COGNITIVE DIAGNOSTIC ASSESSMENT OF SECOND LANGUAGE READING COMPREHENSION: APPLICATION OF THE LOG-LINEAR
COGNITIVE DIAGNOSIS MODELING TO LANGUAGE TESTING
TUĞBA ELİF TOPRAK
DOCTORAL DISSERTATION
DEPARTMENT OF FOREIGN LANGUAGE TEACHING
GAZİ UNIVERSITY
GRADUATE SCHOOL OF EDUCATIONAL SCIENCES
i
TELİF HAKKI ve TEZ FOTOKOPİ İZİN FORMU
Bu tezin tüm hakları saklıdır. Kaynak göstermek koşuluyla tezin teslim tarihinden itibaren ...(….) ay sonra tezden fotokopi çekilebilir.
YAZARIN Adı : Tuğba Elif Soyadı : TOPRAK
Bölümü : İngilizce Öğretmenliği İmza :
Teslim tarihi :
TEZİN
Türkçe Adı: İkinci Dilde Okuduğunu Anlama Becerisinin Bilişsel Tanılayıcı Değerlendirmesi: Log-Lineer Bilişsel Tanılayıcı Modelin Dilde Ölçme-Değerlendirmeye Uygulanması
İngilizce Adı: Cognitive Diagnostic Assessment of Second Language Reading Comprehension: Application of the Log-Linear Cognitive Diagnosis Modeling to Language Testing
ii
ETİK İLKELERE UYGUNLUK BEYANI
Tez yazma sürecinde bilimsel ve etik ilkelere uyduğumu, yararlandığım tüm kaynakları kaynak gösterme ilkelerine uygun olarak kaynakçada belirttiğimi ve bu bölümler dışındaki tüm ifadelerin şahsıma ait olduğunu beyan ederim.
Yazar Adı Soyadı: Tuğba Elif TOPRAK İmza:
iii Jüri onay sayfası
Tuğba Elif TOPRAK tarafından hazırlanan “Cognitive Diagnostic Assessment of Second Language Reading Comprehension: Application of the Log-Linear Cognitive Diagnosis Modeling to Language Testing” adlı tez çalışması aşağıdaki jüri tarafından oy birliği / oy çokluğu ile Gazi Üniversitesi Yabancı Diller Eğitimi Anabilim Dalı’nda Doktora tezi olarak kabul edilmiştir.
Danışman: Prof. Dr. Abdulvahit ÇAKIR
İngiliz Dili Eğitimi Anabilim Dalı, Gazi Üniversitesi ………
Başkan: Doç. Dr. Paşa Tevfik CEPHE
İngiliz Dili Eğitimi Anabilim Dalı, Gazi Üniversitesi .…….…………....
Üye: Doç. Dr. Nurdan ÖZBEK GÜRBÜZ
İngiliz Dili Eğitimi Anabilim Dalı, Orta Doğu Teknik Üniversitesi ..………...
Üye: Yrd. Doç. Dr. Cemal ÇAKIR İngiliz Dili Eğitimi Anabilim Dalı, Gazi Üniversitesi ………
Üye: Yrd. Doç. Dr. Neslihan ÖZKAN İngiliz Dili Eğitimi Anabilim Dalı, Ufuk Üniversitesi ………...
Tez Savunma Tarihi: …../…../……….
Bu tezin Yabancı Diller Eğitimi Anabilim Dalı’nda Doktora tezi olması için şartları yerine getirdiğini onaylıyorum.
Eğitim Bilimleri Enstitüsü Müdürü
iv
ACKNOWLEDGEMENTS
My graduate life has been rewarding and gratifying thanks to many wonderful people around me. First of all, I am greatly indebted to my thesis supervisor and department head Prof.Dr. Abdülvahit Çakır for his enourmous support, encouragement and guidance for the past four years. Throughout my graduate life, he has been encouraging me to take every opportunity that would make me a better researcher. I always appreciate his confidence in me and what I am capable of accomplishing. I would like to offer my sincerest gratitude to Asst.Prof. Dr. Laine Bradshaw for her support and guidance during my journey of learning “how to catch fish”. I appreciate the genuine interest and excitement that she showed for my thesis work and the opportunity she provided me to study at the University of Georgia to hone my skills and knowledge about cognitive diagnostic assessment. Words cannot describe well enough my appreciation and gratitude to Assoc.Prof. Dr. Paşa Tevfik Cephe. I always benefited from challenging and illuminating discussions with him and deep insights that he provided me with on many issues. It has been an honor and pleasure to work with him on several projects. I am especially grateful to Assoc.Prof.Dr. Kemal Sinan Özmen for his encouraging and insightful comments on critical reading and reading cultures which helped me widen my horizon. Many heartful thanks would go to my thesis committee members Assoc.Prof.Dr. Nurdan Özbek Gürbüz, Asst.Prof.Dr. Cemal Çakır and Asst.Prof.Dr. Neslihan Özkan for their constructive comments and insights. This thesis would not have come out as it is without their scholarly contributions.
I cannot thank enough my dear friends and colleagues Betül Kınık, Sibel Kahraman, Sinem Hergüner, Tuğba Taflı, Yasemin Aksoyalp and Zeynep Köroğlu for their moral, spiritual and academic support. Their friendship and support meant so much to me. Thanks an ocean! Heartfelt thanks go to my dear friend Sophia Jeong, for always standing with me and giving me unselfish support. Many thanks would go to a dear friend and avid researcher, Dr. Vahid Aryadoust, for his insightful suggestions about my study and for his encouragement. Words cannot sufficiently express my gratitude to my dear friend Şafak
v
Müjdeci for everything she has done for me and for all the things we have shared since the day we met.
While I was working on this study, I received a PhD research scholarship from TÜBİTAK (The Scientific and Technological Research Council of Turkey). I am appreciative of TÜBİTAK Scientist Support Directorate’s (BİDEB) financial support. I am also grateful for the financial support by YÖK (Turkish Higher Education Council) which enabled me to continue my studies at Quantitative Methodology Department of University of Georgia, USA.
Last, but certainly not least, my deepest thanks go to my beloved family for their unwavering support, encouragement, patience, faith, understanding, and most importantly for their love. They are wonders of my life, no matter how many kilometers we are away from each other. The most important thing that has kept me working as hard as I could has been the faith that my family has in me.
vi
İKİNCİ DİLDE OKUDUĞUNU ANLAMA BECERİSİNİN BİLİŞSEL
TANILAYICI DEĞERLENDİRMESİ: LOG-LINEER BİLİŞSEL
TANILAYICI MODELİN DİLDE ÖLÇME-DEĞERLENDİRMEYE
UYGULANMASI
(Doktora Tezi)
Tuğba Elif Toprak
GAZİ ÜNİVERSİTESİ
EĞİTİM BİLİMLERİ ENSTİTÜSÜ
Kasım 2015
ÖZ
Bu çalışmada tanılayıcı sınıflandırma modelleme yaklaşımı çerçevesinde ikinci dilde okuduğunu anlama becerisine yönelik çok boyutlu bir bilişsel tanılayıcı test geliştirilmesi amaçlanmıştır. Tanılayıcı sınıflandırma modelleme yaklaşımı henüz gelişme aşamasında olsa da, istatistiki açıdan ileri ve karmaşık olan bu modelleme eğitimde ölçme ve değerlendirmede paydaşlara sunulacak tanılayıcı dönütün kalitesini artırmak için büyük umut vadetmektedir. Retrofitting adı verilen yeterlik sınav sonuçlarının tanılayıcı sınıflandırma modellemede kullanıldığı uygulamalarda ciddi sorunlarla karşılaşılmaktadır. İlgili literatürde de bu sıkıntılara sıklıkla değinildiğinden ötürü, bu çalışma tanılayıcı sınıflandırma modelleme kapsamında kullanılmak üzere ikinci dilde okuduğunu anlama becerisini ölçmeye yönelik bilişsel bir tanılayıcı test geliştirmeyi ve bu test sonuçlarını Log-lineer Bilişsel Tanılayıcı Modelleme adı verilen genel bir bilişsel sınıflandırma modeliyle analiz etmeyi amaçlamaktadır. Daha özele indirgemek gerekirse, bu çalışmada ikinci dilde okuduğunu anlama becerisine yönelik geliştirilecek bir bilişsel modelin ölçme değerlendirme faaliyetlerini ve bu faaliyetlerden elde edilecek çıkarımları ne derece
vii
etkilediği; geliştirilen bilişsel tanılayıcı testin (the CDSLRC test) amacına ne kadar hizmet ettiği, Log-lineer Bilişsel Tanılayıcı Modellemenin beceri profillerini ne kadar iyi belirleyebildiği ve ulaşılan beceri profili ve alt becerilerin hangi özellikleri taşıdığı gibi soruları cevaplamayı amaçlamıştır. Bunun yanı sıra, söz konusu çalışmada, simülasyon çalışmalarının aksine gerçek veriler üzerinde çalışma imkanı olmasından dolayı bu çalışma tanılayıcı sınıflandırma modelleme yaklaşımının gerçek uygulamalardaki uygunluğunu sergileyerek eğitimde ve yabancı dilde ölçme değerlendirme alanlarına katkıda bulunmayı amaçlamıştır. Log-lineer Bilişsel Tanılayıcı Modelleme yaklaşımından daha iyi yararlanabilmek ve retrofitting yaklaşımının sıkıntılarını bertaraf etmek için bu çalışmada öncelikli olarak ikinci dilde okuduğunu anlama becerisine yönelik bir bilişsel model geliştirilmiştir. Bu modelin geliştirilmesi için ana dil ve ikinci dilde okumaya yönelik teorik modeller ve literatürün sunduğu ampirik araştırma sonuçları incelenmiştir. Bunun yanı sıra dil kullanım alanı incelenmiş, İngiliz Dili Eğitimi bölümünde çalışan akademisyenlerle mülakatlar gerçekleştirilmiş, çalışmaya katılan 150 öğrencinin ileri okuma dersindeki vize ve final kağıtları incelenmiş ve katılımcılara okuma becerisine yönelik bir öz-değerlendirme anketi sunulmuştur. Bu aşamaların neticesinde bilişsel model geliştirilmiş ve bu modele bağlı olarak ortaya çıkan bilişsel tanılayıcı test (the CDSLRC test) Türkiye’de orta ve büyük ölçekli dokuz devlet üniversitesinin İngiliz Dili Eğitimi anabilim dalında eğitim gören 1058 katılımcıya uygulanmıştır. Analizler, model ve veri arasındaki uyumun ve testteki maddelerin kalitesinin oldukça iyi olduğunu ortaya koymuştur. İstatistiki kanıtlar test maddelerinin amaçlarına hizmet ettiklerini ve ölçmeyi amaçladıkları hedefleri ölçtüklerini sergilemiştir. Ayrıca Log-lineer Bilişsel Tanılayıcı Modellemenin uygulanması sonucu elde edilen beceri sınıflandırmalarının güvenirliklerinin son derece yüksek olduğu saptanmıştır. Bunlara ek olarak bu çalışmada sesli düşünme protokolleri katılımcıların okuma süresince yürüttükleri bilişsel süreçleri anlayabilmek ve bilişsel tanılayıcı testin uygulanması sonucunda edinilen çıkarımların geçerliğini sağlamak için kullanılmıştır. Testten alınan puanlara göre, en yüksek ve en düşük performans gösteren gruplardan rastgele seçilen 15 katılımcı bu protokollere katılmak için davet edilmişlerdir. Sesli düşünme protokollerinden elde edilen veriler hem testin hem de testten elde edilen çıkarımların geçerliğini saptamaya yardımcı olmuş ve ilaveten sıra okuduğunu anlama becerisi açısından iyi ve yetersiz katılımcılar arasındaki farkları saptamayı sağlamıştır. Özetlemek gerekirse, çalışmanın bulguları ölçülen beceriye dair güçlü bir teorik altyapı ile iyi bir test dizaynının bir araya gelmesi sonucunda, bilişsel tanılayıcı bir testin geliştirilmesinin ve Log-lineer Bilişsel Tanılayıcı Modelleme yaklaşımının katılımcılar hakkında pedagojik olarak yararlı ve güvenilir bilgi edinmek amacıyla kullanılmasının mümkün olduğunu göstermiştir.
Bilim Kodu :
Anahtar Kelimeler : tanılayıcı sınıflandırma modelleme, Log-lineer Bilişsel Tanılayıcı Modelleme, ikinci dilde okuduğunu anlama becerisi, yabancı dilde ölçme ve değerlendirme Sayfa Adedi : xvi + 185 sayfa
viii
COGNITIVE DIAGNOSTIC ASSESSMENT OF SECOND
LANGUAGE READING COMPREHENSION: APPLICATION OF
THE LOG-LINEAR COGNITIVE DIAGNOSIS MODELING TO
LANGUAGE TESTING
(Ph.D Dissertation)
Tuğba Elif Toprak
GAZI UNIVERSITY
GRADUATE SCHOOL OF EDUCATIONAL SCIENCES
November 2015
ABSTRACT
This study aimed to create a multidimensional cognitive diagnostic second language reading comprehension test (the CDSLRC test) within the framework of cognitive diagnostic modeling (DCM). Although the domain of cognitive diagnostic modeling is still in its infancy, DCMs, which are statistically sophisticated tools, hold great promise for improving the quality of diagnostic feedback provided to stakeholders in educational assessment. Since the limitations of retrofitting a proficiency test to a DCM are well-reported in the relevant literature, the present study was conducted to generate a cognitive diagnostic test from ground up and apply a DCM (the Log-linear cognitive diagnosis modeling) to the test data. Specifically, the present study attempted to investigate what kind of impacts would a cognitive model of second language reading exert on assessment process itself and the interpretations arising from an assessment; how well the CDSLR test served its purpose; how well the LCDM estimated skill profiles; and, what characteristics
ix
of skill profiles and attributes were captured by the LCDM. Moreover, it aimed to contribute to the fields of educational measurement and language testing by complementing simulation-based studies on DCMs and manifesting the feasibility and applicability of DCMs for operational use. To make use of the Log Linear Cognitive Diagnosis Modeling Framework and to eliminate the limitations of retrofitting, initially a cognitive model guiding the whole process and forming the foundation of the CDSLRC test was generated. The cognitive model utilized in the study was generated through a detailed review of the theoretical reading models in the first and second language and empirical research findings in the relevant areas, conducting a target language use (TLU) domain analysis, carrying out interviews with the faculty working at the English Language Teaching Department, examining a set of 150 examinees’ mid-term and final exam papers in an advanced reading course and administrating a self-assessment questionnaire to the examinees. After generating a cognitive model of second language reading comprehension and developing the CDSLRC test in a series of steps, the CDSLRC test was administrated to 1058 examinees studying at the English Language Teaching Departments of nine large and mid-sized state universities in Turkey. Given second language reading comprehension is very crucial for academic success in higher education environment, investigating the skill profiles of examinees and presenting them with pedagogically meaningful and fine-grained feedback would be highly beneficial. The results revealed that there was a good fit of the model to the data, and the items on the CDSLRC test were of good quality. Statistical evidence demonstrated that the items on the CDSLRC test measured the attributes they targeted and the mastery classification reliabilities were extremely high. In the present study, think-aloud protocols were carried out to gain insights into the examinees’ cognitive processes in reading and to validate the interpretations arising from their scores on the CDSLRC test. Fifteen students randomly selected from upper and lower performing groups on the CDSLR test were invited to think-aloud while they were reading the texts that were used in CDSLR test. Think-aloud data were very helpful both in validating the test itself and the interpretations arising from the test as well as in helping the researcher spot the differences between skilled and less skilled readers. Overall, the findings demonstrated that, by coupling a strong understanding of the construct at hand with an informed test design, it was possible to develop a cognitive diagnostic second language reading comprehension test and use the LCDM to gather diagnostically useful and reliable interpretations of examinees’ second language reading comprehension abilities.
Science Code :
Key Words : diagnostic classification modeling, the Log-linear Cognitive Diagnosis Modeling, second language reading comprehension, language testing and assessment Page Number : xvi + 185 pages
x
TABLE OF CONTENTS
TELİF HAKKI ve TEZ FOTOKOPİ İZİN FORMU ... i
ETİK İLKELERE UYGUNLUK BEYANI... ii
Jüri onay sayfası ... iii
ACKNOWLEDGEMENTS ... iv
ÖZ ... vi
ABSTRACT ... viii
TABLE OF CONTENTS ... x
LIST OF TABLES ... xiv
LIST OF FIGURES ... xv
LIST OF ABBREVIATIONS ... xvi
CHAPTER I ... 1
INTRODUCTION ... 1
Cognitive Diagnostic Assessment... 4
Diagnostic Classification Models ... 5
Log-Linear Cognitive Diagnosis Modeling Framework... 9
DCMs in Language Assessment ... 10
Assessment of Reading Comprehension ... 11
xi
CHAPTER II ... 15
LITERATURE REVIEW ... 15
The nature of reading ... 15
Approaches to reading ... 19
Models of reading ... 21
Links between L1 reading, L2 reading and L2 proficiency ... 25
DCM applications to reading research ... 27
The construct of reading comprehension ... 29
Operationalization of the second language reading comprehension construct in the present study ... 31
CHAPTER III ... 43
METHODOLOGY ... 43
The Research Context and Sample ... 43
The Sample ... 43
The Tools ... 45
The Cognitive Diagnostic Second Language Reading Comprehension Test ... 45
Self- report Questionnaire ... 46
Think-Aloud Verbal Protocols and Follow-up Interviews ... 46
Generating a Cognitive Model of Second Language Reading Comprehension ... 47
Step 1. A Detailed Review of Literature on Reading ... 49
Step 2. Examining and Understanding Target Language Use (TLU) Domain to Reinforce Context Validity ... 59
Step 3. Conducting Interviews with the Faculty Working at the Department ... 59
Step 4. Product Examination... 60
xii
Construction of the CDSLRC (Cognitive Diagnostic Second Language Reading
Comprehension) Test ... 62
The Log-linear Cognitive Diagnosis Modeling Framework (LCDM) ... 63
Software ... 66
CHAPTER IV ... 67
RESULTS ... 67
Results Pertaining to the Application of the LCDM on CDSLRC Test Data ... 67
Model Specifications and the Estimation of the Structural Model ... 69
Item Parameters Estimates of the CDSLRC Test ... 69
Final LCDM Specification ... 74
Attribute Classifications... 75
Diagnostic Score Reporting ... 76
Attribute Reliability ... 80
Model Fit ... 80
Results Pertaining to the Application of the Think-aloud Protocols and Follow-up Interviews ... 81
CHAPTER V ... 89
DISCUSSIONS ... 89
Research Question 1: How Could a Cognitive Model of Second Language Reading Comprehension Impact Assessment Process Itself and the Interpretations Arising from an Assessment? ... 89
Research Question 2: How Well Does the Cognitive Diagnostic Second Language Reading Comprehension Test (CDSLRC Test) That Was Developed within the Scope of This Study Determine Skill Profiles? ... 92
Research Question 3: How Well Does the LCDM Estimate Second Language Reading Comprehension Skill Profiles? ... 95
xiii
Research Question 4: What Are the Characteristics of the Skill Profiles Estimated by the
LCDM? ... 97
CHAPTER VI ... 101
CONCLUSIONS... 101
REFERENCES ... 109
APPENDICES ... 126
Appendix 1. The CDSLRC Test ... 127
Appendix 2. A Coh-Metrix Sample Analysis ... 136
Appendix 3. Self-report Questionnaire (Turkish version) ... 142
Appendix 4. Self-report Questionnaire (English version) ... 143
xiv
LIST OF TABLES
Table 1. An Overview of the Research Process ... 44
Table 2. The Development of Cognitive Model on Second Language Reading Comprehension ... 48
Table 3. Theoretical Models of Reading and Their Implications for the Present Study ... 50
Table 4. Recurrent Attributes in Reading Literature ... 57
Table 5. The CDSLRC Test Attribute to Item Q-matrix ... 68
Table 6. Item Parameter Estimates ... 71
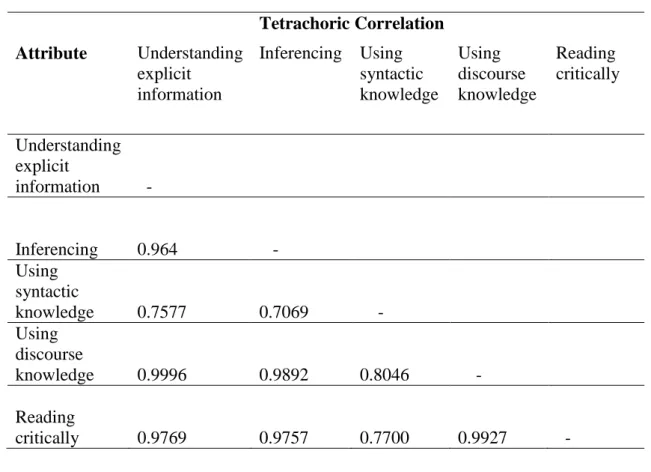
Table 7. Tetrachoric Correlations among the Attributes ... 75
Table 8. Final Class Counts and Proportions for the Latent Classes Based on the Estimated Model ... 76
xv
LIST OF FIGURES
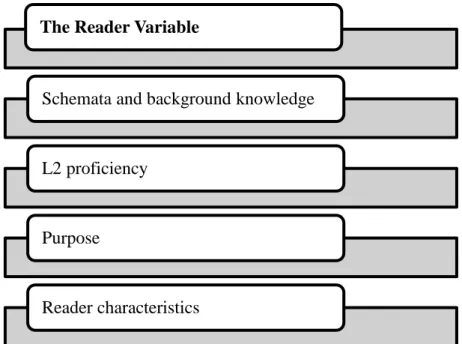
Figure 1. The reader variable ... 33
Figure 2. The text variable ... 36
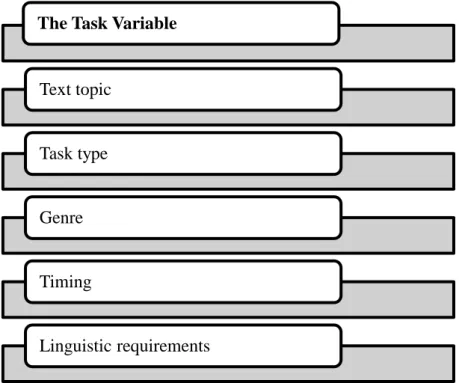
Figure 3. The task variable... 37
Figure 4. Contextual model depicting the variables affecting reading comprehension process... 54
Figure 5. Attributes measured by the CDSLRC test ... 61
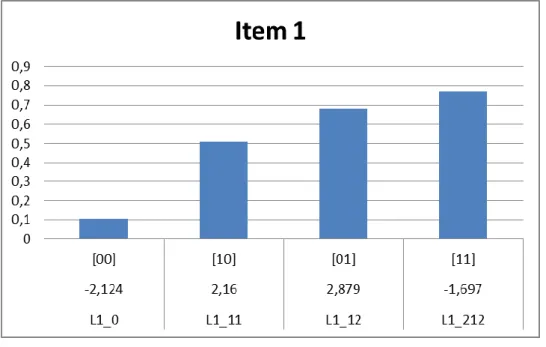
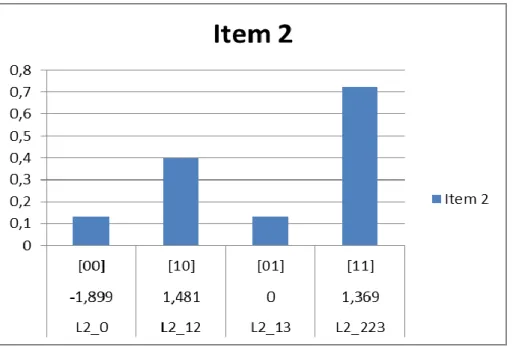
Figure 6. The ICBC for Item 1... 73
Figure 7. The ICBC for Item 2... 74
Figure 8. A sample diagnostic score report (part I) ... 78
xvi
LIST OF ABBREVIATIONS
CDA Cognitive Diagnostic Assessment DCM Diagnostic Classification Modeling DINA Deterministic Input; Noisy “And” Gate DINO Deterministic Input; Noisy “Or” Gate IRT Item Response Theory
MELAB The Michigan English Language Assessment Battery MIRT Multidimensional Item Response Theory
NRC National Research Council SAT Scholastic Aptitude Test
The LCDM The Log-linear Cognitive Diagnostic Modeling TOEFL Test of English as a Foreign Language
1
CHAPTER I
INTRODUCTION
Large-scale assessments have dominantly been used for evaluating the learning outcomes and outputs of educational systems and for obtaining information about the knowledge and abilities of learners (Cui, Gierl, and Chang, 2012; Gao, 2006; Jang, 2008, 2009a). Large-scale assessments have served us for a variety of purposes and could provide us with a general picture of the situation. Yet, they fall short in providing fine-grained information about the performance of the examinees since they specifically focus on percentile ranks showing where an examinee stands (Jang, 2009a; Lee and Sawaki, 2009a) and his overall ability in a given domain (Jurich and Bradshaw, 2013). On the other hand, there has been an increasing tension between high stakes testing and the need for more fine-grained, meaningful information that could be used for instructional and educational purposes and that could also help stakeholders understand examinees’ weaknesses and strengths in a particular domain (Jang, 2008; Nichols, 1994; Snow and Lohman, 1989). The unidimensional nature of high stakes testing has enabled us to assess examinees with more accountability and reliability. However, this very nature of the high stakes testing focusing on ranking examinees along a continuum has paved the way for heated discussion among assessment researchers about the validity of the interpretations arising from these tests and their functions as learning tools. Hence, moving beyond providing examinees merely with a single test score has been on the agenda of educational assessment for decades (Finkelman, Kim, and Roussos, 2009) and this movement has fueled discussions among educational measurement specialists who back up the idea of combining the tenets of cognitive psychology with assessment in order to yield rich and meaningful information about the examinees’ skills, knowledge and abilities required for a specific task or a domain (Gao, 2006).
2
Nevertheless, the call for combining cognitive science and measurement is nothing new (Cronbach, 1975; Embretson, 1991; Embretson and Gorin, 2001; Gierl, 2007; Mislevy, 1996; National Research Council [NRC], 2001; Roussos, DiBello, Stout, Hartz, Henson, and Templin, 2007; Snow and Lohman, 1989). Advancements in the fields of cognitive psychology, educational technology, and statistical modeling have had enjoyed a great impact on educational measurement. Particularly, the impact of cognitive psychology on educational measurement is noteworthy for many scholars. Researchers have addressed and dealt with this issue thoroughly since the call of Snow and Lohman (1989) for integrating cognitive psychology with educational measurement. Snow and Lohman (1989) assert that applying the principles of cognitive psychology to educational measurement is essential. They state that this application would prove beneficial in many ways, such as widening our horizons for understanding and interpreting test scores and gaining a better understanding of the construct of interest. It is also assumed that this application would be useful in generating alternative ways in which the construct could be measured, increasing construct validity, modeling the processes and aspects involved in solving the test tasks successfully and finally, coming up with more relevant and exploratory theories of learning and teaching. Understanding these cognitive aspects and processes of the task at hand is crucial and that is why a cognitive model specifying these aspects and processes is needed to create a cognitive diagnostic test. In a similar vein, Messick (1989) addresses the issue in question and makes the following emphasis in his seminal chapter on validity in Educational Measurement:
Almost any kind of information about a test can contribute to its construct validity, but the contribution becomes stronger if the degree of fit of the information with the theoretical rationale underlying score interpretation is explicitly evaluated. Possibly most illuminating of all are direct probes and modeling of the processes underlying test responses, an approach becoming both more accessible and more powerful with continuing developments in cognitive psychology (p. 17).
Moreover, the report entitled “Knowing What Students Know” released by the NRC in 2001 also suggests that assessments could be seen as evidentiary systems being comprised of three facets: cognition, observation, and interpretation. Here, the facet named as cognition refers to the knowledge related to the abilities, knowledge, and skills of the learners in a particular domain. The ability of the examinee is latent, unobservable and therefore assumed to be cognitive. The second facet, observation, refers to the collection of
3
data with specifically developed tool for that purpose while the last facet called interpretation entails making inferences about the skills of the learners based on our observations. As it is understood, developing a sound theory for a test would increase its construct validity. Since traditional criteria such as item facility and discrimination would not ensure the quality of the items alone, we need more information about the cognitive processes required for the task itself, which would, according to Embretson and Gorin (2001), increase the impact of cognitive psychology on assessment practices gradually. As Gierl and Cui (2008) and Rupp (2007) point out, the impact of cognitive and educational psychology and statistics has been formative on educational measurement. Researchers in the field of educational measurement are searching for plausible methods that could yield more detailed and sound information about the characteristics of test takers which would be beneficial to stakeholders in many ways (Rupp, 2007). One strand of research has set out to model item statistics to gain a better understanding of the cognitive processes that may be required for item solving (Carr, 2003; Embretson, 1998; Freedle and Kostin, 1993; Kostin, 2004). Besides, scale anchoring studies (Beaton and Allen, 1992; Gomez, Noah, Schedl, Wright, and Yolkut, 2007; Liao, 2010) and factor analytic studies (Davis, 1944; Spearitt, 1972; Thorndike, 1971) which focused on group level performance have been conducted. However, it should be noted that these approaches may be limited in that they are not sufficient enough in incorporating current cognitive theories (Gao and Rogers, 2011) or in presenting information about learner profiles since their main focus is on capturing the functioning of the test items (Lee and Sawaki, 2009a).
This endeavor to increase the understanding of test takers’ performances in test tasks and to move beyond the traditional view of assessment which gives us a single score about the performance of test takers has led to a new form of assessment, namely cognitively diagnostic assessment, a term coined by Nichols (1994) which later became the title of a seminal book on this issue (Nichols, Chipman, and Brennan, 1995). To date, to this end, many diagnostic classification models have been developed and put into use (e.g., de la Torre and Douglas, 2004; Embretson, 1984; Gierl, Cui, and Hunka, 2008; Hartz, 2002; Junker and Sijtsma, 2001; Mislevy, Steinberg, and Almond, 2003; Templin and Henson, 2006; von Davier, 2007). The following section provides the reader with some information on cognitive diagnostic assessment and diagnostic classification models. However, to
4
review these models and their characteristics in more detail the reader is referred to Rupp and Templin (2008) and Rupp, Templin and Henson (2010).
Cognitive Diagnostic Assessment
Cognitive Diagnostic Assessment (henceforth, CDA), also named under different labels in the literature, such as skills profiling, skills diagnosis or skills assessment (Roussos et al., 2007), entails assessing each test taker based on a level of competence on a set of skills and assessing the estimation effectiveness of that test by taking the performances of test takers and their skill profiles into consideration. CDA treats assessment as a tool for facilitating learning, rather than assessment of learning, and presents teachers with fine-grained information that would help them modify and tailor their teaching according to the needs of the learners (Jang, 2008, 2009b). CDA may prove useful in several ways such as by increasing the understanding of examinees’ performances in test tasks and moving beyond the traditional view of assessment which gives us no more than a single score about the performance of examinees. This single score would, for no doubts, act as a coarse indicator of cognitive skills and processes needed to accomplish the task and CDA would help us overcome this problem by offering detailed fine-grained information. Moreover, the application of CDA would also provide the stakeholders with meaningful feedback pertaining to the learning outcomes, which could also be regarded as outcome-level feedback for educational institutions (Jurich and Bradshaw, 2013).
CDA is a form of assessment that utilizes a cognitive model to generate items tapping on specific skills or knowledge (which are called attributes) and makes use of this model to guide the analyses related to the response patterns of the examinees to make interpretations about their performances on this task (Gierl, Cui, and Zhou, 2009). The cognitive model used here refers to a “simplified description of human problem solving on standardized educational tasks, which helps to characterize the knowledge and skills students at different levels of learning have acquired and to facilitate the explanation and prediction of students’ performance” (Leighton and Gierl, 2007, p. 6). Cognitive models are created by examining the skills, knowledge and strategies that the test takers make use of while completing a task (Gierl and Cui, 2008). Hence, the need and impetus for a cognitive model would be heralded as highly paramount in the implementation of both CDA and also any kind of assessment.
5
DiBello, Roussos and Stout (2007) propose that the implementation process of CDA consists of the following phases:
a) describing the aim of the assessment and the model involving the attributes to be examined;
b) generating and analyzing the tasks (i.e. test items), determining the psychometric model that is going to be used;
c) selecting the appropriate statistical methods for estimation; and
d) assessing the results of the analyses and reporting the results to the stakeholders. In a similar vein, Jang (2005, 2009a) provides a clear framework for CDA and eloquently identifies the steps of the process. These steps would be:
a) defining learning and instructional goals that would function as the criteria for the diagnosis;
b) by taking these criteria in mind generating tasks that would yield diagnostically meaningful information regarding the proficiency of the examinees; and
c) generating a scoring system that would present us with fine-grained diagnostic information and fourthly make the most of reporting this diagnostic information. In the relevant literature, pertaining to the application of CDA, two approaches prevail (Jang, 2008; Sawaki, Kim, and Gentile, 2009). The first one is the inductive approach in which items and tasks that would enable us to make inferences about the examinees’ abilities and knowledge are created. The second one is the retrofitted approach in which the researchers try to extract information related to the skills and knowledge of interest by using an already existing test. In the former approach, it is very important to generate a cognitive model and define skills beforehand with an informed approach and write the items accordingly in a balanced fashion. However, a closer look at the literature would reveal that it has been the retrofitted approach that has been mainly applied to educational measurement since the inductive approach comes at a hefty price.
Diagnostic Classification Models
There would be occasions on which the main concern is not obtaining a single score about an examinee but estimating his or her profile. This profile or attribute mastery pattern
6
would reveal the examinee’s skills and attributes of what he or she has mastered. This would enable us to make a classification (Henson and Douglas, 2005). Diagnostic classification models, (henceforth would be referred to as DCMs) are used for making these classification-based decisions. DCMs could be regarded as multidimensional measurement models (Jurich and Bradshaw, 2013) and have deep roots in practices, such as classical test theory, item response theory, confirmatory factor analysis, structural equation modeling, and Bayesian statistics. These models have been given different names by the scholars, such as cognitive psychometric models (Rupp, 2007), restricted latent class models (Haertel, 1989), structured located latent class models (Xu and von Davier, 2008), cognitive diagnosis models (Nichols et al., 1995), latent response models (Maris, 1995) and diagnostic classification models (Rupp et al., 2010). Each naming indicates and highlights a certain characteristic of these models; while some labels refer to their purpose, others refer to their theoretical background or statistical properties. However, in this study the researcher sticks to the term diagnostic classification models for the sake of consistency. Because the term DCM encompasses all the models providing classification of examinees based on attributes of interest (Rupp et al., 2010) and furthermore, a distinction between cognitive diagnosis models (such as Rule Space Methodology and Attribute Hierarchy Method) and latent class-based models is needed (Bradshaw, Izsak, Templin, and Jacobson, 2014). DCMs define an examinee’s ability in a given domain based on the attributes that have or have not been mastered. Taking this mastery profile into account, mastery and non-mastery of the skills needed for an item determine the probability of a correct response (Henson, Templin, and Willse, 2009). A mastery profile, which is denoted as αi and defined as a vector of length K, (K refers to the total number of attributes) shows which attributes are mastered. At this point, a cognitive theory describing the process of how the skills aggregate to yield an item response behavior could be deemed quite significant. In the relevant literature on DCMs, a theory related how processes or skills impact an item response behavior is reflected through opting for a particular DCM.
When it comes to the key purpose of DCMs, it could be stated that they serve for presenting stakeholders with meaningful and rich information about examinees’ weaknesses and strengths in a given domain. Moreover, DCMs, with their rigorous methodology, help reinvigorate the validity of the interpretations arising from such
7
diagnostic feedback. Rupp and Templin (2008) offer us a broad and detailed definition of CDMs, in which they describe these models as:
Probabilistic, confirmatory multidimensional latent-variable models with a simple or complex loading structure. They are suitable for modeling observable categorical response variables and contain unobservable (i.e., latent) categorical predictor variables. The predictor variables are combined in compensatory and noncompensatory ways to generate latent classes. (p. 226)
Unidimensional item response theory models try to rank examinees along a continuum of a single general ability in a given domain. On the other hand, DCMs classify examinees according to their mastery or non-mastery of specified attributes due to their multidimensional nature (Madison and Bradshaw, 2014). This feature of DCMs also provides an increased reliability and feasibility even when fewer items are used and this is a considerable advantage over other multidimensional models that are in use (Bradshaw et al., 2014; Templin and Bradshaw, 2013). Moreover, DCMs make it possible to break down a general ability into several dimensions or components, which facilitates the examination of the mental properties or processes leading to the behavior-response at hand.
Again, in contrast to traditional IRT (item response theory) models, DCMs model categorical rather than continuous latent variables. The results obtained from the application of DCMs yield information about the probabilistic attribute profile of each examinee, revealing whether they have mastered one or more than one attribute. DCMs are very effective in predicting the probability of each examinee’s falling into a specific latent diagnostic class. In statistical models that use continuous latent variables and standard-setting procedures, there could always be an error which may stem from more than one source. Moreover, for classification purposes, the utilization of categorical latent variables is more efficient. That is why when compared to unidimensional IRT models DCMs could be better tools for making diagnostic classifications and decisions (Templin and Bradshaw, 2013). Furthermore, it could be argued that DCMs exhibit some advantages over multidimensional item response theory (MIRT) models. One important advantage is that in DCMs, in comparison to MIRT models, fewer items for each dimension are needed to obtain reliable examinee estimates as shown in Templin and Bradshaw (2013).
DCMs are confirmatory in nature because the Q matrix that shows the links between latent and manifest variables (which skills, strategies or attributes are needed to answer each question correctly), specifies the loading structure of DCMs (Bradshaw et al., 2014; Li and
8
Suen, 2013; Sawaki et al., 2009). Though in literature different labels such as latent characteristics, latent traits, elements of processes, skills, attributes, and strategies have been used to refer to latent variables, for the sake of consistency, in this study the researcher sticks to the term “attribute”. Attributes refer to particular skills, knowledge, process and strategies that an examinee should possess to get an item correctly (Buck and Tatsuoka, 1998; Gierl et al., 2000; Leighton and Gierl, 2007). A Q matrix is an item by attribute indicator which shows the attributes that need to be mastered for each item to be answered correctly. To illustrate, for each item, qjk = 1 if the j th item taps on the kth attribute, and qjk = 0 if the kth attribute is not needed to answer the j th item. While constructing the Q matrix, several methods such as think-aloud protocols and expert panels may prove useful. The experts knowledgeable about the domain and having working expertise could be invited to comment on the underlying cognitive processes that are required to get an item right. Test takers’ think-aloud protocols also could give us an idea about the processes they go through while carrying out the tasks.
As pointed out earlier, DCMs define the probability of a correct response based on the Q-matrix and an examinee’smastery profile. However, DCMs show variation in the ways they define the probability of a correct response. Basically, in terms of this difference DCMs could be classified as noncompensatory and compensatory models. Noncompensatory models could be described as models where the conditional relationship between any attribute and the item responses are contingent upon the remaining required attributes that have been mastered or not. Due to this dependency, these models are classified into two among themselves as conjunctive and disjunctive. A basic example of conjunctive models would be the Deterministic Input; Noisy “And” Gate (DINA) Model, which is too restrictive in that the probability of a correct response is high only when the examinee possesses all required attributes for an item (Haertel, 1989; Junker and Sijtsma, 2001). Disjunctive models, on the other hand, posit that the mastery of additional attributes leads to little increase once a subset of the required attributes have been mastered, as in the Deterministic Input; Noisy “Or” Gate (DINO) model of Templin and Henson (2006). In contrast, the compensatory models assume that the mastery of a skill can compensate for non-mastery of other skills as in Compensatory RUM (Hartz, 2002). In the DCM literature, conjunctive models have been more popular than compensatory models in terms of application since these models have been assumed to better fit and reflect the nature of
9
tasks (Roussos, Templin, and Henson, 2007). Conjunctive models have been extensively used in the field of math where the task at hand can be broken down into its components, requiring successful completion of each component. Nonetheless, the use of compensatory DCMs has recently gained popularity when compared to their conjunctive counterpart. Last but not least, DCMs can also be used to test a researcher’s hypothesis related to the cognitive processes that examinees are expected to employ while giving a specific response to an item or task on a test. However, to accomplish this challenging task, an effective data collection design and substantive theory is needed (Rupp and Templin, 2008).
Log-Linear Cognitive Diagnosis Modeling Framework
DCMs define an examinee’s ability in a given domain by taking the attributes that are or not mastered as the basis. Taking this mastery profile into account, mastery and non-mastery of the skills needed for an item determine the probability of a correct response (Henson et al., 2009). At this point, a cognitive theory which is defined as describing the process of how the skills aggregate to yield an item response behavior could be deemed quite significant. In the relevant literature on DCMs, a theory related how processes or skills impact an item response behavior is reflected through opting for a particular DCM. The three most widely discussed general DCM families are
a) the log-linear cognitive diagnosis model (Henson et al., 2009),
b) the generalized deterministic inputs, noisy, and gate model (de la Torre, 2011) and
c) the general diagnostic model family (von Davier, 2010).
In this subsection, a brief overview of the Log-linear cognitive diagnosis modeling (henceforth referred to as the LCDM), which is a general DCM, is presented.
The LCDM is a unifying and general framework which enables us to model most DCMs. DCMs define and parameterize the conditional probability in different ways. Within the LCDM framework one could put constraints on parameters and could come up with different core DCMs, both compensatory and non-compensatory in nature. This way, it becomes possible to model different DCMs such as the DINA, NIDA, Reduced C-RUM,
10
NIDO, DINO and C-RUM (Henson et al., 2009; Rupp et al., 2010). Detailed information on the LCDM, which is the psychometric model utilized for the present study, is provided in the Methods section. Also, for an elaborated explanation on the statistical foundations of the LCDM the reader is referred to the work of Henson et al. (2009) and Rupp et al. (2010).
DCMs in Language Assessment
Although the use of DCMs is not something new to the psychometric society, their use has not been very common in language testing (Lee and Sawaki, 2009a). Tatsuoka’s (1983) pioneering work on rule-space methodology coming out nearly three decades ago has paved the way for developing psychometric-grounded methods for capturing and diagnosing cognitive attributes. That ground-breaking work underscores many implications for language assessment which is, in a way, predominantly occupied with high-stakes examinations. The results obtained from such analyses would be extremely beneficial since they could yield fine-grained information about examinees, and could guide and help us in our educational decisions. These decisions would not be limited to the decisions about mastery level of the examinees, but also would be related to practices in classrooms, educational materials that are used and teachers’ practices. Unfortunately, in the domain of language assessment few diagnostic tests exist for our use (Alderson, 2005) and there is an increasing need for diagnostic tests.
To date, several applications have taken place in language assessment. Notable examples would be the application of the Rule Space Methodology to TOEFL and TOEIC Reading and SAT verbal (Buck, Tatsuoka, and Kostin, 1997; Kasai, 1997; Scott, 1998), the application of the Fusion Model (Hartz, 2002) to TOEFL IBT reading and listening sections and MELAB reading section (Jang, 2005; Lee and Sawaki, 2009a; Li, 2011; Li and Suen, 2013; von Davier, 2005) and the application of the LCDM to University of Michigan’s ECPE test data (Templin and Hoffman, 2013). Attribute Hierarchy Method (Leighton, Gierl, and Hunka, 2004) has also been applied to SAT verbal data (Wang and Gierl, 2007). All these applications have shown that the application of DCMs to language testing yields fruitful results. However, the majority of these applications of DCMs to language assessment have been retrofitting studies as in Sheehan’s tree-based regression method (1997), Buck and Tatsuoka’s (1995, 1996, 1998), Kasai’s (1997) application of
11
RSM to reading comprehension tests, the application of the Fusion model to MELAB reading data (Li, 2011; Li and Suen, 2013) to TOEFL reading and listening sections (Jang, 2005, 2009a, 2009b; Lee and Sawaki, 2009b; Sawaki et al., 2009), to IELTS listening data (Aryadoust, 2011, 2012), and to Quality and Accountability Office reading test (Jang et al., 2013).
An endeavor to reverse engineer existing tests developed to measure proficiency, rather than for diagnostic purposes may pose great challenges for language testers as reflected in Jang (2009b) as “when cognitive diagnostic modeling is retrofitted to an existing non-diagnostic test, serious challenges occur” (p. 233). On the other hand, this very event is also a landmark in the history of language assessment where such kind of studies are rare, as Alderson (2010) also makes clear by pointing out “especially on a topic as under problematized and under researched as the diagnosis of learners’ strengths and weaknesses in second language learning and proficiency” (p. 97). However, the limitations of the retrofitting approach are clearly evident (Alderson, 2010; Gierl and Cui, 2008; Jang, 2008, 2009; Lee and Sawaki, 2009a; Li and Suen, 2013) and the need and impetus for designing a truly diagnostic test has been a recurrent call in the studies which applied DCMs to language proficiency tests (Jang 2009a, 2009b; Li and Suen, 2013; Sawaki et al., 2009).
Assessment of Reading Comprehension
Reading comprehension is a very complex construct and this complexity of reading comprehension has been echoed by many reading researchers (Rupp, Ferne, and Choi, 2006). The dynamic and elusive nature of the reading comprehension makes it difficult to measure the construct and that is why it has been the object of a wealth of research. Assessing reading comprehension is a challenging task (Francis et al., 2006) for several reasons. Firstly, though there is a vast body of research on reading comprehension, reading researchers and theorists have not reached a consensus over which skills and processes are involved in reading. Secondly, even we ascertain that the skills and processes we identify truly exist, still we cannot know for certain if the test that we use measures these skills and processes in a valid and reliable manner. This problem grows more tangled when it comes to assessing reading comprehension for diagnostic purposes. Regarding this issue, Alderson (2000) posed a challenging question when he asked, “How can we possibly diagnose somebody’s reading problems if we have no idea what might constitute a
12
problem and what the possible causes might be?” (p. 2). The challenge that reading assessment needs to initially deal with would be determining what might constitute the reading comprehension. Alderson (2000) continued to elaborate on this challenging issue and asserted that “if we wait until we have a perfect understanding of our constructs before we begin to devise assessment instruments, then we will never begin test construction” (p. 2). The implication arising from these statements would be that as language testers get involved in test development, they will be able to examine both the nature of the tests and the constructs that are measured by those tests. At this point, suffice it to say that the application of DCMs, which provide us with statistical tools to examine substantive theories forming the basis of the tests, would also aid us in refining our understanding of reading comprehension.
Remaining Issues
Though it is also questionable whether DCMs have feasible applications in real life testing situations or not (Bradshaw et al., 2014), this assumption may have to do with the fact that the majority of the applications of DCMs have been retrofitting studies, in which tests were not created for diagnostic purposes or did not possess a multidimensional nature. Many up-to-date practices in CDA make use of the retrofitting approach in which items are scrutinized in terms of their cognitive attributes and then are subject to analysis. This approach seems much more convenient due to the availability of the test items and large data sets which alleviate the burden on developing a test from scratch and collecting data. However, as Gierl (2007) also emphasizes, retrofitting has drawbacks in that it lacks a cognitive model guiding the test design and decisions and items specifically developed to tap on predetermined attributes. Though we could also come across items that could yield relevant information about these attributes, there is still a high possibility of an uneven distribution of these attributes which make it hard to extract meaningful information. A second drawback would be the misfit between the cognitive model generated later and the test data since the test is not based on that cognitive model. To overcome these existing problems with the retrofitting method, a more informed and well-structured test design including a clear cognitive structure and relatively more items would be beneficial (Li and Suen, 2013). Relevant literature also points to the need for DCM applications in which a diagnostic test designed to measure a multidimensional construct is put into use.
13
At this point, this study takes this step and attempts to investigate the possibility of generating a cognitive diagnostic test from ground up and analyze test data through a DCM, specifically the Log-Linear Cognitive Diagnosis Model. The present study is novel and significant in the sense that it utilized a cognitive model guiding the whole process and a cognitive diagnostic test generated in line with this model. Such applications are very rare in the fields of educational measurement and language assessment where most applications depend on retrofitting existing tests to DCMs. This study, to the best of the researcher's knowledge, is one of the first examples of application to DCMs to a test that was designed to measure a multidimensional construct. The present study also questions what might be possible when a test based on a cognitive model and designed for diagnostic purposes is used in a DCM application, which holds great promise in the field of educational measurement. Specifically, this study aimed to answer the following questions:
1. How could a cognitive model of second language reading impact the assessment process itself and the interpretations arising from an assessment?
2. How effectively does the Cognitive Diagnostic Second Language Reading Comprehension Test (the CDSLRC Test) that was developed within the scope of this study determine skill profiles?
3. How effectively does the LCDM estimate second language reading comprehension skill profiles?
4. What are the characteristics of the skill profiles estimated by the LCDM?
The present study aims to reach out heterogeneous audiences with different concerns. These audiences would be language assessment and measurement experts, reading specialists and theorists and language teachers interested in diagnostic assessment. While pursuing the answers pertaining to the questions presented above, the following assumptions were prioritized in the present study:
1. The construct at hand, second language reading comprehension, can be decomposed into a set of distinct reading skills,
2. The sample of the present study had English proficiency high enough to meet the language threshold issue.
Apart from discussing technical issues related to research methodology, the following chapter would narrate steps the and actions taken to generate a cognitive model for second
14
language reading, the process of development of the CDSLRC Test, the administration of the CDSLRC Test on a large-scale sample, the application of the LCDM on test data and the collection of qualitative think-aloud data to ensure the validity of the CDSLRC Test data and the interpretations arising from the application.
15
CHAPTER II
LITERATURE REVIEW
This section is comprised of seven installments. In the first installment, some insights into the nature of reading have been presented. While the second installment reviews the approaches to reading, the third installment gives an account of the theoretical reading models generated to demystify L1 and L2 reading processes and discusses their implications for the present study. The fourth installment discusses the links between L1 reading, L2 reading and L2 proficiency. The fifth installment reviews the studies that utilized diagnostic classification modeling in reading research and appraises the significance of these applications. The sixth installment reflects an attempt to define the construct of reading comprehension. Finally, the seventh installment lays the foundations of the second language reading comprehension construct at hand; and most importantly, describes how it is defined and operationalized in the present study.
The nature of reading
The question “what is reading” has always been a matter of investigation among reading researchers, and since there have been no clear-cut, absolute answers to this question, various definitions of reading have been proposed in a vast body of literature. The most widely accepted definition is that reading is a meaning-making or meaning extracting process. According to this, when we accept reading as a cognitive process, we try to understand the processes, time it takes, and information being utilized during the processing, including possible sources of obstacles and learning gain (Just & Carpenter, 1987). Moreover, in any model of cognitive reading, reading is regarded as an individual endeavor that is takes place in the brain, a process during which many components come
16
into play. Yet, recent socio-cognitive views of reading have expunged the old idea by emphasizing the clear trade-off among the major components of reading process, the text and the reader (Bernhardt, 1991).
Grabe (2009) posits that the major components of reading can be listed as fluency, reading speed, automaticity, rapid word recognition, search processes, vocabulary knowledge, morphological knowledge, syntactic knowledge, text-structure awareness, discourse organization, main idea comprehension, recall of relevant details, inferencing, strategic processing abilities, summarizing, synthesis and evaluation skills and critical thinking. Hence, reading could be regarded as an interaction between text-based and knowledge-based processes of a reader (Alptekin, 2006) in which the reader uses lower-level and higher-level reading processes (Grabe, 2009) in harmony. The lower-level processes encompass precursor skills such as word recognition, syntactic parsing and meaning encoding. These processes highly depend on working memory and are crucial to effective reading (Alptekin and Erçetin, 2009; Grabe, 2009; Holmes, 2009; Perfetti, 1992; Stanovich, 1980) and among these prerequisite skills, especially word recognition skill is considered to have a fundamental role in reading. For instance, Smith and Kosslyn (2007) suggest that the purpose of reading is to translate words into semantic information about the text; consequently, reading primarily requires associating the spelling or orthography of a word with its meaning. The authors point to two kinds of pathways for reading process; these are spelling-meaning route, in which spelling of a word leads to its meaning and spelling-phonology-meaning route in which the spelling is first linked with pronunciation then with meaning. However, the authors also contend that skilled readers and adults follow the first route. It is assumed that these lower-level processes become more automatic as the readers become more skilled in reading (Perfetti, 1992; Stanovich, 2000). On the other hand, higher level processes include textbase and situation model formation (Kintsch, 1988) inferencing, strategic processing and executive-control processing (Grabe, 1991, 2009). Using these higher-level reading processes, readers are able to go beyond the literal meaning that the text contains and make inferences, generalizations and syntheses. At this point Kintsch’s construction-integration model (1988) is worth mentioning. According to Kintsch (1988), as readers move along a text, sentences are converted into propositions that constitute the meaning of the text and later these propositions are transferred to the short-term buffer in order to create a propositional net. These
17
propositions aid in retrieving related propositions from the long-term memory. The propositions that are formed while reading the text and the ones that are retrieved from the long-term memory finally constitute the elaborated propositional nets which may also include irrelevant propositions. During the integration process, these irrelevant propositions in the elaborated propositional net die off. Nevertheless, propositions that are contextually bound become stronger. As a consequence, three levels of representations; which are the surface representation (the text itself), propositional representation or textbase (propositions formed from the text) and the situational representation (a mental model describing the situation) are formed.
Kintsch’s construction-integration model (1988) draws a distinction between micro-level and macro-level representations of the textbase. Lower-level processing elements such as word recognition and syntactic parsing are needed to form the micro-structure of the text, which would lead the reader to the literal meaning. However, only the micro-structure of the text would not be adequate to form a textbase, which would call for establishing the macro-structure of the text. The macro-structure of the text is formed by depending on higher-level processes such as inferencing, establishing cause and effect relationships, etc. Apart from these components, to go beyond the literal meaning of the text and to form a coherent mental representation of the text, readers need to construct a situation model by activating their background knowledge. Therefore, it is safe to posit that Kintsch’s construction-integration model (1988) recognizes the significance of lower-lever processes in reading, yet appraises that higher-level processes are of utmost importance to form a coherent and effective mental representation of the text.
The importance of higher-level processes has been echoed by several scholars in the field. For instance, Balota, Paul and Spieler (1999) contend that apart from orthography, lexical access and syntactic parsing, higher-level discourse integration is fundamental to reading. O’Reilly and Sheehan (2009) provide a detailed account of how these processes exert an impact on reading and propose that reading skills can be categorized as prerequisite reading skill, model building skill and applied comprehension skill. In order to read more effectively, readers are expected to employ model building and applied comprehension skills apart from basic prerequisite reading skill. In O’Reilly and Sheehan’s (2009) taxonomy, prerequisite reading skill is related with the ability to read a text accurately rather than comprehending it and is comprised of several subskills which are listed as
18
recognizing common words, decoding unfamiliar words and reading fluently. On the other hand, model building skill encompasses skills that are necessary to extract meaning from the text, such as using words, sentences and paragraphs to construct meaning, locating and retrieving information, inferencing, generalizing and summarizing. Lastly, applied comprehension skill requires using information presented in the text for specific purposes and moving beyond the literal understanding of the text. This category essentially requires higher level reading and critical thinking skills, such as evaluating, criticizing, integrating, synthesizing, explaining and reasoning.
A similar taxonomy has been offered by Hughes (2003) in which reading skills, operations in Hughes’ terms, are divided into two classes as expeditious reading operations and careful reading operations. Expeditious reading operations are described as skimming, search reading and scanning. Skimming is used to obtain main ideas and discourse topic quickly and efficiently, to establish the structure of a text quickly and to decide the relevance of a text to the needs, while search reading involves finding information on a predetermined topic. Scanning includes finding specific words and phrases, figures, percentages, specific items in an index and specific names in a bibliography or a set of references quickly. In this taxonomy, careful reading operations encompass identifying prominal references and discourse markers, interpreting complex sentences and topic sentences, outlining the logical organization of a text and the development of an argument, distinguishing general statements from the examples, identifying explicitly and implicitly stated main ideas, recognizing writer’s intentions, attitudes and emotions, identifying the addressee of a text and making inferences.
Since reading has been a field of interest among researchers trained in various disciplines, such as cognitive psychology, literacy education and language arts, there is a plethora of research on reading that examines the matter at hand in terms of numerous aspects and from different perspectives. It is difficult to synthesize the extremely wide array of research in reading, yet some inferences about the nature of reading could be drawn. First, reading could be regarded as an interactive process in which there is a continuous trade-off between the reader and the text. The interaction is evident in that while the text helps the writer to convey his message, the reader brings his background knowledge to the process. Second, reading could be accepted as a strategic process in which the reader monitors his comprehension, anticipates what is coming next, identifies breakdowns in comprehension
19
and amends these breakdowns. Third, reading could be regarded as a flexible process in that the reader has the opportunity to tune his reading when he encounters problems and to adjust the way he handles the task. Fourth, reading could be seen as an evaluative process in which the reader evaluates the messages conveyed by the author, and the very ideas, intentions, attitude and style of the author. Besides, the reader may evaluate the reading process by taking his or her own background knowledge into consideration. Fifth, reading could be accepted as a learning process in which the reader expands his knowledge-base of different issues. Finally, reading could certainly be defined as a linguistic process, for which the reader should be equipped with graphemic-phonemic, word, syntactic and semantic knowledge-base.
Approaches to reading
Over the last three decades, views related to the nature of reading have shown drastic changes (McNeil, 2012). These changes occurred particularly as a consequence of the shift experienced in psychology research, a shift from the behavioral orientation to the cognitive orientation (Gao, 2006). Specifically in the mid-60s, where the audiolingualism was on the throne, reading was seen as a way to study vocabulary, grammar and most importantly pronunciation. Hence, until the late 1970s, reading was viewed as a language-based, bottom-up process, during which the reader constructs meaning in a set of sequential phases. The reader was regarded as a passive organism who decoded the meaning through identifying letters, words and sentences. Historically, approaches reflecting these views related to reading are called bottom-up approaches, and Gough (1972), Carver (1977) and LaBerge and Samuels (1974) are typical examples of models that are bottom-up in nature. To illustrate, LaBerge and Samuels (1974) assumed that reading is comprised of two tasks which are decoding and comprehension. In the early stages of reading, decoding employs the attention mechanisms to a considerable degree and as the decoding process becomes automated, it would be possible to devote greater attention to comprehension. LaBerge and Samuels (1974) claimed that three stages, which are visual memory, phonological memory and the response system are involved in reading and these stages are assumed to be in a linear fashion.
However, beginning in the early 70s, bottom-up approaches to reading which viewed reading merely as a language-based, linear decoding process became to be challenged by