Başlık: Farklı Örnek Büyüklükleri için DFREML ve R Regresyon Yöntemleri Kullanılarak Elde Edilen Parametre Tahminlerinin KarşılaştırılmasıYazar(lar):ARSLAN, Serhat;MİRTAGİOĞLU, Hamit;KESİCİ,Tahsin Cilt: 10 Sayı: 3 Sayfa: 291-296 DOI: 10.1501/Tarimbil_0000
Tam metin
Şekil


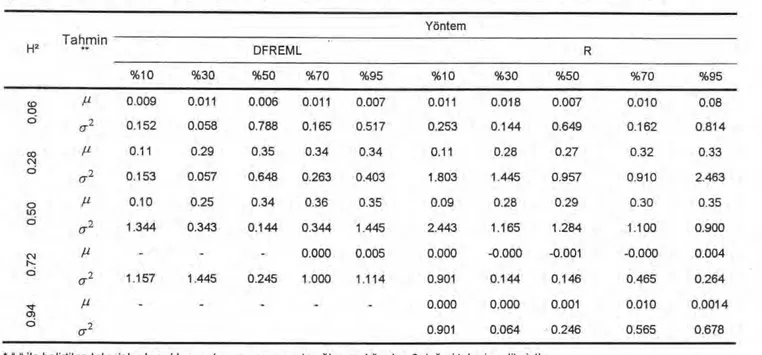
Benzer Belgeler
Terörist saldýrýlar nedeniyle TSSB geliþimi ile ilgili yapýlan çalýþmalarýn çoðunda kadýn olmanýn, etnik bir azýnlýktan olmanýn, düþük eðitim seviyesinde
Geleneksel kırsal konut tipolojileri üzerinden kültür-mekân ilişkilerini, mekânsal yapılanma ve örgütlenmedeki yansımalarını incelemeyi hedefleyen bu çalışmada,
Ýki grup arasýnda farklý olduðunu bul- duðumuz klinik özellikler, OKKB'nin eþlik ettiði OKB hastalarýnda, semptom daðýlýmý açýsýndan tekrarlama ve
(9); dişi Estonian Holstein ve Estonian Native ırklarında yaptığı araştırmada intermedier transversal çap ve vertikal çapların, cranial pelvis boşluğu
De novo serin biyosentezi, glikolizis, çoğu hücre türünde ATP ve enerji sağlar, fakat kanser hücreleri tümör gelişiminde önemli olan glikolizisi anabolizmayı
Bu olgu sunumu ile birlikte 3 aylık, dişi Montofon buzağıda bilateral hamartom olgusunun tanımlanması ve bu nedenle tıkanan dış kulak yolunun operatif tedavisinin
When looking at the results between AISI 1008, 1040 and 4140 materials; carbon ratio is more effective in tensile strength and % section contraction, while alloying
Proximal uçta radius ile eklem yapan daha kısa bir processus coronoideus medialis ile daha uzun ve geniş bir eklem yüzüne sahip processus coronoideus lateralis
