Lineking: coffee shop wait-time monitoring using smartphones
Tam metin
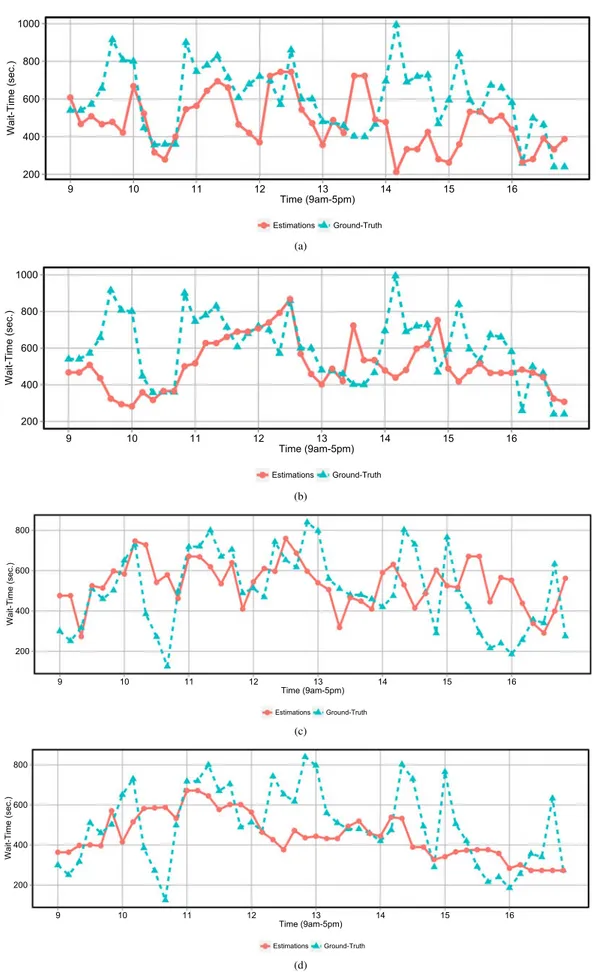
Şekil
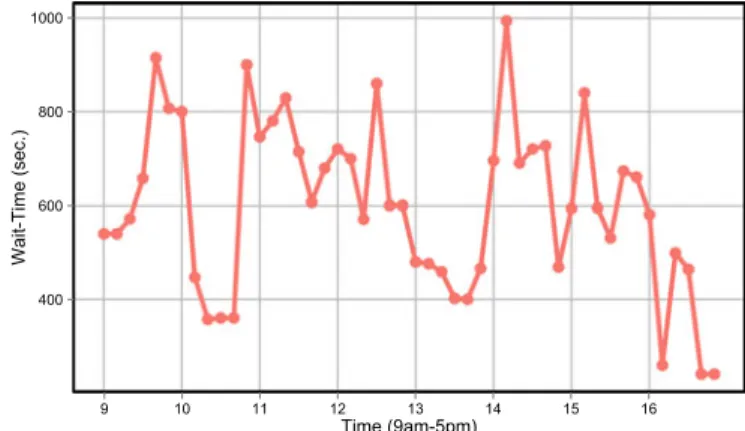
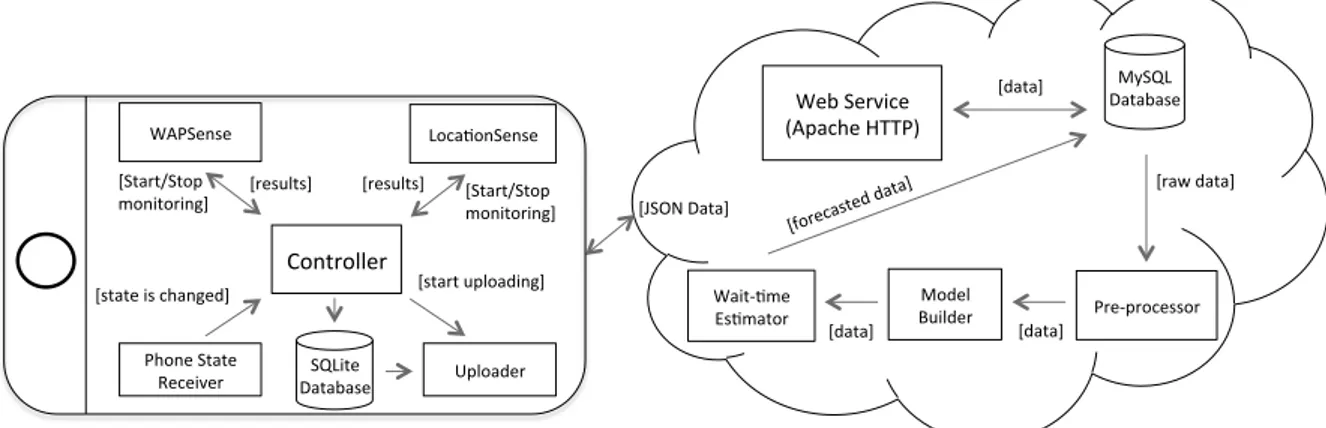
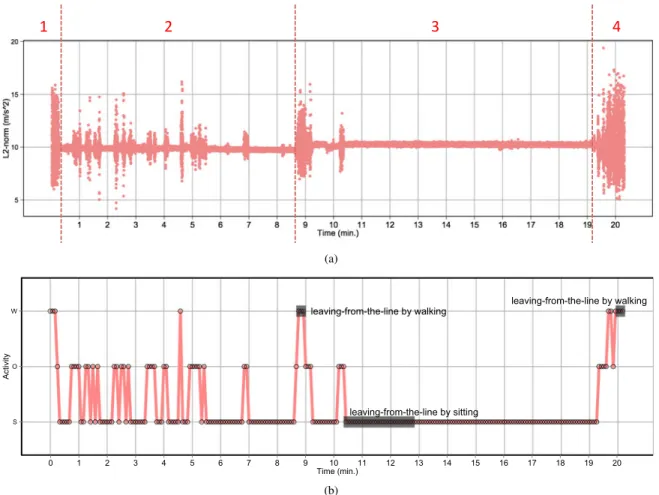
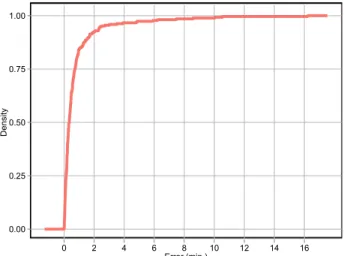
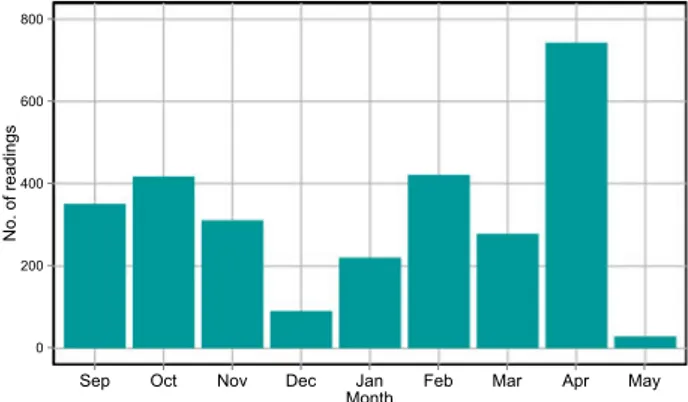
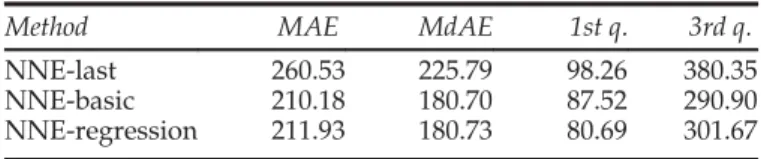
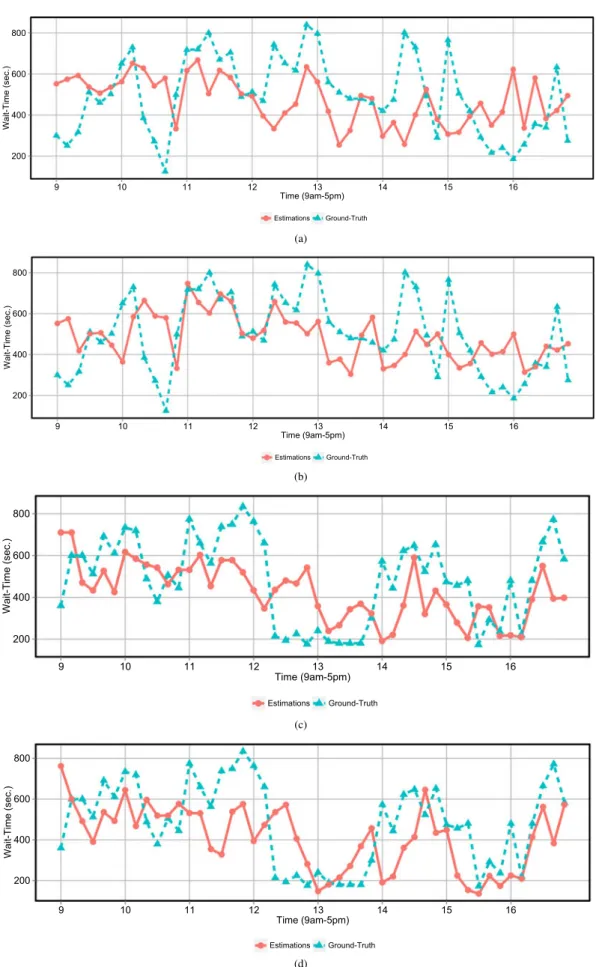
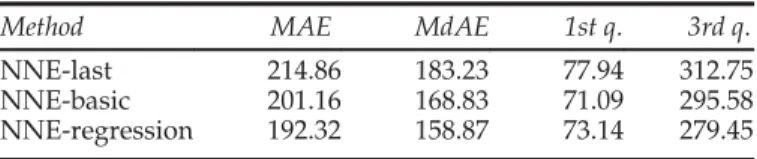
Benzer Belgeler
After suicide bombings in Ankara and Urfa in 2015, the Depart- ment of War Surgery in Gülhane Military Medical Academy (GATA) started the “Current Approaches to Firearms Injuries
Determination of Optimum Device Layout Dimensions Based on the Modulation Frequency The studied bolometer array in this work was mainly designed for investigation of the inter-pixel
Perceived usefulness and ease of use of the online shopping has reduced post purchase dissonance of the customers. Also, these dimensions are very strong and playing
The vortex creep model posits two different kinds of response to a glitch; a linear response characterized by exponential relaxation, and a nonlinear response characterized by a step
Un grand nombre d’aqueducs fameux sillonnent la cam pagne aux environs de la ville: ils sont destinés à transporter l'eau d'une colline à l’autre à travers les
Saptanan ortak temalardan yola çıkarak sosyal bilimler eğitiminde ölçme ve değerlendirmeye dair problemlerin; hem içinde bulunduğumuz acil uzaktan eğitim süreci
Hence, by variation of the wave function, we are able to represent the minimum tunneling time min (E) in terms of the transmission probability of the barrier and its set of
Methods: Patients who had recieved anakinra with a diagnosis of recur- rent pericarditis either idiopathic or secondary to FMF followed in our autoinflammatory disease center
