFA’ dan yararlanılmaktadır (Jöreskog ve Sörbom, 1993).
3
Kümeleme analizinde, veri matrisinde yer alan n birimin p değişkene göre uzaklıkları oluşturulur ve bu uzaklık matrisi (D) ile gösterilir. Değişkenlerin aralarındaki benzerlikler ise ilişki matrisi (R) ile ifade edilir. Birimlerin birbirleri ile olan benzerlik düzeyleri benzerlik matrisi (Sim) ile gösterilebilir. Kümeleme analizi, benzerlik matrisin elemanlarını D matrisinin elemanlarına göre belirleyerek homojen gruplar oluşturur. Bu şekilde küme içi homojenlikler sağlanırken, kümeler arasında ise heterojenlikler oluşur. Eğer kümeler başarılı bir şekilde ayrılırsa, geometrik gösterim yapıldığı zaman aynı küme içindeki nesneler birbirine yakın iken, farklı kümelerde yer alan nesneler birbirlerinden uzakta bulunacaklardır (Hair vd., 2006).
Eğitim bilimlerinde açımlayıcı faktör analizi ve kümeleme analizinin karşılaştırıldığı az sayıda çalışma bulunmaktadır. Bunlardan biri, Doğan ve Başokçu (2010) tarafından istatistik tutum ölçeği için uygulanan açımlayıcı faktör analizi ve aşamalı kümeleme analizi sonuçlarının karşılaştırılmasıdır. Araştırmada ölçek geliştirmede boyut sayısını ve boyutlara düşen maddeleri belirlemede kullanılan açımlayıcı faktör analizi ve aşamalı kümeleme analizi tekniklerinin benzer sonuç verip vermediği, yapıya ilişkin kuramsal tutarlığı sağlayıp sağlamadıkları ve açıkladıkları yapı için elde edilen doğrulayıcı faktör analizi sonuçlarının benzer olup olmadığı incelenmiştir. Araştırma sonuçlarına göre döndürülmüş faktör analiziyle elde edilen yapı ile iki aşamalı kümeleme analiziyle elde edilen yapıya ilişkin doğrulayıcı faktör analiz sonuçlarının büyük benzerlik gösterdiği görülmüştür. Buna rağmen faktörlerdeki maddeler ve madde sayısı bakımından faktör analizi ve aşamalı kümeleme analizinde farklılıklar bulunmuştur.
Bir diğer çalışma ise Şimşek (2006) tarafından yapı geçerliği kanıtlarının karşılaştırılması amacı ile çok boyutlu yapıyı ölçen öfke ölçeğini, Çok Boyutlu Ölçekleme (ÇBÖ), kümeleme analizi (KA), Doğrulayıcı Faktör Analizi (DFA) ve Açımlayıcı Faktör Analizi (AFA) teknikleri ile incelemiştir. KA ve ÇBÖ’ ye ilişkin elde edilen sonuçlar AFA’ ya göre değerlendirildiğinde KA’ nin AFA’ ya göre daha duyarlı bir çözüm sağladığı ve uyumlu sonucun elde edildiği ifade edilmiştir. ÇBÖ’ de ise çok farklı sonuçlara ulaşılmış ve uyum görülmemiştir.
Çok değişkenli istatistiksel yöntemlerin kullanım amaçlarından biriside sınıflandırmadır. Araştırmacılar farklı yığınlardan gelen bireylerin p sayıdaki özelliğini ölçtüğünde elindeki bireyin hangi gruptan geldiğini merak edebilir. Bu durumda araştırmacı sınıflandırma
4
tekniklerini kullanarak p sayıda özelliğini incelediği bireyin hangi gruptan geldiğine karar verebilir. Sınıflandırma yapılırken araştırmacı için iki karar verme konusu bulunmaktadır. Birincisi grubun ayırt edici özelliklerini araştırarak ayırt edicilikte etkili olan değişkenleri belirlemek, ikincisi bu ayırt edici değişkenlerin oluşturduğu bir sınıflandırma fonksiyonu oluşturup, bu fonksiyon yardımıyla bireyleri gruplara sınıflandırmaktır. Ayrıca çok değişkenli istatiksel verilerin sınıflandırılması, bu verilere uygulanabilecek çeşitli istatistiksel teknikler için gerekli ve yararlı bilgiler verecektir.
Sınıflandırmada kullanılan çok değişkenli istatistik yöntemler incelendiğinde grupların önceden bilinmesi veya bilinmemesi durumuna göre ikiye ayrıldıkları görülmektedir. Grupların önceden bilinmemesi durumuna göre sınıflandırmada çok boyutlu ölçekleme analizi ve kümeleme analizi kullanılırken, sınıfların önceden bilinmesi durumunda ise diskriminant analizi ve lojistik regresyon analizi kullanılmaktadır.
Grupların önceden bilinmesi durumunda kullanılan diskriminant analizinde birimlerin sahip oldukları çok sayıdaki özellikler dikkate alınarak, bu özelliklere göre birimlerin doğal ortamdaki gerçek sınıflarına optimal yerleştirilmeleri sağlanır. Birimlerin gruplanmasında bazı matematiksel eşitliklerden faydalanılır. Bu eşitlikler diskriminant fonksiyonu olarak isimlendirilirler ve birbirine en çok benzeyen grupları belirlemeye olanak sağlayacak şekilde grupların ortak özelliklerini belirlemede kullanılırlar. Grupları ayırmada ise karakteristik olarak isimlendirilen diskriminant değişkenleri kullanılmaktadır. Yani diskriminant analizi, iki veya daha fazla sayıdaki grubun farklılıklarının diskriminant değişkenleri vasıtasıyla ortaya konması işlemidir (Klecka, 1980).
Diskriminant analizi gibi grupların önceden bilinmesi durumunda sınıflandırmada kullanılan bir diğer yöntem olan lojistik regresyon analizi ise, bağımlı değişkeninin ikili, üçlü ve çoklu kategorilerde yer aldığı durumlarda bağımsız değişkenlerle bağımlı değişkenler arasındaki neden sonuç ilişkilerini açıklamada kullanılmaktadır. Bağımsız değişkenlere göre cevap değişkeninin beklenen değerleri olasılık olarak elde edildiği regresyon analizi tekniklerinden biridir. Lojistik regresyon analizi, verilerin sınıflanması ve atama işlemlerinde kullanılmaktadır. Bu teknikte bağımlı değişken üzerinde bağımsız değişkenlerin etkileri belirlenmeye çalışılmaktadır (Mertler ve Vannatta 2005).
Alan yazına baktığımız zaman gözlemlerin gruplara ayrılmasında en çok kullanılan yöntemler arasında yukarıda tanımlarını verdiğimiz kümeleme analizi, diskriminant analizi
5
ve lojistik regresyon analizi teknikleri bulunmaktadır. Bu üç teknikten diskriminant analizi ve kümeleme analizi eskiden beri bilinen ve birçok alanda kullanılan tekniklerdir. Lojistik regresyon analizi ise son yıllarda yaygınlaşan ve birçok alanda kullanılmaya başlanan bir tekniktir. Lojistik regresyon analizi çeşitli varsayımların (normallik, ortak kovaryansa sahip olma gibi) bozulması durumunda diskriminant analizine bir alternatif yöntem olarak ortaya çıkmış bir tekniktir. Lojistik regresyon analizi bağımlı değişkenin 0,1 gibi ikili (binary) ya da ikiden çok düzey içeren (polychotomous) çok kategorili değişken olması durumunda normallik varsayımı kısıtlaması olmaması nedeniyle kullanım rahatlığı sağlamaktadır. Ayrıca lojistik regresyon analizi ile yapılan çözümlemeden elde edilen matematiksel modelin yorumlanması kolay olmaktadır (Poulsen ve French, 2008).
Bağımlı değişkenin kategorik, bağımsız değişkenlerin kategorik ya da sürekli olduğu durumlarda kullanılan lojistik regresyon analizi bağımlı değişken ile bağımsız değişkenler arasındaki ilişkileri açıklamaya çalışan bir yöntemdir. Bağımlı değişkenin kategorik olduğu durumlarda lojistik regresyon analizi dışında diskriminant analizi, probit analizi ve logoritmik doğrusal regresyon da kullanılan diğer tekniklerdir (Oğuzlar, 2005).
Diskriminant analizi ve lojistik regresyon analizi aynı amaçlar doğrultusunda kullanılan iki teknik olmasına karşın araştırma verisinin yapısına ve tekniklerin karşılaması gereken sayıltılara göre farklılık göstermektedirler. Diskriminant analizi normal dağılım, doğrusallık, varyans-kovaryans matrislerinin eşitliği gibi sayıltıların karşılanmasını durumunda kullanılırken, lojistik regresyon analizi bu sayıltıların karşılanmaması durumunda da kullanılabilmektedir. Bu nedenle araştırmacılar, verileri sınıflandırmada hangi yöntemi kullanacağına karar verirken, analiz tekniklerinin bu özelliklerini dikkate almak durumundadırlar. Verilerin sınıflandırılmasında kullanılan tekniklerin karşılaştırıldığı çalışmalar incelendiğinde tekniklerin sınıflandırmadaki performanslarının farklılık gösterdiği ve tekniklerin sınıflandırmadaki üstünlüklerinin çalışmadan çalışmaya farklılık gösterdiği görülmüştür.
Örneğin; Hardgrave, Wilson ve Walstrom (1994) MBA öğrencilerinin başarılarını tahmin etmede en küçük kareler regresyonu, aşamalı regresyon, diskriminant analizi, lojistik regresyon ve yapay sinir ağlarını kullanarak bu yöntemlerin karşılaştırmasını yapmışlardır. Uygulanan modellerden en iyisi % 60 doğrulukla tahmin yapabilirken, diskriminant analizi,
6
lojistik regresyon ve yapay sinir ağları yöntemleri regresyon modellerinden daha iyi sonuçlar vermiştir.
Burmaoğlu, Oktay ve Özen (2009) tarafından yapılan çalışmada ise, diskriminant analizi ile lojistik regresyon analizinin sınıflandırma performansları karşılaştırılmıştır. Yapılan araştırmada bağımsız değişkenler olarak Birleşmiş Milletler Kalkınma Programı tarafından Beşeri Kalkınma Endeksinin hesaplanmasında kullanılan metrik değişkenler göz önüne alınmıştır. Bağımlı değişken olarak ise çok gelişmiş ülkeler ve orta düzeyde gelişmiş ülkeler olmak üzere iki kategorili bir yapı kullanılmıştır. Sınıflandırma sonuçları incelendiğinde diskriminant analizi ile % 92,5’lik, lojistik regresyon analizi ile ise % 100’lük bir başarı elde edilmiştir.
Ayrıca, Tektaş (2014) diskriminant analizi ve lojistik regresyon analizinin sınıflandırma performanslarını karşılaştırmak için Marmara Üniversitesi Teknik Bilimler Meslek Yüksekokulu Elektronik ve Otomasyon Bölümünde öğrenim gören öğrencilerin bölümlerinden memnun olup/olmama düzeylerini belirlemeye çalışmıştır. Bu çalışmanın sonucunda diskriminant analizinin öğrencileri sınıflandırmada lojistik regresyon analizinden daha iyi sonuçlar verdiği görülmüştür.
Press ve Wilson (1978) ise yaptıkları sınıflama çalışmasında lojistk regresyon analizi ile diskriminant analizini birlikte kullanmışlar ve elde ettikleri sonuçları karşılaştırmışlardır. Araştırmanın sonucunda, eğer üzerinde çalışılan popülasyonun eş kovaryansa sahip normal bir dağılım ise diskriminant analizinin lojistik regresyon analizine göre daha duyarlı sonuçlar verdiğini tespit etmişlerdir. Normalliğin karşılanmadığı durumlarda ise lojistik regresyon analizinin kullanılmasını önermişlerdir.
Diskriminant analizi ve lojistik regresyon analizinim sınıflandırma performansları bağımlı değişkenin iki ve ikiden daha çok kategeroli olması durumunda değişmektedir. Bağımlı değişkenin iki kategorili olması durumunda lojistik regresyon analizi ile diskriminant analizine göre daha yüksek bir sınıflandırma başarısı elde edilirken, bağımlı değişkenin ikiden daha çok kategorili olduğu durumlarda ise diskriminant analizi ile daha iyi sonuçlar elde edilmektedir. Başarır (1990) yaptığı çalışmada, lojistik regresyon analizini, kardiyolojik ve Öğrenci Seçme Sınavına ilişkin verilere uygulamış elde ettiği sonuçları diskriminant analizi sonuçları ile karşılaştırmıştır. Kardiyolojik verilerde, ikili grup lojistik modellerin ve diskriminant fonksiyonun ayırsama güçleri karşılaştırıldığında diskriminant analizi
7
varsayımlarının bozulumu nedeni ile lojistik regresyon modellerinin daha iyi ayırsama verdiği görülmüştür. Bağımlı değişkenin dört gruptan oluşan ÖSS verilerine uygulanan lojistik regresyon analizinin ayırsama gücü ise oldukça düşük çıkmıştır. Ayrıca lojistik regresyon analizinin somut ölçümlere dayalı verilerde iyi sonuç verebildiği, somut ölçümlerin elde edilmediği sosyal uygulamalarda ise yetersiz kalabildiği sonucu ortaya çıkmıştır.
Aynı araştırma sorusu için kullanılabilen istatiksel yöntemlerin farklı sonuçlar vermesinin nedenleri arasında yöntemlerin kendilerine özgü algoritmaları bulunması ve karşılamaları gereken sayıltılarının farklı olması gösterilebilir. Bu nedenle istatistiksel yöntemlerin karşılaştırılması ve elde edilen sonuçların benzerlik ve farklılıkların incelenmesi, araştırmacıların en iyi sonuca ulaştıracak yöntemi belirlemesi adına önemli görülmektedir. Bu çalışmada da çok geniş kullanım yelpazesine sahip olan çok değişkenli istatistiksel yöntemlerden açımlayıcı faktör analizi ve kümeleme analizi ile diskriminant analizi ve lojistik regresyon analizlerinin ikişerli karşılaştırmaları yapılacaktır. Yöntemlerin karşılaştırılması için iki düzeyli bir yapıya sahip olan güdülenme ölçeği kullanılmıştır. Ölçeğin boyutlarını (faktörlerini) belirlemede açımlayıcı faktör analizi ve kümeleme analizi yöntemleri kullanılmış ve her iki teknikten elde edilen modeller doğrulayıcı faktör analizi ile sınanmıştır. Elde edilen sonuçlara açınlayıcı faktör analizi ve kümeleme analizinin üstün ve zayıf yönleri açıklanmaya çalışılmıştır. Ayrıca öğrencileri güdülenme durumlarına göre sınıflandırmak içinde diskriminant analizi ve lojistik regresyon analizi kullanılmış ve bu iki yönteminde sınıflandırma performansları karşılaştırılarak elde edilen sonuçların ne oranda benzerlik ve farklılık gösterdiği incelenmiştir.
Araştırma kapsamında istatistiksel yöntemlerin karşılaştırmasını yapmak için kullanıdğımız güdülenme kavramı, birveya birden fazla insanı, belirli bir gaye veya amaca doğru devamlı bir şekilde harekete geçirmek için yapılan çabaların toplamıdır. Dilimize de güdüleme yani harekete geçiren güç olarak yerleşmiştir. Güdüleme insanı harekete geçiren ve hareketlerinin yönlerini belirleyen, onların düşünceleri umutları inançları kısaca; arzu, ihtiyaç ve korkularıdır (Yapıcı ve Yapıcı, 2010). Yeterli güdülenmeye sahip olan öğrenciler akademik çalışmalarda öğrenme sürecine aktif biçimde katılabilmektedirler. Yüksek düzeyde güdülenmeye sahip olan öğrencilerde kendilerine verilen zor görevleri yerine getirmede ve çaba harcamada daha isteklidirler. Aynı zamanda bu tip öğrenciler etkili problem çözme
8
stratejileri de kullanabilme gücüne sahiptirler. Diğer taraftan güdülenmesi düşük olan öğrenciler ise az çaba gerektiren görevleri tercih ederken, zorluklar karşısında da görevlerini çok çabuk terk edebilmektedirler (Elliot, Mcgregor, ve Gable, 1999). Güdülenme eğitimde öğrenci başarısının etkileyen faktörlerin başında gelmektedir. Bu nedenle bu çalışmada kullanılan güdülenme ölçeğinin farklı teknikler kullanılarak detaylı bir şekilde incelenmesinin ölçeğe katkı getirmesi de umulmaktadır.
Problem İfadesi
Ölçeklerin faktör yapısını belirlemede kullanılan açımlaycı faktör analizi ve kümeleme analizinin sonuçları ile sınıflandırmada kullanılan diskrminant analizi ve lojistik regresyon analizi sonuçlarının karşılaştırılmalı olarak incelenmesi.
Araştırma Soruları
1. Güdülenme Ölçeğinin;
1.1 Faktör yapısını belirlemek için uygulanan Açımlayıcı Faktör Analizi sonuçları
nasıldır?
1.2 Faktör yapısını belirlemek için uygulanan Kümeleme Analizi sonuçları
nasıldır?
1.3 Faktör yapısını belirlemek için uygulanan Açımlayıcı Faktör Analizi ile
Kümeleme Analizi tekniklerinin sonuçları arasındaki benzerlik ve farklılıklar nelerdir?
2. Güdülenme ölçeğine ilişkin yukarıda bulunan faktörler göz önüne alındığında; 2.1 Diskriminant analizinin öğrencileri sınıflandırma performansı nasıldır?
9
2.2 Lojistik regresyon analizinin öğrencileri sınıflandırma performansı nasıldır? 2.3 Öğrencilerin güdülenme durumlarına göre sınıflandırılmasında diskriminat
analizi ile lojistik regresyon analizlerinin sonuçları arasındaki benzerlik ve farklılıklar nelerdir?
Araştırmanın Amacı
Herhangi bir araştırma kapsamında kullanılacak bir ölçeğin kaç boyutlu bir yapıya sahip olduğunu saptamak için belirli tekniklerden yararlanmak mümkündür. Açımlayıcı faktör analizi en yaygın olarak kullanılan yöntemlerin başında gelmektedir. Kümeleme analizi ise çok fazla bilinmemekle birlikte ölçeklerin faktör yapısını belirlemede kullanılması mümkün olan bir diğer yöntemdir. Açımlayıcı faktör analizi ölçeklerin faktör yapısını belirlemede, değişkenler arasındaki ilişkilere dayalı olarak hesaplama yaparken, kümeleme analizi ise değişkenler arasındaki uzaklıkları göz önüne almaktadır. Bu çalışmada ölçeğin faktör yapısı açımlayıcı faktör analizi ve kümeleme analizi teknikleri ile karşılaştırılmalı olarak incelenerek iki yöntem arasındaki benzerlikler ve farklılıklar belirlenmeye çalışılmıştır. Ayrıca, öğrencilerin güdülenme durumlarına göre sınıflandırmalarını yapmak için diskriminant analizi ve lojistik regresyon analizi teknikleri kullanılmıştır. Bağımlı değişkenin kategorik olması durumunda bireyleri sınıflandırmada kullanılan bu iki yöntemin eğitim bilimlerinde karşılaştırıldığı çalışma sayısı azdır. Yapılan çalışmalarda da bağımlı değişkenin iki kategorili olduğu durumlarda analiz teknikleri karşılaştırılmıştır. Bu çalışmada ise bağımlı değişkenin ikiden fazla kategorisi olması durumunda diskriminant analizi ile lojistik regresyon analizinin sınıflandırma performanslarının karşılaştırılması amaçlanmıştır. Aynı amaç doğrultusunda kullanılan bu yöntemlerin karşılaştırılarak hangi durum ve koşullarda hangisinin kullanılacağının belirlenmesinin eğitim bilimlerinde bu yöntemleri kullanacak araştırmacılara yol göstermesi amaçlanmaktadır.
Araştırmanın Önemi
Ölçeklerin faktör yapısını belirlemek için genellikle tek bir yöntem kullanılmakta bu ise kapsamlı ve doğru sonuçlara ulaşmada yeterli olmamaktadır. Dolayısıyla tek bir ölçme aracı üzerinde birden fazla teknik birlikte kullanılarak elde edilen sonuçların karşılaştırılması
10
ölçme aracı ile ilgili daha sağlıklı sonuçların elde edilmesini sağlayacaktır. Bu nedenle bu çalışmada ölçeğin faktör yapısını belirlemek için uygulanan açımlayıcı faktör analizi ve kümeleme analizi sonuçlarının karşılaştırılmasının araştırmacıyı en iyi sonuca ulaştıracak yöntemi belirlemesine yardım edecek veya elde ettiği sonucu destekleyici güçlü kanıtlara ulaşmasını sağlayacaktır.
Yapılan bir araştırmada, araştırmacı p sayıdaki özelliğini ölçtüğü bireyin hangi gruptan geldiğini merak edebilir. Bu durumda araştırmacı farklı niteliklere sahip bireyleri sınıflara yerleştirecek bir sınıflayıcıya ihtiyaç duyar. Diskriminant analizi sınıflandırma yapmak için kullanılan tekniklerden biridir. Lojistik regresyon analizi de günümüzde diskriminant analizinin yerine kullanılan ve parametrik istatistiklerin varsayımlarını (normallik, doğrusallık, varyansların homojenliği) gerektirmeyen bir teknik olup sınıflandırma işlemlerinde kullanılmaktadır. Diskriminant ve lojistik regresyon analizlerinin kullanıldığı birçok alan vardır; ancak eğitim alanında bu tekniklerle sınırlı sayıda uygulama yapılmıştır. Dolayısıyla bu çalışmada, bu iki tekniğin hem matematiksel hem de istatistiksel yönden detaylı açıklamaları yapılarak birbirlerine göre karşılaştırılmasının eğitim bilimlerinde bu analiz yöntemlerini kullanacak olan araştırmacılar için yararlı bilgiler sunacağı düşünülmektedir. Ayrıca ölçeklerin açımlayıcı faktör analizi ile kümeleme analizinin ve diskriminant analizi ile lojistik regresyon analizi tekniklerinin karşılaştırmaları yapılarak model karşılaştırmasına dayanan araştırmalara katkı getirebileceği düşünülmektedir.
Sınırlılıklar
1. Araştırma 2014-2015 eğitim-öğretim yılında Gazi Üniversitesi Gazi Eğitim
Fakültesinde 1.sınıf, 2.sınıf, 3.sınıf ve 4.sınıfta okuyan 671 öğrenci ile sınırlıdır.
2. Araştırma Pintrich, Smith, Garcia ve McKeachie’nin (1991) tarafından geliştirilen
ve Büyüköztürk, Akgün, Özkahveci ve Demirel (2004) tarafından Türkçeye uyarlaması yapılan Güdülenme ve Öğrenme Stratejileri Ölçeği (ÖGSÖ)’nin Güdülenme alt ölçeğindeki 31 madde ile sınırlıdır.
11
BÖLÜM II
KURAMSAL TEMELLER
Bu bölümde açımlayıcı faktör analizi, kümeleme, diskriminant ve lojistik regresyon analizleri ile güdülenme konularının kuramsal temellerine yer verilmiştir.
Açımlayıcı Faktör Analizi
Psikolojik özellikler, somut ve gözlenebilir olmaktan ziyade, soyut veya gizil olurlar. Bu gizil özelliklere yapı ya da faktör denir. (Kline, 2011). Açımlayıcı faktör analizi, bilinmeyen gizil değişkenlerle (faktörler) gözlenen değişkenler arasındaki ilişkileri ortaya çıkarmak amacıyla kullanılan bir analizdir. Araştırmacı açımlayıcı faktör analizi ile maddelerin (gözlenen değişkenlerin) ilgili faktörler altında çıkmasını ve bu maddelerin yüksek faktör yük değerlerine sahip olmasını ister. Araştırmacılar maddelerin gerçekten hangi faktör altında yer aldıkları konusunda fikir sahibi değilse bu analiz yöntemi keşfedici ya da açımlayıcı olarak tanımlanır (Byrne, 1994).
Faktör analizinde faktörleştirme yapılırken kovaryans veya korelasyon matrisi kullanılır. Dönüştürmede Xpxn ham veri matrisi için varyans-kovaryans matrisinden, Zpxn
standartlaştırılmış değerler matrisi için ise korelasyon matrisinden yararlanılır. Kovaryans veya korelasyon matrisinden hangisinin kullanılacağına karar vermek için verilerin ölçü birimleri ve varyansları dikkate alınır. Eğer ölçü birimleri ve varyansları birbirine yakınsa kovaryans matrisi, birbirlerine yakın değilse korelasyon matrisi kullanılır. Yapılan çalışmalarda genellikle Zpxn standart veri matrisi kullanılmaktadır (Korkmaz, 2000).
Açımlayıcı Faktör Analizine İlişkin Temel Kavramlar
12 Korelasyon Matrisi
Gözlenen değişkenlerden üretilen korelasyon matrisine gözlenen korelasyon matrisi, faktörler aracığıyla üretilen korelasyon matrisine ise üretilmiş korelasyon matrisi denir. Gözlenen ve üretilmiş korelasyon matrislerinin arasındaki fark ise, hata (artık) korelasyon matrisini oluşturmaktadır. İyi bir faktör analizinde, artık korelasyon matrisindeki korelasyon değerleri küçük, gözlenen ve yeniden üretilen matrisler arasındaki uyum ise yüksektir (Tabachnick ve Fidell 2013).
Öz Değer
Öz değer “tipik kök” ya da “gizil kök” olarak adlandırılır ve 𝝀 ile gösterilir. Öz değer, bir faktörle ilişkili olan p kadar orijinal değişken arasındaki ilişki katsayılarının yani her bir faktörün faktör yüklerinin kareleri toplamıdır. Öz değer her bir faktör tarafından açıklanan varyansın oranının hesaplanmasında ve önemli faktör sayısına karar vermede kullanılan bir katsayıdır. Öz değer yükseldikçe, faktörün açıkladığı varyans da yükselir (Tabachnick ve Fidell 2013). Faktör analizinde sadece öz değerleri bir ve birin üzerinde olan faktörler kararlı olarak kabul edilir (Köklü, 2002).
Açımlayıcı faktör analizinde, öz değerlerle ilgili dört kabul söz konusudur. Bu kabuller şu şekilde sıralanır:
1. Öz değerlerin sayısı, analiz edilen değişken ölçümlerin sayısına eşittir. 2. Öz değerlerin toplamı, değişken ölçümlerinin sayısına eşittir.
3. Her bir değişkene ait ölçümlerin sayısı tarafından bölünen öz değer, yeniden üretilen
bir faktörle analiz edilen ilişkiler matrisindeki bilgi oranını gösterir.
4. Her bir değişkene ait ölçümlerin sayısı tarafından bölünen seçilmiş faktörlerin öz
değerlerinin toplamı, yeniden üretilmiş bir set olarak analiz edilen matristeki bilgi oranını gösterir (Thompson’dan aktaran Çokluk vd., 2012).
Yamaç-Birikinti Grafiği (Scree Plot)
Yamaç-birikinti grafiği, faktör sayısına karar vermek amacıyla Cattell tarafından önerilen yardımcı bir grafiktir. Eğer öz değer bir veya birin üzerinde olursa faktörün kararlı olduğuna karar veriliyordu. Ancak yamaç-birikinti grafiği faktör sayısını öz değerlerden daha başarılı
13
bir biçimde azaltmaktadır. Yamaç-birikinti grafiği, baskın faktörleri ortaya koyarak faktör azaltmayı sağlayan bir grafiktir. Bu nedenle bu grafik, faktör analizinin temel amacına hizmet eder (Thompson, 2004).
Faktör Yük Değeri
Faktör yük değeri, maddelerin faktörlerle olan ilişkisini açıklamada kullanılan bir katsayıdır. Bir faktör altında yer alan maddelerin yer aldıkları faktördeki yük değerlerinin yüksek olması istenir. Bir faktörle yüksek düzeyde ilişkisi olan maddelerin oluşturduğu bir küme topluluğu varsa bu bulgu, o maddelerin birlikte bir kavramı (yapıyı, faktörü) ölçtüğü anlamına gelmektedir. Genel olarak, işaretine bakılmaksızın 0,60 ve üstü yük değeri yüksek; 0,30-0,59 arası yük değeri orta düzeyde faktör yük değeri olarak tanımlanır ve değişken çıkartmada bu değerler göz önünde bulundurulur (Kline, 2011). Alan yazında bir madde için en düşük faktör yük değeri 0,30 olarak kabul görürken, 0,40 olması gerektiğini savunan kuramcılarda mevcuttur. Ancak faktör yük değerinin büyüklüğüne karar verirken örneklem büyüklüğü de dikkate alınmalıdır (Şencan, 2005).
Ortak Faktör Varyansı, Varyans Oranı ve Kovaryans Oranları
Faktör analizinde varyansın açıklanmasında kullanılan üç tür varyans vardır. Bunlar ilki, ortak faktörler tarafından açıklanabilen varyans olan ortak faktör varyansı, ikinci olarak bir test ya da bir değişkende gözlenen varyansı tanımlayan özgül varyans, üçüncü olarak ise veri setine ilişkin varyansın açıklanamayan kısımını gösteren hata varyansıdır (Büyüköztürk, 2002). Ortak faktör varyansı, faktör analizi sonucunda faktörlerin her bir değişken üzerinde yol açtıkları ortak varyans olarak tanımlanır. Ayrıca, ortak faktör varyansı, bir maddenin veya değişkenin, faktör yüklerinin kareleri toplamı olarak da ifade edilebilir (Köklü, 2002). Varyans oranı, bir faktördeki maddelerin faktör yük değerleri kareleri toplamının, o faktördeki toplam madde sayısına bölünmesi ile elde edilen değerdir. Kovaryans oranı ise bir faktördeki maddelerin faktör yük değerlerinin kareleri toplamının, ortak faktör varyansları toplamına bölünmesi ile bulunur (Tabachnick ve Fidell 2013).
Analize dahil edilen değişkenlerle ilgili toplam varyansın 2/3 ‘ü kadar miktarının ilk olarak kapsadığı faktör sayısı, önemli faktör sayısı olarak değerlendirilir. Tek faktörlü desenlerde
14
açıklanan varyansın % 30 ve daha fazlası yeterli kabul edilmektedir. Çok fakörlü desenlerde ise açıklanan varyansın daha yüksek olması beklenir (Büyüköztürk, 2002).
Faktörleştirme
Faktör analizi, bir faktörleştirme ya da ortak faktör adı verilen yeni kavramları (değişkenleri) ortaya çıkarma ya da maddelerin faktör yük değerlerini kullanarak kavramların işlevsel tanımlarını elde etme süreci olarak tanımlanabilir. İyi bir faktörleştirmede ya da faktör çıkartmada, a) değişken azaltma olmalı, b) üretilen yeni değişken ya da faktörler arasında ilişkisizlik sağlanmalı ve c) ulaşılan sonuçlar, yani elde edilen faktörler anlamlı olmalıdır (Tabachnick ve Fidell 2013). Faktörleştirmede kullanılan pek çok teknik vardır. Bu teknikler arasında temel bileşenler analizi, temel faktörler analizi, maksimum olasılık faktör analizi, imaj faktör analizi, ağırlıklandırılmamış en küçük kareler analizi, temel eksenler analizi, maksimum olabilirlik ve çoklu gruplandırma teknikleri sayılabilir. Bu teknikler içerisinde en çok kullanılanları temel bileşenler ve temel faktörler analizleridir (Büyüköztürk, 2002). En çok kullanılan iki teknik olan temel bileşenler ve temel eksenler tekniklerine bu çalışmada yer verilmiştir.
Temel Bileşenler Tekniği
Temel bileşenler analizinin temel amacı fazla sayıdaki değişkeni, daha küçük sayıda bileşen altında azaltmaktır. Bu teknik, faktörler hakkında bilgi edinmek isteyen araştırmacılar içinde faktör analizindeki ilk adım olarak oldukça kullanışlı bir tekniktir. Eğer araştırmacı, ölçtüğü konunun temel boyutlarını ortaya çıkarmak istiyorsa, üzerinde çalıştığı veriler en az aralık ölçeğinde ise, verilerdeki hata varyansı düşükse ve asıl amacı bir ölçek geliştirmekse temel bileşenler analizi yöntemini kullanır. Temel bileşenler analizi ile ortaya çıkan faktörler arasında ilişki olması beklenmez, yani ortaya çıkan faktörler (yapılar) birbirinden bağımsızdır (Tabachnick ve Fidell 2013).
Temel Eksenler Tekniği
Temel eksenler tekniğinde de temel bileşenler analizinde olduğu gibi amaç her bir faktörle veri setinden azami dik açılı varyansı çıkartmaktır. Temel eksenler tekniğinin temel bileşenler analizinden farkı ise ortak faktör varyansını tekrarlı yöntemler aracılığıyla
15
bulmasıdır. Bu tekniğin avantajı ortak faktör varyansı, özgül ve hata varyansları çıkartılarak analiz yapılması nedeniyle bu teknik faktör analizi modeline uyar. Tekniğin dezavantajı ise bazen korelasyon matrisinin yeniden üretilmesi konusunda diğer faktörleştirme teknikleri kadar iyi olmamasıdır (Tabachnick ve Fidell 2013).
Temel bileşenler ve temel eksenler teknikleri arasında bazı önemli farklılıklar bulunmaktadır. Bunlardan birincisi, temel bileşenler tekniği, verilerin kovaryans matrisinin biçimi üzerinde herhangi bir varsayım yapılmaksızın verilerin dönüşümünü amaçlarken, temel eksenler analizinde verilerin tanımlanmış bir modele uyduğu varsayılmaktadır. Bu varsayımlar ortak ve artık faktörlerin bazı koşulları sağlama zorunluluğunu getirmekte, bu koşullar sağlanmadığında temel eksenler tekniği ile doğru sonuçlara ulaşılamamaktadır. İkinci olarak ise temel bileşenler tekniği, gözlenmiş değişkenlerden temel bileşenlere dönüşümü hedef alırken, temel eksenler analizinde belirlenmiş faktörlerden gözlenmiş değişkenlere dönüşüm öngörülmektedir (Tatlıdil, 2002).
Faktör Döndürme
Araştırmacılar, bir faktör analizi tekniğini kullanarak elde ettikleri m kadar önemli faktöre, "bağımsızlık, yorumlamada açıklık ve anlamlılık" sağlamak gibi amaçlar doğrultusunda eksen döndürmesi uygulayabilirler. Faktör döndürmesi sonrasında çözümün temel matematiksel özellikleri değişmez. Eksenlerin döndürülmesinden sonra maddelerin bir faktördeki yükü artarken diğer faktörlerdeki yük değerlerinde azalma olur. Bu şekilde faktörler, kendileri ile yüksek ilişkili maddeleri bulurlar ve faktörlerin yorumlanması daha kolay olur (Tabachnick ve Fidell 2013).
Faktör döndürme grafik ve geometrik döndürme tekniği ile analitik döndürme tekniği olmak üzere iki şekilde yapılmaktadır. Geometrik döndürme tekniği fazla zaman alan, objektif olmayan şansa bağlı sonuçlar vermesi nedeni ile önerilmemektedir. Analitik döndürme teknikleri ise dik ve eğik döndürme olmak üzere ikiye ayrılmaktadır. Faktörlerin açıkladıkları varyans miktarının döndürme işleminden etkilenmemesi istenir. Bu istek doğrultusunda dik döndürme teknikleri ön plana çıkmaktadır. Fakat bazı durumlarda dik döndürme yöntemleri en iyi faktör kümesine ulaşmakta yeterli olmamaktadır. Böyle durumlarda eğik döndürme teknikleri kullanılmaktadır (Brown, 2006). Döndürme işlemi olmaksızın faktörleştirme sonuçlarını yorumlamak büyük olasılıkla güç olacaktır.
16
Faktörleştirme işleminin ardından elde edilen çözümün yorumlanabilmesi ve bilimsel yararı geliştirmek için döndürme tekniklerinden faydalanılır (Tabachnick ve Fidell 2013).
Dik döndürme Teknikleri
Dik döndürme yöntemlerinde faktörler birbirleri ile ilişkisizdir ve faktörler eksenlerin konumu değiştirilmeksizin doksan derecelik açıyla döndürülürler. Elde edilen faktörlerin daha anlamlı sonuçlar vermesi için faktörlerden her seferinde iki tanesi sabit tutularak ikişer ikişer diklik özelliği bozulmayacak biçimde döndürülmesini sağlayan dik döndürme algoritmaları geliştirilmiştir. Dik döndürme tekniklerinden bazıları; quartimax, varimax, equamax’ dır (Büyüköztürk, 2015).
Quartimax: İki faktörlü yapıların olması durumunda en iyi sonucu veren yöntemlerin başında gelmektedir. Bu teknikte, her satırdaki herhangi bir değer büyütülüp 1’e yaklaştırılırken, öteki değerler küçültülerek 0’a yaklaştırılır.
Varimax: Bu yöntem genellikle çok faktörlü yapının söz konusu olduğu durumlarda kullanılmaktadır. Faktör yükleri matrisinin sütunlarına öncelik veren bu teknikte her sütundaki bazı yük değerleri 1’e yaklaştırılırken, geriye kalan çok sayıda değeri 0’a yaklaştırır. Bu yöntemde de diğer yöntemlere olduğu gibi daha iyi yorum yapılabilmesi için faktör varyanslarının maksimum olmasını sağlayacak biçimde döndürme yapılmaktadır.
Equamax: Faktörleri ve değişkenleri basitleştirmek için eş zamanlı olarak çalışan bir yöntem olan equamax, varimax ve quartimax yöntemlerinin bir karışımıdır.
( Tabachnick ve Fidell 2013).
Eğik Döndürme Teknikleri
Eğik döndürme yönteminde her faktör birbirinden bağımsız olarak döndürülür. Ayrıca bu yöntemde eksenlerin birbirine dik olması gerekmez. Araştırmacılar faktörler arasında bir ilişki olduğunu düşünüyorlarsa eğik döndürme yöntemlerini kullanırlar. Yapılan döndürme sonrasında değişkenlerle ilgili açıklanan toplam varyans değişmezken, her bir faktörün açıkladığı varyans miktarları değişir. Eğik döndürme yöntemleri olarak sıkça kullanılan teknikler Direct Oblimin ve Promax’tır (Büyüköztürk, 2015).
17
Direct Oblimin: Bu yöntemde eksenler doksan derecenin dışındaki herhangi bir açıyla döndürülürler. Faktörlerin kendi aralarındaki ilişkili olma derecesi bir delta değeri ile hesaplanmaya çalışılır. Delta sıfır veya negatif işaretli bir değerdir. Sıfır değeri, en yüksek derecede birbirleri ile ilişkili faktörleri ortaya çıkarırken, büyük negatif değerler ise dik açılı döndürmeye yakın değerler verir (Şencan, 2005). Promax: Eğik döndürme yöntemleri arasında hızlı ve ekonomik olması açısından iyi
bir seçenektir. Bu teknikte, genellikle 2, 4 veya 6 olarak tanımlanan bir kappa değeri hesaplanır. Promax döndürme yöntemini kontrol eden kappa değerinin 4 olması halinde, çözüm için en iyi çözüm olduğu ifade edilir (Tabachnick ve Fidell 2013).
Sayıltılar ve Analizin Diğer Gereklilikleri
Açımlayıcı faktör analizine başlamadan önce, bazı temel kavramların araştırmacı tarafından test edilmesi gerekmektedir. Örneklem büyüklüğü, kayıp değerler, normallik, doğrusallık, çoklubağlantı ve tekillik ile uç değerler kavramlarının araştırmacı tarafından incelenmesi gerekmektedir.
Örneklem Büyüklüğü
Faktör analizinde yeterli görülen örneklem büyüklüğü en az 300 olarak görülmektedir. Fakat yüksek faktör yük değerleri elde etmek için 150 civarında da örneklem büyüklüğünün yeterli olduğu kabul edilmektedir. Örneklem büyüklüğü, araştırmacının elindeki madde veya faktör sayısı gibi ölçütlere dayalı olarak da tahmin edilmektedir (Tabachnick ve Fidell 2013). Faktör analizinde örneklem büyüklüğü açısından veri yapısının uygunluğunu test etmek için Kaiser-Meyer-Olkin testi kullanılmaktadır. Bu test, gözlenen korelasyon katsayılarının büyüklüğü ile kısmi korelasyon katsayılarının büyüklüğünü karşılaştırmayı sağlayan bir testtir. Kaiser- Meyer-Olkin testi sonucunda, elde edilen değerin 0,50’den düşük olması halinde analize devam edilemeyeceği belirtilmektedir. Örneklem büyüklüğü için 0,60 değeri yeterli görülen değer olarak kabul edilirken 0,90 ve üzeri değerlerin “mükemmel” olduğu yorumu yapılmaktadır (Tavşancıl, 2005).
18 Kayıp Değerler
Açımlayıcı faktör analizinde, değişkenler arasındaki korelasyon matrisi baz alınarak yapıldığından, veri yapısındaki kayıp değerlerin kontrol edilmesi gerekmektedir. Kayıp değerler için önerilen çözüm yoları şunlardır. Birincisi kayıp değerlerin tahmin edilmesidir. İkinci olarak kayıp değerlerin bulunduğu satırların silinmesi yoludur. Son olarak ise kayıp veri matrisinin hesaplanması yoludur (Tabachnick ve Fidell 2013).
Normallik
Çok değişkenli normallik, tüm değişkenlerin ve değişkenlerin tüm doğrusal kombinasyonlarının normal olarak dağılması sayıltısıdır. Açımlayıcı faktör analizinde verilerin çok değişkenli normal dağılımdan geldiği “Barlett Küresellik Testi” ile test edilir. Barlett Küresellik testi sonucu ne kadar yüksek ise manidar olma olasılığı da o kadar yüksektir. Barlett küresellik testide bir ki-kare testidir. Bu nedenle, bu testte de diğer ki-kare testlerinde olduğu gibi anlamlılık değerine bakılır ve anlamlılık değeri 0,05’ten küçük ise R korelasyon veya kovaryans matrisindeki birim matrisi (herhangi bir matriste köşegendeki rakamların dışındaki tüm değerlerin sıfır olması)’ndan farklı olduğu sonucuna varılır. Bu durumda korelasyon matrisinden faktör çıkarılabileceği sonucu çıkar, eğer anlamlılık değeri 0,05’ten büyük olursa “matriste paylaşılan varyans olmadığı” yorumu yapılır ve faktör analizi yapılamaz (Şencan, 2005).
Çok değişkenli normallik testi, oldukça duyarlı olmasına rağmen tek değişkenler arasındaki normallik “Çarpıklık/ Kayışlılık”ve “Basıklık” katsayıları ile test edilmektedir. Çarpıklık, örneklem verilerinin dağılımındaki asimetriklik olarak tanımlanır. Çarpıklık katsayısı bir dağılımda, normal dağılımdan uzaklaşmanın derecesini göstermektedir Basıklık katsayısı ise bir dağılımın sivriliğinin ya da basıklığının derecesidir (Kurtz, 1999).
Doğrusallık
Doğrusallık iki değişken arasındaki ilişkinin doğru/düz olmasıdır. İki değişken arasında doğrusal bir ilişkinin varlığı, doğrusal korelasyon katsayısı (r) ile hesaplanmaktadır. Çok değişkenli normallik sayıltısı değişken çiftleri arasındaki ilişkilerin doğrusal olduğunu
19
göstermektedir. Saçılma diyagramları değişken çiftleri arasındaki doğrusallığı değerlendirmede kullanılmaktadır (Büyüköztürk, 2002).
Çoklu Bağlantı
Çoklu bağlantı sorunu değişkenlerin ikişerli olarak birbirleriyle yüksek derecede ilişkili olması durumudur. Çoklu bağlantıda iki değişkenin birbirine benzerlik kriteri 0,90 olarak belirlenmiştir. Yani iki değişken arasındaki korelasyon 0,90’dan büyük olursa çoklu bağlantı problemi ortaya çıkmaktadır. Çoklu bağlantı problemi, değişkenlerin özgün katkılarının ya da etkilerinin ayırt edilmesini güçleştirir, bu da yanlış yorumlamalara ve sonuç çıkartmalara yol açabilir. (Şencan, 2005).
Uç Değerler
Veri setinde araştırmacı tarafından kontrol altına alınamayan, başka değişkenler tarafından üretilen beklenmedik gözlemler oluşabilir. Bu beklenmedik gözlemler ve aşırı değerler çok değişkenli veri setlerinde oldukça karmaşık olabilmektedir. Veri setlerinde beklenmedik gözlemler ve aşırı değerler uç değerler olarak adlandırılmaktadır (Schumacker ve Lomax, 1996).
Bir veri setinde aşırı uç değerler olması, bu gözlemlerin farklı bir örneklemden gelebileceği veya aynı örneklemden toplanan veriler içinde aşırı uç durumlar olabileceği olasılığıdır. Veri setindeki uç değerle, çok fazla veri kaybına neden olabilir, bu ise analizin yapılması açısından araştırmacıya bir problem oluşturmaktadır (Kline, 2011). Uç değerler tek değişkenli ve çok değişkenli olmak üzere ikiye ayrılmaktadır. Tek değişkenli uç değerler, tek bir değişken için beklenmeyen satırlardır. Tek değişkenli uç değerleri bulmak için işlem toplam puan üzerinden yapılır ve mahalonobis uzaklığı hesaplanarak bulunur. Regresyon analizinde uç değerlerin olup olmadıklarını anlamada kullanılan mahalonobis uzaklığı bağımsız değişkenin uzayındaki merkezden veya örneklem ortalamasından tek bir veri uzaklığını ölçen bir istatistiktir. Çok değişkenli uç değerler ise değişken sayısı için beklenmedik kombinasyonlara sahip satırlardır. Çok değişkenli uç değerler belirlenirken madde puanları standart puanlara (z puanlarına) dönüştürülerek -3 ve +3 ün dışında kalan değerler çok değişkenli uç değerler olarak değerlendirilir ve analiz dışı bırakılır (Tabachnick
20
ve Fidell 2013). Tüm bu sayıltılar ve gereklilikler sağlandıktan sonra faktör analizine geçilebilir.
Kümeleme Analizi
Dünya var olduğundan günümüze kadar insanlar çevrelerinde bulunan nesneleri, eşyaları, v.b gruplara ayırmaya çalışmıştır. Örneğin bitkileri yenilir yenmez diye ilkel çağlarda sınıflayan insanoğlu, ilerleyen zamanlarda gruplandırmanın amacını ve kapsamını değiştirerek kullanmıştır. Gruplandırmadaki en temel amaç birbirine benzer olanları birleştirmektir (Everitt ve Dunn, 2010). Birimlerin sayısı arttıkça onları sınıflara ayırmak git gide zorlaşmış, bu nedenle sınıflandırma yapmak için yeni yöntemler geliştirilmiştir. Bu yöntemlerden biride kümeleme analizidir. Kümeleme analizinin başlangıcı, 1753 yılında Linnaeus’ un hayvanlar ve bitkiler üzerinde yaptığı sınıflandırmaya dayanmaktadır.
Kümeleme analizi 20. yüzyılda gelişim göstermesine rağmen onunla ilgili bilgiler son yıllarda elde edilmiştir. Kümeleme analizinin gelişim göstermesindeki önemli çalışmalardan birisi Robert Sokal ve Peter Sneath adlı iki biyolog tarafından 1963 yılında yayımlanan ‘Principles of Numerical Taxonomy’ adlı kitap olmuştur. İki biyolog biyolojik sınıflandırmaların yapılması için etkili yöntemler araştırmışlardır. Bunun için organizmalar arasındaki benzerlik derecelerini ortaya koymaya çalışmışlardır ve kümeleme analizinin kullanımı ile nispeten benzer organizmalar aynı gruplara yerleştirilmiştir. Kümeleme analizine olan yoğun ilgi bu çalışmadan sonra olmuştur. 1963 ile 1975 yılları arasında kümeleme analizi ile ilgili çalışma sayısı katlanarak artmıştır. Bilgisayar teknolojisindeki büyük gelişmelerle birlikte kümeleme analizi yöntemlerinde ve uygulanabilirlik alanlarında çeşitlilik artmıştır (Aldenderfer ve Blashfield, 1984).
Kümeleme analizi başta tıp, biyoloji, psikoloji, sosyoloji, eğitim bilimleri olmak üzere hemen hemen tüm bilim alanlarında kullanılan çok değişkenli istatiksel bir analiz tekniğidir. Tıp alanında çeşitli hastalıkların sınıflandırılması, hastalıklara ya da semptomlara göre uygulanabilecek olan tedavilerin sınıflandırılması gibi amaçlarla kullanılırken; eğitim bilimleri alanında eğitim programları geliştirmek ve örnek öğrenme kalıpları oluşturmak gibi amaçlarla kullanılmaktadır. Kümeleme analizi kendi içerisinde popüler bir alan olmasına rağmen, özellikle eğitim ve sosyal bilimlerde; faktör analizi, diskriminant analizi, çok
21
boyutlu ölçekleme gibi yöntemlere nazaran çok bilinen bir yöntem değildir (Aldenderfer ve Blashfield 1984).
Kümeleme analizi; birimleri veya nesneleri, p sayıda değişkene göre hesaplanan ve benzerlik ölçüsü olarak da bazı ölçülerin kullanıldığı homojen sınıflara bölmek amacıyla kullanılmaktadır. Kümeleme analizi, birimleri dört değişik amaca yönelik olarak sınıflara ayıran bir yöntemdir:
n sayıdaki birimi, nesneyi, p sayıdaki değişkene göre belirlenmiş özelliklerine göre mümkün olduğunca kendi içinde türdeş (homojen) ve kendi aralarında ise farklı (heterojen) alt sınıflara (kümelere) bölmek için,
p sayıda değişkeni, n sayıdaki birimde belirlenmiş olan değerlere göre birimlerin ortak özelliklerini açıkladığı varsayılan alt kümelere ayırmak ve ortak özelliklerini ortaya koymak,
Hem birimleri hem de değişkenleri beraber ele alarak ortak n birimi p değişkene göre ortak özelliklere sahip olan alt kümelere ayırmak,
Birimleri, p değişkene göre belirlenmiş olan değerlere göre izledikleri biyolojik ve tipolojik sınıflamayı ortaya koymak için kullanılan bir yöntemdir (Everitt ve Dunn 2010).
Kümeleme analizinde kullanılan pek çok uzaklık ölçüsü ve bu ölçüler üzerinde kurulmuş pek çok yöntem bulunmaktadır. Seçilen uzaklık ölçülerine ve seçilen yöntemlere bağlı olarak kümeleme analizi sonuçları çok farklı çıkabilmekte ve araştırmacıyı kararsızlığa götürmektedir. Bu nedenle son yıllarda çok kullanılan bir yol kümeleme analizinde temel bileşenlerden yararlanılmasıdır. Bu yolla hem değişken sayısı azaltılmakta hem de özellikle ilk iki temel bileşen üzerindeki gözlem sonuçlarının çiziminden ayrıntılı bilgi çıkarmak mümkün olabilmektedir ( Hair vd., 2006).
Kümeleme analizinde gözlemlerin gruplanması için için geliştirilen bazı yöntemlerde kümeleme, tüm gözlem çiftleri arasındaki benzerliklerin bulunmasıyla başlar. Bazı durumlarda benzerlikler, uzaklık ölçümlerine dayalı olarak bulunur. Diğer kümeleme yöntemlerinde, küme merkezlerinin seçimi veya küme içi ve kümeler arası değişimin karşılaştırılması yapılır. Değişkenlerin de kümelenmesi mümkündür. Bu durumda benzerlik için korelasyon kullanılır (Galimberti ve Soffritti, 2007).