T.C.
SELÇUK ÜNĠVERSĠTESĠ FEN BĠLĠMLERĠ ENSTĠTÜSÜ
KURBAĞA SIÇRAMA ALGORĠTMASININ KÜMELEME PROBLEMLERĠNE
UYGULANMASI Murat KARAKOYUN YÜKSEK LĠSANS TEZĠ
Bilgisayar Mühendisliği Anabilim Dalını
Aralık-2015 KONYA Her Hakkı Saklıdır
TEZ BĠLDĠRĠMĠ
Bu tezdeki bütün bilgilerin etik davranıĢ ve akademik kurallar çerçevesinde elde edildiğini ve tez yazım kurallarına uygun olarak hazırlanan bu çalıĢmada bana ait olmayan her türlü ifade ve bilginin kaynağına eksiksiz atıf yapıldığını bildiririm.
DECLARATION PAGE
I hereby declare that all information in this thesis document has been obtained and presented in accordance with academic rules and ethical conduct. I also declare that, as required by these rules and conduct, I have fully cited and referenced all material and results that are not original to this work.
Murat KARAKOYUN
iv ÖZET YÜKSEK LĠSANS
KURBAĞA SIÇRAMA ALGORĠTMASININ KÜMELEME PROBLEMLERĠNE UYGULANMASI
Murat KARAKOYUN
Selçuk Üniversitesi Fen Bilimleri Enstitüsü Bilgisayar Mühendisliği Anabilim Dalı DanıĢman: Yrd. Doç. Dr. Ahmet BABALIK
2015, 84 Sayfa Jüri
Yrd. Doç. Dr. Ahmet BABALIK Yrd. Doç. Dr. Mehmet HACIBEYOĞLU
Yrd. Doç. Dr. Mustafa Servet KIRAN
Verilerin kendi aralarındaki benzerlik ve farklılık durumlarına göre gruplandırılması iĢlemi kümeleme olarak adlandırılabilir. Kümeleme iĢleminden sonra aynı kümedeki verilerin benzerliklerinin, farklı kümelerdeki verilerin benzersizliklerinin maksimum olması beklenir. Bu çalıĢmada UCI Machine Learning Repository veri ambarından alınan 12 adet veri seti (Balance, Breast Cancer Wisconsin Diagnostic, Breast Cancer Wisconsin Original, Credit, Dermatology, Diabetes, E. Coli, Glass, Heart Disease, Iris, Thyroid ve Wine) üzerinde Kurbağa Sıçrama Algoritması (KSA) ile hiyerarĢik olmayan kümeleme yapılmıĢtır. KSA küme merkezlerinin belirlenmesi amacıyla kullanılmıĢtır. Veriler ile küme merkezleri arasındaki toplam uzaklık Öklid metodu ile hesaplanmıĢtır. Toplam karesel uzaklık değerinin minimize edilmesi KSA’nın amaç fonksiyonu olarak ele alınmıĢtır. Bunun yanı sıra KSA’nın genel yapısında herhangi bir değiĢikliğe gidilmeden, memetik evrim aĢamasında uygunluk değeri en kötü olan kurbağanın konumunun güncellenmesi için sıçrama miktarının belirlenmesi sırasında adaptif bir seçim önerilmiĢtir. KSA’nın önerilen bu yeni hali Adaptif Kurbağa Sıçrama Algoritması (AKSA) olarak isimlendirilmiĢtir. KSA ve AKSA’nın belirlenen veri setleri üzerindeki kümeleme performansları incelenmiĢtir. Elde edilen deneysel sonuçlara göre AKSA’nın kümeleme problemleri için KSA’dan genel olarak daha baĢarılı sonuçlar elde ettiği görülmüĢtür.
Anahtar Kelimeler: Adaptif Kurbağa Sıçrama Algoritması, HiyerarĢik olmayan kümeleme, Kurbağa sıçrama algoritması, Kümeleme.
v ABSTRACT MS THESIS
USING THE SHUFFLED FROG LEAPING ALGORITHM ON CLUSTERING PROBLEMS
Murat KARAKOYUN
THE GRADUATE SCHOOL OF NATURAL AND APPLIED SCIENCE OF SELÇUK UNIVERSITY
THE DEGREE OF MASTER OF SCIENCE IN COMPUTER ENGINEERING Advisor: Asst. Prof. Dr. Ahmet BABALIK
2015, 84 Pages Jury
Asst. Prof. Dr. Ahmet BABALIK Asst. Prof. Dr. Mehmet HACIBEYOĞLU
Asst. Prof. Dr. Mustafa Servet KIRAN
The clustering is to group any data set according to data similarities and dissimilarities. After clustering, the similarity among data in same group and the dissimilarity among data in different groups are expected to be maximum. In this work, Shuffled Frog Leaping Algorithm (SFLA) is applied on non-hierarchical clustering by using 12 data sets (Balance, Breast Cancer Wisconsin Diagnostic, Breast Cancer Wisconsin Original, Credit, Dermatology, Diabetes, E.Coli, Glass, Heart Disease, Iris, Thyroid and Wine) taken from UCI Machine Learning Repository platform. SFLA is used to find center of clusters. Euclidean method is used to calculate the distance between data objects and their cluster center. The minimizing of the sum squared distance value is used as SFLA’s fitness function. Besides, without going to any changes in the structure of SFLA, a new adaptive choice of leaping size is proposed during the updating location of the worst frog in the population. The proposed model of the SFLA is named as Adaptive Shuffled Frog Leaping Algorithm (ASFLA). The clustering performances of the SFLA and ASFLA are analyzed on using data sets from UCI and compared with each other. According to the experimental results, the clustering performance of the ASFLA is generally better than the clustering performance of the SFLA.
Keywords: Adaptive Shuffled Frog Leaping Algorithm, Clustering, Non-hierarchical clustering, Shuffled frog leaping algorithm.
vi ÖNSÖZ
ÇalıĢmalarım boyunca gösterdiği katkı ve yardımlarından dolayı danıĢmanım Sayın Yrd. Doç. Dr. Ahmet BABALIK’ a ve benden desteklerini esirgemeyen sevgili eĢime ve biricik kızıma teĢekkürlerimi sunarım.
Murat KARAKOYUN KONYA-2015
vii ĠÇĠNDEKĠLER ÖZET ... iv ABSTRACT ... v ÖNSÖZ ... vi ĠÇĠNDEKĠLER ... vii KISALTMALAR ... ix 1.GĠRĠġ ... 1 2. KAYNAK ARAġTIRMASI ... 3 3. MATERYAL VE YÖNTEM ... 8 3.1. Materyal ... 8 3.1.1.Sentetik veriler ... 8 3.1.2.Gerçek veriler ... 9 3.2.Kümeleme ... 12
3.2.1. Kümelemede kullanılan uzaklık metotları ... 14
3.2.1.1. Sürekli veriler için uzaklık metotları ... 14
Öklid (Euclidean) uzaklığı ... 14
Manhattan uzaklığı ... 15
Minkowski uzaklığı ... 15
Pearson uzaklığı ... 16
3.2.1.2. Kesikli veriler için uzaklık yöntemleri ... 16
3.2.2. Kümeleme Algoritmaları ... 16
3.2.2.1. HiyerarĢik kümeleme algoritmaları ... 17
Tek bağlantı algoritması ... 18
Tam bağlantı algoritması ... 18
Ortalama bağlantı algoritması ... 18
3.3.2.2. HiyerarĢik olmayan kümeleme algoritmaları ... 19
K-Means kümeleme algoritması ... 19
K-Medoids kümeleme algoritması ... 22
3.2.3.Kümeleme sonuçlarının değerlendirilmesinde kullanılan yöntemler ... 22
3.2.3.1.Rand index ölçüm yöntemi ... 23
3.2.3.2.Toplam karesel uzaklık yöntemi ... 23
3.2.3.3.Yakınsama değeri ... 24
3.3.Kurbağa Sıçrama Algoritması (KSA) ... 24
3.4.Kurbağa Sıçrama Algoritmasının Kümeleme Problemine Uygulanması ... 34
3.5.Önerilen Kurbağa Sıçrama Algoritması ... 35
4.ARAġTIRMA BULGULARI VE TARTIġMA ... 39
4.1.Sentetik Veriler Ġçin Sonuçlar ... 39
4.2.Gerçek Veriler Ġçin Sonuçlar ... 40
viii
4.2.2. Toplam karesel uzaklık hesabı ... 53
4.2.3. KSA ve AKSA’nın TKU yakınsamaları ... 66
5.SONUÇ VE ÖNERĠLER... 80
KAYNAKLAR ... 82
ix
KISALTMALAR
AKSA : Adaptif Kurbağa Sıçrama Algoritması ASFLA : Adaptive Shuffled Frog Leaping Algorithm
FCM : Fuzzy C-Means
GA : Genetik Algoritma
HFKHM : Hybrid Fuzzy K-Harmonic Means
KHM : K-Harmonic Means
KKA : Karınca Kolonisi Algoritması KSA : Kurbağa Sıçrama Algoritması PSO : Parçacık Sürü Optimizasyonu
RI : Rand Index
SFLA : Shuffled Frog Leaping Algorithm
SSE : Sum Squared Error
TKU : Toplam Karesel Uzaklık YAK : Yapay Arı Kolonisi
1.GĠRĠġ
Kümeleme, veri madenciliği, istatistiksel veri analizi ve veri kıyaslama gibi konularda verileri gruplandırmak için kullanılan önemli bir yöntemdir. Bu yöntem, aynı kümede toplanan verilerin benzerlik derecelerinin yüksek, ayrı kümeler için ise birbiri ile farklılık derecelerinin yüksek olması esasına dayanır. Yani küme içi benzerliğin maksimum ve kümeler arası benzerliğin minimum olması istenir (Karaboga ve Ozturk 2011).
Literatürde birçok kümeleme algoritması bulunmaktadır; ancak kümeleme algoritmaları temel olarak hiyerarĢik ve hiyerarĢik olmayan kümeleme algoritmaları olmak üzere 2 ana baĢlıkta toplanmaktadır. HiyerarĢik kümeleme algoritmalarında gruplandırma iĢlemi yapılırken küme sayısı belli değildir. Diğer yandan hiyerarĢik olmayan kümeleme algoritmaları, N adet veriyi k tane kümeye ayırır. Yani küme sayısına daha önceden karar verilmiĢtir ve buna göre kümeleme iĢlemi gerçekleĢtirilir (Frigui ve Krishnapuram 1999).
HiyerarĢik olmayan kümeleme algoritmalarının baĢında K-Means algoritması gelmektedir. K-Means algoritması hızlı, basit ve genel olarak baĢarılı bir algoritma olmasına karĢın, baĢarım oranı seçilen baĢlangıç konumuna bağlıdır ve bu sebeple de çoğu zaman baĢlangıç konumuna en yakın yerel minimuma takılır (MacQueen 1967). Bu sorunu aĢmak için araĢtırmacılar çalıĢmalarında farklı kümeleme algoritmaları geliĢtirmeye çalıĢmaktadırlar. Ġstatistik, graf teorisi, maksimizasyon algoritmaları, yapay sinir ağları, evrimsel algoritmalar ve sürü zekası algoritmaları gibi farklı teknikler kümeleme problemlerinin çözümlerinde kullanılmaktadır (Karaboga ve Ozturk 2011).
Bu çalıĢmada, hiyerarĢik olmayan kümeleme yapmak üzere Kurbağa Sıçrama Algoritması (KSA) kullanılmıĢtır. KSA, topluluk Ģeklinde yaĢayan kurbağaların yiyecek arama davranıĢlarını modelleyen memetik bir algoritmadır. KSA’nın temel amacı minimum hareket ile maksimum besine ulaĢmaktır. KSA’nın çalıĢması sırasında popülasyondaki kurbağalar birbirleri ile bilgi paylaĢarak en kaliteli besin kaynağına ulaĢmaya çalıĢırlar. Bu çalıĢmada, orijinal KSA’nın kümeleme problemlerinde performansını artırmak amacıyla KSA’nın yerel arama aĢamasında kullanılan sıçrama miktarı parametresinin seçiminde yeni bir yaklaĢım önerilmiĢtir. Önerilen AKSA ve KSA’nın orijinal halinin kümeleme problemlerindeki performansları Rand Index (RI) ve Toplam Karesel Uzaklık (TKU) yöntemleri ile algoritmaların sonuca yakınsama
değerleri ele alınarak kıyaslanmıĢtır. ÇalıĢmada kullanılan veri setleri UCI Machine Learning Repository veri ambarından alınmıĢtır (UCI 2014).
Bu çalıĢmanın organizasyon Ģeması Ģu Ģekildedir; çalıĢmanın birinci bölümünde kümeleme hakkında genel bilgi verilmiĢtir. Bununla beraber kümeleme yapmak için kullanılan KSA hakkında temel bilgiler verilmiĢtir.
ÇalıĢmanın ikinci bölümünde literatür araĢtırması sunulmuĢtur. Kümeleme problemi üzerine yapılan çalıĢmalar ve KSA’nın kullanıldığı çalıĢmalar incelenmiĢtir. Bununla beraber kümeleme problemlerine, KSA’nın uygulandığı bazı çalıĢmalar incelenmiĢtir.
ÇalıĢmanın üçüncü bölümünde ilk olarak kümeleme problemlerinde veri olarak kullanılan sentetik (yapay) ve gerçek veriler tanıtılmıĢ, bu veriler hakkında detaylı bilgi verilmiĢtir. Kümeleme problemi analizi hakkında bilgi verilmiĢtir. Kümeleme yöntemlerinden bahsedilmiĢtir. Kümeleme analizinde kullanılan performans değerlendirme yöntemlerinden bahsedilerek bu çalıĢmada kullanılan, performans ölçüm yöntemleri vurgulanmıĢtır. Daha sonra kümeleme probleminde kullanılan KSA’nın genel yapısı ve çalıĢma prensibi hakkında bilgi verilmiĢtir. KSA’nın kümeleme problemine uygulanması hakkında açıklama yapılmıĢtır. Üçüncü bölümde son olarak KSA’nın orijinal hali ile önerilen AKSA arasındaki fark açıklanmıĢtır.
ÇalıĢmanın dördüncü bölümünde elde edilen deneysel sonuçlar, tablo ve grafikler ile detaylı bir Ģekilde incelenmiĢtir.
2. KAYNAK ARAġTIRMASI
Kümeleme, veri madenciliği, istatistiksel veri analizi ve veri kıyaslama gibi konularda verileri gruplandırmak için kullanılan önemli bir yöntemdir. Veriler karakteristik özelliklerinin benzerlik derecelerine göre gruplandırılırken, birbirine benzer yapıda olan veriler aynı grupta toplanmak istenmektedir. Öte yandan veri gruplarının kendi aralarındaki benzerliklerinin minimum olması istenmektedir (Karaboga ve Ozturk 2011). Literatürde, gerek farklı alanlardaki verilerin kümelenmesi gerekse de farklı algoritmaların kümeleme problemleri üzerinde kullanılması sonucu birçok çalıĢma mevcuttur.
Karami ve Zapata (2015) yaptıkları çalıĢmada, Parçacık Sürü Optimizasyonu (PSO) ve K-Means algoritmalarını kullanarak, içerik merkezli ağlara yapılan saldırıları bertaraf etmek için, gelen saldırıları kümeleyip elde edilen sonuçlara göre önlem alacak bir yaklaĢımda bulunmuĢlardır. K-Means algoritması tek baĢına kullanıldığında elde edilen küme merkezlerinin yeterli derecede optimize edilmediğini belirterek, iki aĢamalı bir çalıĢma gerçekleĢtirmiĢlerdir. Eğitim aĢaması olarak adlandırdıkları ilk bölümde PSO ve K-Means algoritmalarını hibrit bir Ģekilde kullanarak küme merkezlerini bulmaktadırlar. Ġkinci aĢama olan algılama aĢamasında verilerin anormalliklerini tespit etmek için bulanık yeni bir yaklaĢım kullanmıĢlardır. ÇalıĢmalarını, bazı diğer kümeleme algoritmaları ile kıyasladıklarında daha optimum küme merkezleri ve yüksek kalitede algılama oranları yakaladıklarını belirtmiĢlerdir (Karami ve Guerrero-Zapata 2015).
Tsapanos ve ark.(2015)’ları Kernel K-Means’e yeni bir yaklaĢım getirerek üç aĢamalı yeni bir model sunmuĢlardır. Kernel matrix hesaplama, yeni bir yaklaĢımla kernel matris kırpma metodu ve kernel K-Means kümeleme algoritması bölümlerinden oluĢan bu yeni yaklaĢımda büyük ölçekteki veri setleri üzerinde çalıĢılmıĢ ve performansın arttırılması hedeflenmiĢtir (Tsapanos ve ark 2015).
Wu ve ark.(2015)’ları K-harmonic means (KHM) ve Fuzzy C-means (FCM) kümeleme metotlarını birlikte kullanarak Hybrid Fuzzy K-harmonic means (HFKHM) algoritmasını veri kümeleme problemlerine uyarlamıĢlardır. ÇalıĢmalarının deneysel sonuçlarında, kümeleme performansını arttırdıklarını belirtmiĢlerdir (Wu ve ark 2015).
Basu ve Murthy (2015), doküman kümeleme problemi üzerinde çalıĢmıĢlardır. Klasik K-Means algoritmasına yeni bir yaklaĢım getirerek, önerdikleri yeni bir uzaklık fonksiyonu kullanmıĢlardır. Bu yöntemlerinde kümeleme aĢamasında, klasik K-Means
algoritmasının ihtiyaç duyduğu gibi, küme sayısına önceden ihtiyaç duyulmadığını belirtmiĢlerdir. Elde ettikleri deneysel sonuçlarda veri setlerindeki dokümanların yüksek baĢarı ile gruplandırıldığını belirtmiĢlerdir (Basu ve Murthy 2015).
Liu ve Ban (2015) önerdikleri yeni bir metotla, literatürde var olan diğer kümeleme tekniklerinden farklı olarak kümeleme problemi üzerinde çalıĢmıĢlardır. Bu yöntemlerinde küme sayısının önceden bilinmesine ihtiyaç duymamıĢlardır. Önerdikleri yöntem, gruplar içerisindeki verilerin birbiri ile olan iliĢkilerini detaylandıran, iki boyutlu dinamik bir topolojik graf üretme tabanlı çalıĢmaktadır. Elde ettikleri deneysel sonuçlara göre önerdikleri yöntemin baĢarılı olduğunu gözlemlemiĢlerdir (Liu ve Ban 2015).
Rahman ve Islam (2014) Genetik Algoritma (GA) tabanlı olmak üzere K-Means ile bütünleĢmiĢ bir kümeleme yaklaĢımı önererek kümeleme problemindeki doğru küme sayısını tespit etme konusunda çalıĢmıĢlardır. Bu yaklaĢımları ile daha performanslı küme merkezlerinin tespitini yapmıĢlardır. ÇalıĢmalarında kullandıkları 20 veri seti üzerinde kıyaslama yaptıkları diğer beĢ metottan genel olarak daha baĢarılı olduklarını göstermiĢlerdir (Rahman ve Islam 2014).
Tzortzis ve Likas (2014) klasik K-Means algoritmasının, seçilen baĢlangıç konumundan dolayı yerel optimuma yakalanma durumunu bertaraf etmek için MinMax K-Means algoritması olarak isimlendirdikleri yöntemi geliĢtirmiĢlerdir. Önerdikleri yöntemlerinde kümelere, varyans değerlerine göre ağırlıklar atanmakta ve bu ağırlık değerleri hedefe göre optimize edilmektedir. Elde ettikleri deneysel sonuçlar ile önerilen yöntemin doğruluğunu ve etkinliğini göstermiĢlerdir (Tzortzis ve Likas 2014).
Banharnsakun ve ark.(2013)’ları saf yapay arı kolonisi algoritmasına yeni bir yaklaĢım getirerek veri kümeleme üzerine çalıĢmıĢlardır. Önerdikleri bu yeni yaklaĢıma Best-so-far Artificial Bee Colony ismini vermiĢlerdir. Birçok veri kümesi üzerinde yaptıkları deneylerde, önerdikleri yaklaĢımın literatürde kayda geçilmiĢ klasik kümeleme algoritmalarından daha iyi veya eĢ değer sonuçlar elde etmiĢlerdir (Banharnsakun ve ark 2013).
Korürek ve Nizam (2008) QRS komplekslerini gruplandırmak amacıyla Karınca Kolonisi Algoritması (KKA) tabanlı yeni bir kümeleme yaklaĢımı üzerinde çalıĢmıĢlardır. Önerdikleri yeni yaklaĢımlarında, sonuçların doğruluk oranının arttığını ve çalıĢma sürelerinde düĢme görüldüğünü gözlemlemiĢlerdir (Korürek ve Nizam 2008).
Akarsu ve Karahoca (2011) yaptıkları çalıĢmalarında kümeleme ve özellik seçimi problemlerine yeni bir hibrit yaklaĢım önermiĢlerdir. Göğüs kanseri veri kümesini bölümlemek için KKA tekniğini kullanmıĢlardır. Veri kümesinden alakasız veya gereksiz özellikleri ayrıĢtırmak için sıralı geriye arama özellik seçme tekniği kullanmıĢlardır. ÇalıĢmalarının sonucu olarak önerdikleri FS-ACO yönteminin baĢarım oranının diğer filtreleme yaklaĢımlarında daha yüksek olduğunu belirtmiĢlerdir (Akarsu ve Karahoca 2011).
Karaboga ve Ozturk (2011) çalıĢmalarında metasezgisel algoritmalardan Yapay Arı Kolonisi (YAK) Algoritması ve PSO ile beraber literatürde sıklıkla kullanılan bazı sınıflandırma algoritmalarının kümeleme analizindeki baĢarımlarını karĢılaĢtırmıĢlardır. UCI Machine Learning Repository veri ambarından aldıkları veri kümeleri üzerinde yaptıkları deney sonuçlarına göre YAK algoritmasının veri kümeleme probleminde baĢarılı sonuçlar verdiğini gözlemlemiĢlerdir (Karaboga ve Ozturk 2011).
Memetik metasezgisel bir algoritma olan KSA, ilk olarak Eusuff ve Lansey (2003) tarafından su dağıtım Ģebekesi probleminin optimizasyonunda kullanılmıĢtır (Eusuff ve Lansey 2003). Literatüre bakıldığında kurbağa sıçrama algoritmasının farklı alanlarda, saf Ģekilde veya hibrit Ģekillerde kullanıldığı görülmektedir.
Samuel ve Rajan (2015) çalıĢmalarında, hibrit parçacık sürü optimizasyonu tabanlı genetik algoritma ve hibrit parçacık sürü optimizasyonu tabanlı karıĢtırılmıĢ kurbağa sıçrama algoritması kullanarak uzun vadeli jeneratör bakım planlaması sorununa çözüm getirmeyi amaçlamıĢlardır. Aynı problemin çözümü için kullandıkları diğer sezgisel algoritmalar ile önerdikleri yaklaĢımlarının performans kıyaslamalarını yapmıĢlar ve hibrit parçacık sürü optimizasyon tabanlı karıĢtırılmıĢ kurbağa sıçrama algoritmasının, kullandıkları diğer algoritmalardan daha iyi sonuç verdiğini gözlemlemiĢlerdir (Samuel ve Rajan 2015).
Li ve ark.(2015)’ları serbest uzay optik haberleĢme sistemlerindeki türbülans telafi (dengeleme) mekanizmasındaki eksiklikleri gidermek için modifiye edilmiĢ kurbağa sıçrama algoritmasını kullanmıĢlardır. ÇalıĢmadaki simülasyon ve deneysel sonuçlara bakıldığında modifiye edilmiĢ kurbağa sıçrama algoritmasının atmosferik dengelemede iyi sonuçlar verdiği görülmüĢ ve serbest uzay optik haberleĢme sistemlerinin performans verimliliğini arttırılabileceği gözlemlenmiĢtir (Li ve ark 2015). Panda ve ark.(2014)’ları çalıĢmalarında iki ayrı probleme uyarlanmak üzere kurbağa sıçrama algoritmasını kullanmıĢlardır. Ġlk olarak, KSA’yı çok katmanlı yapay sinir ağları algoritmasının eğitim aĢamasında kullanmıĢlardır. KSA’yı çözüm olarak
sundukları diğer problem ise optimizasyon problemi olarak sundukları kanal dengeleme sorunudur. Elde ettikleri sonuçlar baĢarılı olduklarını göstermiĢtir (Panda ve ark 2014).
Luo ve ark.(2014)’ları veri merkezlerinde bulunan sanal makinelerin üzerinde uyguladıkları çalıĢmalarında maksimum seviyede enerji tasarrufu sağlamak için yaptıkları bu çalıĢmalarında, büyük çaplı veri merkezlerindeki kaynak tahsisi problemine çözüm getirmeyi amaçlamıĢlardır. Bu nedenle modifiye edilmiĢ kurbağa sıçrama algoritması ile geliĢtirilmiĢ yüksek optimizasyon kullanılarak dinamik bir tahsis etme yöntemi geliĢtirmiĢlerdir. Elde ettikleri deneysel sonuçlarda, önerdikleri yöntemin enerji tasarrufu sağlama ve çevre dostu olma konularında baĢarılı olduğu gözlemlenmiĢtir (Luo ve ark 2014).
Yüksek gürültü ve dalga çarpıklıkları sebebiyle, dönen makinenin sürtünmeden kaynaklanan arıza kaynağını akustik emisyon kullanarak bulmak oldukça zor olduğunu belirten Cheng ve ark.(2014)’ları bu sorunu aĢmak için yaptıkları çalıĢmalarında KSA kullanarak, wavelet neural network algoritmasının parametrelerini optimize etmeyi hedeflemiĢlerdir. Deneysel sonuçlar KSA kullanımının çalıĢma için basit ve etkin olduğunu, buna karĢın baĢarı oranını yükselttiğini görmüĢlerdir (Cheng ve ark 2014).
Bhattacharjee ve Sarmah (2014) çalıĢmalarında, kurbağa sıçrama algoritmasına yeni bir yaklaĢım getirerek sırt çantası (knapsack) problemini çözmeyi hedeflemiĢlerdir. Önerdikleri yaklaĢımlarının küçük ve orta büyüklükteki sırt çantası problemlerinde çok etkili olduğunu gözlemlemiĢlerdir. Büyük ölçekteki problemlerde ise etkili bir alternatif olabileceğini gözlemlemiĢlerdir (Bhattacharjee ve Sarmah 2014).
Arshi ve ark.(2014)’ları kurbağa sıçrama algoritmasının yakıt yönetim optimizasyonu problemine uygulanmasını çalıĢma konusu edinmiĢlerdir. Farklı reaktörler kullanarak elde ettikleri deneysel sonuçlarında yöntemin nükleer mühendislik alanında ümit verici olduğunu gözlemlemiĢlerdir (Arshi ve ark 2014).
Günümüzdeki bilgi paylaĢım ve bilgiye eriĢim kolaylığından dolayı web uygulamalarındaki bilgi kirliliği ve fazlalığı çeĢitli bilgi filtreleme yaklaĢımlarının geliĢmesine ön ayak olmuĢtur. Geleneksel filtreleme yöntemleri genel olarak kullanıcıların zaman ve mekân özellikleri ile ilgilenmektedir. Mehta ve Banati (2014) çalıĢmalarında demografik (nüfus bilgilerine dayalı) bir filtreleme yöntemi oluĢturmak amacıyla kurbağa sıçrama algoritmasını kullanmıĢlardır. Ġki metodolojiden oluĢan bu önerilmiĢ çalıĢmalarının sonuçlarına bakıldığında, KSA’nın içerik filtreleme konusunda güvenilir sonuçlar veren bir algoritma olduğu görülmüĢtür (Mehta ve Banati 2014).
Baskılı devre kartı derleyicisindeki yüzey montaj makinesinin çalıĢmasını etkileyen önemli faktörlerden biri bileĢen alma ve yerleĢtirme sırasıdır. Zhu ve Zhang (2014) kurbağa sıçrama algoritmasının geliĢtirilmiĢ modelini önererek bu sorunu optimize etmeyi hedeflemiĢlerdir. ÇalıĢmalarını, klasik KSA ve GA performansı ile kıyaslayarak baĢarı oranının yüksek olduğunu buna karĢın önerdikleri algoritmanın çalıĢma zamanı açısından daha yavaĢ olduğunu görmüĢlerdir (Zhu ve Zhang 2014).
Prabha ve Visalakshi (2014) yaptığı çalıĢmalarında kurbağa sıçrama algoritmasını, K-Means algoritması ile birleĢtirerek, K-Means tabanlı bir geliĢtirilmiĢ kurbağa sıçrama algoritması önermiĢlerdir. Kümeleme probleminin analizi için geliĢtirdikleri bu algoritmanın, klasik kümeleme yöntemi olan K-Means algoritması ile kurbağa sıçrama algoritmasının performansından genel olarak daha iyi sonuç verdiğini gözlemlemiĢlerdir (Prabha ve Visalakshi 2014).
Chittineni ve ark.(2011)’ları yaptığı çalıĢmalarında KSA’nın memetik evrim aĢamasında yapılan, en kötü kurbağanın konumunun güncellenmesi bölümünde yeni bir öneride bulunmuĢlardır. Algoritmanın orijinal halinde, yerel en iyi ile global en iyi kurbağanın konumu baz alınarak, yerel en kötü kurbağanın konumu üretildiğinde daha iyi bir sonuç alınmazsa en kötü kurbağa yerine rasgele bir kurbağa üretilerek popülasyona dahil edilir. Önerilen bu algoritmada ise yeni kurbağa üretmek yerine yerel en iyi kurbağanın konumu, en kötü kurbağaya verilerek en kötü kurbağanın konumu bu Ģekilde güncellenmiĢ olmaktadır. Algoritmanın orijinal hali ile önerilen algoritmayı kümeleme problemlerine uygulayarak performans değerlendirmesi yapmıĢlardır. Elde ettikleri sonuçlar önerilen algoritmanın daha baĢarılı olduğunu göstermiĢtir (Chittineni ve ark 2011).
Amiri ve ark.(2009)’ları çalıĢmalarında kurbağa sıçrama algoritması ile bazı metasezgisel algoritmaların kümeleme problemi üzerindeki performanslarını kıyaslamıĢlardır. Elde ettikleri sonuçlar, KSA’nın kümeleme problemlerinde uygulanabilirliğini göstermiĢtir. Performans ölçüm yöntemi olarak toplam karesel hata ölçüsünü kullanmıĢlardır (Amiri ve ark 2009).
3. MATERYAL VE YÖNTEM
3.1. Materyal
Bu çalıĢmada iki tür veri seti kullanılmıĢtır. Algoritmaları test etmek amacıyla belli kurallar çerçevesinde üretilen sentetik veriler (ayrık çember, teğet çember ve teğet küre) ile UCI veri ambarından alınan, online eriĢilebilen veri kümeleri (Balance, Breast Cancer Wisconsin Diagnostic, Breast Cancer Wisconsin Original, Credit, Dermatology, Diabetes, E. Coli, Glass, Heart Disease, Iris, Thyroid ve Wine) üzerinde çalıĢılmıĢtır (UCI 2014).
3.1.1.Sentetik veriler
Algoritmaları test etmek için ilk aĢamada manuel üretilen sentetik veriler üzerine çalıĢılmıĢtır. Ayrık çember, teğet çember (2 boyutlu) ve teğet küre (3 boyutlu) veri setlerinden oluĢan sentetik verilerin özellikleri çizelge 3.1’de gösterilmektedir.
Çizelge 3.1. Sentetik verilerin özellikleri
Veri Seti Örnek Sayısı Nitelik Sayısı Küme Sayısı
Ayrık Çember 80 2 2
Teğet Çember 80 2 2
Teğet Küre 80 3 2
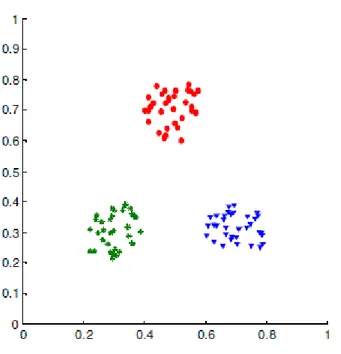
Ayrık çember verisi, merkezleri x-y koordinat düzleminde olan ve birbirini kesmeyecek Ģekilde seçilen iki çemberin içerisinde rastgele noktaların üretilmesiyle elde edilmiĢtir. ġekil 3.1’de ayrık çemberler için rassal üretilen veriler ve küme merkezleri gösterilmektedir.
Teğet çember verisi de benzer Ģekilde x-y koordinat düzleminde, sınırları bir birine teğet olan iki çemberin kapsadığı noktalardan rassal seçilmiĢtir. ġekil 3.2’de teğet çemberler için rassal üretilen veriler ve küme merkezleri gösterilmektedir.
ġekil 3.2. Rassal üretilen teğet çember verisi
Bir diğer veri kümemiz olan teğet küre veri seti 3 boyutlu uzayda, birbirine teğet olan iki kürenin sınır olarak belirlendiği alanlarda rassal seçilmiĢ noktalardan oluĢmaktadır.
3.1.2.Gerçek veriler
Sentetik veriler üzerinde algoritmanın çalıĢması test edildikten sonra literatürde kabul görmüĢ online eriĢilebilir olan UCI veri ambarından alınan ve literatürde sıklıkla kullanılan veri setleri üzerinde çalıĢılmıĢtır. Eksik veri içeren örnekler veri setlerinden kaldırılmıĢ ve iĢlenmemiĢtir. Kullanılan veri kümeleri ve özellikleri çizelge 3.2’de gösterilmiĢtir. (*) ile iĢaretlenmiĢ veri setlerinde eksik veri bulunmaktadır.
Balance: Psikolojik deneysel sonuçlarını modellemek için kullanılan bu veri setinde 4 nitelik ve 3 sınıf vardır. Sağ ve sol ağırlık ile sağ ve sol uzaklık değerlerini nitelik olarak kullanan veri setinde sınıf değerleri sağa yatkın (scale tip to the right), sola yatkın (scale tip to the left) ve dengeli (balanced) ölçüm olarak kullanılmaktadır. Veri kümesi, dengeli sınıfında 49 adet, sola yatkın sınıfta 288 adet ve sağa yatkın sınıfında da 288 adet örnek olmak üzere toplamda 625 örnekten oluĢmaktadır.
Breast Cancer Wisconsin - Diagnostic: Hastalık bölgesindeki tümörlü alanın özellikleri sınıflandırmada nitelik olarak kullanılmaktadır. Örneğin: tümörlü bölgenin kalınlığı, tümörlü hücrelerin Ģekil ve büyüklük olarak birbirine benzemesi oranı, tümörün vücuda yapıĢma oranı gibi özellikler. Bu özelliklerin kullanılması ile tümörün iyi huylu veya kötü huylu olması sonucu elde edilir. 30 nitelikten oluĢan bu veri setinde
2 sınıf bulunmaktadır. Veri kümesi, Benign sınıfında 357 ve Malignant sınıfında 212 adet olmak üzere toplam 569 örnekten oluĢmaktadır.
Breast Cancer Wisconsin - Original: Breast Cancer Wisconsin Diagnostic veri seti ile nitelik bakımından benzer özelliklerde olan bu veri setinde 9 adet nitelik ve 2 adet sınıf (Benign, Malignant) bulunmaktadır. Veri kümesi, Benign sınıfında 458 ve Malignant sınıfında 241 adet olmak üzere toplam 699 örnekten oluĢmaktadır. Bu veri setinde eksik olan 16 örnek veri setinden çıkarılmıĢtır.
Credit: Avustralya kredi kartı veri setinden alınan bu veri setinde 51 nitelikten 14 tanesi kullanılmıĢtır. Niteliklerden 6 tanesi sayısal ve 8 tanesi kategoriktir. 2 sınıfa sahip olan bu veri setinde, 1.sınıfa ait 383 ve 2.sınıfa ait 307 örnek olmak üzere toplamda 690 adet örnek bulunmaktadır.
Dermatology: Ciltte oluĢan kızarıklık, sertleĢme, kaĢıntı, yumuĢama, kepeklenme, çatlama; kafa derisi, diz ve el dirseklerinde hastalığın görülme düzeyi gibi medikal özellikleri nitelik olarak kullanılmaktadır. Veri setinde 34 nitelik ve 6 sınıf vardır. Veri seti, Psoriasis sınıfından 112, Seboreic Dermatitis sınıfından 61, Lichen Planus sınıfından 72, Pityriasis Rosea sınıfından 49, Cronic Dermatitis sınıfından 52 ve Pityriasis Rubra Pilaris sınıfından 20 adet olmak üzere toplamda 366 örnekten oluĢmaktadır.
Diabetes: Bilgilerinin tamamı bayan hastalardan alınan bu veri setinde 8 adet nitelik ve 2 adet sınıf mevcuttur. Hastanın; hamile kalma sayısı, plazmadaki glükoz yoğunluğu, küçük tansiyon değeri, kol kasları deri kalınlığı, vücut kitle indeks değeri ve yaĢ gibi özellikleri nitelik olarak kullanılmaktadır. Veri seti toplamda 768 hastanın bilgilerinden oluĢmaktadır.
Escherichia Coli (E. coli): Bu veri setinde normalde 7 nitelik, 8 sınıf ve 336 adet örnek bulunmaktadır. Ancak sınıflardan 3 tanesi sırasıyla 2, 2 ve 5 adet örnek içermektedir. Bu nedenle bu 3 sınıf yapılan çalıĢmada kullanılmamıĢtır. DeğiĢikliklerden sonra veri setindeki sınıf sayısı 5 ve örnek sayısı 327 olarak belirlenmiĢtir.
Glass: Cam tiplerini belirten 6 adet sınıftan oluĢan bu veri setinde 9 nitelik ve 214 örnek bulunmaktadır. Camın yapısındaki sodyum, magnezyum, alüminyum, silikon, potasyum, baryum, kalsiyum, demir gibi elementlerin kullanım miktarlarını nitelik olarak kullanmaktadır. Cam tipi olarak kullandığı sınıflar, building windows float, building windows non-float, vehicle windows float, containers, table ware ve head lamps olarak belirlenmiĢtir.
Heart Disease: Veri seti normalde 75 nitelik bulunmaktadır; ancak genel olarak sınıflandırma çalıĢmalarında bunlardan 14 tanesi (1 tanesi sınıf özelliği olmak üzere) kullanılmaktadır. Bu çalıĢmada da 13 nitelik olarak değerlendirilmiĢtir. 2 adet sınıftan oluĢan bu veri setinde toplamda 303 örnek mevcuttur. Bu veri setinde 6 adet kayıt eksik veri içerdiğinden iĢleme alınmamıĢtır.
Iris: Ġris bitkisinin çanak ve taç yapraklarının uzunluk ve geniĢlik gibi bilgilerini nitelik olarak kullanır. Sınıf olarak iris bitkisinin üç türü olan Iris Setosa, Iris Versicolour ve Iris Virginica değerlerini kullanır. Bu veri setinde 4 nitelik ve 3 sınıf vardır. Iris Setosa, Iris Versicolour ve Iris Virginica sınıflarının her birinde 50’Ģer olmak üzere toplam 150 örnekten oluĢmaktadır.
Thyroid: RT3U (tiroid hormonlarını birbirine bağlayan uçların ölçümü) testinden elde edilen değerler ile öz sıvıdaki bazı değerlerin özellik olarak kullanılması ile hastanın normal olduğu, yüksek veya düĢük derecede tiroit hastalıklı olduğu tahmini için kullanılan veri kümesidir. Veri setinde 5 nitelik ve 3 sınıf vardır. Normal sınıfında 150, Hyper sınıfında 35 ve Hypo sınıfında 30 adet olmak üzere toplam 215 örnekten oluĢmaktadır.
Wine: ġarap türlerini sınıf olarak kullanan bu veri setinde 3 sınıf sayısı ve 13 nitelik bulunmaktadır. ġarap verilerini barındıran bu veri seti toplamda 178 örnekten oluĢmaktadır.
Çizelge 3.2. ÇalıĢmada kullanılan veri setleri
Veri Seti Örnek Sayısı Nitelik Sayısı Küme Sayısı
Balance 625 4 3
Breast Cancer W. Diagnostic 569 30 2
Breast Cancer W. Original* 699 9 2
Credit 690 14 2 Dermatology 366 34 6 Diabetes 768 8 2 E. Coli 327 7 5 Glass 214 9 6 Heart Disease* 303 13 2 Iris 150 4 3 Thyroid 215 5 3 Wine 178 13 3
Normalizasyon: Normalizasyon, istatistiksel veri iĢleme alanlarında, veriler arasındaki farklılığın büyük ölçülerde olduğu durumlarda, verileri birbirine yaklaĢtırmak ve tek bir düzen içerisine almak amacıyla uygulanan bir yöntemdir. Bu Ģekilde veriler birbirine yaklaĢtırılarak aykırı olan değerlerin, çalıĢmanın sonucunu
etkilemesinin önüne geçilmesi amaçlanır. Sınıflandırma ve kümeleme iĢlemlerinde veriler genellikle belli bir aralıkta normalize edilir. Verilerin normalize edilmesi için kullanılan farklı yöntemler vardır. Bu çalıĢmada kullanılan verilerin normalize edilmesi aĢamasında Min-Max normalizasyonu yöntemi kullanılmıĢtır. Bu normalizasyon yönteminde veriler belirlenen aralıklar arasında yeni değerlerini almaktadır. EĢitlik (3.1) bir verinin normalize edilmiĢ değerinin nasıl hesaplandığını göstermektedir (Han ve ark 2006).
nMax nMin
nMin X X X X nX min max min (3.1)Burada X normalize edilecek değer, nX normalizasyon iĢleminden sonra X’in alacağı değer, minX normalize edilecek değerlerin en küçük (minimum) olanı, maxX normalize edilecek değerlerin en büyüğü (maksimum), nMax yeni maksimum değer yani verilerin normalize edileceği üst sınır, nMin yeni minimum değerdir. Bu çalıĢmada veriler [0, 1] aralığında normalize edilmiĢtir. Yani nMin=0 ve nMax=1 olarak belirlenmiĢtir. Bu durumda eĢitlik (3.1) güncellenerek eĢitlik (3.2) Ģeklinde özetlenerek kullanılmıĢtır.
X X X X nX min max min (3.2) 3.2.Kümeleme
Kümeleme, sınırları belirlenmemiĢ bir veri (nesne) topluluğunu, verilerin birbiri ile olan benzerliklerine göre gruplara ayırmaktır. Bu ayrıĢtırma (gruplandırma) iĢlemi sayesinde, veriler yapılacak sonraki çalıĢmalarda araĢtırmacılar için kolayca kullanılabilecek bir hale dönüĢtürülür. Kümeleme iĢlemi, doğal gruplar Ģeklinde bulunan verileri, daha belirleyici alt kümelere (gruplara) ayırmaktadır (Tatlıdil 1996, Özdamar 1999).
Kümelemede temel amaç homojen (benzer) nesnelerin bir araya getirilerek heterojen (birbirinden uzak, farklı) gruplar oluĢturulmasıdır. Bu Ģekilde verilerin incelenmesi aĢamasında minimum bilgi kaybı ile veriler gruplandırılmaktadır. Kümelenecek nesneler, karakteristik özellikleri kullanılarak gruplandırma iĢlemine tabi tutulur. Aynı gruba düĢecek nesnelerin birbiri ile maksimum seviyede benzer olması istenirken, farklı gruptaki nesnelerin de birbirinden yapı olarak maksimum seviyede
farklı olması istenmektedir (Lorr 1983, Hair ve ark 1998). ġekil 3.3’de görüldüğü gibi aynı küme içindeki nesneler birbirine çok yakın iken, kümelerin birbiri ile olan uzaklığı ise oldukça fazladır.
ġekil 3.3. Nesneler ve kümeler arası uzaklık
Kümeleme analizi olarak da isimlendirilen kümeleme iĢleminin öncelikli hedefi, belli bir örnek, nesne veya nokta topluluğu için doğal grup sınırlarını belirlemektir (Jain 2010).
Kümelemede ilk aĢama, nesneler arası benzerlik veya farklılık anlamına gelen uzaklığın hesaplanmasında kullanılacak olan uzaklık ölçütünün seçilmesidir. Daha sonra kullanılacak kümeleme yöntemi (hiyerarĢik veya hiyerarĢik olmayan), kullanım amacına göre belirlenir. Üçüncü adımda seçilen kümeleme yöntemi için kullanılacak olan kümeleme algoritması seçilir. Son aĢamada ise küme sayısı belirlenerek kümelemede elde edilen sonuç üzerinde değerlendirme yapılır (Sharma 1996).
Ball, verilerin kullanım amacına ve kullanım alanlarına göre kümelemenin amaçlarını aĢağıdaki gibi belirlemiĢtir (Ball 1970):
- Doğru tiplerin belirlenmesi - Model oluĢturmak
- Hipotez testi - Veri araĢtırma
- Veri indirgeme - Hipotez oluĢturma
Kümeleme, nesnelerin aynı grupta ise birbiri ile benzer, farklı gruplarda ise birbirlerinden farklı olması durumunu esas almaktadır. Nesnelerin birbiri olan iliĢkisini daha iyi anlatabilmek için benzerlik ve benzersizlik (farklılık) kavramları kullanılmaktadır. Ġki nesnenin benzerliği ne kadar fazla olursa, o iki nesne arasındaki iliĢki o kadar kuvvetlidir demektir. Bu durumda iliĢkinin zayıf olduğu durumlarda nesneler arasındaki farklılık yüksektir denilebilir. Nesneler arasındaki benzerlik ve farklılık değerleri farklı metotlarla ölçülebilir. Benzerlik ve farklılık değerleri kullanılarak nesnelerin ayırt ediciliği daha net sınırlarla belirlenip gruplara daha rahat ayrıĢtırılabilir. Nesneler arasındaki benzerlik değerinin ölçülmesinde kullanılan metodun seçilmesinde, nesnelere ait özelliklerin veri tipleri etkili olur. Bir nesneye ait özelliğin aldığı değerlerin sayısı sonlu ise bu veri tipi kesikli (discrete) veri kategorisine dâhil olur. Ancak nesnenin özelliği birden çok aralıkta, o aralıklardaki her değeri alabiliyorsa sürekli (continuous) veri kategorisine girer (Doğan 2002, Servi 2009).
3.2.1. Kümelemede kullanılan uzaklık metotları
Verilerin sürekli veya kesikli olması, seçilen ölçme yönteminin belirlenmesinde etkili olmaktadır. Literatürde, uzaklık ölçme yöntemi olarak sıklıkla kullanılan bazı metotlar aĢağıda verilmiĢtir.
3.2.1.1. Sürekli veriler için uzaklık metotları
Her biri n adet özellikten (nitelik) oluĢan, xi ve xj gibi iki nesne arasındaki
uzaklığın hesaplanmasında kullanılan bazı metotlar aĢağıdaki gibi ele alınmaktadır. Öklid (Euclidean) uzaklığı
En yaygın olarak kullanılan yöntemlerden olan Öklid uzaklık metodu, belirlenen iki nokta (nesne) arasındaki doğrusal uzaklığı hesaplar. Öklid uzaklık metodu ile iki nesne arasındaki uzaklık, eĢitlik (3.3)’e göre hesaplanır.
n kx
x
ik jk j i d 1 2)
(
, (3.3)d(i, j): i. ve j. nesnenin birbirine uzaklığı xik: i. nesnenin k. niteliğinin değeri
xjk: j. nesnenin k. niteliğinin değeri
i = 1, 2, …, N j = 1, 2, …, N
N: Veri setindeki toplam nesne sayısı.
Manhattan uzaklığı
Manhattan uzaklık bulma yönteminde nesneler arasındaki mutlak uzaklık değeri ele alınır. Literatürde City-Block yöntemi olarak da bilinir. Manhattan uzaklık metodunda nesneler arasındaki uzaklık, eĢitlik (3.4)’e göre hesaplanır.
i j
xi xj xi xj xin xjn
d , 1 1 2 2 (3.4)
d(i, j): i. ve j. nesnenin birbirine uzaklığı xi: Veri setindeki i. nesne
xj: Veri setindeki j. nesne
Minkowski uzaklığı
Minkowski metodu kullanılarak iki nesne arasındaki uzaklık, eĢitlik (3.5)’e göre hesaplanır.
m m jn in m j i m j i x x x x x x j i d 1 2 2 1 1 , (3.5)d(i, j): i. ve j. nesnenin birbirine uzaklığı xi: Veri setindeki i. nesne
xj: Veri setindeki j. nesne
Minkowski yönteminde m değeri 1 seçilirse formül, Manhattan uzaklık metodu formülüne, m değeri 2 seçilirse Öklid uzaklık metodu formülüne dönüĢür. Bu açıdan değerlendirildiğinde Minkowski metodunun, Manhattan ve Öklid metotlarının genel formu olduğu söylenebilir.
Pearson uzaklığı
Pearson uzaklık metodu kullanılarak iki nesne arasındaki uzaklık eĢitlik (3.6) ile bulunur. Bu eĢitlikte kullanılan Sk değeri, uzaklığın hesaplandığı nesneye ait varyanstır.
2
2 2 2 2 2 2 1 2 1 1 ,j xi xj S xi xj S xin xjn Sn i d (3.6)d(i, j): i. ve j. nesnenin birbirine uzaklığı xi: Veri setindeki i. nesne
xj: Veri setindeki j. nesne
Yukarıda verilen ve mesafe ölçmek için yaygın olarak kullanılan uzaklık bulma metotları değiĢken değerlerinin sürekli olması durumunda uygulanmaktadır (Tatlıdil 1996, Doğan 2002).
3.2.1.2. Kesikli veriler için uzaklık yöntemleri
DeğiĢkenlerin kesikli olması durumunda sürekli verilerin kümelenmesinde kullanılan eĢitliklere, eĢitlik (3.7) ile hesaplanan wt katsayısı eklenmektedir. EĢitlik
(3.7)’deki dt değeri, t. değiĢkenin dağılım aralığını ifade etmektedir (Tatlıdil 1996).
nitel veriler için için veriler nicel
d
w
t t 1 , , 1 (3.7) 3.2.2. Kümeleme AlgoritmalarıKümeleme algoritmalarını, hiyerarĢik ve hiyerarĢik olmayan kümeleme algoritmaları Ģeklinde iki ana baĢlığa ayırabiliriz. Kümeleme algoritmalarının genel anlamda kategorize edilmesi Ģekil 3.4 ile gösterilmiĢtir.
ġekil 3.4. Kümeleme algoritmaları (Selim 2014)
3.2.2.1. HiyerarĢik kümeleme algoritmaları
HiyerarĢik kümeleme algoritmalarında, belirli adımlardan geçerek kümelere ayrılan nesnelerin, kümeler için aidiyet düzeyleri bulunur. Bu aidiyet ölçüsü de benzerlik veya farklılık özelliklerinden elde edilir. HiyerarĢik kümeleme algoritmaları temel olarak iki grupta incelenebilir: Toplamalı (yığılmalı) hiyerarĢik kümeleme ve bölünmeli hiyerarĢik kümeleme algoritmaları.
Toplamalı hiyerarĢik kümeleme algoritmalarındaki temel yaklaĢım veri setindeki her bir nesne bir küme olarak alınır ve bu veriler farklı aĢamalardan geçip birbirine bağlanarak küme sayısı düĢürülür. Bölünmeli hiyerarĢik kümeleme algoritmalarında ise, toplamalı hiyerarĢik kümeleme algoritmalarından farklı olarak veri setindeki tüm nesnelerin bir grup oluĢturduğu kabul görülür. Ġlk aĢamada tek grupta toplanan bu veriler belli baĢlı adımlardan geçerek farklı kümelere ayrılır (Lorr 1983, Tatlıdil 1996).
Ġlk aĢamada küme sayısı belli olmayan hiyerarĢik kümeleme algoritmalarında, küme sayısına görsel analizler kullanılarak karar verilir. HiyerarĢik tekniklerin ağaç diyagramları ile gösterilen sonuçlarına dendogram adı verilir (Lorr 1983, Everitt ve Dunn 1992).
HiyerarĢik kümeleme algoritmalarından bazıları: Tek bağlantı algoritması, Tam bağlantı algoritması, Ortalama bağlantı algoritmasıdır.
Tek bağlantı algoritması
Sonuçları bir ağaç diyagramında gösteren bu algoritma ilk olarak Florek ve arkadaĢları tarafından uygulanmıĢtır. Tek bağlantı algoritması nesnelerin birbirine göre mesafelerini bulmak için uzaklık veya benzerlik matrisinden yararlanır. Bu matrisleri kullanarak birbirine en yakın iki nesne veya küme birleĢtirilmekte ve birleĢtirme iĢlemi yinelenmektedir. BirleĢtirme iĢleminde benzerlik (sk) ve uzaklık (dk) değerleri sırasıyla
eĢitlik (3.8) ve (3.9) ile elde edilir (Everitt ve Dunn 1992, ġentürk 1995).
( ) ( ) (3.8)
( ) ( ) (3.9)
Tam bağlantı algoritması
Benzerlik veya uzaklık matrisinden yararlanarak en yakın iki nesne veya kümeyi birleĢtiren bu algoritma, tek bağlantı algoritmasının tersi olarak çalıĢmaktadır. Bu algoritmanın en önemli dezavantajı aynı kümeye ait nesnelerin arasındaki uzaklığın belirli bir küçüklükte olması durumunda sağlıklı sonuç vermeyebilmesidir. BirleĢtirme iĢleminde benzerlik (sk) değeri eĢitlik (3.10), uzaklık (dk) değeri eĢitlik (3.11)
kullanılarak elde edilir (Tatlıdil 1996).
( ) ( ) (3.10)
( ) ( ) (3.11)
Ortalama bağlantı algoritması
Sokal ve Michener tarafından önerilen bu algoritmada, iki kümeden alınan birer çift nesne arasındaki ortalama fark iki küme arasındaki fark olarak alınır. Farklı türleri bulunan bu algoritmanın, en yaygın olarak kullanılan türünde, nesne çiftlerinin arasındaki uzaklığın aritmetik ortalaması hesaplanmaktadır (Everitt 1974, Fırat 1997).
3.3.2.2. HiyerarĢik olmayan kümeleme algoritmaları
HiyerarĢik kümeleme algoritmalarının aksine kümeleme iĢlemine baĢlamadan önce anlamlı bir küme sayı belirlenmiĢ ise hiyerarĢik olmayan kümeleme algoritmaları kullanılabilir. Nesnelerin ayrıĢtırılacağı küme (grup) sayısı belirlendikten sonra küme belirleme kriterlerine göre hangi nesnenin hangi kümeye ait olduğuna karar verilir ve atama iĢlemleri gerçekleĢtirilir (Everitt ve Dunn 1992, Tatlıdil 1996).
HiyerarĢik olmayan kümeleme algoritmaları, eldeki nesnelerin belirlenen küme sayısına (k) bölünmesi amacıyla tasarlanmıĢtır. Küme sayısı (k) herhangi bir değer olarak belirleneceği gibi kümeleme algoritmasının bir parçası olarak da belirlenebilir. HiyerarĢik olmayan algoritmalar, hiyerarĢik algoritmalara göre daha hızlı olduğundan daha büyük veri kümeleri üzerinde uygulanabilir (Anderberg 1973, Johnson ve Wichern 1998).
HiyerarĢik olmayan kümeleme algoritmalarında k küme sayısını belirlemek oldukça önemli bir problemdir. Sağlıklı bir sonucun elde edilmesi doğru küme sayısının seçimi ile doğrudan iliĢkilidir. Küçük çaptaki verilerin kümelenmesinde k küme sayısı sıklıkla eĢitlik (3.12) ile bulunur (Atamer 1992).
√ (3.12)
EĢitlik (3.12)’de n, kümelenecek nesne sayısını temsil etmektedir.
K-Means kümeleme algoritması
HiyerarĢik olmayan kümeleme algoritmaları içerisinde en çok kullanılan K-Means kümeleme algoritması 1967 yılında J.B. MacQueen tarafından geliĢtirilmiĢtir (MacQueen 1967). K-Means kümeleme algoritmasının, küme merkezi hesaplama iĢleminde genellikle karesel hata toplamı (Sum Squared Error - SSE) kullanılır. SSE değerinin minimum olması istenen durumdur. En düĢük SSE değerine sahip kümeleme sonucu en iyi sonuçtur prensibine dayanır. Algoritma temel olarak nesnelerin bağlı oldukları küme merkezine olan karesel uzaklıklarının minimum olması esasına dayanmaktadır. K-Means kümeleme yöntemi her nesnenin sadece bir kümeye (gruba) ait olduğu fikrini benimser. Bu açıdan ele alındığında K-Means’in oldukça keskin bir kümeleme algoritması olduğu söylenebilir. Her küme için bulunan küme merkezi, o kümeyi direkt olarak temsil etmektedir (Han ve ark 2006, Tan ve ark 2006).
K-Means algoritması N adet nesneyi k tane kümeye bölme prensibine dayanır. Burada k tane kümenin, küme merkezlerinin birbirinden uzak olması ve küme içi nesnelerin birbirine yakın olması hedeflenir. Küme benzerliği kümedeki nesnelerin küme merkezine olan ortalama uzaklık değeri ile ölçülür ki bu da kümenin ağırlık merkezini verir. Bir küme içindeki nesnelerin merkeze olan karesel uzaklıklarının küçük olması o küme merkezinin iyi seçildiği anlamına gelmektedir (Xu ve Wunsch 2005).
N adet nesneden oluĢan ve k adet kümeye ayrılacak bir veri seti olduğu kabul edildiğinde; mi, Ci kümesinin merkez noktası ve x, Ci kümesine ait bir nesne olmak
üzere tüm kümelerin karesel hata toplamı değeri eĢitlik (3.13) ile hesaplanır.
m x
dist SSE i K i x Ci , 1 2
(3.13)Karesel hata toplamı değerinin minimize edilmesi K-Means algoritmasının temel hedefidir. K-Means algoritmasının dezavantajlarından bir tanesi verinin bölüneceği küme sayısının belirlenmesi iĢleminin bir standardının olmamasıdır (Jain 2010).
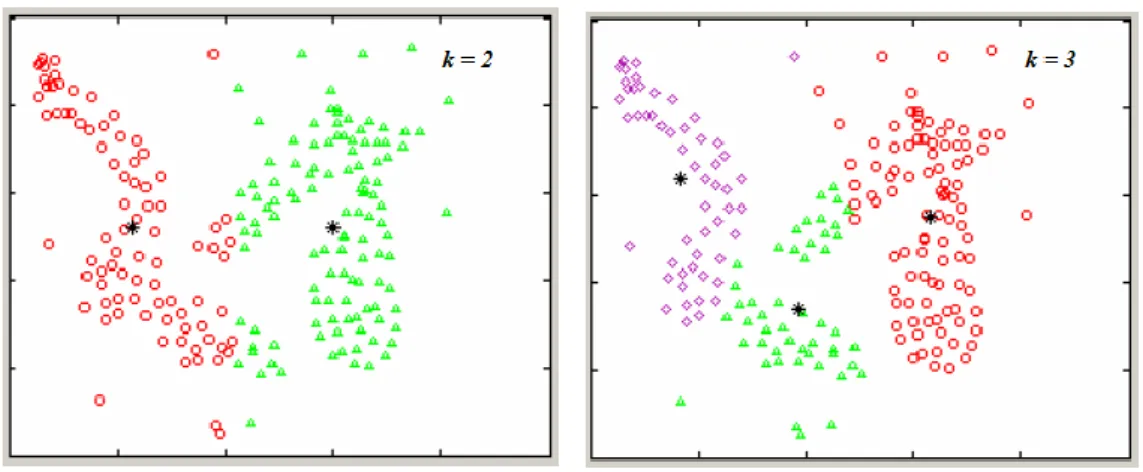
ġekil 3.5. Farklı k değerleri için kümeleme sonucu
Aynı veri seti için farklı k küme sayısı seçildiğinde sonuçlar da farklı olacaktır. ġekil 3.5’te k=2 ve k=3 seçildiğinde verilerin nasıl kümelendiği gözlemlenebilir.
Velmurugan (2014) yaptığı çalıĢmasında K-Means algoritmasını temel olarak aĢağıdaki adımlarla tanımlamıĢtır (Velmurugan 2014):
1. Her bir küme için küme merkezini temsil edecek bir nokta seçilir. 2. Veri kümesine ait her nesne için en yakın olduğu küme bulunur. 3. Her küme için küme merkezleri tekrar hesaplanarak güncellenir.
4. Küme merkezleri belirlenen hata payı kadar değiĢmeyene ve ya belirlenmiĢse iterasyon sayısı sonlanana kadar 2 ve 3.adımlar tekrarlanır. ġekil 3.6’da herhangi bir kümeleme tekniğine tabi tutulmayan verilerin grafiksel dağılımları görülmektedir.
ġekil 3.6. Kümeleme iĢlemine tabi tutulmayan orijinal veri
Bu verilere K-Means kümeleme tekniği uygulandıktan sonra (k küme sayısı = 3 seçildiğinde) Ģekil 3.7’deki gibi kümelendiğini görebiliriz.
ġekil 3.7. K-Means uygulanmıĢ verilerin dağılımı (k = 3 olarak seçilmiĢtir)
K-Means kümeleme algoritması, literatürde sıklıkla kullanılan bir algoritma olmasının yanında oldukça hızlı ve basit bir yapısı vardır. Genel olarak baĢarılı sonuçlar elde etmesine rağmen bu baĢarısı seçilen baĢlangıç konumuna yüksek derece bağlıdır. BaĢlangıç noktasının olası bazı noktalarda seçilmesi, algoritmanın yerel optimuma yakalanması sonucuna sebep olabilmektedir. Bu durum K-Means algoritmasının dezavantajlarının baĢında gelmektedir (MacQueen 1967).
K-Medoids kümeleme algoritması
Ġlk olarak Kaufman ve Rousseeuw tarafından 1987 yılında ortaya konulan bu algoritmada, kümelenecek nesnelerin küme merkezi sayılan nokta medoid olarak adlandırılır. Diğer hiyerarĢik olmayan kümeleme algoritmaları gibi K-Medoids algoritması da temelde N adet nesneyi k adet kümeye, nesnelerin benzerlik ve farklılıklarına göre ayrılmasını hedefler (IĢık ve Çamurcu 2007).
K-Medoids algoritması, bir diğer hiyerarĢik olmayan kümeleme algoritması olan K-Means algoritması ile oldukça benzer bir yapıya sahiptir. ĠĢlem aĢamaları olarak birbirine çok benzeyen bu iki algoritmanın ayrıldığı nokta baĢlangıçtaki küme merkezlerinin seçimi bölümüdür. K-Means algoritmasında rasgele veya keyfi olarak seçilen küme merkezleri, K-Medoids algoritmasında verilerden seçilir. Yani k adet kümenin merkezlerini temsil etmek üzere k adet veri medoid (küme merkezi) olarak seçilir. BaĢlangıç aĢamasında keyfi olarak seçilen bu medoidler, her çalıĢtırılmada farklı olabileceği için algoritmanın farklı sonuçları vermesi muhtemeldir. K-Medoids algoritması aĢağıda verilmiĢtir (Selim 2014):
1) N adet nesneden k adet medoid seçilir.
2) Geriye kalan nesneler seçilen medoidlere göre kümelere ayrılır. 3) Medoid olmayan nesnelerden biri rasgele seçilir.
4) 3. adımda rasgele seçilen nesne medoid olarak kabul edilir ve diğer nesnelerin bu nesneye olan uzaklıkları hesaplanır.
5) Eğer seçilen bu nesne esas medoide göre daha iyi sonuç verirse yeni medoid olarak atanır.
6) 2. ve 5. adımlar belli bir değiĢim olmayana kadar devam ettirilir.
3.2.3.Kümeleme sonuçlarının değerlendirilmesinde kullanılan yöntemler
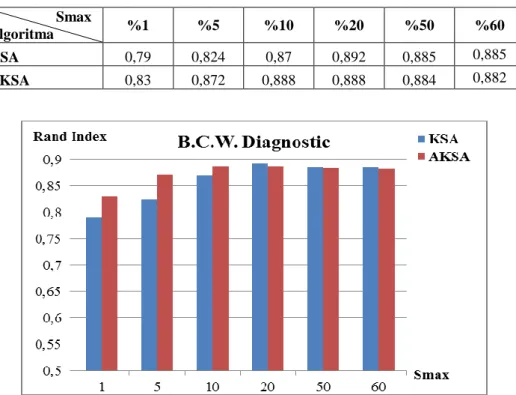
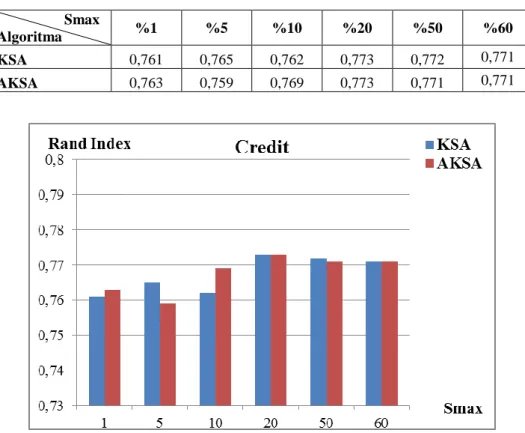
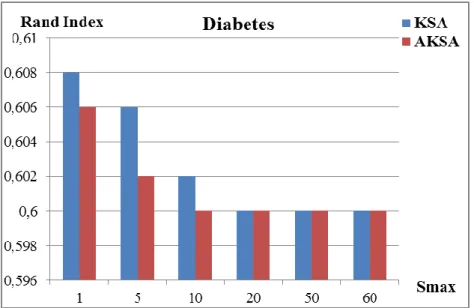
Kümeleme analizinde alınan sonuçların değerlendirilmesi için farklı yöntemler kullanılmaktadır. Kullanılan veri türüne, seçilen kümeleme yöntemine göre yöntemler belirlenmektedir. Bu çalıĢmada KSA’nın orijinal hali ile önerilen KSA’nın sonuçlarını değerlendirmek ve kıyaslamak için Rand Index Ölçüm (RI), Toplam Karesel Uzaklık (TKU) ve TKU yakınsama değerleri kullanılmıĢtır.
3.2.3.1.Rand index ölçüm yöntemi
N adet nesneden oluĢan ve k tane kümeye bölünecek olan bir veri setinde, gerçek küme bilgileri bilinen nesneler E (Expected) ve kümeleme iĢlemine tabi tutulduktan sonra nesneler O (Obtained) ile temsil edilsin. Veri setindeki her nesne, kendisi hariç geriye kalan tüm nesneler için bu kıyaslamaya tabi tutulur. i, j = 1,2,…,N olmak üzere veri setindeki her xi ve xj nesne çiftinin, E ve O durumlarında birbirine göre 4 farklı
durumu vardır.
1. xi ve xj nesne çiftinin O durumunda aynı kümeye dâhil olması ve E
durumunda da bu nesne çiftinin aynı kümede olması.
2. xi ve xj nesne çiftinin O durumunda aynı kümeye dâhil olması ve E
durumunda da bu nesne çiftinin farklı kümelerde olması.
3. xi ve xj nesne çiftinin O durumunda farklı kümelere dâhil olması ve E
durumunda da bu nesne çiftinin aynı kümede olması.
4. xi ve xj nesne çiftinin O durumunda farklı kümelere dâhil olması ve E
durumunda da bu nesne çiftinin farklı kümelerde olması.
Veri setindeki xi ve xj nesne çiftlerinin yukarıdaki 4 durum için elde edilen
eĢleĢme sayıları sırasıyla a, b, c ve d ile gösterilsin. Yukarıdaki 4 durumun elde edilen toplam sayıları M ile gösterilsin. Bu durumda M = a + b + c + d ile elde edilir. RI, kümeleme sonucu elde edilen Rand Index değeri eĢitlik (3.14) ile hesaplanır.
M d a
RI ( ) (3.14)
Rand Index değeri [0, 1] aralığında değerler alır. RI değeri bire yaklaĢtıkça E ve O durumlarının birbirine benzerliği artmaktadır. Bu durum kümelemenin iyi yapıldığını göstermektedir (Rand 1971, Servi 2009).
3.2.3.2.Toplam karesel uzaklık yöntemi
Küme merkezi tabanlı kümeleme algoritmalarında kümeye ait nesnelerin toplam uzaklıklarının minimize olması istenilen bir durumdur. Bu hedef doğrultusunda küme merkezinin, kümeye ait nesnelere olan karesel uzaklık değerinin minimize edilmesi optimizasyon problemi olarak düĢünülebilir. Toplam karesel uzaklık değeri ne kadar küçük olursa küme merkezi o kadar iyi belirlenmiĢtir denilebilir (Wan ve ark 2012).
Küme merkezleri ile nesneler arasındaki mesafenin hesaplanmasında kullanılan yöntemler bölüm 3.2.1’de anlatılmıĢtır. Bu çalıĢmada küme merkezleri ile kümeye ait nesneler arasındaki mesafenin hesaplanması için eĢitlik (3.3) ile hesaplanan Öklid uzaklığı kullanılmıĢtır. Seçilen farklı maksimum adım büyüklüğü (Smax) değerleri ile
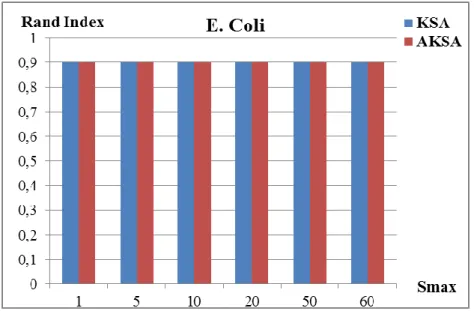
KSA ve AKSA’nın performansı elde edilen toplam karesel uzaklık değerleri ile kıyaslanmıĢtır.
3.2.3.3.Yakınsama değeri
Ġteratif olarak çalıĢan algoritmalar, her iterasyon adımı sonucunda maliyet fonksiyonunu en iyi çözüme ulaĢacak Ģekilde güncellemektedir. Üzerinde çalıĢılan problem maksimizasyon veya minimizasyon problemi olabilir. Maliyet fonksiyonunun değeri maksimizasyon problemleri için sürekli yükselerek çözüme doğru gitmeyi hedeflerken minimizasyon problemlerinde ise sürekli azalarak çözüme gitmeyi hedeflemektedir. Optimizasyon algoritmalarının yerel minimuma yakalanmadan sonuca daha hızlı gitmesi istenilen bir durumdur (Acılar 2013).
Bu çalıĢmada maliyet fonksiyonu olarak kullanılan Öklid uzaklığının her iterasyon sonucu elde edilen uygunluk değeri temel alınarak KSA ve AKSA’nın sonuca yakınsama gözlemleri yapılmıĢtır. Böylece algoritmaların sonuca gitme hızları hakkında bilgi elde edilmiĢtir.
3.3.Kurbağa Sıçrama Algoritması (KSA)
Kurbağa Sıçrama Algoritması (KSA), ilk olarak 2003 yılında Eusuff ve Lansey tarafından su dağıtım Ģebekesi probleminin optimizasyonu için kullanılmıĢtır (Eusuff ve Lansey 2003).
Genetik bilimindeki gen kavramının, kültürel ve sosyal anlamda mem kavramına denk olduğu söylenebilir. Bireyin sahip olduğu kalıtsal özellikler genler ile aktarıldığı gibi sosyal hayatta sahip olduğu deneyim ve davranıĢlar da memler vasıtasıyla baĢkasına aktarılabilmektedir. Memler, taklit adı verilen süreçler yoluyla, bireyler arasında aktarılmakta ve yayılabilmektedirler. Genetik biliminde nesiller arasında iyi genler nasıl aktarılıyor ise, mem düzeyinde de iyi fikirlerin bireyler arasında daha fazla yayılması söz konusu olabilmektedir. Memetik bir optimizasyon algoritması olan kurbağa sıçrama algoritması, kurbağa topluluğunun maksimum miktarda besine, minimum hareketle ulaĢması için yaptıkları hareketleri model alır. Topluluktaki kurbağaların tamamı algoritmanın popülasyonunu oluĢtururken, popülasyondaki her
kurbağa bir çözümü temsil eder. Algoritmada belirlenen kısıt ve değiĢkenlere göre her bireyin (kurbağanın) bir uygunluk değeri olacaktır. Bu değer her bireyin besine olan yakınlık derecesidir. Algoritmada öncelikli olarak rastgele bir kurbağa popülasyonu oluĢturulur. Daha sonra popülasyon uygunluk değerlerine göre sıralı bir Ģekilde gruplara (mempleks) ayrılır. Bu gruplar içerisinde her bir kurbağa grubu birbirinden bağımsız olarak belirli bir iterasyon sayısınca memetik evrime tabi tutulur. Memetik evrim aĢaması, popülasyondaki her bir kurbağanın sahip olduğu mem kalitesini arttırarak hedefe gidilmesini amaçlar. Memetik evrim adımlarında, iyi değerlere sahip bireylerin, algoritmanın devamında uygulanacak adımlar için, nispeten daha kötü sonuçlara sahip bireylerden etkisinin daha fazla olması amaçlanmaktadır. Bu nedenle memetik evrim aĢamasında seçim iĢlemi yapılmadan önce her bir kurbağaya, sahip olduğu mem kalitesi ile orantılı olarak bir seçilme katsayısı verilir. Gruplar kendi içlerinde buldukları sonuçları popülasyon bazında bir araya getirerek, bu sonuçlara göre popülasyonun yeni ve farklı gruplara ayrılması gerçekleĢtirilir. Böylece kurbağaların sahip olduğu memetik bilgi, farklı konumlardaki kurbağaların da katkısıyla global düzeyde paylaĢılıp, en iyi çözüme doğru adım adım gidilmektedir. Mempleksler içinde yapılan bu evrimsel iĢlemler diğer gruplardan bağımsız olduğu için değiĢiklikler hızlı bir Ģekilde grup içine uygulanıp güncellemeler yapılmaktadır. Grupların kendi içinde yaptıkları bu güncelleme popülasyonun diğer gruplarında bulunan kurbağalar tarafından da görülebilmektedir (Eusuff ve ark 2006).
KSA, bireylerin birbirinden bağımsız olarak çözüm üretip popülasyon genelinde çözümlerini paylaĢması ve bilgi değiĢimi yapmasına dayanır. KSA, memetik algoritmalar ile parçacık sürü optimizasyonu algoritmalarının iyi yanlarını kullanırken, genetik ve yine parçacık sürü optimizasyonu algoritmalarının eksikliklerini iyileĢtirerek kullanmaya yönelik çalıĢır (Kumar ve Kumar 2013).
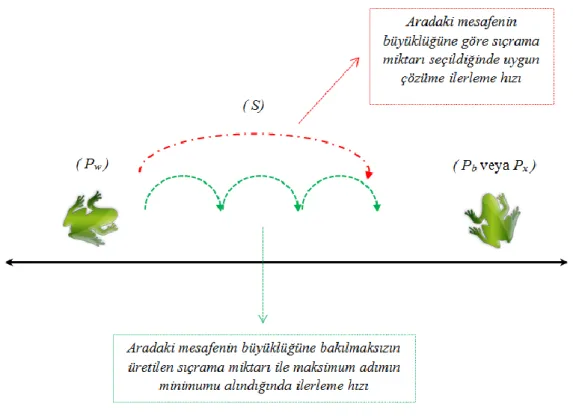
KSA kombinatoryal optimizasyon problemi için geliĢtirilmiĢ sezgisel bir algoritmadır. KSA’da kurbağaların genel yaĢam alanları göller veya daha küçük su birikintileridir. Temsili bir kurbağa sürüsü Ģekil 3.8 ile gösterilmiĢtir. YaĢam alanlarında her bir kurbağa farklı konumlarda bulunmaktadır. Birbiriyle iletiĢim ve etkileĢim içerisinde olan bu kurbağaların her birinin kendince bir memetik bilgisi bulunmaktadır. Bu memetik bilgi, kurbağanın besine olan uzaklığını tutar. Her kurbağa kendi memetik bilgisini diğer kurbağalar ile paylaĢarak, konumunu besine daha yakın bir hale getirebilir. Memetik bilginin bu Ģekilde paylaĢımı sayesinde popülasyondaki kurbağalar sürekli besine doğru konumlarını güncellemektedirler (Eusuff ve ark 2006).
ġekil 3.8. Kurbağa popülasyonun yaĢam alanı (Elbeltagi ve ark 2005)
Eusuff ve ark. (2006)’ları çalıĢmalarında Kurbağa sıçrama algoritmasının genel adımlarını aĢağıdaki gibi belirlemiĢlerdir (Eusuff ve ark 2006).
Adım 1: Kurbağa sıçrama algoritmasında kullanılacak olan tüm parametre ve kısıtların belirlendiği adımdır. m mempleks (grup) sayısı ve n her bir mempleksin sahip olduğu kurbağa sayısı olmak üzere, algoritma popülasyonunun toplam kurbağa sayısı olan F = m x n olur. Memetik evrim aĢamasında oluĢturulacak alt-mempleksteki kurbağa sayısı q, gene memetik evrimde alt-mempleksteki en kötü kurbağanın konumu güncellenirken kullanılacak olan maksimum adım büyüklüğü Smax, memetik evrimde
memplekslerin uğrayacağı evrim sayısı (memetik evrim döngü sayısı) N ve algoritmanın bitmesi için gereken iterasyon sayısı I veya algoritma bitirme kriteri belirlenir.
Smax değeri kullanılan veri setindeki niteliklerin her biri için ayrı ayrı hesaplanır.
Örneğin 5 nitelikli bir veri seti için Smax = { Smax1, Smax2, Smax3, Smax4, Smax5} Ģeklindedir.
Adım2: Problem için her biri olası bir çözümü temsil eden, popülasyondaki her kurbağa için belirlenen sınırlar içerisinde rasgele bir çözüm üretilir. d problemin boyutu olmak üzere her bir kurbağa çözüm uzayında U(i) Ģeklinde temsil edilir. Burada U(i), i. kurbağanın vektörel gösterimidir ve U(i) = (Ui1, Ui2, …, Uid) Ģeklinde bir gösterimi
vardır. Bu adımda yapılan sonraki iĢlem her bir kurbağanın ürettiği uyguluk (fitness) f(i) değerinin hesaplanmasıdır.
Adım 3: Uygunluk değerleri hesaplanan popülasyondaki tüm kurbağalar, en iyi uygunluk değerinden en kötüye doğru olacak Ģekilde sıralanır. X, uygunluk değerine göre sıralanmıĢ bireylerin tutulduğu dizidir ve X = {U(1), U(2), …, U(F)} Ģeklinde gösterilir. Dizinin uygunluk değerine göre sıralandığını düĢünürsek dizideki ilk kurbağa
popülasyondaki en iyi uygunluk değerine sahip kurbağadır. Px en iyi kurbağayı (global
en iyi) temsil etmektedir. Bu durumda Px = U(1) olmaktadır.
Adım 4: X dizisi bu aĢamada memplekslere ayrılır. Y, her birinin içerisinde n adet kurbağa olan m tane mempleksten oluĢur ve Yi = Y1, Y2, …, Ym Ģeklindedir.
Popülasyondaki kurbağaların memplekslere ayrılması eĢitlik (3.15) kullanılarak yapılmaktadır.
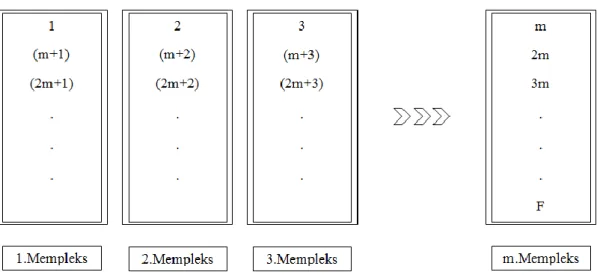
* ( ) | ( ) ( ( )+ (3.15)
Burada [k=1, …, m] ve [j=1, …, n] durumu söz konusudur. EĢitlik (3.15)’i bir örnek ile açıklayacak olursak m=3 varsayımıyla Ģu Ģekilde özetlenebilir. X dizisindeki ilk kurbağa (U(1)) 1.memplekse, ikinci kurbağa 2.memplekse, üçüncü kurbağa 3.memplekse dâhil olur. Devamında dördüncü kurbağa 1.memplekse, beĢinci kurbağa 2.memplekse ve altıncı kurbağa 3.memplekse girer. Bu iĢlem tüm kurbağalar memplekslere dağıtılana kadar devam eder. Bu Ģekilde her bir memplekste n tane kurbağa olmuĢ olur.
ġekil 3.8. Kurbağaların memplekslere ayrılma durumu
ġekil 3.8’de X dizisindeki, uygunluk değerine göre sıralanmıĢ kurbağaların memplekslere ayrılma durumunu gösteren örnek bir gösterim sunulmuĢtur.
Adım 5: Popülasyondaki kurbağalara memplekslere ayrıldıktan sonra her bir mempleks için memetik evrim döngüsü baĢlar. Bu döngü her bir mempleks için ilk adımda belirlenen N iterasyon sayısı kadar olur. Kurbağa sıçrama algoritmasının lokal
(yerel) arama kısmını oluĢturan bu adım, algoritmanın genel adımları anlatıldıktan sonra detaylı bir Ģekilde incelenecektir.
Adım 6: Belirlenen memetik döngü sayısının her memplekse uygulanması sonucunda, Y mempleks dizisindeki tüm mempleksleri oluĢturan kurbağalar karıĢtırılarak X dizisine atanır. X dizisi kurbağaların yeni konumlarına göre hesaplanan uygunluk değerleri baz alınarak en iyi kurbağadan en kötü kurbağaya doğru olacak Ģekilde sıralanır. X dizisinin ilk elemanı olan kurbağanın konumu Px (global en iyi)
olarak iĢaretlenir.
Adım 7: Ġterasyon sayacı bir arttırılır. Eğer maksimum iterasyon sayısına ulaĢılmıĢ veya belirlenen bitirme kriteri sağlanmıĢsa algoritma durdurulur. Aksi halde Adım 4’e gidilir.
Kurbağa sıçrama algoritmasının yerel arama kısmını oluĢturan, her grubu belli bir evrimsel döngüye tabi tutan Adım 5’in alt adımları aĢağıdaki gibi özetlenebilir.
Adım 5.1: Memetik evrim her bir memplekse uygulanacağı için mempleks sayacı olarak im değiĢkeni belirlenir ve baĢlangıç değeri atanır, im = 0. Ayrıca her bir mempleksin tabi tutulacağı evrimsel döngü sayısını tutmak için iN sayacı tanımlanarak baĢlangıç değeri atanır, iN = 0.
Adım 5.2: Memetik evrim aĢamasında kurbağaların temel amacı en iyi çözüme doğru yaklaĢmaktır. Bu hedeflerini gerçekleĢtirmek için de duruma göre ya global en iyi (Px) ya da yerel en iyi (Pb) kurbağanın konumundan faydalanırlar. Her zaman global en
iyi kurbağanın konumundan faydalanmak yerel minimuma yakalanma riskini taĢıdığı için yerel en iyi değer de hesaba katılarak evrimsel döngüler gerçekleĢtirilmektedir. Mempleks içerisindeki aktif evrimin baĢlaması için söz konusu mempleksten bir alt-mempleks üretilmesi gerekir. Alt-alt-mempleksler oluĢturulurken, alt-mempleksteki uygunluk değeri açısından daha iyi kurbağalara daha yüksek seçilme oranları verilerek, alt-memplekse girme Ģansları arttırılır. Yüksek uygunluk değerine sahip kurbağalara daha fazla Ģans verilmesine karĢın, düĢük uygunluk değerine sahip kurbağalar yok sayılmamakta ve düĢük de olsa uygunluk değerine göre bir seçim olasılığı verilmektedir. Mempleksteki kurbağaların alt-memplekse seçilme Ģansını belirleyen oranlar belirlenirken, eĢitlik (3.16) ile formüle edilen üçgensel olasılık dağılım fonksiyonu kullanılır.
( )