FEN BİLİMLERİ ENSTİTÜSÜ
UZUN KUYRUKLU SİMETRİK DAĞILIMIN PARAMETRELERİ İÇİN SANSÜRLÜ ÖRNEKLEMLERE DAYALI İSTATİSTİKSEL SONUÇ
ÇIKARIMI
Erol KUŞ
YÜKSEK LİSANS TEZİ İSTATİSTİK ANABİLİM DALI
2
FEN BİLİMLERİ ENSTİTÜSÜ
UZUN KUYRUKLU SİMETRİK DAĞILIMIN PARAMETRELERİ İÇİN SANSÜRLÜ ÖRNEKLEMLERE DAYALI İSTATİSTİKSEL SONUÇ
ÇIKARIMI
Erol KUŞ
YÜKSEK LİSANS TEZİ İSTATİSTİK ANABİLİM DALI
Bu tez 26/02/2010 tarihinde aşağıdaki jüri tarafından oybirliği / oyçokluğu ile kabul edilmiştir.
... ………. ………
Doç. Dr. Coşkun KUŞ Doç.Dr. Aşır GENÇ Yrd.Doç.Dr.Hasan KÖSE
i
UZUN KUYRUKLU SİMETRİK DAĞILIMIN PARAMETRELERİ İÇİN SANSÜRLÜ ÖRNEKLEMLERE DAYALI İSTATİSTİKSEL SONUÇ
ÇIKARIMI
Erol KUŞ Selçuk Üniversitesi Fen Bilimleri Enstitüsü İstatistik Anabilim Dalı
Danışman: Doç.Dr. Coşkun KUŞ 2010, 62 Sayfa
Jüri: Doç.Dr. Coşkun KUŞ Doç.Dr. Aşır GENÇ
Yrd.Doç.Dr. Hasan KÖSE
Bu tez çalışmasında, uzun kuyruklu simetrik dağılımın parametrelerinin ilerleyen tür tip-II sağdan sansürlü örneklemlere dayalı parametre tahmini ele alınmıştır. Uzun kuyruklu simetrik dağılımın konum ve ölçek parametrelerinin modifiye edilmiş en çok olabilirlik tahmin edicileri analitik olarak elde edildi. En çok olabilirlik tahmin edicilerin asimptotik normallik özelliği kullanılarak konum ve ölçek parametreleri için yaklaşık güven aralıkları inşa edilmiştir. Modifiye edilmiş en çok olabilirlik tahmin edicilerinin ve güven aralıklarının kapsama olasılıklarının performanslarını incelemek için simülasyon çalışması yapılmıştır. Aynı zamanda nümerik bir örnek verilmiştir.
Anahtar Kelimeler: Modifiye edilmiş en çok olabilirlik tahmin edicileri, ilerleyen
ii
STATISCIAL INFERENCE FOR THE PARAMETERS OF LONG-TAILED SYMMETRIC DISTRIBUTION BASED ON CENCORED SAMPLES
Erol KUŞ Selçuk University
Graduate School of Natural and Applied Sciences Department of Statistics
Supervisor:Assoc.Prof.Dr Coşkun KUŞ 2010, 62 Pages
Jury: Assoc.Prof.Dr. Coşkun KUŞ
Assoc.Prof.Dr. Aşır GENÇ
Ass.Prof.Dr. Hasan KÖSE
In this thesis, it is considered that the estimation of parameters of long tailed symmetric distribution based on progressive type-II right censored samples. Modified maximum likelihood estimators are obtained analitically for location and scale parameters of long tailed symmetric distribution. Approximate confidence intervals of location and scale parameters are constructed using asymtotic normality of maximum likelihood estimators. Simulation study is performed to investigate the performances of the modified maximum likelihood estimators and coverage probabilities of the approximate confidence intervals. A numerical example is also presented.
Key Words: Long tailed symmetric distribution, modified maximum likelihood
iii
Bu çalışma konusunu bana veren, çalışmalarım süresince beni teşvik eden, maddi ve manevi yardımlarını hiçbir zaman esirgemeyen değerli hocam sayın Doç.Dr.Coşkun KUŞ’a, çalışmalarımda yardımcı olan değerli hocalarım Yrd.Doç.Dr.İsmail KINACI, Yrd.Doç.Dr.Buğra SARAÇOĞLU, Arş.Gör.Ahmet PEKGÖR, Arş.Gör.Alper SİNAN, Dr.Aydın KARAKOCA ve Dr.Neslihan İYİT’e sonsuz teşekkürlerimi sunarım.
iv
Çizelge 2.1 Farklı p değerleri için LTS dağılımının Basıklık Katsayı
değerleri.
31
Çizelge 3.1 Modifiye edilmiş en çok olabilirlik tahmin edicilerinin
simulasyonla ve fisher bilgi matrisi kullanılarak elde edilen varyans ve
kovaryansları (p=3)……….. 46
Çizelge 3.2 Modifiye edilmiş en çok olabilirlik tahmin edicilerinin
simulasyonla ve fisher bilgi matrisi kullanılarak elde edilen varyans ve
kovaryansları (p= )……….. 5 47
Çizelge 3.3 Modifiye edilmiş en çok olabilirlik tahmin edicilerinin simulasyonla ve fisher bilgi matrisi kullanılarak elde edilen varyans ve kovaryansları
(p=10)……….
48
Çizelge 3.4 Konum ve Ölçek parametrelerinin fisher bilgi matrisine dayalı %95 lik yaklaşık güven aralıklarının kapsama olasılıkları……….. 49
v
ŞEKİLLER DİZİNİ
Şekil 1.1. İlerleyen tür tip-II sağdan sansürlü örneklem plânı... 13 Şekil 2.1 Farklı p değerleri için LTS dağılımının o.y.f grafiği……… 27 Şekil 2.2 Farklı μ değerleri için LTS dağılımının o.y.f grafiği……… 28
Şekil 2.3 Farklı σ değerleri için LTS dağılımının olasılık o.y.f.
grafiği………...
28
Şekil 2.4 LTS dağılımının farklı p değerleri için kurtosis değişim grafiği……... 31 Şekil 4.1 Çizelge 4.1’de verilen verilere ait (2.25)’te tanımlanan αi
değerleri….
51
Şekil 4.2 Çizelge 4.1’de verilen verilere ait (2.25)’te tanımlanan βi
değerleri….
51
Şekil 4.3 Çizelge 4.1’de verilen verilere ait (2.25)’te tanımlanan Δ değerleri… 51 i
Şekil 4.4 Çizelge 4.1’de verilen verilere ait (2.25)’te tanımlanan γi
değerleri….
GİRİŞ ... 1
1. TEMEL KAVRAMLAR... 3
1.1. Bazı Özel Fonksiyonlar... 3
1.1.1. Gamma Fonksiyonu ... 3
1.1.2. Beta Fonksiyonu ... 4
1.1.3. Genelleştirilmiş Hipergeometrik Fonksiyon... 4
1.2. Çarpıklık Katsayısı... 5
1.3. Basıklık Katsayısı ... 5
1.4. Konum-Ölçek Parametreli Dağılımlar Ailesi... 6
1.5. Bazı Özel Dağılımlar ... 8
1.5.1. Düzgün Dağılım... 8
1.5.2. Student t Dağılım ... 8
1.5.3. Lojistik Dağılım ... 9
1.6. Sıra İstatistikleri ... 10
1.7. Tip-II Sağdan Sansürlü Örneklem ... 12
1.8. İlerleyen Tür Tip-II Sağdan Sansürlü Örneklem ... 13
1.9. Asimptotik Normallik ... 17
1.10. Olabilirlik Fonksiyonu ... 18
1.11. Fisher Bilgi Matrisi ... 19
1.12. En Çok Olabilirlik Tahmin Edicileri... 19
1.13. Asimptotik Güven Aralıkları... 20
1.14. Taylor Serileri ... 21
1.15. Birinci Mertebe Yaklaşımı... 21
1.16. Newton-Raphson Yöntemi... 24
2.UZUN KUYRUKLU SİMETRİK DAĞILIM ... 26
2.1.En Çok Olabilirlik Tahmincisi... 32
2.2. Modifiye Edilmiş En Çok Olabilirlik Tahmin Edicileri ... 33
2.3. LTS Dağılımının Parametrelerinin MMLE Tahmin Edicileri ... 36
2.4. MLE Tahmin Edicilerinin Varyans-Kovaryans Matrisi ... 42
2.5 Gözlenen Fisher Bilgi Matrisi... 43
3. SİMÜLASYON ÇALIŞMASI... 45
4. UYGULAMA ... 50
5. SONUÇ VE ÖNERİLER ... 53
EK 1. Simulasyon Sonuçları İçin Delphi 5 Programında Yazılan Kod ... 54
GİRİŞ
Bir sistemin güvenilirliği için sonuç çıkarımı yaparken sistemi oluşturan tüm bileşenlerin bozulma zamanlarını gözlemlemek her zaman mümkün olmayabilir. Örneğin; bir klinikte tedavi gören hastalara ilişkin veriler, eksiksiz gözlenemeyebilir veya pahalı bir elektronik parçanın yaşam zamanı hakkında bilgi edinmek için yapılan yaşam testinde, parçaların hepsinin bozulmalarının gözlenmesi maliyeti ve test zamanını artıracağından istenmeyebilir. Bu tip durumlarda, deney yada gözlem sonrası sansürlenmiş veri elde edilir. Tıp, biyoloji, sigortacılık, mühendislik, kalite kontrol ve birçok alanda sansürlenmiş verilerle karşılaşılmaktadır.
Deney ya da gözlemler sonucunda değişik sansür türleriyle karşılaşmak mümkündür. Birinci tip sansürleme olarak adlandırılan sansürleme modeli, t gibi önceden belirlenmiş bir zamandan önce, sistemdeki bozulan birimlerin bozulma zamanının gözlenmesi durumudur. İkinci tip sansürleme olarak adlandırılan sansürleme modeli, n birimden oluşan bir sistemin bozulan k ≤n biriminin bozulma zamanının gözlenmesi durumudur. Rasgele sansürleme olarak adlandırılan sansürleme modeli ise birimlerin bozulma zamanlarının başka bir rasgele olaydan dolayı sansürlenmesi durumudur (Kale 2003).
İkinci tip sansürlemenin en popüler olanı, ilerleyen tür tip-II sağdan sansürlemedir (progressive type-II right censoring). Bu sansürleme modeli şu şekilde izah edilebilir: n sayıda özdeş bileşenin (aynı yaşam zamanı dağılımına sahip) yaşam testine tabi tutulduğu düşünülsün. Sistemde meydana gelen 1. bozulma ile rasgele R1 sayıda bileşenin sistemden çekildiğini, daha sonra geriye kalan n− R1−1 bileşenden, 2. bozulma ile rasgele R2 sayıda bileşenin sistemden çekildiğini ve böylece m. bozulma ile rasgele R sayıda bileşenin sistemden m
hacimli örneklem ilerleyen tür tip-II sağdan sansürlü örneklemdir (Balakrishnan ve Aggarwala 2000)
İlerleyen Tür Tip-II sağdan sansürlü örneklemlere dayalı Balakrishnan ve ark. (2004) Uç Değer dağılımının, Balakrishnan ve Asgharzadeh (2005) Ölçeklendirilmiş Yarı Lojistik dağılımın (Scaled Half-Logistic Distribution), Lin ve ark. (2006) Log-Gamma dağılımının, Asgharzadeh (2006) Genelleştirilmiş Lojistik dağılımın(Generalized Logistic Distribution), Sultan ve ark. (2007) Weibull dağılımının, Asgharzadeh (2009) Genelleştirilmiş Üstel dağılımın ve parametreleri için modifiye edilmiş en çok olabilirlik tahmin edicilerini önermişler ve bu tahmin edicilerin özelliklerini Monte Carlo simülasyonu yardımıyla incelemişlerdir.
Tezin birinci bölümünde, çalışmada gerekli olan temel kavramlar verilmiştir. İkinci Bölümde, uzun kuyruklu simetrik dağılım ve özellikleri tanıtılmıştır. Ayrıca bu dağılımın parametrelerinin modifiye edilmiş en çok olabilirlik tahmin edicileri ve asimptotik varyans-kovaryans matrisi elde edilmiştir. Üçüncü Bölümde, uzun kuyruklu simetrik dağılımın konum ve ölçek parametreleri için modifiye edilmiş en çok olabilirlik tahmin edicilerinin beklenen değerleri, varyansları ve kovaryansları hem simülasyon hem de fisher bilgi matrisine dayalı olarak elde edilmiştir. Yine simülasyon çalışmasıyla fisher bilgi matrisine dayalı yaklaşık güven aralıklarının kapsama olasılılıkları incelenmiştir. Dördüncü Bölümde tezde elde edilen sonuçlar için bir uygulama verilmiştir. Beşinci Bölümde ise tezde elde edilen sonuçlara ve ilerideki çalışmalar için bazı önerilere yer verilmiştir.
1. TEMEL KAVRAMLAR
1.1. Bazı Özel Fonksiyonlar
1.1.1. Gamma Fonksiyonu Gamma fonksiyonu
( )
=∫
∞ −( )
− > Γ 0 1exp , β 0 β tβ t dtşeklinde tanımlanır (Kuş 2004). β pozitif tam sayı olmak üzere
(
β +1)
=β! Γ( )
1.7724538509 exp 2 2 1 0 2 = = − = ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ Γ∫
∞ t dt π( ) ( )
2 = 2 1/222 1/2Γ( ) (
Γ +1/2)
Γ β π − β− β β dir. Stirling formülü( )
( )
( )
⎥ ⎦ ⎤ ⎢ ⎣ ⎡ + + − Γ − 288 1 12 1 1 2 exp ~ 1/2 1/2 β π β β β β( )
[
Γ]
=(
− −)
( )
− + −( )
+ − + + 5 3 1 1 1260 1 360 1 12 1 2 log 2 log 2 log β β β π β β β β şeklindedir.1.1.2. Beta Fonksiyonu
, 0
a b> olmak üzere Beta fonksiyonu
( )
( ) ( )
(
)
b a b a b a + Γ Γ Γ = , Bşeklinde tanımlanır. Burada Γ i
( )
, Gamma fonksiyonudur (Kuş, 2004).1.1.3. Genelleştirilmiş Hipergeometrik Fonksiyon
Genelleştirilmiş hipergeometrik fonksiyon
(
) ( )
(
)
(
) ( )
1 1 , 1 0 1 ( , , ) 1 p k i i i p q q k i i i r n k n F r k d k d − ∞ = − = = ∏ Γ + Γ = Γ + ∏ Γ + Γ∑
n dbiçiminde tanımlanır. Burada n=[n1,n2,...,np], ]d=[d1,d2,...,dq dır. Özel olarak 1p= q2, = için hipergeometrik fonksiyon
(
)
(
) (
) ( ) ( )
(
) (
η) ( )
η β α β α β η β η η β α β ηα β 1 1 1 0 1 0 1 1 1 , 2 1 ) 1 ( ) 1 ( ) ( ) ( ) ; ; , ( − − − = ∞ − − − Γ + Γ + Γ Γ Γ + Γ + Γ ∑ = − − − Γ Γ Γ =∫
k k k k z dt tz t t z F k k1.2. Çarpıklık Katsayısı
İlk üç momenti sonlu olan bir X rasgele değişkeninin beklenen değeri μ, varyansı σ2 olsun. Bu durumda X rasgele değişkeninin Çarpıklık(Skewness) Katsayısı 3 1 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = σ μ γ E X şeklinde tanımlanır.
Çarpıklık katsayısı olasılık (yoğunluk) fonksiyonunun ortalama etrafındaki asimetrikliğin ölçüsü olarak yorumlanır(Casella ve Berger 2002, Roussas 1973).
0
1 >
γ ise dağılım sağa çarpıktır, γ1 <0 ise dağılım sola çarpıktır denir(Roussas 1973). X rasgele değişkeninin olasılık yoğunluk fonksiyonu f
( )
x , a∈ noktası etrafında simetrik ise γ1 =0 dır(Casella ve Berger 2002, Roussas 1973).1.3. Basıklık Katsayısı
İlk dört momenti sonlu olan bir X rasgele değişkeninin beklenen değeri μ, varyansı σ2 olsun. Bu durumda X rasgele değişkeninin Basıklık(kurtosis) Katsayısı 4 2 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = σ μ γ E X şeklinde tanımlanır(Roussas 1973).
Yukarıdaki tanım ele alındığında, normal dağılım için Basıklık Katsayısı 3 olarak elde edilir.
Basıklık Katsayısı, olasılık (yoğunluk) fonksiyonunun yükseklik derecesinin ölçüsü olarak yorumlanır. Dağılımın Basıklık Katsayısı γ2 >3
olduğunda normal dağılıma göre sivri, γ2 <3 olduğunda normal dağılıma göre daha basıktır denir.
1.4. Konum-Ölçek Parametreli Dağılımlar Ailesi
X rasgele değişkeninin dağılım fonksiyonu Fμ(x) ve
( )
1{
F( ) ( )
x:F x F(
x)
; , Fbiliniyor}
Fμ ⋅ ∈ℑ = μ μ = −μ μ∈Θ
olmak üzere ℑ1’e konum parametreli dağılımlar ailesi, μ’ye ise konum parametresi denir. Burada Θ, μ parametresi için parametre uzayıdır. μ parametresinin X rasgele değişkeni için konum parametresi olması için gerek ve yeter koşul X −μ rasgele değişkeninin dağılımının μ’den bağımsız olmasıdır. Yani
(
X x)
P(
X x)
F(
x)
F(
x)
F(x)P −μ ≤ = ≤ +μ = μ +μ = +μ−μ =
dir.
X rasgele değişkeninin dağılım fonksiyonu Fσ(x) ve
( )
2( )
:( )
; , biliniyor x Fσ F x F xσ σ F σ F σ ⎧ ⎛ ⎞ ⎫ ⋅ ∈ ℑ =⎨ = ⎜ ⎟ ∈ ∑ ⎬ ⎝ ⎠ ⎩ ⎭olmak üzere ℑ2’e konum parametreli dağılımlar ailesi, σ ’ya ise ölçek parametresi denir. Burada ∑ , σ parametresi için parametre uzayıdır. σ
parametresinin X rasgele değişkeni için ölçek parametresi olması için gerek ve yeter koşul
σ
X rasgele değişkeninin dağılımının σ ’dan bağımsız olmasıdır. Yani
(
)
( )( )
X x P x P X σx Fσ σx F σ F x σ σ ⎛ ≤ ⎞= ≤ = = ⎛ ⎞= ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ ⎝ ⎠ dir.(
μ σ,)
′ =γ olmak üzere X rasgele değişkeninin dağılım fonksiyonu F xγ( ) ve
( )
3( ) ( )
: ; , biliniyor x Fγ F x F xγ γ F μ γ F σ ⎧ ⎛ − ⎞ ⎫ ⋅ ∈ ℑ =⎨ = ⎜ ⎟ ∈Γ ⎬ ⎝ ⎠ ⎩ ⎭olmak üzere ℑ ’e konum ve ölçek parametreli dağılımlar ailesi, 3 μ’ye konum ve σ ’ya da ölçek parametresi denir. Burada Γ , γ parametresi için parametre uzayıdır. γ parametresinin X rasgele değişkeni için konum parametresi olması
için gerek ve yeter koşul σ
μ −
X
rasgele değişkeninin dağılımının γ dan bağımsız
olmasıdır. Yani
(
)
(
)
( )
X x P μ x P X σx μ F σx μ F σ μ μ F x σ σ − + − ⎛ ≤ ⎞= ≤ + = + = ⎛ ⎞= ⎜ ⎟ ⎜ ⎟ ⎝ ⎠ γ ⎝ ⎠1.5. Bazı Özel Dağılımlar
1.5.1. Düzgün Dağılım
X rasgele değişkeni,
(
β,θ)
aralığında düzgün dağılıma sahip ise, sırasıyla, olasılık yoğunluk ve dağılım fonksiyonu,( ) (
= θ −β)
− β < <θ x x f 1, (1.1)( ) (
= −β)(
θ −β)
− β < <θ x x x F 1, (1.2)biçimindedir. Düzgün dağılım için Düzgün
(
β,θ)
gösterimi kullanılacaktır.X rasgele değişkeni Düzgün
(
β,θ)
dağılımına sahip olduğunda X in beklenendeğer ve varyansı, sırasıyla,
( ) (
X = β +θ)
2−1 E( ) (
)
2 1 12− − = θ β X Var şeklindedir. 1.5.2. Student t DağılımSürekli bir X rasgele değişkeninin olasılık yoğunluk fonksiyonu
( )
1 2 2 1 2 1 , , 2 r r x f x x r r πr r + + + ⎛ ⎞ Γ⎜⎝ ⎟⎠ ⎛ ⎞ = × +⎜ ⎟ ∈ ∈ ⎛ ⎞ ⎝ ⎠ Γ⎜ ⎟⎝ ⎠ise X rasgele değişkenine t dağılımına sahiptir denir. Burada r parametresi,
dağılımın serbestlik derecesi olarak adlandırılır. r serbestlik dereceli t dağılımı
için t r
( )
gösterimi kullanılacaktır.X rasgele değişkeni t r
( )
dağılımına sahip olduğunda X in beklenendeğer ve varyansı sırasıyla,
( )
0, 2,3, E X = r= …( )
, 3, 4, 2 r Var X r r = = − … şeklindedir (Ghahramani 2005). 1.5.3. Lojistik Dağılımμ ve σ parametreli lojistik dağılıma sahip olan X rasgele değişkeninin olasılık yoğunluk fonksiyonu
( )
2 exp , 1 exp x f x x x μ σ μ σ σ − ⎛− ⎞ ⎜ ⎟ ⎝ ⎠ = ∈ ⎡ + ⎛− − ⎞⎤ ⎜ ⎟ ⎢ ⎝ ⎠⎥ ⎣ ⎦ (1.3)şeklinde tanımlanır. Burada, μ∈ konum ve σ∈ + ölçek parametresidir. μ ve
σ parametreli lojistik dağılım kısaca Lojistik
(
μ,σ)
ile gösterilecektir.(
μ,σ)
Lojistik dağılımına sahip olan X rasgele değişkeninin dağılım
fonksiyonu
( )
1 , 1 exp F x x x μ σ = ∈ − ⎛ ⎞ + ⎜− ⎟ ⎝ ⎠ (1.4)şeklindedir. Lojistik
(
μ,σ)
dağılıma sahip X rasgele değişkeninin beklenen değer ve varyansı sırasıyla E( )
X =μ ve( )
3 2 2σ π = XVar şeklindedir. Lojistik
dağılımın çarpıklık katsayısı sıfır olup E
( )
X =μ etrafında simetriktir (Asgharzadeh 2006).1.6. Sıra İstatistikleri
F dağılım fonksiyonuna sahip bir kitleden alınan X1,X2,…,Xn
örnekleminin X1:n ≤ X2:n ≤ ≤ Xn:n olacak biçimde büyüklük sırasına göre dizilmesiyle elde edilen her bir Xi:n rasgele değişkeni i. sıra istatistiği olarak isimlendirilir.
{
n}
n X X X
X1: =min 1, 2,…,
sıra istatistiğinin dağılım fonksiyonu,
{
}
(
)
n n x F x X P x F1( )= 1: ≤ =1− 1− ( ) (1.5) ve maks :n = n X{
X1,X2,…,Xn}
sıra istatistiğinin dağılım fonksiyonu,
{
:} (
)
( ) ( ) n
n n n
F x =P X ≤x = F x
1≤ ≤r n olmak üzere r. sıra istatistiğinin dağılım fonksiyonu
{
X x} {
P X X X r x}
P x
Fr( )= r:n ≤ = 1, 2,…, n lerden enaz tanesi≤
dir.
{
X X1, 2, ,… Xn lerden tam tanesii ≤x}
olayı A ile gösterilsin. Ai i olayları ayrık olduğundan,( )
( ) n n r i i i r i r F x P A P A = = ⎧ ⎫ = ⎨ ⎬= ⎩∪
⎭∑
n(
( ) 1) (
i ( ))
n i i r n F x F x i − = ⎛ ⎞ = ⎜ ⎟ − ⎝ ⎠∑
(1.6)dır. Bu ise tam olmayan beta fonksiyonudur. Yani
(
) (
)
( ) n ( ) 1i ( ) n i r i r n F x F x F x i − = ⎛ ⎞ = ⎜ ⎟ − ⎝ ⎠∑
∫
− − − + − = ) ( 0 1(1 ) ) 1 , ( 1 F xtr t n rdt r n r B =IF(x)(r,n−r+1) dır. Şayet Xi’ ler f x dF x dx( ) = ( ) olacak biçimde sürekli rasgele değişkenler ise
∫
− − − + − = = ) ( 0 1(1 ) ) 1 , ( B 1 ) ( ) ( x F r n r r r t t dt dx d r n r dx x dF x f(
( )) (
1 ( ))
( ) ) 1 , ( B 1 1 x f x F x F r n r r n r− − − + − = olur.Burada
( )
! ( 1)!( )! ) 1 , ( B r n−r+ = n −1 r− n−r şeklindedir (David 1970). n n n n X XX1: , 2: ,…, : sıra istatistiklerinin ortak olasılık yoğunluk fonksiyonu ise
f1,2,…,n(x1,x2,…,xn)=n!f
( ) ( )
x1 f x2 × × f( )
xn , −∞<x1 ≤ ≤ xn <∞ (1.7)şeklindedir (David 1970).
1.7. Tip-II Sağdan Sansürlü Örneklem
n sayıda özdeş bileşenin yaşam testine tabi tutulduğu düşünülsün.
Meydana gelen m≤ bozulma ile yaşam testi sona erdirilsin. Bu şekilde yapılan n
sansürlemeye Tip-II sağdan sansürleme denir (Kale 2003).
n m n
n X X
X1: < 2: < < : , olasılık yoğunluk fonksiyonu f ve dağılım fonksiyonu F olan dağılımdan alınan tip-II sağdan sansürlü örneklem olmak üzere X1:n,X2:n,…,Xm:n’ nin marjinal ortak olasılık yoğunluk fonksiyonu (1.7) den
(
) ( ) ( ) ( )
{
1}
, ! ! , , , 1 2 1 , , 2 , 1∏
= − − − = m i m n i i m m f x F x m n n x x x f … … −∞<x1< <xm<∞ (1.8)Eşitlik (1.8)’de m=n alınırsa bilinen sıra istatistiklerinin ortak olasılık yoğunluk fonksiyonu (1.7) elde edilir.
Tip-II sağdan sansürleme, yaşam testinin maliyetini ve süresini azaltmasına karşın sonuç çıkarımının güvenilirliğini azaltmaktadır.
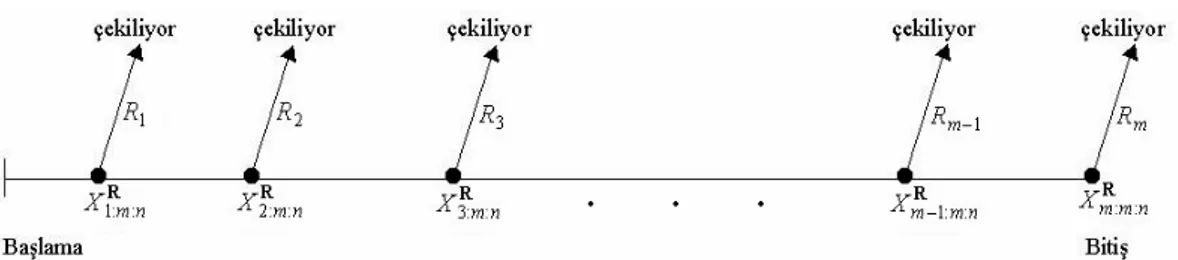
1.8. İlerleyen Tür Tip-II Sağdan Sansürlü Örneklem
İlerleyen tür tip-II sağdan sansürlenmiş model (Progressive type-II right censoring model) şu şekilde tanımlanmaktadır (Balakrishnan ve Aggarwala 2000).
n sayıda özdeş bileşenin bir sistemde yaşam testine tabi tutulduğu
düşünülsün. Sistemde meydana gelen 1. bozulma ile R1 sayıda bileşenin sistemden çekildiğini daha sonra geriye kalan n− R1−1 bileşenden, 2. bozulma ile R2 sayıda bileşenin sistemden çekildiğini ve böylece m. bozulma ile R m
sayıda bileşenin sistemden çekilmesiyle m bileşenin bozulma zamanı gözlenir. Bu şekilde elde edilen m hacimli örnekleme ilerleyen tür tip-II sağdan sansürlü
örneklem denir. Burada n=m+
∑
mi=1Ri biçimindedir ve R=(
R1,R2,…,Rm)
sansür şeması olarak adlandırılır.
Şekil 1.1. İlerleyen tür tip-II sağdan sansürlü örneklem plânı
R R R n m m n m n m X X
X1: : < 2: : < < : : , olasılık yoğunluk fonksiyonu g ve dağılım
fonksiyonu G olan dağılımdan alınan ilerleyen tür tip-II sağdan sansürlü
örneklem olmak üzere R R R
n m m n m n m X X
X1: : < 2: : < < : : ’ nin ortak olasılık yoğunluk fonksiyonu kombinatorik yöntemler de kullanılarak aşağıdaki gibi elde edilir:
{
x X mn x x x X mn x x xm Xmmn xm xm}
A= < R < +Δ < R < +Δ < R < +Δ : : 2 2 : : 2 2 1 1 : : 1 1 , ,…,olayı göz önüne alınsın. A olayının gerçekleşmesi için mümkün X1,X2,…,Xn
rasgele değişkenlerinin kendi aralarında mümkün sıralanmalarının sayısı;
(
− 1−1)
× ×(
− 1 − 2 − − 1− +1)
=n n R n R R R − m c m (1.9) olmak üzere{ }
A P{
x X mn x x x X mn x x xm Xmmn xm xm}
P = < R < +Δ < R < +Δ < R < +Δ : : 2 2 : : 2 2 1 1 : : 1 1 , ,…,{
}
m m m m m m m X x x R X x x x x x X R x x X x x x X R x x X x P c Δ + > Δ + < < Δ + > Δ + < < Δ + > Δ + < < × = tane , , tane , , tane , 2 2 2 2 2 2 2 1 1 1 1 1 1 1 m[
(
)
]
[
(
i i) ( )
i]
i R i i x G x x G x x G c× − +Δ i +Δ − =∏
=1 1(
m)
X X X x x x g n m m n m n m , 2R: :, , R: : 1, 1, , R : : 1 … …( )
m x x x x x x A P m Δ × × Δ × Δ = → Δ → Δ → Δ 2 1 0 0 0 2 1 lim =(
)
[
]
[
(
) ( )
]
m m i i i i R i i x x x x G x x G x x G c i Δ × × Δ − Δ + Δ + − ×∏
= → Δ 1 1 0 1 lim(
)
[
]
[
(
)
( )
]
∏
∏
∏
= = = → Δ Δ − Δ + Δ + − × = m i i m i i i i m i R i i x x x G x x G x x G c i 1 1 1 0 1 lim(
)
[
]
(
) ( )
i i i i m i x m i R i i x x x G x x G x x G c i Δ − Δ + Δ + − × =∏
∏
= Δ → =1 Δ →0 1 0 lim 1 lim( )
( )
1 1 1 i m m R i i i i c G x g x = = = ×∏
⎡⎣ − ⎤⎦∏
( )
[
]
( )
i R m i i g x x G c i∏
= − × = 1 1 (1.10)elde edilir. (1.10)’da R=
(
0 …, ,0)
alınırsa bilinen sıra istatistiklerinin ortak olasılık yoğunluk fonksiyonu (1.7), R=(
0 …, ,n−m)
alınırsa tip-II sağdan sansürlü sıra istatistiklerinin ortak olasılık yoğunluk fonksiyonu (1.8) elde edilir (Balakrishnan ve Aggarwala 2000).İlerleyen tür tip-II sağdan sansürlü örnekleme, yaşam zamanı analizlerinde veri elde etmede önemli bir yöntemdir. Çalışan parça diğer bir test için sistemden çekilip, deneyin maliyeti ve deney süresi azaltılabilir(Kuş, 2004).
Teorem 1.1 (Balakrishnan ve Sandhu 1995) R R R
n m m n m n m U U U1: : < 2: : < < : : ,
( )
0,1Düzgün dağılımından alınmış R sansür şemalı ilerleyen tür tip-II sağdan
sansürlü sıra istatistikleri olsun.
R R R R R n m m n m m n m m n m m n m m U V U U V U U V : : 1 : : 2 : : 1 2 : : 1 : : 1 1 1 1 1 1 − = − − = − − = − − − (1.11)
rasgele değişkenleri bağımsızdır ve sırasıyla
m i R i Beta V m i m j j i ~ ,1 , 1,2, , 1 … = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ +
∑
+ − =İspat. (1.1),( 1.2) ve (1.10)’dan, R R R n m m n m n m U U
U1: : < 2: : < < : : ’nin ortak olasılık fonksiyonu
(
, , ,)
(
1)
, 0 1 1 1 2 1 , , , 2: : :: : : 1 =∏
− < < < < = m m i R i m U U U u u u c u u u f i n m m n m n m R … R … R (1.12)şeklinde elde edilir. Burada c , (1.9)’da tanımlandığı gibidir. (1.11)’de ters
dönüşüm yapılırsa m i V U m i m j j n m i 1 , 1,2, , 1 : : = −
∏
= … + − = Relde edilir. Eşitlik (1.11)’de tanımlanan dönüşümün jakobiyeni
∏
= − = m i i i V J 2 1
olarak bulunur. Böylece V1,V2,…,Vm in ortak olasılık yoğunluk fonksiyonu
(
v v v)
f v v v v J f m j j m m m U U U m V V V m mn mn mmn ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − − =∏
= − 1 1 , , , 2 1 , , ,2 , , , 1:: 2:: : : 1 ,1 , ,1 1 … … R R … R … 1 , , 0 , 1 1 1 1 < < ∑ =∏
= + − + − = m m i R i i v v v c m i m j j … (1.13) biçiminde elde edilir.Eşitlik (1.13)’de faktorizasyon teoremi kullanılırsa
1 ~ m ,1 i j j m i V Beta i R = − + ⎛ ⎞ + ⎜ ⎟ ⎝
∑
⎠, i=1, 2, ,… m ve V1,V2,…,Vm’nin bağımsız olduğu görülür.
R R R n m m n m n m U U U1: : < 2: : < < : : , Düzgün
( )
0,1 dağılımından alınmış Rsansür şemalı ilerleyen tür tip-II sağdan sansürlü sıra istatistikleri olsun. Teorem 1.1’den
R R R R R n m m n m m n m m n m m n m m U V U U V U U V : : 1 : : 2 : : 1 2 : : 1 : : 1 1 1 1 1 1 − = − − = − − = − − −
rasgele değişkenleri bağımsız ve sırasıyla
m i R i Beta V m i m j j i ~ ,1 , 1,2, , 1 … = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ +
∑
+ − =beta rasgele değişkenleridir. O zaman W V i m
m i m j j R i i i , 1,2, , 1 = … ∑ = = −+ + bağımsız ve
( )
0,1 Düzgün dağılımına sahiptir. 1.9. Asimptotik Normallik( )
X rasgele değişkenlerin bir dizisi , Z , standart normal dağılıma sahip nbir rasgele değişken ve ⎯⎯d→ , dağılımda yakınsamayı göstermek üzere, d n n n X a Z b − ⎯⎯→
olacak şekilde reel sayıların
( )
a ve pozitif reel sayıların n( )
b dizileri varsa, n( )
X ndizisine asimptotik normal veya daha açık olarak “a ortalaması” ve “n 2 n b
varyansı” ile asimptotik normal dizisi denir ve ~
(
, 2)
n n n AN a bX biçiminde
gösterilir. Buradaki a sayısı n X ’in beklenen değeri ve n 2 n
b sayısı X nin varyansı n
olmayabilir. Bu değerler sırasıyla X ’in asimptotik ortalama ve asimptotik n
1.10. Olabilirlik Fonksiyonu
n X X
X1, 2,..., örneklemi, olasılık (yoğunluk) fonksiyonu ( ; ),f x γ γ∈ p
olan kitleden alınan n birimlik bir örneklem olsun. Örneklemin ortak olasılık yoğunluk fonksiyonu
( ; ), n
f x γ x∈
olmak üzere bu fonksiyona parametrenin bir fonksiyonu gözü ile bakıldığında
( )
;( )
; , pL γ x = f x γ γ∈Γ ⊂ (1.14)
şeklinde tanımlanan fonksiyona X1,X2,...,Xn örneklemine dayalı olabilirlik
fonksiyonu denir. Burada x=
(
x x1, , ,2 … x ′n)
ve γ =(
γ γ1, , ,2 … γn)
′ şeklinde olupΓ parametre uzayıdır. Olabilirlik fonksiyonu L
( )
γ x; in logaritması alınarak( )
γ =log(
L( )
γ x;)
, γ∈Γ ⊂ p (1.15)1.11. Fisher Bilgi Matrisi
n X X
X1, 2,..., örneklemi, olasılık (yoğunluk) fonksiyonu ( ; ),f x γ γ∈ p
olan kitleden alınan n birimlik bir örneklem olsun. Bu örneklem için Fisher bilgi matrisi(Fisher information matrix)
(
)
(
)
( )
( ) log ; I E L E ⎧⎛ ∂ ⎞⎫ = − ⎨⎜∂ ⎟⎬ ⎝ ⎠ ⎩ ⎭ ⎧⎛ ∂ ⎞⎫ = − ⎨⎜∂ ⎟⎬ ⎝ ⎠ ⎩ ⎭ γ γ X γ γ γ( )
( )
( )
( )
( )
( )
( )
( )
( )
2 2 2 2 1 1 2 1 2 2 2 2 2 1 2 2 2 2 2 2 1 2 p p p p p γ γ γ γ γ γ γ γ γ γ γ γ γ γ γ ⎛∂ ∂ ∂ ⎞ ⎜ ∂ ∂ ∂ ∂ ∂ ⎟ ⎜ ⎟ ⎜∂ ∂ ∂ ⎟ ⎜ ⎟ ⎜ ⎟ = − ∂ ∂ ∂ ∂ ∂ ⎜ ⎟ ⎜ ⎟ ⎜∂ ∂ ∂ ⎟ ⎜ ⎟ ⎜∂ ∂ ∂ ∂ ∂ ⎟ ⎝ ⎠ γ γ γ γ γ γ γ γ γ (1.16)şeklinde tanımlanır, burada L γ X
(
;)
ve( )
γ sırasıyla eşitlik (1.14) ve (1.15) de verilen olabilirlik ve log-olabilirlik fonksiyonlarıdır (Wu ve Kuş 2009).1.12. En Çok Olabilirlik Tahmin Edicileri
Olabilirlik veya log-olabilirlik fonksiyonunu maksimum yapan γ değeri
( )
(
)
(
( )
)
ˆ arg max= L ; =arg max
γ γ x γ (1.17)
γ nın en çok olabilirlik tahmin edicisi (Maximum Likelihood Estimator, MLE)
1.13. Asimptotik Güven Aralıkları
Eşitlik (1.17) de tanımlanan en çok olabilirlik tahmin edicisi ˆγ bazı düzgünlük şartları altında
(
ˆ)
d(
0, 1( )
)
n γ γ− ⎯⎯→N I− γolmak üzere asimptotik normaldir, burada I−1
( )
γ , (1.16) eşitliğinde tanımlıFisher Bilgi Matrisidir. Fisher Bilgi matrisinin tersi ˆγ nın asimptotik varyans-kovaryans matrisidir. Bu matrisin bilinmesi, büyük örneklemler için γ γˆ ˆ1, , ,2 … γˆn tahmin edicilerinin ayrı ayrı asimptotik varyanslarının bilinmesi anlamına gelmektedir. I−1
( )
γ nın tutarlı bir tahmin edicisi( )
( )
( )
( )
( )
( )
( )
( )
( )
( )
1 2 2 2 2 1 1 2 1 2 2 2 1 2 2 1 2 2 2 2 2 2 1 2 ˆ p p p p p I γ γ γ γ γ γ γ γ γ γ γ γ γ γ γ γ γ − − = ⎛∂ ∂ ∂ ⎞ ⎜ ∂ ∂ ∂ ∂ ∂ ⎟ ⎜ ⎟ ⎜∂ ∂ ∂ ⎟ ⎜ ⎟ ⎜ ⎟ = − ∂ ∂ ∂ ∂ ∂ ⎜ ⎟ ⎜ ⎟ ⎜∂ ∂ ∂ ⎟ ⎜ ⎟ ⎜∂ ∂ ∂ ∂ ∂ ⎟ ⎝ ⎠ γ γ γ γ γ γ γ γ γ γ (1.18a)dır (Adamidis ve Loukas 1998). Buradan ,γi i=1, 2, ,… p için ˆγi’ya dayalı asimptotik güven aralığı
1 1 2 2 ˆi ii i ˆi ii 1 P γ z α V γ γ z α V α − − ⎛ ⎞ − < < + ≅ − ⎜ ⎟ ⎝ ⎠ (1.18b)
şeklinde oluşturulabilir. Burada V , eşitlik (1.18a)’da verilen matrisin ii .i diogonal elemanıdır ve a∈
( )
0,1 için z , standart normal dağılımın a a. kuantilidir (Wu ve Kuş 2009).1.14. Taylor Serileri
[ ]
a b Rf : , → fonksiyonunun
( )
a b, aralığında n. mertebeden türevi f (n)olmak üzere
[ ]
a,b ’nin keyfi x ve 0 x>x0 noktaları için(
)
∑
= + − = n k n k k x x x k R x f x f 0 0 0 ) ( ( ) / ! ( ) ) ( (1.19)açılımına f fonksiyonunun x noktasındaki Taylor serisi denir. Burada 0
(
1)
!(
(
)
)(
1) (
)
, 0 1 1 ) ( ( 1) 0 + − 0 − − 0 1 < < + = n+ θ θ n n+ θ n f x x x x x n x R (1.20) veya( )
x o(
(
x x0)
)
, x x0 R n n = − → (1.21) şeklindedir (Shahbazov 2005).1.15. Birinci Mertebe Yaklaşımı
1: :m n, 2: :m n, , m m n: :
UR UR … UR Düzgün
( )
0,1 dağılımından alınmış ilerleyen tür tip IIsağdan sansürlü örneklem olmak üzere bu örneklemin ortak olasılık yoğunluk fonksiyonu;
(
1 2)
(
)
1 1 , , , 1 i, 0 1 m R m i m i f u u u c u u u = =∏
− < < < < … (1.22) şeklindedir, burada c(
− 1−1)
× ×(
− 1 − 2 − − 1− +1)
=n n R n R R R − m c m dir.Bu sonuçlar kullanılarak, U1: :Rm n,U2: :Rm n, ,… Um m nR: : Düzgün
( )
0,1 dağılımındanalınmış ilerleyen tür tip II sağdan sansürlü örneklem olmak üzere
: : , 1, 2, , i m n
UR i= … m .i ilerleyen tür sağdan sansürlü sıra istatistiğinin beklenen
değer ve varyansı
(
i m n: :)
i 1 i,E UR =π = −b i=1 …,2, ,m (1.23)
(
i m n: :)
i i,Var UR =k b i=1, 2, ,… m (1.24)
şeklindedir. 1 i≤ < ≤ için j n Ui m nR: : ile
: : j m n
UR rasgele değişkenlerinin arasındaki
kovaryans
(
i m n: : , j m n: :)
i j, Cov UR UR =k b 1 i≤ < ≤ j m biçimindedir. Burada i=1 …,2, ,m ve 1 1 1 m j m j m j m j R R a j R R − + − + + + + = + + + + için 1 1 1 1 1 1 1 1 2 3 1 2 i k k m i k k k m i k k m k k k m m m j j j m i j m i m k R R R k m k R R R m k R R R m k R R R a γ + = + + = + = − + = − + ⎧ − + + + + + ⎫ = ⎨ ⎬ − + + + + + ⎩ ⎭ ⎧ − + + + + + ⎫ − ⎨ ⎬ − + + + + + ⎩ ⎭ = −∏
∏
∏
∏
(1.25) ve 1 1 1 1 1 2 i m k k m i j k k k m j m i m k R R R b a m k R R R + = + = − + ⎧ − + + + + + ⎫ = ⎨ ⎬= − + + + + + ⎩ ⎭∏
∏
(1.26)Yukarıdaki açıklamalar kullanılarak herhangi sürekli bir F i
( )
dağılımına sahip bir kitleden alnınan ilerleyen tür tip II sağdan sansürlü sıra istatistiklerinin beklenen değer, varyans ve kovaryans değerleri aşağıdaki gibi elde edilebilir.Ters olasılık integral dönüşümünden
(
)
1 : : : : d i m n i m n YR =F− UR (1.27)yazılabilir. Burada F , ilerleyen tür tip II sağdan sansürlü örneklemin geldiği −1
yaşam zamanı dağılımı için dağılım fonksiyonun tersidir ve = ise dağılımda d eşitliği göstermektedir. (1.27) eşitliğinin sağ tarafı πi =E U
(
i m nR: :)
civarında Taylorserisine açıp beklenen değerini alınıp ilk terim dışındakiler göz ardı edilerek
( )
1( )
: : ,
i m n i
E YR ≈F− π i=1 …,2, ,m (1.28)
yazılabilir. Eşitlik (1.28)’deki πi, (1.23) eşitliğinde verildiği gibidir. Bu bilgiler yardımıyla varyans ve kovaryans değerleri de
( )
( )( )
{
1}
2 1 : : i m n i i i Var YR ≈ F− π k b i=1 …,2, ,m (1.29) ve(
)
( )( )
( )( )
1 1 1 1 : : , : : , i m n j m n i j i j Cov YR YR ≈F− π F− π k b 1 i≤ < ≤ (1.30) j m şeklindedir. Burada F 1( )1( )
u d F 1( )
u du− = − şeklinde tanımlıdır (Balakrishnan ve
1.16. Newton-Raphson Yöntemi
( )
x =0f denkleminin bir kökünün bulunmasındaki iteratif yöntemlerden biridir. f
( )
x sürekli ve türevlenebilen fonksiyonunun bilinen yaklaşık bir kökün
x olsun. f
(
xn + fonksiyonu h)
x civarında ikinci mertebeye kadar Taylor nserisine açılırsa
(
x h)
f( )
x hf( )
x h hf( )
(
x x h)
f n + = n + ′ n + ′′ n ∈ n, n + 2 2 ξ ξyazılabilir. xn +h=xn+1 değerinin gerçek köke çok yakın olduğu yani
(
x h)
f n + ’ ın hemen sıfır olduğu düşünülürse,
( )
x hf( )
x h f( )
(
x x h)
f n + ′ n + ′′ n ∈ n n + = , 2 0 2 ξ ξyazılır. h yeterince küçük ise h ’yi içeren terim ve sonraki terimler ihmal 2
edilebilir. Böylece
( )
xn +hf′( )
xn =0 f veya( )
( )
xnn f x f h ′ − =( )
( )
n n n n x f x f x x ′ − = +1 iterasyon denklemine ulaşılır (Oturanç ve ark 2003).Newton – Raphson yöntemi geometrik olarak incelenecek olursa
( )
x =0f fonksiyonunun başlangıç yaklaşık kökü x olmak üzere fonksiyonun 0
( )
(
x0,f x0)
noktasındaki teğetinin denklemi( )
x0 f( )(
x0 x x0)
fy− = ′ −
olarak yazılabilir. Bu teğetin x eksenini kestiği nokta ilk kök yaklaşımı olur ve
( )
( )
00 0 1 x f x f x x ′ − =2.UZUN KUYRUKLU SİMETRİK DAĞILIM
Uzun Kuyruklu Simetrik dağılım, özellikle aykırı değer içeren örneklemlere dayalı istatistiksel sonuç çıkarımı yaparken çok kullanışlıdır (Tiku ve Akkaya 2004). X rasgele değişkeni, Uzun Kuyruklu Simetrik dağılıma (Long-Tailed Symmetric Distribution, LTS) sahip olduğunda, X ’in olasılık yoğunluk fonksiyonu 2 1 1 ( ; , ) 1 , 1 1 B , 2 2 p x g x x k k p μ μ σ σ σ − ⎧ − ⎫ ⎪ ⎛ ⎞ ⎪ = ⎨ + ⎜ ⎟ ⎬ ∈ ⎛ − ⎞⎪⎩ ⎝ ⎠ ⎪⎭ ⎜ ⎟ ⎝ ⎠ (2.1)
şeklinde tanımlanır (Tiku ve Akkaya 2004, syf:30).
Burada k = p2 −3, 3 2
p> , μ∈ ve σ >0 dır. Ayrıca X rasgele değişkeninin 5p>1. için beklenen değer ve varyansı E
( )
X =μ, Var( )
X =σ2şeklindedir. Ayrıca μ konum, σ ölçek parametresidir (Şenoğlu ve Tiku 2001).
3
2 −
= p
k ifadesinde p ’nin sonsuza yaklaşması durumunda LTS
dağılımı normal dağılıma yaklaşır (Şenoğlu ve Tiku 2001, Tiku ve Akaya, 2004). Şekil 2.1 de μ =0 veσ =1 olması durumunda farklı p değerleri için LTS
Şekil 2.1 Farklı p değerleri için LTS dağılımının olasılık yoğunluk
fonksiyonunun grafiği
Şekil 2.1 incelendiğinde, p değerlerinin artması durumunda LTS dağılımının olasılık yoğunluk fonksiyonu normal dağılımın olasılık yoğunluk fonksiyonuna benzemektedir. p=10 olması durumunda LTS dağılımının olasılık yoğunluk fonksiyonu hemen hemen normal dağılımın olasılık yoğunluk fonksiyonu ile aynıdır.
Aşağıda p=2,σ = değerleri sabit kalması koşulu ile farklı 1 μ değerleri için LTS dağılımının olasılık yoğunluk fonksiyonunun grafiği aşağıda verilmiştir.
Şekil 2.2 Farklı μ değerleri için LTS dağılımının olasılık yoğunluk fonksiyonunun grafiği
Şekil 2.2 incelendiğinde μ arttırıldığında LTS dağılımının olasılık yoğunluk fonksiyonunun grafiği sağa doğru kaymaktadır. Burada μ parametresinin LTS dağılımı için bir konum parametresi olduğu açıkça gözlenmektedir.
Şekil 2.3 Farklı σ değerleri için LTS dağılımının olasılık yoğunluk
Şekil 2.3’teki grafikte sabit p=2,μ =0 değerleri için farklı σ değerlerine karşılık LTS dağılımının olasılık yoğunluk fonksiyonunun grafiği çizilmiştir. Grafik incelendiğinde σ değerleri arttıkça olasılık yoğunluk fonksiyonunun grafiğinin yayılımı artmaktadır. Burada σ ’nın, LTS dağılımı için ölçek parametresi olduğu açıkça gözlemlenmektedir.
LTS dağılımına sahip X rasgele değişkeninin dağılım fonksiyonu
2 1 1 ( , , ) 1 1 1 B , 2 2 p x x G x dx k k p μ μ σ σ σ − −∞ ⎧ − ⎫ ⎪ ⎛ ⎞ ⎪ = ⎨ + ⎜ ⎟ ⎬ ⎛ − ⎞⎪⎩ ⎝ ⎠ ⎪⎭ ⎜ ⎟ ⎝ ⎠
∫
(2.2) şeklindedir.X rasgele değişkeni μ veσ parametreli LTS dağılımına sahip olduğunda
σ μ − = X
Z dönüşümü uygulanırsa Z standart LTS dağılımına sahip olur ve
Z ’nin olasılık yoğunluk fonksiyonu
2 1 ( ) 1 , 1 1 B , 2 2 p z f z z k k p − ⎧ ⎫ = ⎨ + ⎬ ∈ ⎛ − ⎞ ⎩ ⎭ ⎜ ⎟ ⎝ ⎠ (2.3)
şeklinde tanımlanır. Burada B ,ii
( )
Beta fonksiyonudur. Z’nin Maple 11 program yardımıyla hesaplanan dağılım fonksiyonu ise2 1 ( ) 1 , 1 1 B , 2 2 p z z F z dz z k k p − −∞ ⎧ ⎫ = ⎨ + ⎬ ∈ ⎛ − ⎞ ⎩ ⎭ ⎜ ⎟ ⎝ ⎠
∫
(2.4) şeklindedir.X , LTS dağılıma sahip bir rasgele değişken olmak üzere X rasgele
değişkeninin r.momenti Maple 11 programı yardımıyla
( )
(
)
(
( )
)
2 2 1 1 1 1 B , 2 2 1 1 2 3 1 1 1 2 2 2 2 , 3 1 2 2 2 p r r r r z E X x dx k k p r r p p p p π − ∞ −∞ ⎛ ⎞ ⎜ ⎟ ⎝ ⎠ ⎧ ⎫ = ⎨ + ⎬ ⎛ − ⎞ ⎩ ⎭ ⎜ ⎟ ⎝ ⎠ ⎛ ⎞ ⎛ ⎞ Γ⎜ − − ⎟ ⎜Γ + ⎟ − + − ⎝ ⎠ ⎝ ⎠ = > ⎛ ⎞ Γ⎜ − ⎟ ⎝ ⎠∫
(2.5)biçiminde elde edilir.
(2.5) eşitsizliği kullanılarak LTS dağılımının Basıklık katsayısı (kurtosis)
2 3 3 5 2 , 5 2 2 p p p γ ⎛ − ⎞ ⎜ ⎟ ⎝ ⎠ = > −
şeklindedir (Tiku ve Akkaya 2004).
Ayrıca LTS dağılımı simetrik dağılım olduğundan çarpıklık katsayısı
1 0
γ = dır. Çizelge 2.1’de LTS dağılımının farklı p değerleri için Basıklık
katsayısı değerleri verilmiştir(Tiku ve Akaya 2004). Şekil 2.4’de Excel yazılımı
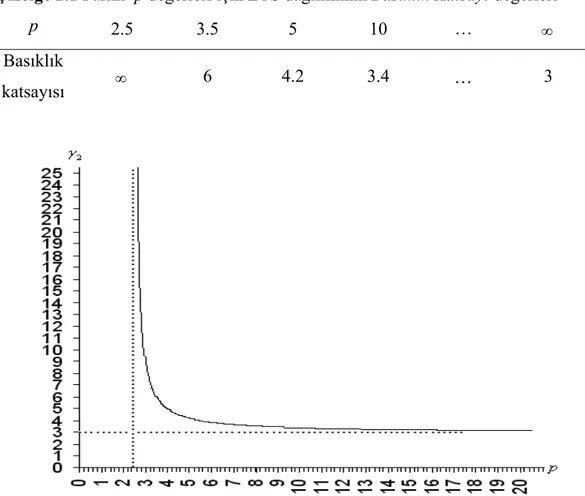
Çizelge 2.1 Farklı p değerleri için LTS dağılımının Basıklık Katsayı değerleri
p 2.5 3.5 5 10 … ∞
Basıklık
katsayısı ∞ 6 4.2 3.4 … 3
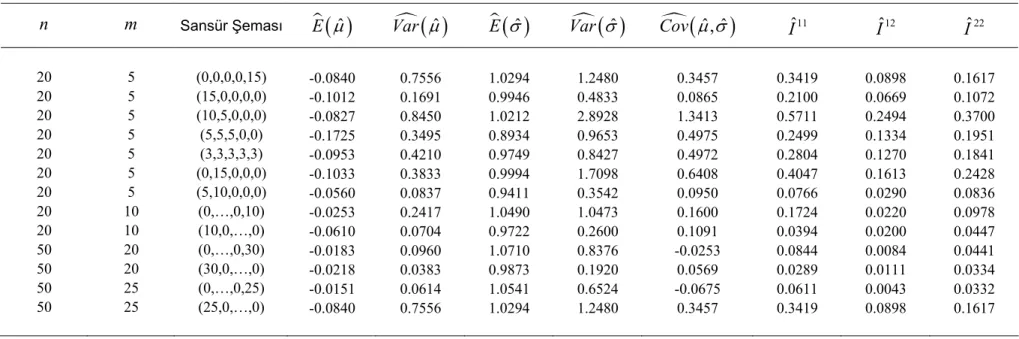
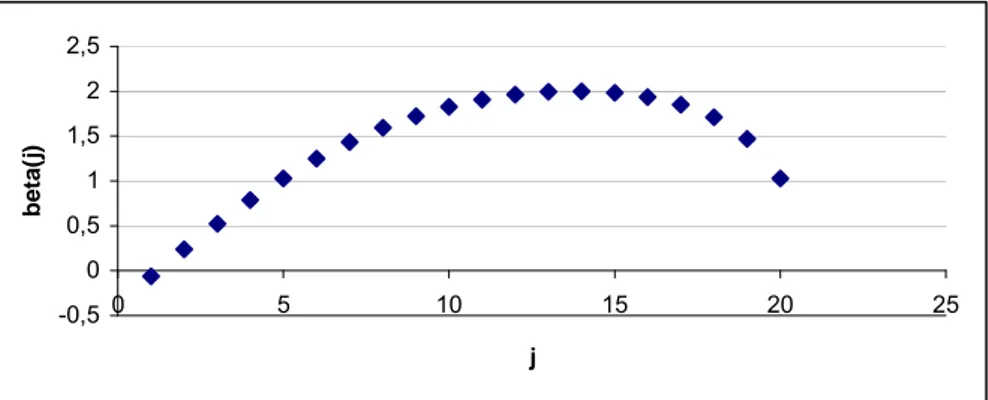
Şekil 2.4 LTS dağılımının farklı p değerleri için Basıklık katsayısı değişim grafiği
Şekil 2.4 incelendiğinde 2.5p= için basıklık katsayısının sonsuza gittiği,
p arttıkça basıklık katsayısının 3’e yaklaştığı (normal dağılım basıklık katsayısı)
gözükmektedir. Buda LTS dağılımının, p parametresi sonsuza gittiğinde normal
dağılıma yaklaştığını desteklemektedir.
X , LTS dağılımına sahip bir rasgele değişken olmak üzere
v X v T Z k k μ σ − ⎛ ⎞ = ⎜ ⎟=
⎝ ⎠ şeklinde tanımlanan T rasgele değişkeni v= p2 −1 serbestlik dereceli t dağılımına sahiptir (Tiku ve Akkaya 2004, Tiku ve Sürücü,
2.1.En Çok Olabilirlik Tahmincisi R R R n m m n m n m X X X1: : < 2: : < < : : , LTS dağılımından
(
R1,R2,…,Rn)
sansür şemalı ilerleyen tür tip II sağdan sansürlü örneklem olsun.(1.10)’dan ilerleyen tür tip II sağdan sansürlü örnekleme dayalı olabilirlik fonksiyonu(
)
(
)
(
(
)
)
1 , m , , 1 , , Rj j j j L μ σ c g x μ σ G x μ σ = =∏
− (2.6)şeklindedir. Burada G, eşitlik (2.1)’de verilen g yoğunluk fonksiyonuna ilişkin
(2.2) de verilen dağılım fonksiyonudur. Eşitlik (2.6)’da verilen olabilirlik fonksiyonu
(
)
( )
(
( )
)
Rj j m j j m f z F z c L =∏
− = − 1 , 1 σ σ μ (2.7)şeklinde yazılabilir, burada f i
( )
ve F i( )
, sırasıyla, (2.3) ve (2.4) de tanımlandığı gibidir. Ayrıca, zj =(
xj −μ)
/σ dır. Olabilirlik fonksiyonun logaritması alınarak log-olabilirlik fonksiyonu(
)
[
]
( )
∑
(
( )
)
∑
(
( )
)
= = − + + − = m j j j m j j R F z z f m c L 1 1 1 log log log log , log μ σ σbiçiminde elde edilir. Buradan olabilirlik denklemleri aşağıdaki gibi elde edilmiştir (Asgharzadeh 2006).
(
)
( )
( )
∑
( )
( )
∑
= = = − + ′ − = ∂ ∂ m j j j j m j j j z F z f R z f z f L 1 1 0 1 1 1 , log σ σ μ σ μ (2.8)(
)
( )
( )
∑
( )
( )
∑
= = = − + ′ − − = ∂ ∂ m j j j j j m j j j j z F z f z R z f z f z m L 1 1 0 1 1 1 , log σ σ σ σ σ μ (2.9)2.2. Modifiye Edilmiş En Çok Olabilirlik Tahmin Edicileri
İlerleyen tür tip II sağdan sansürlü örneklemlere dayalı olabilirlik denklemlerinden ilgili parametrelerin en çok olabilirlik tahmin edicileri genellikle analitik olarak elde edilemez. Böylece konum ölçek parametreleri için analitik olarak elde edilebilen asimptotik en çok olabilirlik tahmin edicileri arzu edilebilir. Bu analitik tahmin ediciler olabilirlik denklemlerin iteratif çözümleri için iyi bir başlangıç değeri olarak kullanılabilirler. Asimptotik olabilirlik denklemleri fikri yeni değildir. Asimptotik en çok olabilirlik tahmin edicileri ayrıntılı olarak Tiku ve Akkaya ( Robust Estimation and Hypothesis Testing )’nın kitabında tartışılmıştır.
En çok olabilirlik tahmin edicileri (MLE), bazı düzgünlük şartları (regularity conditions) altında asimptotik normallik gibi arzu edilen özelliklere sahip olmaktadır. Fisher bilgi matrisinin (Fisher Information Matrix) tersi, bazı düzgünlük şartları altında ML tahmin edicilerinin asimptotik dağılımının varyans-kovaryans matrisi olması nedeniyle parametrelerin asimptotik güven aralıkları ML tahmin edicilerine dayalı olarak elde edilebilmektedir. ML tahmin edicilerinin istenen özelliklere sahip olmasının yanı sıra bazı durumlarda bu tahmin edicilerin elde edilmesinde bazı sorunlar ortaya çıkabilir. Örneğin, olabilirlik fonksiyonunun parametreye göre lineer olmadığı ve birden fazla tepeli (polymodal) olması durumunda ML tahmin edicilerini elde etmek için Newton-Raphson ve EM (Expectation-Maximization) algoritması gibi bazı iteratif yöntemler kullanılmaktadır. Bu iteratif yöntemlerin uygulanmasında parametrelerin başlangıç değerlerinin seçimi birden fazla tepeli olabilirlik fonksiyonunun en
büyüklenmesinde önemli rol oynamaktadır. Olabilirlik denklemlerinin gerçek çözümlerine uzak başlangıç değerleri verilmesi durumunda yukarıda bahsedilen iteratif yöntemler genel maksimum yerine yerel maksimum değerine ulaşabilir. Sansürlü ve maskeli örneklemlere dayalı olabilirlik fonksiyonları, genellikle parametrelere göre lineer değildir. Bu sebepten iteratif yöntemlerin, istenilen çözüme ulaştırmama ihtimali göz önüne alındığında daima analitik olarak elde edilen ve ML tahmin edicileri ile aynı asimptotik özelliklere sahip olan modifiye edilmiş en çok olabilirlik tahmin edicilerinin (MMLE, Tiku 1967a, b; 1968a, b, c; 1970; 1973) önemi ortaya çıkmaktadır. Modifiye edilmiş tahmin ediciler aşağıdaki prosedür yardımıyla elde edilebilir (Tiku ve Akkaya 2004).
Aşağıda ölçek parametresi bilindiğinde konum parametresinin modifiye edilmiş en çok olabilirlik tahmin edicisinin elde edilmesindeki süreç verilmiştir.
1, 2, , n
X X … X , konum parametresi θ , ölçek parametresi σ (biliniyor) olan g yoğunluklu bir kitleden alınan nbirimlik bir örneklem olmak üzere bu örnekleme dayalı olabilirlik denklemi
(
)
1 log ; 1 ( ) 0 n i i L g z θ θ σ = ∂ = = ∂∑
X , (zi = xi−θ σ) / (2.10)şeklinde yazılabilir, burada ,x ii =1, 2, ,… n, X X1, 2, ,… Xn örnekleminin aldığı değerler ve X=
(
X X1, 2, ,… Xn)
dir. X X1, 2, ,… Xn örneklemine dayalı sıra istatistikleri(1) (2) ( )n
X ≤X ≤ ≤ X (2.11) olmak üzere (2.10) eşitliği, (2.11) de verilen sıra istatistiklerine dayalı olarak
(
)
( ) 1 log ; 1 ( ) 0 n i i L g z θ θ σ = ∂ = = ∂∑
X , z( )i =(x( )i −θ σ) / (2.12)biçiminde yazılabilir, burada ,z ii =1, 2, ,… , n Z(1) ≤Z(2)≤ ≤Z( )n sıra istatistiklerinin aldığı değerlerdir. t , .i standartlaştırılmış sıra istatistiği (i) Z( )i nin
beklenen değeri
(
t( )i =E Z( )
( )i ,i=1, 2, ,… n)
olmak üzere g(z(i)) yi, t civarında (i)Taylor serisine açıp ilk iki terimi alındığında aşağıdaki doğrusal eşitlik elde edilir.
) ( ) ( ) ( ) ( ) ( () () () () i t z i i i i g z z t z t g z g = ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ ∂ ∂ − + ≅ (2.13) ) (i i i β z α + = , (1≤i≤n) , burada ) ( ) ( i t z i g z z ⎭⎬ = ⎫ ⎩ ⎨ ⎧ ∂ ∂ = β ve αi =g(t(i))−βit(i) (2.14)
dır. Eğer g(z) sınırlı bir fonksiyon ve z , (i) t ye yaklaştığında (i) 1 i n≤ ≤ için
( ) ( )
( i ) ( i i i ) n 0
g z − α β+ z ⎯⎯⎯→∞→ , (2.15)
dır. (2.13) (2.12) de yazıldığında modifiye edilmiş olabilirlik denklemi
{
}
* ( ) 1 log log 1 0 n i i i i L L z α β θ θ σ = ∂ ≅∂ = + = ∂ ∂∑
(2.16)şeklinde yazılabilir. Bu eşitlik bazı düzgünlük (regularity) şartlar altında
* 1 log log lim 0 n L L n θ θ →∞ ⎧∂ ∂ ⎫ ⎪ − ⎪= ⎨ ∂ ∂ ⎬ ⎪ ⎪ ⎩ ⎭ (2.17) dır. (2.15) ve (2.17) den, modifiye edilmiş en çok olabilirlik denklemi asimptotik olarak en çok olabilirlik denklemine denk olduğu söylenebebilir. (2.16) denkleminden elde analitik olarak elde edilen θ parametresinin tahmin edicisine modifiye edilmiş olabilirlik MML (Modified Maxsimum Likelihood) tahmin edicisi