On-the-fly ensemble classifier pruning in evolving data streams
Tam metin
Şekil
![Figure 1.2: Four patterns of real concept drift over time. Revised from [2]](https://thumb-eu.123doks.com/thumbv2/9libnet/5924764.123070/15.918.173.794.160.445/figure-patterns-real-concept-drift-time-revised.webp)


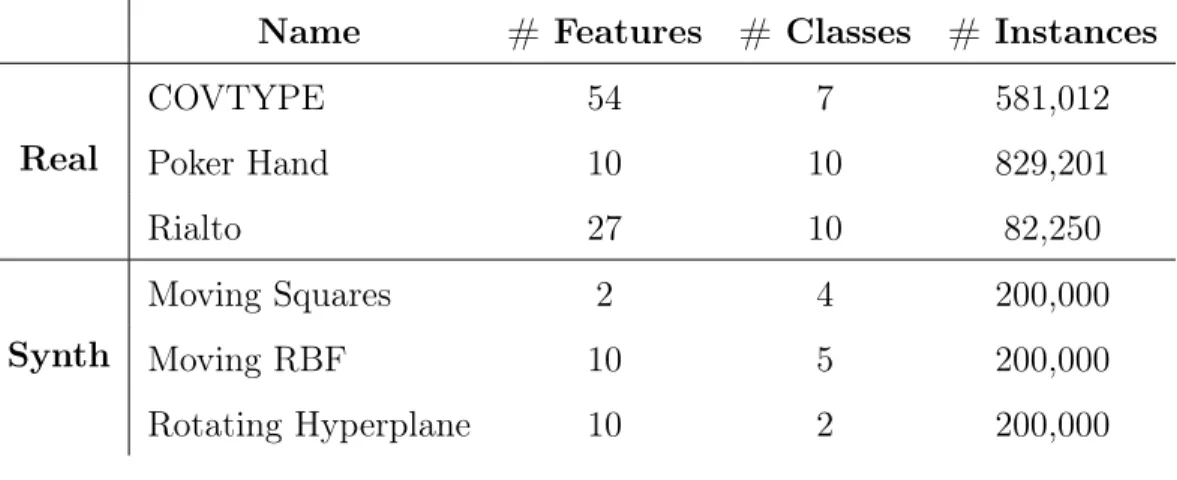
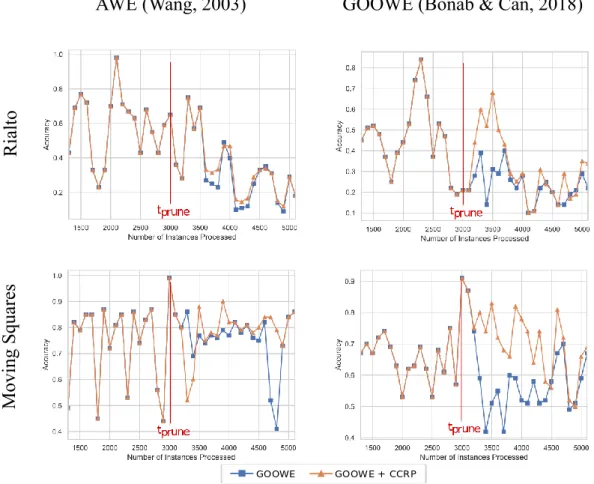
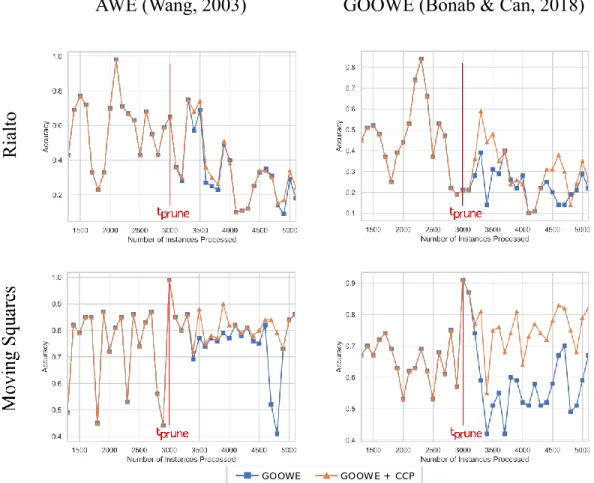
Benzer Belgeler
EU-Turkey relations improved in the early 2000s, a new thread of Turkish nationalism emerged, a paradoxical mix of Kemalism and anti-Westernism that found support in military
Noel Buxton's interests in foreign policy can be divided into as follows: the Turkish Empire generally but more specifically the problems of Turkish rule in the
On the other hand, optimal stochastic signaling further reduces the average probability of error by using all the available power and assigning some of the power to a large
We proposed a new test prioritization technique and showed that selecting individually informative and topologically diverse SNPs in terms of genomic location leads to
Yayımlanmamış yüksek lisans tezi, Ankara: Gazi Üniversitesi Sosyal Bilimler Enstitüsü, Sanat Tarihi Anabilim Dalı.. Eyüpsultan mezarlıklarında
Bu bakteri türlerinin toprak uygulaması, tohum muamelesi ve fide daldırma muameleleri gibi farklı uygulamaları olup, ıslanabilir toz (WP), tohuma uygulanan
Deri ve Zührevi Hastalıklar Kliniği, Düzce, Türkiye **Düzce Üniversitesi Tıp Fakültesi, Çocuk Sağlığı ve Hastalıkları Anabilim Dalı, Düzce, Türkiye
İnsanın tanrıya çeşitli tarzlarda öykünme çabası, Platon’un farklı diyaloglarında farklı şekil- lerde ele alınmıştır. Bu ideal, Theaetetus’ta, hakiki filozofun
